
| | |  Ver fonte no GitHub Ver fonte no GitHub |
Este tutorial treina um modelo Transformer para traduzir um conjunto de dados de português para inglês . Este é um exemplo avançado que pressupõe conhecimento de geração de texto e atenção .
A ideia central por trás do modelo Transformer é a autoatenção — a capacidade de atender a diferentes posições da sequência de entrada para calcular uma representação dessa sequência. O Transformer cria pilhas de camadas de autoatenção e é explicado abaixo nas seções Atenção ao produto escalado e Atenção multi-cabeças .
Um modelo de transformador lida com entradas de tamanho variável usando pilhas de camadas de autoatenção em vez de RNNs ou CNNs . Essa arquitetura geral tem várias vantagens:
- Ele não faz suposições sobre as relações temporais/espaciais entre os dados. Isso é ideal para processar um conjunto de objetos (por exemplo, unidades de StarCraft ).
- As saídas de camada podem ser calculadas em paralelo, em vez de uma série como um RNN.
- Itens distantes podem afetar a saída uns dos outros sem passar por muitas etapas RNN ou camadas de convolução (consulte Transformador de memória de cena , por exemplo).
- Ele pode aprender dependências de longo alcance. Este é um desafio em muitas tarefas de sequência.
As desvantagens desta arquitetura são:
- Para uma série temporal, a saída para um passo de tempo é calculada a partir de todo o histórico em vez de apenas as entradas e o estado oculto atual. Isso pode ser menos eficiente.
- Se a entrada tiver uma relação temporal/espacial, como texto, alguma codificação posicional deve ser adicionada ou o modelo verá efetivamente um pacote de palavras.
Após treinar o modelo neste caderno, você poderá inserir uma frase em português e devolver a tradução em inglês.
Configurar
pip install tensorflow_datasetspip install -U tensorflow-text
import collections
import logging
import os
import pathlib
import re
import string
import sys
import time
import numpy as np
import matplotlib.pyplot as plt
import tensorflow_datasets as tfds
import tensorflow_text as text
import tensorflow as tf
logging.getLogger('tensorflow').setLevel(logging.ERROR) # suppress warnings
Baixe o conjunto de dados
Use os conjuntos de dados do TensorFlow para carregar o conjunto de dados de tradução português-inglês do projeto de tradução aberta TED Talks .
Este conjunto de dados contém aproximadamente 50.000 exemplos de treinamento, 1.100 exemplos de validação e 2.000 exemplos de teste.
examples, metadata = tfds.load('ted_hrlr_translate/pt_to_en', with_info=True,
as_supervised=True)
train_examples, val_examples = examples['train'], examples['validation']
O objeto tf.data.Dataset retornado pelos conjuntos de dados do TensorFlow gera pares de exemplos de texto:
for pt_examples, en_examples in train_examples.batch(3).take(1):
for pt in pt_examples.numpy():
print(pt.decode('utf-8'))
print()
for en in en_examples.numpy():
print(en.decode('utf-8'))
e quando melhoramos a procura , tiramos a única vantagem da impressão , que é a serendipidade . mas e se estes fatores fossem ativos ? mas eles não tinham a curiosidade de me testar . and when you improve searchability , you actually take away the one advantage of print , which is serendipity . but what if it were active ? but they did n't test for curiosity .
Tokenização e destokenização de texto
Você não pode treinar um modelo diretamente no texto. O texto precisa ser convertido em alguma representação numérica primeiro. Normalmente, você converte o texto em sequências de IDs de token, que são usados como índices em uma incorporação.
Uma implementação popular é demonstrada no tutorial do Tokenizer Subword cria tokenizers de subpalavra ( text.BertTokenizer ) otimizados para este conjunto de dados e os exporta em um saved_model .
Baixe e descompacte e importe o saved_model :
model_name = "ted_hrlr_translate_pt_en_converter"
tf.keras.utils.get_file(
f"{model_name}.zip",
f"https://storage.googleapis.com/download.tensorflow.org/models/{model_name}.zip",
cache_dir='.', cache_subdir='', extract=True
)
Downloading data from https://storage.googleapis.com/download.tensorflow.org/models/ted_hrlr_translate_pt_en_converter.zip 188416/184801 [==============================] - 0s 0us/step 196608/184801 [===============================] - 0s 0us/step './ted_hrlr_translate_pt_en_converter.zip'
tokenizers = tf.saved_model.load(model_name)
O tf.saved_model contém dois tokenizers de texto, um para inglês e outro para português. Ambos têm os mesmos métodos:
[item for item in dir(tokenizers.en) if not item.startswith('_')]
['detokenize', 'get_reserved_tokens', 'get_vocab_path', 'get_vocab_size', 'lookup', 'tokenize', 'tokenizer', 'vocab']
O método tokenize converte um lote de strings em um lote preenchido de IDs de token. Este método divide pontuação, letras minúsculas e normaliza unicode a entrada antes da tokenização. Essa padronização não é visível aqui porque os dados de entrada já estão padronizados.
for en in en_examples.numpy():
print(en.decode('utf-8'))
and when you improve searchability , you actually take away the one advantage of print , which is serendipity . but what if it were active ? but they did n't test for curiosity .
encoded = tokenizers.en.tokenize(en_examples)
for row in encoded.to_list():
print(row)
[2, 72, 117, 79, 1259, 1491, 2362, 13, 79, 150, 184, 311, 71, 103, 2308, 74, 2679, 13, 148, 80, 55, 4840, 1434, 2423, 540, 15, 3] [2, 87, 90, 107, 76, 129, 1852, 30, 3] [2, 87, 83, 149, 50, 9, 56, 664, 85, 2512, 15, 3]
O método detokenize tenta converter esses IDs de token de volta em texto legível por humanos:
round_trip = tokenizers.en.detokenize(encoded)
for line in round_trip.numpy():
print(line.decode('utf-8'))
and when you improve searchability , you actually take away the one advantage of print , which is serendipity . but what if it were active ? but they did n ' t test for curiosity .
O método de lookup de nível inferior converte de token-IDs em texto de token:
tokens = tokenizers.en.lookup(encoded)
tokens
<tf.RaggedTensor [[b'[START]', b'and', b'when', b'you', b'improve', b'search', b'##ability', b',', b'you', b'actually', b'take', b'away', b'the', b'one', b'advantage', b'of', b'print', b',', b'which', b'is', b's', b'##ere', b'##nd', b'##ip', b'##ity', b'.', b'[END]'] , [b'[START]', b'but', b'what', b'if', b'it', b'were', b'active', b'?', b'[END]'] , [b'[START]', b'but', b'they', b'did', b'n', b"'", b't', b'test', b'for', b'curiosity', b'.', b'[END]'] ]>
Aqui você pode ver o aspecto de "subpalavra" dos tokenizers. A palavra "searchability" é decomposta em "search ##ability" e a palavra "serendipity" em "s ##ere ##nd ##ip ##ity"
Configurar pipeline de entrada
Para criar um pipeline de entrada adequado para treinamento, você aplicará algumas transformações ao conjunto de dados.
Esta função será usada para codificar os lotes de texto bruto:
def tokenize_pairs(pt, en):
pt = tokenizers.pt.tokenize(pt)
# Convert from ragged to dense, padding with zeros.
pt = pt.to_tensor()
en = tokenizers.en.tokenize(en)
# Convert from ragged to dense, padding with zeros.
en = en.to_tensor()
return pt, en
Aqui está um pipeline de entrada simples que processa, embaralha e agrupa os dados:
BUFFER_SIZE = 20000
BATCH_SIZE = 64
def make_batches(ds):
return (
ds
.cache()
.shuffle(BUFFER_SIZE)
.batch(BATCH_SIZE)
.map(tokenize_pairs, num_parallel_calls=tf.data.AUTOTUNE)
.prefetch(tf.data.AUTOTUNE))
train_batches = make_batches(train_examples)
val_batches = make_batches(val_examples)
Codificação posicional
As camadas de atenção veem sua entrada como um conjunto de vetores, sem ordem sequencial. Este modelo também não contém nenhuma camada recorrente ou convolucional. Por causa disso, uma "codificação posicional" é adicionada para fornecer ao modelo algumas informações sobre a posição relativa dos tokens na sentença.
O vetor de codificação posicional é adicionado ao vetor de incorporação. Embeddings representam um token em um espaço d-dimensional onde tokens com significado semelhante estarão mais próximos uns dos outros. Mas os embeddings não codificam a posição relativa dos tokens em uma frase. Assim, após adicionar a codificação posicional, os tokens ficarão mais próximos uns dos outros com base na similaridade de seu significado e sua posição na sentença , no espaço d-dimensional.
A fórmula para calcular a codificação posicional é a seguinte:
\[\Large{PE_{(pos, 2i)} = \sin(pos / 10000^{2i / d_{model} })} \]
\[\Large{PE_{(pos, 2i+1)} = \cos(pos / 10000^{2i / d_{model} })} \]
def get_angles(pos, i, d_model):
angle_rates = 1 / np.power(10000, (2 * (i//2)) / np.float32(d_model))
return pos * angle_rates
def positional_encoding(position, d_model):
angle_rads = get_angles(np.arange(position)[:, np.newaxis],
np.arange(d_model)[np.newaxis, :],
d_model)
# apply sin to even indices in the array; 2i
angle_rads[:, 0::2] = np.sin(angle_rads[:, 0::2])
# apply cos to odd indices in the array; 2i+1
angle_rads[:, 1::2] = np.cos(angle_rads[:, 1::2])
pos_encoding = angle_rads[np.newaxis, ...]
return tf.cast(pos_encoding, dtype=tf.float32)
n, d = 2048, 512
pos_encoding = positional_encoding(n, d)
print(pos_encoding.shape)
pos_encoding = pos_encoding[0]
# Juggle the dimensions for the plot
pos_encoding = tf.reshape(pos_encoding, (n, d//2, 2))
pos_encoding = tf.transpose(pos_encoding, (2, 1, 0))
pos_encoding = tf.reshape(pos_encoding, (d, n))
plt.pcolormesh(pos_encoding, cmap='RdBu')
plt.ylabel('Depth')
plt.xlabel('Position')
plt.colorbar()
plt.show()
(1, 2048, 512)

Mascaramento
Mascare todos os tokens de bloco no lote de sequência. Ele garante que o modelo não trate o preenchimento como entrada. A máscara indica onde o valor de pad 0 está presente: ela emite um 1 nesses locais e um 0 caso contrário.
def create_padding_mask(seq):
seq = tf.cast(tf.math.equal(seq, 0), tf.float32)
# add extra dimensions to add the padding
# to the attention logits.
return seq[:, tf.newaxis, tf.newaxis, :] # (batch_size, 1, 1, seq_len)
x = tf.constant([[7, 6, 0, 0, 1], [1, 2, 3, 0, 0], [0, 0, 0, 4, 5]])
create_padding_mask(x)
<tf.Tensor: shape=(3, 1, 1, 5), dtype=float32, numpy=
array([[[[0., 0., 1., 1., 0.]]],
[[[0., 0., 0., 1., 1.]]],
[[[1., 1., 1., 0., 0.]]]], dtype=float32)>
A máscara de antecipação é usada para mascarar os tokens futuros em uma sequência. Em outras palavras, a máscara indica quais entradas não devem ser usadas.
Isso significa que para prever o terceiro token, apenas o primeiro e o segundo token serão usados. Da mesma forma para prever o quarto token, apenas o primeiro, segundo e terceiro tokens serão usados e assim por diante.
def create_look_ahead_mask(size):
mask = 1 - tf.linalg.band_part(tf.ones((size, size)), -1, 0)
return mask # (seq_len, seq_len)
x = tf.random.uniform((1, 3))
temp = create_look_ahead_mask(x.shape[1])
temp
<tf.Tensor: shape=(3, 3), dtype=float32, numpy=
array([[0., 1., 1.],
[0., 0., 1.],
[0., 0., 0.]], dtype=float32)>
Atenção ao produto escalado
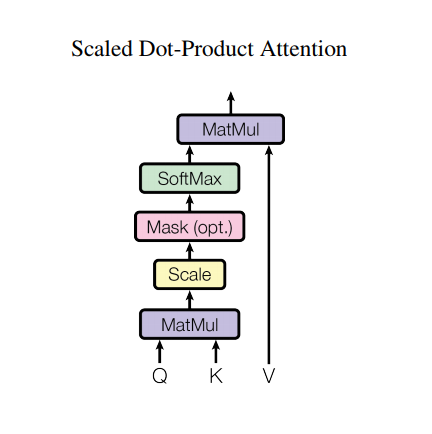
A função de atenção utilizada pelo transformador tem três entradas: Q (consulta), K (chave), V (valor). A equação usada para calcular os pesos de atenção é:
\[\Large{Attention(Q, K, V) = softmax_k\left(\frac{QK^T}{\sqrt{d_k} }\right) V} \]
A atenção do produto escalar é dimensionada por um fator de raiz quadrada da profundidade. Isso é feito porque para grandes valores de profundidade, o produto escalar cresce em magnitude empurrando a função softmax onde tem pequenos gradientes resultando em um softmax muito difícil.
Por exemplo, considere que Q e K têm média 0 e variância 1. A multiplicação de suas matrizes terá média 0 e variância dk . Portanto, a raiz quadrada de dk é usada para dimensionamento, para que você obtenha uma variação consistente, independentemente do valor de dk . Se a variação for muito baixa, a saída pode ser muito plana para otimizar efetivamente. Se a variação for muito alta, o softmax pode saturar na inicialização, dificultando o aprendizado.
A máscara é multiplicada por -1e9 (próximo ao infinito negativo). Isso é feito porque a máscara é somada com a multiplicação da matriz escalonada de Q e K e é aplicada imediatamente antes de um softmax. O objetivo é zerar essas células, e grandes entradas negativas para softmax são próximas de zero na saída.
def scaled_dot_product_attention(q, k, v, mask):
"""Calculate the attention weights.
q, k, v must have matching leading dimensions.
k, v must have matching penultimate dimension, i.e.: seq_len_k = seq_len_v.
The mask has different shapes depending on its type(padding or look ahead)
but it must be broadcastable for addition.
Args:
q: query shape == (..., seq_len_q, depth)
k: key shape == (..., seq_len_k, depth)
v: value shape == (..., seq_len_v, depth_v)
mask: Float tensor with shape broadcastable
to (..., seq_len_q, seq_len_k). Defaults to None.
Returns:
output, attention_weights
"""
matmul_qk = tf.matmul(q, k, transpose_b=True) # (..., seq_len_q, seq_len_k)
# scale matmul_qk
dk = tf.cast(tf.shape(k)[-1], tf.float32)
scaled_attention_logits = matmul_qk / tf.math.sqrt(dk)
# add the mask to the scaled tensor.
if mask is not None:
scaled_attention_logits += (mask * -1e9)
# softmax is normalized on the last axis (seq_len_k) so that the scores
# add up to 1.
attention_weights = tf.nn.softmax(scaled_attention_logits, axis=-1) # (..., seq_len_q, seq_len_k)
output = tf.matmul(attention_weights, v) # (..., seq_len_q, depth_v)
return output, attention_weights
Como a normalização softmax é feita em K, seus valores decidem a importância dada a Q.
A saída representa a multiplicação dos pesos de atenção e o vetor V (valor). Isso garante que os tokens nos quais você deseja se concentrar sejam mantidos como estão e os tokens irrelevantes serão eliminados.
def print_out(q, k, v):
temp_out, temp_attn = scaled_dot_product_attention(
q, k, v, None)
print('Attention weights are:')
print(temp_attn)
print('Output is:')
print(temp_out)
np.set_printoptions(suppress=True)
temp_k = tf.constant([[10, 0, 0],
[0, 10, 0],
[0, 0, 10],
[0, 0, 10]], dtype=tf.float32) # (4, 3)
temp_v = tf.constant([[1, 0],
[10, 0],
[100, 5],
[1000, 6]], dtype=tf.float32) # (4, 2)
# This `query` aligns with the second `key`,
# so the second `value` is returned.
temp_q = tf.constant([[0, 10, 0]], dtype=tf.float32) # (1, 3)
print_out(temp_q, temp_k, temp_v)
Attention weights are: tf.Tensor([[0. 1. 0. 0.]], shape=(1, 4), dtype=float32) Output is: tf.Tensor([[10. 0.]], shape=(1, 2), dtype=float32)
# This query aligns with a repeated key (third and fourth),
# so all associated values get averaged.
temp_q = tf.constant([[0, 0, 10]], dtype=tf.float32) # (1, 3)
print_out(temp_q, temp_k, temp_v)
Attention weights are: tf.Tensor([[0. 0. 0.5 0.5]], shape=(1, 4), dtype=float32) Output is: tf.Tensor([[550. 5.5]], shape=(1, 2), dtype=float32)
# This query aligns equally with the first and second key,
# so their values get averaged.
temp_q = tf.constant([[10, 10, 0]], dtype=tf.float32) # (1, 3)
print_out(temp_q, temp_k, temp_v)
Attention weights are: tf.Tensor([[0.5 0.5 0. 0. ]], shape=(1, 4), dtype=float32) Output is: tf.Tensor([[5.5 0. ]], shape=(1, 2), dtype=float32)
Passe todas as consultas juntas.
temp_q = tf.constant([[0, 0, 10],
[0, 10, 0],
[10, 10, 0]], dtype=tf.float32) # (3, 3)
print_out(temp_q, temp_k, temp_v)
Attention weights are: tf.Tensor( [[0. 0. 0.5 0.5] [0. 1. 0. 0. ] [0.5 0.5 0. 0. ]], shape=(3, 4), dtype=float32) Output is: tf.Tensor( [[550. 5.5] [ 10. 0. ] [ 5.5 0. ]], shape=(3, 2), dtype=float32)
Atenção de várias cabeças
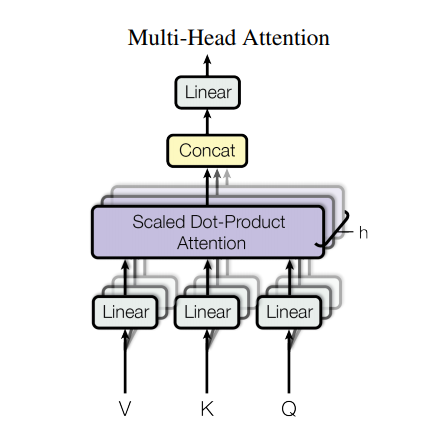
A atenção de várias cabeças consiste em quatro partes:
- Camadas lineares.
- Atenção de produto escalar escalado.
- Camada linear final.
Cada bloco de atenção de várias cabeças recebe três entradas; Q (consulta), K (chave), V (valor). Estes são colocados através de camadas lineares (Densa) antes da função de atenção multi-cabeça.
No diagrama acima (K,Q,V) são passados por camadas separadas lineares ( Dense ) para cada cabeça de atenção. Por simplicidade/eficiência, o código abaixo implementa isso usando uma única camada densa com num_heads vezes mais saídas. A saída é reorganizada para uma forma de (batch, num_heads, ...) antes de aplicar a função de atenção.
A função scaled_dot_product_attention definida acima é aplicada em uma única chamada, transmitida para eficiência. Uma máscara apropriada deve ser usada na etapa de atenção. A saída de atenção para cada cabeça é então concatenada (usando tf.transpose e tf.reshape ) e passa por uma camada Dense final.
Em vez de uma única cabeça de atenção, Q, K e V são divididos em várias cabeças porque permite que o modelo atenda conjuntamente a informações de diferentes subespaços de representação em diferentes posições. Após a divisão, cada cabeça tem uma dimensionalidade reduzida, de modo que o custo total de computação é o mesmo que uma atenção de cabeça única com dimensionalidade total.
class MultiHeadAttention(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads):
super(MultiHeadAttention, self).__init__()
self.num_heads = num_heads
self.d_model = d_model
assert d_model % self.num_heads == 0
self.depth = d_model // self.num_heads
self.wq = tf.keras.layers.Dense(d_model)
self.wk = tf.keras.layers.Dense(d_model)
self.wv = tf.keras.layers.Dense(d_model)
self.dense = tf.keras.layers.Dense(d_model)
def split_heads(self, x, batch_size):
"""Split the last dimension into (num_heads, depth).
Transpose the result such that the shape is (batch_size, num_heads, seq_len, depth)
"""
x = tf.reshape(x, (batch_size, -1, self.num_heads, self.depth))
return tf.transpose(x, perm=[0, 2, 1, 3])
def call(self, v, k, q, mask):
batch_size = tf.shape(q)[0]
q = self.wq(q) # (batch_size, seq_len, d_model)
k = self.wk(k) # (batch_size, seq_len, d_model)
v = self.wv(v) # (batch_size, seq_len, d_model)
q = self.split_heads(q, batch_size) # (batch_size, num_heads, seq_len_q, depth)
k = self.split_heads(k, batch_size) # (batch_size, num_heads, seq_len_k, depth)
v = self.split_heads(v, batch_size) # (batch_size, num_heads, seq_len_v, depth)
# scaled_attention.shape == (batch_size, num_heads, seq_len_q, depth)
# attention_weights.shape == (batch_size, num_heads, seq_len_q, seq_len_k)
scaled_attention, attention_weights = scaled_dot_product_attention(
q, k, v, mask)
scaled_attention = tf.transpose(scaled_attention, perm=[0, 2, 1, 3]) # (batch_size, seq_len_q, num_heads, depth)
concat_attention = tf.reshape(scaled_attention,
(batch_size, -1, self.d_model)) # (batch_size, seq_len_q, d_model)
output = self.dense(concat_attention) # (batch_size, seq_len_q, d_model)
return output, attention_weights
Crie uma camada MultiHeadAttention para experimentar. Em cada local na sequência, y , o MultiHeadAttention executa todas as 8 cabeças de atenção em todos os outros locais da sequência, retornando um novo vetor de mesmo comprimento em cada local.
temp_mha = MultiHeadAttention(d_model=512, num_heads=8)
y = tf.random.uniform((1, 60, 512)) # (batch_size, encoder_sequence, d_model)
out, attn = temp_mha(y, k=y, q=y, mask=None)
out.shape, attn.shape
(TensorShape([1, 60, 512]), TensorShape([1, 8, 60, 60]))
Rede de feed forward pontual
A rede de feed forward pontual consiste em duas camadas totalmente conectadas com uma ativação ReLU entre elas.
def point_wise_feed_forward_network(d_model, dff):
return tf.keras.Sequential([
tf.keras.layers.Dense(dff, activation='relu'), # (batch_size, seq_len, dff)
tf.keras.layers.Dense(d_model) # (batch_size, seq_len, d_model)
])
sample_ffn = point_wise_feed_forward_network(512, 2048)
sample_ffn(tf.random.uniform((64, 50, 512))).shape
TensorShape([64, 50, 512])
Codificador e decodificador
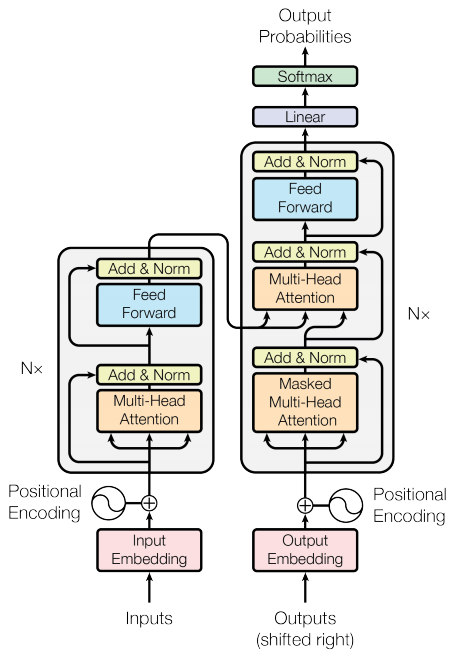
O modelo de transformador segue o mesmo padrão geral de um modelo de sequência a sequência padrão com atenção .
- A sentença de entrada é passada por
Ncamadas de codificador que geram uma saída para cada token na sequência. - O decodificador atende a saída do codificador e sua própria entrada (autoatenção) para prever a próxima palavra.
Camada do codificador
Cada camada do codificador consiste em subcamadas:
- Atenção multi-cabeça (com máscara de preenchimento)
- Redes de feed forward pontuais.
Cada uma dessas subcamadas tem uma conexão residual ao seu redor seguida por uma normalização de camada. As conexões residuais ajudam a evitar o problema do gradiente de fuga em redes profundas.
A saída de cada subcamada é LayerNorm(x + Sublayer(x)) . A normalização é feita no eixo d_model (último). Existem N camadas de codificador no transformador.
class EncoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(EncoderLayer, self).__init__()
self.mha = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
attn_output, _ = self.mha(x, x, x, mask) # (batch_size, input_seq_len, d_model)
attn_output = self.dropout1(attn_output, training=training)
out1 = self.layernorm1(x + attn_output) # (batch_size, input_seq_len, d_model)
ffn_output = self.ffn(out1) # (batch_size, input_seq_len, d_model)
ffn_output = self.dropout2(ffn_output, training=training)
out2 = self.layernorm2(out1 + ffn_output) # (batch_size, input_seq_len, d_model)
return out2
sample_encoder_layer = EncoderLayer(512, 8, 2048)
sample_encoder_layer_output = sample_encoder_layer(
tf.random.uniform((64, 43, 512)), False, None)
sample_encoder_layer_output.shape # (batch_size, input_seq_len, d_model)
TensorShape([64, 43, 512])
Camada do decodificador
Cada camada do decodificador consiste em subcamadas:
- Atenção de várias cabeças mascaradas (com máscara de antecipação e máscara de preenchimento)
- Atenção multi-cabeça (com máscara de preenchimento). V (valor) e K (chave) recebem a saída do encoder como entradas. Q (consulta) recebe a saída da subcamada de atenção multi-cabeças mascarada.
- Redes de feed forward pontuais
Cada uma dessas subcamadas tem uma conexão residual ao seu redor seguida por uma normalização de camada. A saída de cada subcamada é LayerNorm(x + Sublayer(x)) . A normalização é feita no eixo d_model (último).
Existem N camadas de descodificadores no transformador.
Como Q recebe a saída do primeiro bloco de atenção do decodificador e K recebe a saída do codificador, os pesos de atenção representam a importância dada à entrada do decodificador com base na saída do codificador. Em outras palavras, o decodificador prevê o próximo token observando a saída do codificador e atendendo automaticamente sua própria saída. Veja a demonstração acima na seção de atenção ao produto escalado.
class DecoderLayer(tf.keras.layers.Layer):
def __init__(self, d_model, num_heads, dff, rate=0.1):
super(DecoderLayer, self).__init__()
self.mha1 = MultiHeadAttention(d_model, num_heads)
self.mha2 = MultiHeadAttention(d_model, num_heads)
self.ffn = point_wise_feed_forward_network(d_model, dff)
self.layernorm1 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm2 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.layernorm3 = tf.keras.layers.LayerNormalization(epsilon=1e-6)
self.dropout1 = tf.keras.layers.Dropout(rate)
self.dropout2 = tf.keras.layers.Dropout(rate)
self.dropout3 = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
# enc_output.shape == (batch_size, input_seq_len, d_model)
attn1, attn_weights_block1 = self.mha1(x, x, x, look_ahead_mask) # (batch_size, target_seq_len, d_model)
attn1 = self.dropout1(attn1, training=training)
out1 = self.layernorm1(attn1 + x)
attn2, attn_weights_block2 = self.mha2(
enc_output, enc_output, out1, padding_mask) # (batch_size, target_seq_len, d_model)
attn2 = self.dropout2(attn2, training=training)
out2 = self.layernorm2(attn2 + out1) # (batch_size, target_seq_len, d_model)
ffn_output = self.ffn(out2) # (batch_size, target_seq_len, d_model)
ffn_output = self.dropout3(ffn_output, training=training)
out3 = self.layernorm3(ffn_output + out2) # (batch_size, target_seq_len, d_model)
return out3, attn_weights_block1, attn_weights_block2
sample_decoder_layer = DecoderLayer(512, 8, 2048)
sample_decoder_layer_output, _, _ = sample_decoder_layer(
tf.random.uniform((64, 50, 512)), sample_encoder_layer_output,
False, None, None)
sample_decoder_layer_output.shape # (batch_size, target_seq_len, d_model)
TensorShape([64, 50, 512])
Codificador
O Encoder é composto por:
- Incorporação de entrada
- Codificação posicional
- N camadas do codificador
A entrada é colocada por meio de uma incorporação que é somada à codificação posicional. A saída desta soma é a entrada para as camadas do codificador. A saída do codificador é a entrada para o decodificador.
class Encoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
maximum_position_encoding, rate=0.1):
super(Encoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(input_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding,
self.d_model)
self.enc_layers = [EncoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, training, mask):
seq_len = tf.shape(x)[1]
# adding embedding and position encoding.
x = self.embedding(x) # (batch_size, input_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x = self.enc_layers[i](x, training, mask)
return x # (batch_size, input_seq_len, d_model)
sample_encoder = Encoder(num_layers=2, d_model=512, num_heads=8,
dff=2048, input_vocab_size=8500,
maximum_position_encoding=10000)
temp_input = tf.random.uniform((64, 62), dtype=tf.int64, minval=0, maxval=200)
sample_encoder_output = sample_encoder(temp_input, training=False, mask=None)
print(sample_encoder_output.shape) # (batch_size, input_seq_len, d_model)
(64, 62, 512)
Decodificador
O Decoder é composto por:
- Incorporação de saída
- Codificação posicional
- N camadas do decodificador
O destino é colocado por meio de uma incorporação que é somada à codificação posicional. A saída desta soma é a entrada para as camadas do decodificador. A saída do decodificador é a entrada para a camada linear final.
class Decoder(tf.keras.layers.Layer):
def __init__(self, num_layers, d_model, num_heads, dff, target_vocab_size,
maximum_position_encoding, rate=0.1):
super(Decoder, self).__init__()
self.d_model = d_model
self.num_layers = num_layers
self.embedding = tf.keras.layers.Embedding(target_vocab_size, d_model)
self.pos_encoding = positional_encoding(maximum_position_encoding, d_model)
self.dec_layers = [DecoderLayer(d_model, num_heads, dff, rate)
for _ in range(num_layers)]
self.dropout = tf.keras.layers.Dropout(rate)
def call(self, x, enc_output, training,
look_ahead_mask, padding_mask):
seq_len = tf.shape(x)[1]
attention_weights = {}
x = self.embedding(x) # (batch_size, target_seq_len, d_model)
x *= tf.math.sqrt(tf.cast(self.d_model, tf.float32))
x += self.pos_encoding[:, :seq_len, :]
x = self.dropout(x, training=training)
for i in range(self.num_layers):
x, block1, block2 = self.dec_layers[i](x, enc_output, training,
look_ahead_mask, padding_mask)
attention_weights[f'decoder_layer{i+1}_block1'] = block1
attention_weights[f'decoder_layer{i+1}_block2'] = block2
# x.shape == (batch_size, target_seq_len, d_model)
return x, attention_weights
sample_decoder = Decoder(num_layers=2, d_model=512, num_heads=8,
dff=2048, target_vocab_size=8000,
maximum_position_encoding=5000)
temp_input = tf.random.uniform((64, 26), dtype=tf.int64, minval=0, maxval=200)
output, attn = sample_decoder(temp_input,
enc_output=sample_encoder_output,
training=False,
look_ahead_mask=None,
padding_mask=None)
output.shape, attn['decoder_layer2_block2'].shape
(TensorShape([64, 26, 512]), TensorShape([64, 8, 26, 62]))
Crie o transformador
O transformador consiste no codificador, decodificador e uma camada linear final. A saída do decodificador é a entrada para a camada linear e sua saída é retornada.
class Transformer(tf.keras.Model):
def __init__(self, num_layers, d_model, num_heads, dff, input_vocab_size,
target_vocab_size, pe_input, pe_target, rate=0.1):
super().__init__()
self.encoder = Encoder(num_layers, d_model, num_heads, dff,
input_vocab_size, pe_input, rate)
self.decoder = Decoder(num_layers, d_model, num_heads, dff,
target_vocab_size, pe_target, rate)
self.final_layer = tf.keras.layers.Dense(target_vocab_size)
def call(self, inputs, training):
# Keras models prefer if you pass all your inputs in the first argument
inp, tar = inputs
enc_padding_mask, look_ahead_mask, dec_padding_mask = self.create_masks(inp, tar)
enc_output = self.encoder(inp, training, enc_padding_mask) # (batch_size, inp_seq_len, d_model)
# dec_output.shape == (batch_size, tar_seq_len, d_model)
dec_output, attention_weights = self.decoder(
tar, enc_output, training, look_ahead_mask, dec_padding_mask)
final_output = self.final_layer(dec_output) # (batch_size, tar_seq_len, target_vocab_size)
return final_output, attention_weights
def create_masks(self, inp, tar):
# Encoder padding mask
enc_padding_mask = create_padding_mask(inp)
# Used in the 2nd attention block in the decoder.
# This padding mask is used to mask the encoder outputs.
dec_padding_mask = create_padding_mask(inp)
# Used in the 1st attention block in the decoder.
# It is used to pad and mask future tokens in the input received by
# the decoder.
look_ahead_mask = create_look_ahead_mask(tf.shape(tar)[1])
dec_target_padding_mask = create_padding_mask(tar)
look_ahead_mask = tf.maximum(dec_target_padding_mask, look_ahead_mask)
return enc_padding_mask, look_ahead_mask, dec_padding_mask
sample_transformer = Transformer(
num_layers=2, d_model=512, num_heads=8, dff=2048,
input_vocab_size=8500, target_vocab_size=8000,
pe_input=10000, pe_target=6000)
temp_input = tf.random.uniform((64, 38), dtype=tf.int64, minval=0, maxval=200)
temp_target = tf.random.uniform((64, 36), dtype=tf.int64, minval=0, maxval=200)
fn_out, _ = sample_transformer([temp_input, temp_target], training=False)
fn_out.shape # (batch_size, tar_seq_len, target_vocab_size)
TensorShape([64, 36, 8000])
Definir hiperparâmetros
Para manter este exemplo pequeno e relativamente rápido, os valores para num_layers, d_model, dff foram reduzidos.
O modelo base descrito no artigo utilizado: num_layers=6, d_model=512, dff=2048 .
num_layers = 4
d_model = 128
dff = 512
num_heads = 8
dropout_rate = 0.1
Otimizador
Use o otimizador Adam com um agendador de taxa de aprendizado personalizado de acordo com a fórmula do artigo .
\[\Large{lrate = d_{model}^{-0.5} * \min(step{\_}num^{-0.5}, step{\_}num \cdot warmup{\_}steps^{-1.5})}\]
class CustomSchedule(tf.keras.optimizers.schedules.LearningRateSchedule):
def __init__(self, d_model, warmup_steps=4000):
super(CustomSchedule, self).__init__()
self.d_model = d_model
self.d_model = tf.cast(self.d_model, tf.float32)
self.warmup_steps = warmup_steps
def __call__(self, step):
arg1 = tf.math.rsqrt(step)
arg2 = step * (self.warmup_steps ** -1.5)
return tf.math.rsqrt(self.d_model) * tf.math.minimum(arg1, arg2)
learning_rate = CustomSchedule(d_model)
optimizer = tf.keras.optimizers.Adam(learning_rate, beta_1=0.9, beta_2=0.98,
epsilon=1e-9)
temp_learning_rate_schedule = CustomSchedule(d_model)
plt.plot(temp_learning_rate_schedule(tf.range(40000, dtype=tf.float32)))
plt.ylabel("Learning Rate")
plt.xlabel("Train Step")
Text(0.5, 0, 'Train Step')

Perda e métricas
Como as sequências alvo são preenchidas, é importante aplicar uma máscara de preenchimento ao calcular a perda.
loss_object = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def loss_function(real, pred):
mask = tf.math.logical_not(tf.math.equal(real, 0))
loss_ = loss_object(real, pred)
mask = tf.cast(mask, dtype=loss_.dtype)
loss_ *= mask
return tf.reduce_sum(loss_)/tf.reduce_sum(mask)
def accuracy_function(real, pred):
accuracies = tf.equal(real, tf.argmax(pred, axis=2))
mask = tf.math.logical_not(tf.math.equal(real, 0))
accuracies = tf.math.logical_and(mask, accuracies)
accuracies = tf.cast(accuracies, dtype=tf.float32)
mask = tf.cast(mask, dtype=tf.float32)
return tf.reduce_sum(accuracies)/tf.reduce_sum(mask)
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.Mean(name='train_accuracy')
Treinamento e checkpoint
transformer = Transformer(
num_layers=num_layers,
d_model=d_model,
num_heads=num_heads,
dff=dff,
input_vocab_size=tokenizers.pt.get_vocab_size().numpy(),
target_vocab_size=tokenizers.en.get_vocab_size().numpy(),
pe_input=1000,
pe_target=1000,
rate=dropout_rate)
Crie o caminho do ponto de verificação e o gerenciador de ponto de verificação. Isso será usado para salvar pontos de verificação a cada n épocas.
checkpoint_path = "./checkpoints/train"
ckpt = tf.train.Checkpoint(transformer=transformer,
optimizer=optimizer)
ckpt_manager = tf.train.CheckpointManager(ckpt, checkpoint_path, max_to_keep=5)
# if a checkpoint exists, restore the latest checkpoint.
if ckpt_manager.latest_checkpoint:
ckpt.restore(ckpt_manager.latest_checkpoint)
print('Latest checkpoint restored!!')
O destino é dividido em tar_inp e tar_real. tar_inp é passado como entrada para o decodificador. tar_real é a mesma entrada deslocada em 1: Em cada local em tar_input , tar_real contém o próximo token que deve ser previsto.
Por exemplo, sentence = "SOS Um leão na selva está dormindo EOS"
tar_inp = "SOS Um leão na selva está dormindo"
tar_real = "Um leão na selva está dormindo EOS"
O transformador é um modelo auto-regressivo: ele faz previsões uma parte de cada vez e usa sua saída até o momento para decidir o que fazer em seguida.
Durante o treinamento, este exemplo usa forçar o professor (como no tutorial de geração de texto ). O forçamento do professor é passar a saída real para a próxima etapa de tempo, independentemente do que o modelo prevê na etapa de tempo atual.
À medida que o transformador prevê cada token, a autoatenção permite que ele examine os tokens anteriores na sequência de entrada para prever melhor o próximo token.
Para evitar que o modelo espie a saída esperada, o modelo usa uma máscara de antecipação.
EPOCHS = 20
# The @tf.function trace-compiles train_step into a TF graph for faster
# execution. The function specializes to the precise shape of the argument
# tensors. To avoid re-tracing due to the variable sequence lengths or variable
# batch sizes (the last batch is smaller), use input_signature to specify
# more generic shapes.
train_step_signature = [
tf.TensorSpec(shape=(None, None), dtype=tf.int64),
tf.TensorSpec(shape=(None, None), dtype=tf.int64),
]
@tf.function(input_signature=train_step_signature)
def train_step(inp, tar):
tar_inp = tar[:, :-1]
tar_real = tar[:, 1:]
with tf.GradientTape() as tape:
predictions, _ = transformer([inp, tar_inp],
training = True)
loss = loss_function(tar_real, predictions)
gradients = tape.gradient(loss, transformer.trainable_variables)
optimizer.apply_gradients(zip(gradients, transformer.trainable_variables))
train_loss(loss)
train_accuracy(accuracy_function(tar_real, predictions))
O português é usado como idioma de entrada e o inglês é o idioma de destino.
for epoch in range(EPOCHS):
start = time.time()
train_loss.reset_states()
train_accuracy.reset_states()
# inp -> portuguese, tar -> english
for (batch, (inp, tar)) in enumerate(train_batches):
train_step(inp, tar)
if batch % 50 == 0:
print(f'Epoch {epoch + 1} Batch {batch} Loss {train_loss.result():.4f} Accuracy {train_accuracy.result():.4f}')
if (epoch + 1) % 5 == 0:
ckpt_save_path = ckpt_manager.save()
print(f'Saving checkpoint for epoch {epoch+1} at {ckpt_save_path}')
print(f'Epoch {epoch + 1} Loss {train_loss.result():.4f} Accuracy {train_accuracy.result():.4f}')
print(f'Time taken for 1 epoch: {time.time() - start:.2f} secs\n')
Epoch 1 Batch 0 Loss 8.8600 Accuracy 0.0000 Epoch 1 Batch 50 Loss 8.7935 Accuracy 0.0082 Epoch 1 Batch 100 Loss 8.6902 Accuracy 0.0273 Epoch 1 Batch 150 Loss 8.5769 Accuracy 0.0335 Epoch 1 Batch 200 Loss 8.4387 Accuracy 0.0365 Epoch 1 Batch 250 Loss 8.2718 Accuracy 0.0386 Epoch 1 Batch 300 Loss 8.0845 Accuracy 0.0412 Epoch 1 Batch 350 Loss 7.8877 Accuracy 0.0481 Epoch 1 Batch 400 Loss 7.7002 Accuracy 0.0552 Epoch 1 Batch 450 Loss 7.5304 Accuracy 0.0629 Epoch 1 Batch 500 Loss 7.3857 Accuracy 0.0702 Epoch 1 Batch 550 Loss 7.2542 Accuracy 0.0776 Epoch 1 Batch 600 Loss 7.1327 Accuracy 0.0851 Epoch 1 Batch 650 Loss 7.0164 Accuracy 0.0930 Epoch 1 Batch 700 Loss 6.9088 Accuracy 0.1003 Epoch 1 Batch 750 Loss 6.8080 Accuracy 0.1070 Epoch 1 Batch 800 Loss 6.7173 Accuracy 0.1129 Epoch 1 Loss 6.7021 Accuracy 0.1139 Time taken for 1 epoch: 58.85 secs Epoch 2 Batch 0 Loss 5.2952 Accuracy 0.2221 Epoch 2 Batch 50 Loss 5.2513 Accuracy 0.2094 Epoch 2 Batch 100 Loss 5.2103 Accuracy 0.2140 Epoch 2 Batch 150 Loss 5.1780 Accuracy 0.2176 Epoch 2 Batch 200 Loss 5.1436 Accuracy 0.2218 Epoch 2 Batch 250 Loss 5.1173 Accuracy 0.2246 Epoch 2 Batch 300 Loss 5.0939 Accuracy 0.2269 Epoch 2 Batch 350 Loss 5.0719 Accuracy 0.2295 Epoch 2 Batch 400 Loss 5.0508 Accuracy 0.2318 Epoch 2 Batch 450 Loss 5.0308 Accuracy 0.2337 Epoch 2 Batch 500 Loss 5.0116 Accuracy 0.2353 Epoch 2 Batch 550 Loss 4.9897 Accuracy 0.2376 Epoch 2 Batch 600 Loss 4.9701 Accuracy 0.2394 Epoch 2 Batch 650 Loss 4.9543 Accuracy 0.2407 Epoch 2 Batch 700 Loss 4.9345 Accuracy 0.2425 Epoch 2 Batch 750 Loss 4.9169 Accuracy 0.2442 Epoch 2 Batch 800 Loss 4.9007 Accuracy 0.2455 Epoch 2 Loss 4.8988 Accuracy 0.2456 Time taken for 1 epoch: 45.69 secs Epoch 3 Batch 0 Loss 4.7236 Accuracy 0.2578 Epoch 3 Batch 50 Loss 4.5860 Accuracy 0.2705 Epoch 3 Batch 100 Loss 4.5758 Accuracy 0.2723 Epoch 3 Batch 150 Loss 4.5789 Accuracy 0.2728 Epoch 3 Batch 200 Loss 4.5699 Accuracy 0.2737 Epoch 3 Batch 250 Loss 4.5529 Accuracy 0.2753 Epoch 3 Batch 300 Loss 4.5462 Accuracy 0.2753 Epoch 3 Batch 350 Loss 4.5377 Accuracy 0.2762 Epoch 3 Batch 400 Loss 4.5301 Accuracy 0.2764 Epoch 3 Batch 450 Loss 4.5155 Accuracy 0.2776 Epoch 3 Batch 500 Loss 4.5036 Accuracy 0.2787 Epoch 3 Batch 550 Loss 4.4950 Accuracy 0.2794 Epoch 3 Batch 600 Loss 4.4860 Accuracy 0.2804 Epoch 3 Batch 650 Loss 4.4753 Accuracy 0.2814 Epoch 3 Batch 700 Loss 4.4643 Accuracy 0.2823 Epoch 3 Batch 750 Loss 4.4530 Accuracy 0.2837 Epoch 3 Batch 800 Loss 4.4401 Accuracy 0.2852 Epoch 3 Loss 4.4375 Accuracy 0.2855 Time taken for 1 epoch: 45.96 secs Epoch 4 Batch 0 Loss 3.9880 Accuracy 0.3285 Epoch 4 Batch 50 Loss 4.1496 Accuracy 0.3146 Epoch 4 Batch 100 Loss 4.1353 Accuracy 0.3146 Epoch 4 Batch 150 Loss 4.1263 Accuracy 0.3153 Epoch 4 Batch 200 Loss 4.1171 Accuracy 0.3165 Epoch 4 Batch 250 Loss 4.1144 Accuracy 0.3169 Epoch 4 Batch 300 Loss 4.0976 Accuracy 0.3190 Epoch 4 Batch 350 Loss 4.0848 Accuracy 0.3206 Epoch 4 Batch 400 Loss 4.0703 Accuracy 0.3228 Epoch 4 Batch 450 Loss 4.0569 Accuracy 0.3247 Epoch 4 Batch 500 Loss 4.0429 Accuracy 0.3265 Epoch 4 Batch 550 Loss 4.0231 Accuracy 0.3291 Epoch 4 Batch 600 Loss 4.0075 Accuracy 0.3311 Epoch 4 Batch 650 Loss 3.9933 Accuracy 0.3331 Epoch 4 Batch 700 Loss 3.9778 Accuracy 0.3353 Epoch 4 Batch 750 Loss 3.9625 Accuracy 0.3375 Epoch 4 Batch 800 Loss 3.9505 Accuracy 0.3393 Epoch 4 Loss 3.9483 Accuracy 0.3397 Time taken for 1 epoch: 45.59 secs Epoch 5 Batch 0 Loss 3.7342 Accuracy 0.3712 Epoch 5 Batch 50 Loss 3.5723 Accuracy 0.3851 Epoch 5 Batch 100 Loss 3.5656 Accuracy 0.3861 Epoch 5 Batch 150 Loss 3.5706 Accuracy 0.3857 Epoch 5 Batch 200 Loss 3.5701 Accuracy 0.3863 Epoch 5 Batch 250 Loss 3.5621 Accuracy 0.3877 Epoch 5 Batch 300 Loss 3.5527 Accuracy 0.3887 Epoch 5 Batch 350 Loss 3.5429 Accuracy 0.3904 Epoch 5 Batch 400 Loss 3.5318 Accuracy 0.3923 Epoch 5 Batch 450 Loss 3.5238 Accuracy 0.3937 Epoch 5 Batch 500 Loss 3.5141 Accuracy 0.3949 Epoch 5 Batch 550 Loss 3.5066 Accuracy 0.3958 Epoch 5 Batch 600 Loss 3.4956 Accuracy 0.3974 Epoch 5 Batch 650 Loss 3.4876 Accuracy 0.3986 Epoch 5 Batch 700 Loss 3.4788 Accuracy 0.4000 Epoch 5 Batch 750 Loss 3.4676 Accuracy 0.4014 Epoch 5 Batch 800 Loss 3.4590 Accuracy 0.4027 Saving checkpoint for epoch 5 at ./checkpoints/train/ckpt-1 Epoch 5 Loss 3.4583 Accuracy 0.4029 Time taken for 1 epoch: 46.04 secs Epoch 6 Batch 0 Loss 3.0131 Accuracy 0.4610 Epoch 6 Batch 50 Loss 3.1403 Accuracy 0.4404 Epoch 6 Batch 100 Loss 3.1320 Accuracy 0.4422 Epoch 6 Batch 150 Loss 3.1314 Accuracy 0.4425 Epoch 6 Batch 200 Loss 3.1450 Accuracy 0.4411 Epoch 6 Batch 250 Loss 3.1438 Accuracy 0.4405 Epoch 6 Batch 300 Loss 3.1306 Accuracy 0.4424 Epoch 6 Batch 350 Loss 3.1161 Accuracy 0.4445 Epoch 6 Batch 400 Loss 3.1097 Accuracy 0.4453 Epoch 6 Batch 450 Loss 3.0983 Accuracy 0.4469 Epoch 6 Batch 500 Loss 3.0900 Accuracy 0.4483 Epoch 6 Batch 550 Loss 3.0816 Accuracy 0.4496 Epoch 6 Batch 600 Loss 3.0740 Accuracy 0.4507 Epoch 6 Batch 650 Loss 3.0695 Accuracy 0.4514 Epoch 6 Batch 700 Loss 3.0602 Accuracy 0.4528 Epoch 6 Batch 750 Loss 3.0528 Accuracy 0.4539 Epoch 6 Batch 800 Loss 3.0436 Accuracy 0.4553 Epoch 6 Loss 3.0425 Accuracy 0.4554 Time taken for 1 epoch: 46.13 secs Epoch 7 Batch 0 Loss 2.7147 Accuracy 0.4940 Epoch 7 Batch 50 Loss 2.7671 Accuracy 0.4863 Epoch 7 Batch 100 Loss 2.7369 Accuracy 0.4934 Epoch 7 Batch 150 Loss 2.7562 Accuracy 0.4909 Epoch 7 Batch 200 Loss 2.7441 Accuracy 0.4926 Epoch 7 Batch 250 Loss 2.7464 Accuracy 0.4929 Epoch 7 Batch 300 Loss 2.7430 Accuracy 0.4932 Epoch 7 Batch 350 Loss 2.7342 Accuracy 0.4944 Epoch 7 Batch 400 Loss 2.7271 Accuracy 0.4954 Epoch 7 Batch 450 Loss 2.7215 Accuracy 0.4963 Epoch 7 Batch 500 Loss 2.7157 Accuracy 0.4972 Epoch 7 Batch 550 Loss 2.7123 Accuracy 0.4978 Epoch 7 Batch 600 Loss 2.7071 Accuracy 0.4985 Epoch 7 Batch 650 Loss 2.7038 Accuracy 0.4990 Epoch 7 Batch 700 Loss 2.6979 Accuracy 0.5002 Epoch 7 Batch 750 Loss 2.6946 Accuracy 0.5007 Epoch 7 Batch 800 Loss 2.6923 Accuracy 0.5013 Epoch 7 Loss 2.6913 Accuracy 0.5015 Time taken for 1 epoch: 46.02 secs Epoch 8 Batch 0 Loss 2.3681 Accuracy 0.5459 Epoch 8 Batch 50 Loss 2.4812 Accuracy 0.5260 Epoch 8 Batch 100 Loss 2.4682 Accuracy 0.5294 Epoch 8 Batch 150 Loss 2.4743 Accuracy 0.5287 Epoch 8 Batch 200 Loss 2.4625 Accuracy 0.5303 Epoch 8 Batch 250 Loss 2.4627 Accuracy 0.5303 Epoch 8 Batch 300 Loss 2.4624 Accuracy 0.5308 Epoch 8 Batch 350 Loss 2.4586 Accuracy 0.5314 Epoch 8 Batch 400 Loss 2.4532 Accuracy 0.5324 Epoch 8 Batch 450 Loss 2.4530 Accuracy 0.5326 Epoch 8 Batch 500 Loss 2.4508 Accuracy 0.5330 Epoch 8 Batch 550 Loss 2.4481 Accuracy 0.5338 Epoch 8 Batch 600 Loss 2.4455 Accuracy 0.5343 Epoch 8 Batch 650 Loss 2.4427 Accuracy 0.5348 Epoch 8 Batch 700 Loss 2.4399 Accuracy 0.5352 Epoch 8 Batch 750 Loss 2.4392 Accuracy 0.5353 Epoch 8 Batch 800 Loss 2.4367 Accuracy 0.5358 Epoch 8 Loss 2.4357 Accuracy 0.5360 Time taken for 1 epoch: 45.31 secs Epoch 9 Batch 0 Loss 2.1790 Accuracy 0.5595 Epoch 9 Batch 50 Loss 2.2201 Accuracy 0.5676 Epoch 9 Batch 100 Loss 2.2420 Accuracy 0.5629 Epoch 9 Batch 150 Loss 2.2444 Accuracy 0.5623 Epoch 9 Batch 200 Loss 2.2535 Accuracy 0.5610 Epoch 9 Batch 250 Loss 2.2562 Accuracy 0.5603 Epoch 9 Batch 300 Loss 2.2572 Accuracy 0.5603 Epoch 9 Batch 350 Loss 2.2646 Accuracy 0.5592 Epoch 9 Batch 400 Loss 2.2624 Accuracy 0.5597 Epoch 9 Batch 450 Loss 2.2595 Accuracy 0.5601 Epoch 9 Batch 500 Loss 2.2598 Accuracy 0.5600 Epoch 9 Batch 550 Loss 2.2590 Accuracy 0.5602 Epoch 9 Batch 600 Loss 2.2563 Accuracy 0.5607 Epoch 9 Batch 650 Loss 2.2578 Accuracy 0.5606 Epoch 9 Batch 700 Loss 2.2550 Accuracy 0.5611 Epoch 9 Batch 750 Loss 2.2536 Accuracy 0.5614 Epoch 9 Batch 800 Loss 2.2511 Accuracy 0.5618 Epoch 9 Loss 2.2503 Accuracy 0.5620 Time taken for 1 epoch: 44.87 secs Epoch 10 Batch 0 Loss 2.0921 Accuracy 0.5928 Epoch 10 Batch 50 Loss 2.1196 Accuracy 0.5788 Epoch 10 Batch 100 Loss 2.0969 Accuracy 0.5828 Epoch 10 Batch 150 Loss 2.0954 Accuracy 0.5834 Epoch 10 Batch 200 Loss 2.0965 Accuracy 0.5827 Epoch 10 Batch 250 Loss 2.1029 Accuracy 0.5822 Epoch 10 Batch 300 Loss 2.0999 Accuracy 0.5827 Epoch 10 Batch 350 Loss 2.1007 Accuracy 0.5825 Epoch 10 Batch 400 Loss 2.1011 Accuracy 0.5825 Epoch 10 Batch 450 Loss 2.1020 Accuracy 0.5826 Epoch 10 Batch 500 Loss 2.0977 Accuracy 0.5831 Epoch 10 Batch 550 Loss 2.0984 Accuracy 0.5831 Epoch 10 Batch 600 Loss 2.0985 Accuracy 0.5832 Epoch 10 Batch 650 Loss 2.1006 Accuracy 0.5830 Epoch 10 Batch 700 Loss 2.1017 Accuracy 0.5829 Epoch 10 Batch 750 Loss 2.1058 Accuracy 0.5825 Epoch 10 Batch 800 Loss 2.1059 Accuracy 0.5825 Saving checkpoint for epoch 10 at ./checkpoints/train/ckpt-2 Epoch 10 Loss 2.1060 Accuracy 0.5825 Time taken for 1 epoch: 45.06 secs Epoch 11 Batch 0 Loss 2.1150 Accuracy 0.5829 Epoch 11 Batch 50 Loss 1.9694 Accuracy 0.6017 Epoch 11 Batch 100 Loss 1.9746 Accuracy 0.6007 Epoch 11 Batch 150 Loss 1.9787 Accuracy 0.5996 Epoch 11 Batch 200 Loss 1.9798 Accuracy 0.5992 Epoch 11 Batch 250 Loss 1.9781 Accuracy 0.5998 Epoch 11 Batch 300 Loss 1.9772 Accuracy 0.5999 Epoch 11 Batch 350 Loss 1.9807 Accuracy 0.5995 Epoch 11 Batch 400 Loss 1.9836 Accuracy 0.5990 Epoch 11 Batch 450 Loss 1.9854 Accuracy 0.5986 Epoch 11 Batch 500 Loss 1.9832 Accuracy 0.5993 Epoch 11 Batch 550 Loss 1.9828 Accuracy 0.5993 Epoch 11 Batch 600 Loss 1.9812 Accuracy 0.5996 Epoch 11 Batch 650 Loss 1.9822 Accuracy 0.5996 Epoch 11 Batch 700 Loss 1.9825 Accuracy 0.5997 Epoch 11 Batch 750 Loss 1.9848 Accuracy 0.5994 Epoch 11 Batch 800 Loss 1.9883 Accuracy 0.5990 Epoch 11 Loss 1.9891 Accuracy 0.5989 Time taken for 1 epoch: 44.58 secs Epoch 12 Batch 0 Loss 1.8522 Accuracy 0.6168 Epoch 12 Batch 50 Loss 1.8462 Accuracy 0.6167 Epoch 12 Batch 100 Loss 1.8434 Accuracy 0.6191 Epoch 12 Batch 150 Loss 1.8506 Accuracy 0.6189 Epoch 12 Batch 200 Loss 1.8582 Accuracy 0.6178 Epoch 12 Batch 250 Loss 1.8732 Accuracy 0.6155 Epoch 12 Batch 300 Loss 1.8725 Accuracy 0.6159 Epoch 12 Batch 350 Loss 1.8708 Accuracy 0.6163 Epoch 12 Batch 400 Loss 1.8696 Accuracy 0.6164 Epoch 12 Batch 450 Loss 1.8696 Accuracy 0.6168 Epoch 12 Batch 500 Loss 1.8748 Accuracy 0.6160 Epoch 12 Batch 550 Loss 1.8793 Accuracy 0.6153 Epoch 12 Batch 600 Loss 1.8826 Accuracy 0.6149 Epoch 12 Batch 650 Loss 1.8851 Accuracy 0.6145 Epoch 12 Batch 700 Loss 1.8878 Accuracy 0.6143 Epoch 12 Batch 750 Loss 1.8881 Accuracy 0.6142 Epoch 12 Batch 800 Loss 1.8906 Accuracy 0.6139 Epoch 12 Loss 1.8919 Accuracy 0.6137 Time taken for 1 epoch: 44.87 secs Epoch 13 Batch 0 Loss 1.7038 Accuracy 0.6438 Epoch 13 Batch 50 Loss 1.7587 Accuracy 0.6309 Epoch 13 Batch 100 Loss 1.7641 Accuracy 0.6313 Epoch 13 Batch 150 Loss 1.7736 Accuracy 0.6299 Epoch 13 Batch 200 Loss 1.7743 Accuracy 0.6299 Epoch 13 Batch 250 Loss 1.7787 Accuracy 0.6293 Epoch 13 Batch 300 Loss 1.7820 Accuracy 0.6286 Epoch 13 Batch 350 Loss 1.7890 Accuracy 0.6276 Epoch 13 Batch 400 Loss 1.7963 Accuracy 0.6264 Epoch 13 Batch 450 Loss 1.7984 Accuracy 0.6261 Epoch 13 Batch 500 Loss 1.8014 Accuracy 0.6256 Epoch 13 Batch 550 Loss 1.8018 Accuracy 0.6255 Epoch 13 Batch 600 Loss 1.8033 Accuracy 0.6253 Epoch 13 Batch 650 Loss 1.8057 Accuracy 0.6250 Epoch 13 Batch 700 Loss 1.8100 Accuracy 0.6246 Epoch 13 Batch 750 Loss 1.8123 Accuracy 0.6244 Epoch 13 Batch 800 Loss 1.8123 Accuracy 0.6246 Epoch 13 Loss 1.8123 Accuracy 0.6246 Time taken for 1 epoch: 45.34 secs Epoch 14 Batch 0 Loss 2.0031 Accuracy 0.5889 Epoch 14 Batch 50 Loss 1.6906 Accuracy 0.6432 Epoch 14 Batch 100 Loss 1.7077 Accuracy 0.6407 Epoch 14 Batch 150 Loss 1.7113 Accuracy 0.6401 Epoch 14 Batch 200 Loss 1.7192 Accuracy 0.6382 Epoch 14 Batch 250 Loss 1.7220 Accuracy 0.6377 Epoch 14 Batch 300 Loss 1.7222 Accuracy 0.6376 Epoch 14 Batch 350 Loss 1.7250 Accuracy 0.6372 Epoch 14 Batch 400 Loss 1.7220 Accuracy 0.6377 Epoch 14 Batch 450 Loss 1.7209 Accuracy 0.6380 Epoch 14 Batch 500 Loss 1.7248 Accuracy 0.6377 Epoch 14 Batch 550 Loss 1.7264 Accuracy 0.6374 Epoch 14 Batch 600 Loss 1.7283 Accuracy 0.6373 Epoch 14 Batch 650 Loss 1.7307 Accuracy 0.6372 Epoch 14 Batch 700 Loss 1.7334 Accuracy 0.6367 Epoch 14 Batch 750 Loss 1.7372 Accuracy 0.6362 Epoch 14 Batch 800 Loss 1.7398 Accuracy 0.6358 Epoch 14 Loss 1.7396 Accuracy 0.6358 Time taken for 1 epoch: 46.00 secs Epoch 15 Batch 0 Loss 1.6520 Accuracy 0.6395 Epoch 15 Batch 50 Loss 1.6565 Accuracy 0.6480 Epoch 15 Batch 100 Loss 1.6396 Accuracy 0.6495 Epoch 15 Batch 150 Loss 1.6473 Accuracy 0.6488 Epoch 15 Batch 200 Loss 1.6486 Accuracy 0.6488 Epoch 15 Batch 250 Loss 1.6539 Accuracy 0.6483 Epoch 15 Batch 300 Loss 1.6595 Accuracy 0.6473 Epoch 15 Batch 350 Loss 1.6591 Accuracy 0.6472 Epoch 15 Batch 400 Loss 1.6584 Accuracy 0.6470 Epoch 15 Batch 450 Loss 1.6614 Accuracy 0.6467 Epoch 15 Batch 500 Loss 1.6617 Accuracy 0.6468 Epoch 15 Batch 550 Loss 1.6648 Accuracy 0.6464 Epoch 15 Batch 600 Loss 1.6680 Accuracy 0.6459 Epoch 15 Batch 650 Loss 1.6688 Accuracy 0.6459 Epoch 15 Batch 700 Loss 1.6714 Accuracy 0.6456 Epoch 15 Batch 750 Loss 1.6756 Accuracy 0.6450 Epoch 15 Batch 800 Loss 1.6790 Accuracy 0.6445 Saving checkpoint for epoch 15 at ./checkpoints/train/ckpt-3 Epoch 15 Loss 1.6786 Accuracy 0.6446 Time taken for 1 epoch: 46.56 secs Epoch 16 Batch 0 Loss 1.5922 Accuracy 0.6547 Epoch 16 Batch 50 Loss 1.5757 Accuracy 0.6599 Epoch 16 Batch 100 Loss 1.5844 Accuracy 0.6591 Epoch 16 Batch 150 Loss 1.5927 Accuracy 0.6579 Epoch 16 Batch 200 Loss 1.5944 Accuracy 0.6575 Epoch 16 Batch 250 Loss 1.5972 Accuracy 0.6571 Epoch 16 Batch 300 Loss 1.5999 Accuracy 0.6568 Epoch 16 Batch 350 Loss 1.6029 Accuracy 0.6561 Epoch 16 Batch 400 Loss 1.6053 Accuracy 0.6558 Epoch 16 Batch 450 Loss 1.6056 Accuracy 0.6557 Epoch 16 Batch 500 Loss 1.6094 Accuracy 0.6553 Epoch 16 Batch 550 Loss 1.6125 Accuracy 0.6548 Epoch 16 Batch 600 Loss 1.6149 Accuracy 0.6543 Epoch 16 Batch 650 Loss 1.6171 Accuracy 0.6541 Epoch 16 Batch 700 Loss 1.6201 Accuracy 0.6537 Epoch 16 Batch 750 Loss 1.6229 Accuracy 0.6533 Epoch 16 Batch 800 Loss 1.6252 Accuracy 0.6531 Epoch 16 Loss 1.6253 Accuracy 0.6531 Time taken for 1 epoch: 45.84 secs Epoch 17 Batch 0 Loss 1.6605 Accuracy 0.6482 Epoch 17 Batch 50 Loss 1.5219 Accuracy 0.6692 Epoch 17 Batch 100 Loss 1.5292 Accuracy 0.6681 Epoch 17 Batch 150 Loss 1.5324 Accuracy 0.6674 Epoch 17 Batch 200 Loss 1.5379 Accuracy 0.6666 Epoch 17 Batch 250 Loss 1.5416 Accuracy 0.6656 Epoch 17 Batch 300 Loss 1.5480 Accuracy 0.6646 Epoch 17 Batch 350 Loss 1.5522 Accuracy 0.6639 Epoch 17 Batch 400 Loss 1.5556 Accuracy 0.6634 Epoch 17 Batch 450 Loss 1.5567 Accuracy 0.6634 Epoch 17 Batch 500 Loss 1.5606 Accuracy 0.6629 Epoch 17 Batch 550 Loss 1.5641 Accuracy 0.6624 Epoch 17 Batch 600 Loss 1.5659 Accuracy 0.6621 Epoch 17 Batch 650 Loss 1.5685 Accuracy 0.6618 Epoch 17 Batch 700 Loss 1.5716 Accuracy 0.6614 Epoch 17 Batch 750 Loss 1.5748 Accuracy 0.6610 Epoch 17 Batch 800 Loss 1.5764 Accuracy 0.6609 Epoch 17 Loss 1.5773 Accuracy 0.6607 Time taken for 1 epoch: 45.01 secs Epoch 18 Batch 0 Loss 1.5065 Accuracy 0.6638 Epoch 18 Batch 50 Loss 1.4985 Accuracy 0.6713 Epoch 18 Batch 100 Loss 1.4979 Accuracy 0.6721 Epoch 18 Batch 150 Loss 1.5022 Accuracy 0.6712 Epoch 18 Batch 200 Loss 1.5012 Accuracy 0.6714 Epoch 18 Batch 250 Loss 1.5000 Accuracy 0.6716 Epoch 18 Batch 300 Loss 1.5044 Accuracy 0.6710 Epoch 18 Batch 350 Loss 1.5019 Accuracy 0.6719 Epoch 18 Batch 400 Loss 1.5053 Accuracy 0.6713 Epoch 18 Batch 450 Loss 1.5091 Accuracy 0.6707 Epoch 18 Batch 500 Loss 1.5131 Accuracy 0.6701 Epoch 18 Batch 550 Loss 1.5152 Accuracy 0.6698 Epoch 18 Batch 600 Loss 1.5177 Accuracy 0.6694 Epoch 18 Batch 650 Loss 1.5211 Accuracy 0.6689 Epoch 18 Batch 700 Loss 1.5246 Accuracy 0.6684 Epoch 18 Batch 750 Loss 1.5251 Accuracy 0.6685 Epoch 18 Batch 800 Loss 1.5302 Accuracy 0.6678 Epoch 18 Loss 1.5314 Accuracy 0.6675 Time taken for 1 epoch: 44.91 secs Epoch 19 Batch 0 Loss 1.2939 Accuracy 0.7080 Epoch 19 Batch 50 Loss 1.4311 Accuracy 0.6839 Epoch 19 Batch 100 Loss 1.4424 Accuracy 0.6812 Epoch 19 Batch 150 Loss 1.4520 Accuracy 0.6799 Epoch 19 Batch 200 Loss 1.4604 Accuracy 0.6782 Epoch 19 Batch 250 Loss 1.4606 Accuracy 0.6783 Epoch 19 Batch 300 Loss 1.4627 Accuracy 0.6783 Epoch 19 Batch 350 Loss 1.4664 Accuracy 0.6777 Epoch 19 Batch 400 Loss 1.4720 Accuracy 0.6769 Epoch 19 Batch 450 Loss 1.4742 Accuracy 0.6764 Epoch 19 Batch 500 Loss 1.4772 Accuracy 0.6760 Epoch 19 Batch 550 Loss 1.4784 Accuracy 0.6759 Epoch 19 Batch 600 Loss 1.4807 Accuracy 0.6756 Epoch 19 Batch 650 Loss 1.4846 Accuracy 0.6750 Epoch 19 Batch 700 Loss 1.4877 Accuracy 0.6747 Epoch 19 Batch 750 Loss 1.4890 Accuracy 0.6745 Epoch 19 Batch 800 Loss 1.4918 Accuracy 0.6741 Epoch 19 Loss 1.4924 Accuracy 0.6740 Time taken for 1 epoch: 45.24 secs Epoch 20 Batch 0 Loss 1.3994 Accuracy 0.6883 Epoch 20 Batch 50 Loss 1.3894 Accuracy 0.6911 Epoch 20 Batch 100 Loss 1.4050 Accuracy 0.6889 Epoch 20 Batch 150 Loss 1.4108 Accuracy 0.6883 Epoch 20 Batch 200 Loss 1.4111 Accuracy 0.6876 Epoch 20 Batch 250 Loss 1.4121 Accuracy 0.6871 Epoch 20 Batch 300 Loss 1.4179 Accuracy 0.6859 Epoch 20 Batch 350 Loss 1.4182 Accuracy 0.6857 Epoch 20 Batch 400 Loss 1.4212 Accuracy 0.6851 Epoch 20 Batch 450 Loss 1.4282 Accuracy 0.6837 Epoch 20 Batch 500 Loss 1.4296 Accuracy 0.6833 Epoch 20 Batch 550 Loss 1.4343 Accuracy 0.6826 Epoch 20 Batch 600 Loss 1.4375 Accuracy 0.6822 Epoch 20 Batch 650 Loss 1.4413 Accuracy 0.6817 Epoch 20 Batch 700 Loss 1.4464 Accuracy 0.6809 Epoch 20 Batch 750 Loss 1.4491 Accuracy 0.6805 Epoch 20 Batch 800 Loss 1.4530 Accuracy 0.6799 Saving checkpoint for epoch 20 at ./checkpoints/train/ckpt-4 Epoch 20 Loss 1.4533 Accuracy 0.6799 Time taken for 1 epoch: 45.84 secs
Executar inferência
As etapas a seguir são usadas para inferência:
- Codifique a frase de entrada usando o tokenizer português (
tokenizers.pt). Esta é a entrada do codificador. - A entrada do decodificador é inicializada com o token
[START]. - Calcule as máscaras de preenchimento e as máscaras de antecipação.
- O
decoderentão emite as previsões observando aencoder outpute sua própria saída (autoatenção). - Concatene o token previsto para a entrada do decodificador e passe-o para o decodificador.
- Nesta abordagem, o decodificador prevê o próximo token com base nos tokens anteriores que ele previu.
class Translator(tf.Module):
def __init__(self, tokenizers, transformer):
self.tokenizers = tokenizers
self.transformer = transformer
def __call__(self, sentence, max_length=20):
# input sentence is portuguese, hence adding the start and end token
assert isinstance(sentence, tf.Tensor)
if len(sentence.shape) == 0:
sentence = sentence[tf.newaxis]
sentence = self.tokenizers.pt.tokenize(sentence).to_tensor()
encoder_input = sentence
# as the target is english, the first token to the transformer should be the
# english start token.
start_end = self.tokenizers.en.tokenize([''])[0]
start = start_end[0][tf.newaxis]
end = start_end[1][tf.newaxis]
# `tf.TensorArray` is required here (instead of a python list) so that the
# dynamic-loop can be traced by `tf.function`.
output_array = tf.TensorArray(dtype=tf.int64, size=0, dynamic_size=True)
output_array = output_array.write(0, start)
for i in tf.range(max_length):
output = tf.transpose(output_array.stack())
predictions, _ = self.transformer([encoder_input, output], training=False)
# select the last token from the seq_len dimension
predictions = predictions[:, -1:, :] # (batch_size, 1, vocab_size)
predicted_id = tf.argmax(predictions, axis=-1)
# concatentate the predicted_id to the output which is given to the decoder
# as its input.
output_array = output_array.write(i+1, predicted_id[0])
if predicted_id == end:
break
output = tf.transpose(output_array.stack())
# output.shape (1, tokens)
text = tokenizers.en.detokenize(output)[0] # shape: ()
tokens = tokenizers.en.lookup(output)[0]
# `tf.function` prevents us from using the attention_weights that were
# calculated on the last iteration of the loop. So recalculate them outside
# the loop.
_, attention_weights = self.transformer([encoder_input, output[:,:-1]], training=False)
return text, tokens, attention_weights
Crie uma instância dessa classe Translator e experimente-a algumas vezes:
translator = Translator(tokenizers, transformer)
def print_translation(sentence, tokens, ground_truth):
print(f'{"Input:":15s}: {sentence}')
print(f'{"Prediction":15s}: {tokens.numpy().decode("utf-8")}')
print(f'{"Ground truth":15s}: {ground_truth}')
sentence = "este é um problema que temos que resolver."
ground_truth = "this is a problem we have to solve ."
translated_text, translated_tokens, attention_weights = translator(
tf.constant(sentence))
print_translation(sentence, translated_text, ground_truth)
Input: : este é um problema que temos que resolver. Prediction : this is a problem that we have to solve . Ground truth : this is a problem we have to solve .
sentence = "os meus vizinhos ouviram sobre esta ideia."
ground_truth = "and my neighboring homes heard about this idea ."
translated_text, translated_tokens, attention_weights = translator(
tf.constant(sentence))
print_translation(sentence, translated_text, ground_truth)
Input: : os meus vizinhos ouviram sobre esta ideia. Prediction : my neighbors heard about this idea . Ground truth : and my neighboring homes heard about this idea .
sentence = "vou então muito rapidamente partilhar convosco algumas histórias de algumas coisas mágicas que aconteceram."
ground_truth = "so i \'ll just share with you some stories very quickly of some magical things that have happened ."
translated_text, translated_tokens, attention_weights = translator(
tf.constant(sentence))
print_translation(sentence, translated_text, ground_truth)
Input: : vou então muito rapidamente partilhar convosco algumas histórias de algumas coisas mágicas que aconteceram. Prediction : so i ' m going to share with you a few stories of some magic things that have happened . Ground truth : so i 'll just share with you some stories very quickly of some magical things that have happened .
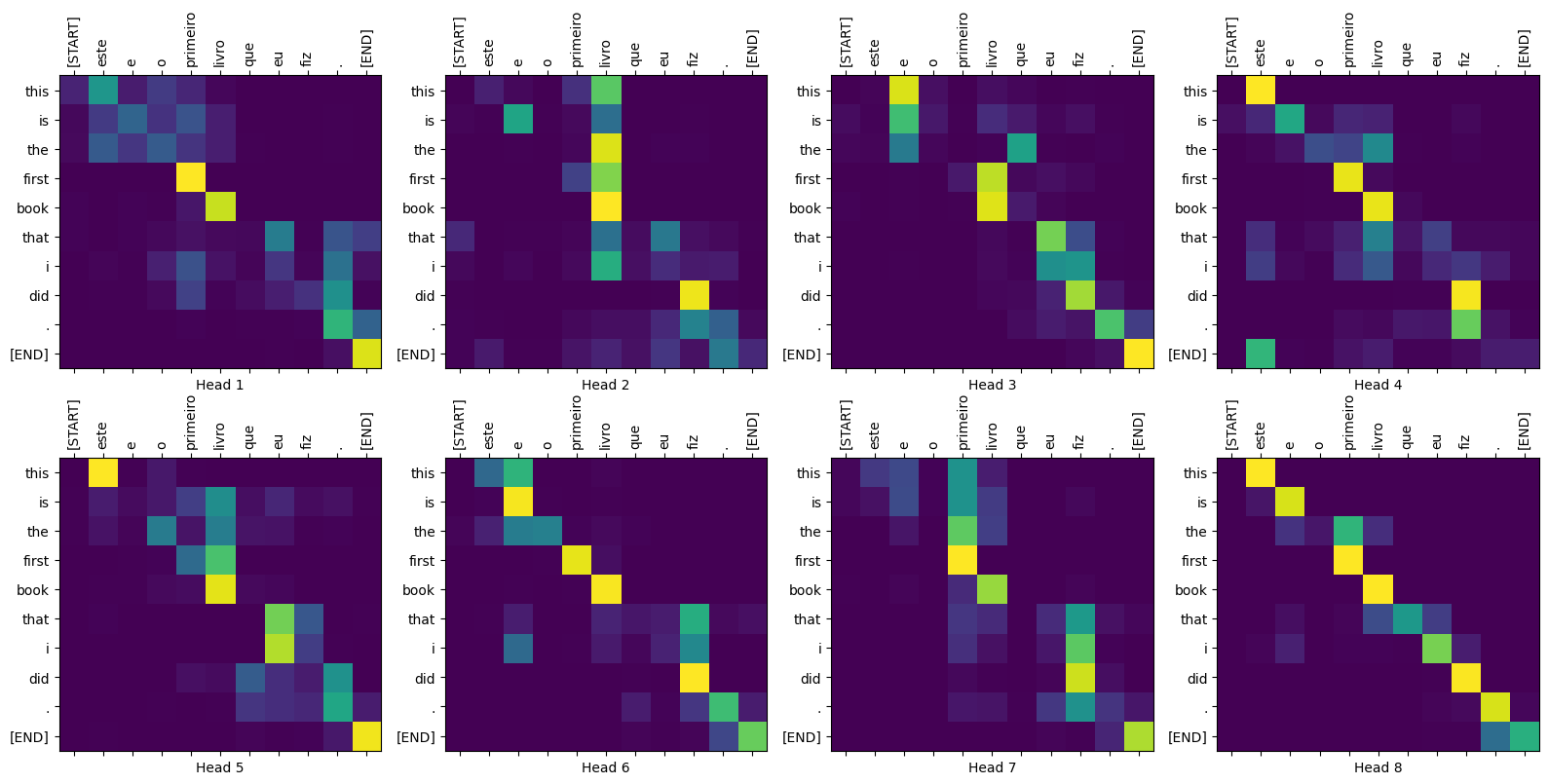
Parcelas de atenção
A classe Translator retorna um dicionário de mapas de atenção que você pode usar para visualizar o funcionamento interno do modelo:
sentence = "este é o primeiro livro que eu fiz."
ground_truth = "this is the first book i've ever done."
translated_text, translated_tokens, attention_weights = translator(
tf.constant(sentence))
print_translation(sentence, translated_text, ground_truth)
Input: : este é o primeiro livro que eu fiz. Prediction : this is the first book that i did . Ground truth : this is the first book i've ever done.
def plot_attention_head(in_tokens, translated_tokens, attention):
# The plot is of the attention when a token was generated.
# The model didn't generate `<START>` in the output. Skip it.
translated_tokens = translated_tokens[1:]
ax = plt.gca()
ax.matshow(attention)
ax.set_xticks(range(len(in_tokens)))
ax.set_yticks(range(len(translated_tokens)))
labels = [label.decode('utf-8') for label in in_tokens.numpy()]
ax.set_xticklabels(
labels, rotation=90)
labels = [label.decode('utf-8') for label in translated_tokens.numpy()]
ax.set_yticklabels(labels)
head = 0
# shape: (batch=1, num_heads, seq_len_q, seq_len_k)
attention_heads = tf.squeeze(
attention_weights['decoder_layer4_block2'], 0)
attention = attention_heads[head]
attention.shape
TensorShape([10, 11])
in_tokens = tf.convert_to_tensor([sentence])
in_tokens = tokenizers.pt.tokenize(in_tokens).to_tensor()
in_tokens = tokenizers.pt.lookup(in_tokens)[0]
in_tokens
<tf.Tensor: shape=(11,), dtype=string, numpy=
array([b'[START]', b'este', b'e', b'o', b'primeiro', b'livro', b'que',
b'eu', b'fiz', b'.', b'[END]'], dtype=object)>
translated_tokens
<tf.Tensor: shape=(11,), dtype=string, numpy=
array([b'[START]', b'this', b'is', b'the', b'first', b'book', b'that',
b'i', b'did', b'.', b'[END]'], dtype=object)>
plot_attention_head(in_tokens, translated_tokens, attention)

def plot_attention_weights(sentence, translated_tokens, attention_heads):
in_tokens = tf.convert_to_tensor([sentence])
in_tokens = tokenizers.pt.tokenize(in_tokens).to_tensor()
in_tokens = tokenizers.pt.lookup(in_tokens)[0]
in_tokens
fig = plt.figure(figsize=(16, 8))
for h, head in enumerate(attention_heads):
ax = fig.add_subplot(2, 4, h+1)
plot_attention_head(in_tokens, translated_tokens, head)
ax.set_xlabel(f'Head {h+1}')
plt.tight_layout()
plt.show()
plot_attention_weights(sentence, translated_tokens,
attention_weights['decoder_layer4_block2'][0])

O modelo se sai bem em palavras desconhecidas. Nem "triceratops" ou "enciclopédia" estão no conjunto de dados de entrada e o modelo quase aprende a transliterá-los, mesmo sem um vocabulário compartilhado:
sentence = "Eu li sobre triceratops na enciclopédia."
ground_truth = "I read about triceratops in the encyclopedia."
translated_text, translated_tokens, attention_weights = translator(
tf.constant(sentence))
print_translation(sentence, translated_text, ground_truth)
plot_attention_weights(sentence, translated_tokens,
attention_weights['decoder_layer4_block2'][0])
Input: : Eu li sobre triceratops na enciclopédia. Prediction : i read about trigatotys in the encyclopedia . Ground truth : I read about triceratops in the encyclopedia.

Exportar
Esse modelo de inferência está funcionando, então, em seguida, você o exportará como um tf.saved_model .
Para fazer isso, envolva-o em outra subclasse tf.Module , desta vez com um tf.function no método __call__ :
class ExportTranslator(tf.Module):
def __init__(self, translator):
self.translator = translator
@tf.function(input_signature=[tf.TensorSpec(shape=[], dtype=tf.string)])
def __call__(self, sentence):
(result,
tokens,
attention_weights) = self.translator(sentence, max_length=100)
return result
No tf.function acima, apenas a sentença de saída é retornada. Graças à execução não estrita em tf.function , quaisquer valores desnecessários nunca são computados.
translator = ExportTranslator(translator)
Como o modelo está decodificando as previsões usando tf.argmax as previsões são determinísticas. O modelo original e um recarregado de seu SavedModel devem fornecer previsões idênticas:
translator("este é o primeiro livro que eu fiz.").numpy()
b'this is the first book that i did .'
tf.saved_model.save(translator, export_dir='translator')
2022-02-04 13:19:17.308292: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as embedding_4_layer_call_fn, embedding_4_layer_call_and_return_conditional_losses, dropout_37_layer_call_fn, dropout_37_layer_call_and_return_conditional_losses, embedding_5_layer_call_fn while saving (showing 5 of 224). These functions will not be directly callable after loading.
reloaded = tf.saved_model.load('translator')
reloaded("este é o primeiro livro que eu fiz.").numpy()
b'this is the first book that i did .'
Resumo
Neste tutorial, você aprendeu sobre codificação posicional, atenção multi-head, a importância do mascaramento e como criar um transformador.
Tente usar um conjunto de dados diferente para treinar o transformador. Você também pode criar o transformador base ou o transformador XL alterando os hiperparâmetros acima. Você também pode usar as camadas definidas aqui para criar BERT e treinar modelos de última geração. Além disso, você pode implementar a pesquisa de feixe para obter melhores previsões.