XlaBuilder ইন্টারফেসে সংজ্ঞায়িত ক্রিয়াকলাপের শব্দার্থবিদ্যা নিম্নলিখিত বর্ণনা করে। সাধারণত, এই ক্রিয়াকলাপগুলি xla_data.proto এ RPC ইন্টারফেসে সংজ্ঞায়িত ক্রিয়াকলাপগুলির সাথে একের পর এক ম্যাপ করে।
নামকরণের উপর একটি নোট: সাধারণীকৃত ডেটা টাইপ XLA হল একটি এন-ডাইমেনশনাল অ্যারে যা কিছু ইউনিফর্ম টাইপের উপাদান ধারণ করে (যেমন 32-বিট ফ্লোট)। ডকুমেন্টেশন জুড়ে, অ্যারে একটি অবাধ-মাত্রিক অ্যারে বোঝাতে ব্যবহৃত হয়। সুবিধার জন্য, বিশেষ ক্ষেত্রে আরো নির্দিষ্ট এবং পরিচিত নাম আছে; উদাহরণস্বরূপ একটি ভেক্টর একটি 1-মাত্রিক অ্যারে এবং একটি ম্যাট্রিক্স একটি 2-মাত্রিক অ্যারে।
সর্বোপরি
এছাড়াও দেখুন XlaBuilder::AfterAll ।
আফটারঅল বিভিন্ন সংখ্যক টোকেন নেয় এবং একটি একক টোকেন তৈরি করে। টোকেন হল আদিম প্রকার যা আদেশ কার্যকর করার জন্য পার্শ্ব-প্রতিক্রিয়াশীল ক্রিয়াকলাপগুলির মধ্যে থ্রেড করা যেতে পারে। AfterAll একটি সেট অপারেশনের পরে একটি অপারেশন অর্ডার করার জন্য টোকেনের যোগদান হিসাবে ব্যবহার করা যেতে পারে।
AfterAll(operands)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operands | XlaOp | টোকেনের বৈচিত্র্যময় সংখ্যা |
অল গ্যাদার
এছাড়াও দেখুন XlaBuilder::AllGather ।
প্রতিলিপি জুড়ে সংযোগ সঞ্চালন.
AllGather(operand, all_gather_dim, shard_count, replica_group_ids, channel_id)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | প্রতিলিপি জুড়ে সংযুক্ত করার জন্য অ্যারে |
all_gather_dim | int64 | সংযুক্তি মাত্রা |
replica_groups | int64 এর ভেক্টরের ভেক্টর | যে গোষ্ঠীগুলির মধ্যে সংযোগ সঞ্চালিত হয়৷ |
channel_id | ঐচ্ছিক int64 | ক্রস-মডিউল যোগাযোগের জন্য ঐচ্ছিক চ্যানেল আইডি |
-
replica_groupsহল রেপ্লিকা গ্রুপের একটি তালিকা যার মধ্যে সংযোগ করা হয় (বর্তমান প্রতিরূপের জন্য প্রতিলিপি আইডিReplicaIdব্যবহার করে পুনরুদ্ধার করা যেতে পারে)। প্রতিটি গোষ্ঠীর প্রতিলিপিগুলির ক্রম নির্ধারণ করে যে ক্রমে তাদের ইনপুটগুলি ফলাফলে অবস্থিত।replica_groupsহয় খালি হতে হবে (যে ক্ষেত্রে সমস্ত প্রতিলিপি একটি একক গোষ্ঠীর অন্তর্গত,0থেকেN - 1পর্যন্ত অর্ডার করা হয়েছে), অথবা প্রতিলিপির সংখ্যার সমান সংখ্যক উপাদান থাকতে হবে। উদাহরণস্বরূপ,replica_groups = {0, 2}, {1, 3}প্রতিলিপিগুলি0এবং2, এবং1এবং3এর মধ্যে সংযুক্তি সম্পাদন করে। -
shard_countহল প্রতিটি রেপ্লিকা গ্রুপের আকার। আমাদের এই ক্ষেত্রে প্রয়োজন যেখানেreplica_groupsখালি থাকে। -
channel_idক্রস-মডিউল যোগাযোগের জন্য ব্যবহৃত হয়: একইchannel_idদিয়ে শুধুমাত্রall-gatherক্রিয়াকলাপ একে অপরের সাথে যোগাযোগ করতে পারে।
আউটপুট শেপ হল ইনপুট শেপ যা all_gather_dim দিয়ে shard_count বার বড় করে। উদাহরণস্বরূপ, যদি দুটি রেপ্লিকা থাকে এবং অপারেন্ড দুটি প্রতিলিপিতে যথাক্রমে [1.0, 2.5] এবং [3.0, 5.25] মান থাকে, তাহলে এই অপ থেকে আউটপুট মান যেখানে all_gather_dim 0 হবে [1.0, 2.5, 3.0, 5.25] উভয় প্রতিলিপিতে।
AllReduce
এছাড়াও দেখুন XlaBuilder::AllReduce ।
প্রতিলিপি জুড়ে একটি কাস্টম গণনা সম্পাদন করে।
AllReduce(operand, computation, replica_group_ids, channel_id)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | রেপ্লিকা জুড়ে কমাতে অ্যারে বা অ্যারের একটি অ-খালি টিপল |
computation | XlaComputation | হ্রাস গণনা |
replica_groups | int64 এর ভেক্টরের ভেক্টর | যে গ্রুপগুলির মধ্যে হ্রাস করা হয় |
channel_id | ঐচ্ছিক int64 | ক্রস-মডিউল যোগাযোগের জন্য ঐচ্ছিক চ্যানেল আইডি |
- যখন
operandঅ্যারের একটি টিপল হয়, তখন টিপলের প্রতিটি উপাদানে অল-রিডুস সঞ্চালিত হয়। -
replica_groupsহল রেপ্লিকা গ্রুপের একটি তালিকা যার মধ্যে হ্রাস করা হয় (বর্তমান প্রতিরূপের জন্য প্রতিলিপি আইডিReplicaIdব্যবহার করে পুনরুদ্ধার করা যেতে পারে)।replica_groupsহয় খালি হতে হবে (যে ক্ষেত্রে সমস্ত প্রতিলিপি একটি একক গোষ্ঠীর অন্তর্গত), অথবা অনুরূপ সংখ্যার সমান সংখ্যক উপাদান থাকতে হবে। উদাহরণস্বরূপ,replica_groups = {0, 2}, {1, 3}প্রতিলিপি0এবং2, এবং1এবং3এর মধ্যে হ্রাস সম্পাদন করে। -
channel_idক্রস-মডিউল যোগাযোগের জন্য ব্যবহৃত হয়: একইchannel_idদিয়ে শুধুমাত্রall-reduceক্রিয়াকলাপ একে অপরের সাথে যোগাযোগ করতে পারে।
আউটপুট আকৃতি ইনপুট আকারের মতই। উদাহরণস্বরূপ, যদি দুটি প্রতিলিপি থাকে এবং অপারেন্ড দুটি প্রতিলিপিতে যথাক্রমে [1.0, 2.5] এবং [3.0, 5.25] মান থাকে, তাহলে এই অপ এবং সমষ্টি গণনা থেকে আউটপুট মান উভয়ের উপর [4.0, 7.75] হবে প্রতিলিপি ইনপুট একটি tuple হলে, আউটপুট একটি tuple পাশাপাশি.
AllReduce এর ফলাফল গণনা করার জন্য প্রতিটি প্রতিলিপি থেকে একটি ইনপুট থাকা প্রয়োজন, তাই যদি একটি প্রতিলিপি একটি AllReduce নোডকে অন্যটির চেয়ে বেশি বার চালায়, তাহলে পূর্বের প্রতিরূপটি চিরতরে অপেক্ষা করবে। যেহেতু প্রতিলিপিগুলি একই প্রোগ্রাম চালাচ্ছে, তাই এটি হওয়ার জন্য অনেকগুলি উপায় নেই, তবে এটি সম্ভব যখন একটি while লুপের অবস্থা ইনফিড থেকে পাওয়া ডেটার উপর নির্ভর করে এবং ইনফেড করা ডেটার কারণে while লুপ আরও বার পুনরাবৃত্তি হয়। একটি প্রতিলিপি অন্য তুলনায়.
AllToAll
এছাড়াও দেখুন XlaBuilder::AllToAll ।
AllToAll হল একটি যৌথ অপারেশন যা সমস্ত কোর থেকে সমস্ত কোরে ডেটা পাঠায়। এর দুটি পর্যায় রয়েছে:
- বিক্ষিপ্ত পর্ব। প্রতিটি কোরে, অপারেন্ডটি
split_dimensionsবরাবর ব্লকেরsplit_countসংখ্যায় বিভক্ত হয়, এবং ব্লকগুলি সমস্ত কোরে ছড়িয়ে পড়ে, যেমন, ith ব্লকটি ith কোরে পাঠানো হয়। - সংগ্রহ পর্ব। প্রতিটি কোর
concat_dimensionবরাবর প্রাপ্ত ব্লকগুলিকে সংযুক্ত করে।
অংশগ্রহণকারী কোরগুলি এর দ্বারা কনফিগার করা যেতে পারে:
-
replica_groups: প্রতিটি ReplicaGroup গণনায় অংশগ্রহণকারী প্রতিলিপি আইডিগুলির একটি তালিকা ধারণ করে (বর্তমান প্রতিরূপের জন্য প্রতিরূপ আইডিReplicaIdব্যবহার করে পুনরুদ্ধার করা যেতে পারে)। AllToAll নির্দিষ্ট ক্রমে সাবগ্রুপের মধ্যে প্রয়োগ করা হবে। উদাহরণস্বরূপ,replica_groups = { {1,2,3}, {4,5,0} }এর অর্থ হল একটি AllToAll প্রতিলিপিগুলির মধ্যে প্রয়োগ করা হবে{1, 2, 3}, এবং সংগ্রহ পর্বে, এবং প্রাপ্ত ব্লকগুলি হবে 1, 2, 3 এর একই ক্রমে সংযুক্ত করা হবে। তারপর, প্রতিলিপি 4, 5, 0 এর মধ্যে আরেকটি AllToAll প্রয়োগ করা হবে এবং সংযোজন ক্রমটিও 4, 5, 0 হবে। যদিreplica_groupsখালি থাকে তবে সমস্ত প্রতিলিপি একটির অন্তর্গত গ্রুপ, তাদের উপস্থিতির সংমিশ্রণ ক্রমে।
পূর্বশর্ত:
-
split_dimensionএর অপারেন্ডের ডাইমেনশন সাইজsplit_countদ্বারা বিভাজ্য। - অপারেন্ডের আকৃতি টিপল নয়।
AllToAll(operand, split_dimension, concat_dimension, split_count, replica_groups)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | n মাত্রিক ইনপুট অ্যারে |
split_dimension | int64 | ব্যবধানে একটি মান [0, n) যা অপারেন্ডটি বিভক্ত হওয়া মাত্রার নাম দেয় |
concat_dimension | int64 | ব্যবধানে একটি মান [0, n) যা বিভক্ত ব্লকগুলিকে সংযুক্ত করার মাত্রার নাম দেয় |
split_count | int64 | এই অপারেশনে অংশগ্রহণকারী কোরের সংখ্যা। যদি replica_groups খালি থাকে, তাহলে এটি প্রতিলিপির সংখ্যা হওয়া উচিত; অন্যথায়, এটি প্রতিটি গ্রুপের প্রতিলিপি সংখ্যার সমান হওয়া উচিত। |
replica_groups | ReplicaGroup ভেক্টর | প্রতিটি গ্রুপে প্রতিলিপি আইডিগুলির একটি তালিকা রয়েছে৷ |
নীচে Alltoall এর একটি উদাহরণ দেখায়।
XlaBuilder b("alltoall");
auto x = Parameter(&b, 0, ShapeUtil::MakeShape(F32, {4, 16}), "x");
AllToAll(x, /*split_dimension=*/1, /*concat_dimension=*/0, /*split_count=*/4);
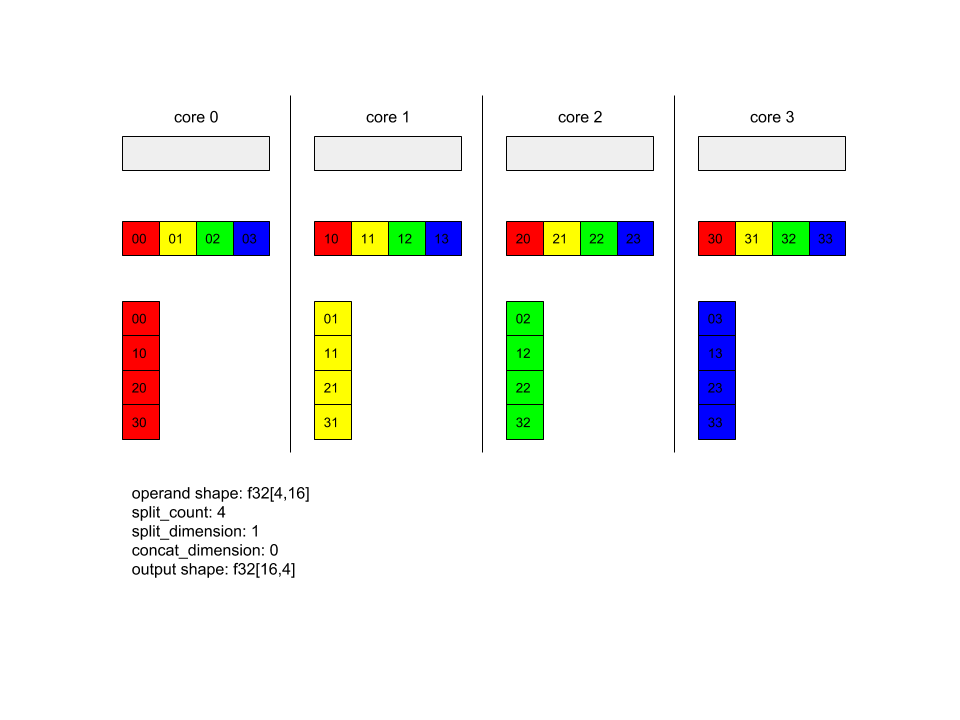
এই উদাহরণে, Alltoall-এ 4টি কোর অংশগ্রহণ করছে। প্রতিটি কোরে, অপারেন্ডটি 0 মাত্রা বরাবর 4টি অংশে বিভক্ত, তাই প্রতিটি অংশের আকার f32[4,4] আছে। 4টি অংশ সমস্ত কোরে ছড়িয়ে ছিটিয়ে রয়েছে। তারপর প্রতিটি কোর কোর 0-4 এর ক্রমানুসারে, মাত্রা 1 বরাবর প্রাপ্ত অংশগুলিকে সংযুক্ত করে। সুতরাং প্রতিটি কোরের আউটপুটের আকার f32[16,4] আছে।
ব্যাচ নর্মগ্র্যাড
অ্যালগরিদমের বিশদ বিবরণের জন্য XlaBuilder::BatchNormGrad এবং মূল ব্যাচের স্বাভাবিককরণের কাগজটিও দেখুন।
ব্যাচের আদর্শের গ্রেডিয়েন্ট গণনা করে।
BatchNormGrad(operand, scale, mean, variance, grad_output, epsilon, feature_index)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | n মাত্রিক বিন্যাস স্বাভাবিক করা হবে (x) |
scale | XlaOp | 1 মাত্রিক অ্যারে (\(\gamma\)) |
mean | XlaOp | 1 মাত্রিক অ্যারে (\(\mu\)) |
variance | XlaOp | 1 ডাইমেনশনাল অ্যারে (\(\sigma^2\)) |
grad_output | XlaOp | গ্রেডিয়েন্ট BatchNormTraining এ পাস করা হয়েছে (\(\nabla y\)) |
epsilon | float | এপসিলন মান (\(\epsilon\)) |
feature_index | int64 | operand বৈশিষ্ট্যের মাত্রার সূচক |
ফিচার ডাইমেনশনের প্রতিটি ফিচারের জন্য ( feature_index হল operand ফিচার ডাইমেনশনের জন্য সূচক), অপারেশনটি অন্য সব ডাইমেনশন জুড়ে operand , offset এবং scale সাপেক্ষে গ্রেডিয়েন্ট গণনা করে। feature_index operand বৈশিষ্ট্যের মাত্রার জন্য একটি বৈধ সূচক হতে হবে।
তিনটি গ্রেডিয়েন্ট নিম্নলিখিত সূত্র দ্বারা সংজ্ঞায়িত করা হয়েছে ( operand হিসাবে একটি 4-মাত্রিক অ্যারে ধরে নেওয়া এবং বৈশিষ্ট্যের মাত্রা সূচক l , ব্যাচের আকার m এবং স্থানিক আকার w এবং h সহ):
\[ \begin{split} c_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sigma^2_l+\epsilon} \right) \\\\ d_l&= \frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \\\\ \nabla x_{ijkl} &= \frac{\gamma_{l} }{\sqrt{\sigma^2_{l}+\epsilon} } \left( \nabla y_{ijkl} - d_l - c_l (x_{ijkl} - \mu_{l}) \right) \\\\ \nabla \gamma_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \left( \nabla y_{ijkl} \frac{x_{ijkl} - \mu_l}{\sqrt{\sigma^2_{l}+\epsilon} } \right) \\\\\ \nabla \beta_l &= \sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h \nabla y_{ijkl} \end{split} \]
ইনপুট mean এবং variance ব্যাচ এবং স্থানিক মাত্রা জুড়ে মুহূর্তের মান উপস্থাপন করে।
আউটপুট প্রকারটি তিনটি হ্যান্ডেলের একটি টিপল:
| আউটপুট | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
grad_operand | XlaOp | ইনপুট operand সাথে গ্রেডিয়েন্ট ($\nabla x$) |
grad_scale | XlaOp | ইনপুট scale সাথে গ্রেডিয়েন্ট ($\nabla \gamma$) |
grad_offset | XlaOp | ইনপুট offset ক্ষেত্রে গ্রেডিয়েন্ট ($\nabla \beta$) |
BatchNormInference
অ্যালগরিদমের বিশদ বিবরণের জন্য XlaBuilder::BatchNormInference এবং মূল ব্যাচের স্বাভাবিককরণ কাগজটিও দেখুন।
ব্যাচ এবং স্থানিক মাত্রা জুড়ে একটি অ্যারেকে স্বাভাবিক করে।
BatchNormInference(operand, scale, offset, mean, variance, epsilon, feature_index)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | n ডাইমেনশনাল অ্যারেকে স্বাভাবিক করতে হবে |
scale | XlaOp | 1 মাত্রিক অ্যারে |
offset | XlaOp | 1 মাত্রিক অ্যারে |
mean | XlaOp | 1 মাত্রিক অ্যারে |
variance | XlaOp | 1 মাত্রিক অ্যারে |
epsilon | float | এপসিলন মান |
feature_index | int64 | operand বৈশিষ্ট্যের মাত্রার সূচক |
ফিচার ডাইমেনশনের প্রতিটি ফিচারের জন্য ( feature_index হল operand ফিচার ডাইমেনশনের জন্য সূচক), অপারেশনটি অন্য সব ডাইমেনশন জুড়ে গড় এবং ভ্যারিয়েন্স গণনা করে এবং operand প্রতিটি উপাদানকে স্বাভাবিক করার জন্য গড় এবং প্রকরণ ব্যবহার করে। feature_index operand বৈশিষ্ট্যের মাত্রার জন্য একটি বৈধ সূচক হতে হবে।
BatchNormInference প্রতিটি ব্যাচের mean এবং variance গণনা না করে BatchNormTraining কল করার সমতুল্য। এটি আনুমানিক মান হিসাবে পরিবর্তে ইনপুট mean এবং variance ব্যবহার করে। এই অপের উদ্দেশ্য হল অনুমানে বিলম্ব কমানো, তাই নাম BatchNormInference ।
আউটপুট হল একটি এন-ডাইমেনশনাল, ইনপুট operand মতো একই আকৃতি সহ স্বাভাবিক বিন্যাস।
ব্যাচ নর্ম ট্রেনিং
অ্যালগরিদমের বিশদ বিবরণের জন্য XlaBuilder::BatchNormTraining এবং the original batch normalization paper দেখুন।
ব্যাচ এবং স্থানিক মাত্রা জুড়ে একটি অ্যারেকে স্বাভাবিক করে।
BatchNormTraining(operand, scale, offset, epsilon, feature_index)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | n মাত্রিক বিন্যাস স্বাভাবিক করা হবে (x) |
scale | XlaOp | 1 ডাইমেনশনাল অ্যারে (\(\gamma\)) |
offset | XlaOp | 1 ডাইমেনশনাল অ্যারে (\(\beta\)) |
epsilon | float | এপসিলন মান (\(\epsilon\)) |
feature_index | int64 | operand বৈশিষ্ট্যের মাত্রার সূচক |
ফিচার ডাইমেনশনের প্রতিটি ফিচারের জন্য ( feature_index হল operand ফিচার ডাইমেনশনের জন্য সূচক), অপারেশনটি অন্য সব ডাইমেনশন জুড়ে গড় এবং ভ্যারিয়েন্স গণনা করে এবং operand প্রতিটি উপাদানকে স্বাভাবিক করার জন্য গড় এবং প্রকরণ ব্যবহার করে। feature_index operand বৈশিষ্ট্যের মাত্রার জন্য একটি বৈধ সূচক হতে হবে।
operand \(x\) এর প্রতিটি ব্যাচের জন্য অ্যালগরিদমটি নিম্নরূপ যা স্থানিক মাত্রার আকার হিসাবে w এবং h সহ m উপাদান ধারণ করে ( operand একটি 4 মাত্রিক অ্যারে)
প্রতিটি বৈশিষ্ট্যের জন্য ব্যাচ গড় \(\mu_l\) গণনা করে
lবৈশিষ্ট্যের মাত্রায়:\(\mu_l=\frac{1}{mwh}\sum_{i=1}^m\sum_{j=1}^w\sum_{k=1}^h x_{ijkl}\)ব্যাচ ভ্যারিয়েন্স গণনা করে \(\sigma^2_l\): $\sigma^2 l=\frac{1}{mwh}\sum {i=1}^m\sum {j=1}^w\sum {k=1}^h ( x_{ijkl} - \mu_l)^2$
স্বাভাবিককরণ, স্কেল এবং পরিবর্তন:\(y_{ijkl}=\frac{\gamma_l(x_{ijkl}-\mu_l)}{\sqrt[2]{\sigma^2_l+\epsilon} }+\beta_l\)
এপসিলন মান, সাধারণত একটি ছোট সংখ্যা, বিভাজন-দ্বারা-শূন্য ত্রুটি এড়াতে যোগ করা হয়।
আউটপুট টাইপ তিনটি XlaOp s এর একটি টিপল:
| আউটপুট | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
output | XlaOp | ইনপুট operand (y) এর মতো একই আকার সহ n মাত্রিক বিন্যাস |
batch_mean | XlaOp | 1 ডাইমেনশনাল অ্যারে (\(\mu\)) |
batch_var | XlaOp | 1 ডাইমেনশনাল অ্যারে (\(\sigma^2\)) |
batch_mean এবং batch_var হল উপরের সূত্রগুলি ব্যবহার করে ব্যাচ এবং স্থানিক মাত্রা জুড়ে গণনা করা মুহূর্ত।
BitcastConvertType
আরও দেখুন XlaBuilder::BitcastConvertType ।
TensorFlow-এর একটি tf.bitcast এর মতোই, ডেটা শেপ থেকে টার্গেট শেপে এলিমেন্ট-ভিত্তিক বিটকাস্ট অপারেশন করে। ইনপুট এবং আউটপুট আকার অবশ্যই মিলবে: যেমন s32 উপাদানগুলি বিটকাস্ট রুটিনের মাধ্যমে f32 উপাদানে পরিণত হবে এবং একটি s32 উপাদান চারটি s8 উপাদানে পরিণত হবে৷ বিটকাস্ট একটি নিম্ন-স্তরের কাস্ট হিসাবে প্রয়োগ করা হয়, তাই বিভিন্ন ফ্লোটিং-পয়েন্ট উপস্থাপনা সহ মেশিনগুলি বিভিন্ন ফলাফল দেবে।
BitcastConvertType(operand, new_element_type)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | ডিমস ডি সহ T টাইপের অ্যারে |
new_element_type | PrimitiveType | U টাইপ করুন |
অপারেন্ডের মাত্রা এবং লক্ষ্য আকৃতি অবশ্যই মিলতে হবে, শেষ মাত্রা ছাড়াও যা রূপান্তরের আগে এবং পরে আদিম আকারের অনুপাত দ্বারা পরিবর্তিত হবে।
উত্স এবং গন্তব্য উপাদানের প্রকারগুলি অবশ্যই টিপল হতে হবে না৷
বিটকাস্ট-বিভিন্ন প্রস্থের আদিম প্রকারে রূপান্তর
BitcastConvert HLO নির্দেশটি সেই ক্ষেত্রে সমর্থন করে যেখানে আউটপুট উপাদানের আকার T' ইনপুট উপাদান T এর আকারের সমান নয়। যেহেতু পুরো অপারেশনটি ধারণাগতভাবে একটি বিটকাস্ট এবং অন্তর্নিহিত বাইট পরিবর্তন করে না, আউটপুট উপাদানটির আকৃতি পরিবর্তন করতে হবে। B = sizeof(T), B' = sizeof(T') , দুটি সম্ভাব্য ক্ষেত্রে আছে।
প্রথমত, যখন B > B' , আউটপুট আকারটি B/B' আকারের একটি নতুন ক্ষুদ্র-সবচেয়ে মাত্রা পায়। উদাহরণ স্বরূপ:
f16[10,2]{1,0} %output = f16[10,2]{1,0} bitcast-convert(f32[10]{0} %input)
কার্যকর স্কেলারের জন্য নিয়ম একই থাকে:
f16[2]{0} %output = f16[2]{0} bitcast-convert(f32[] %input)
বিকল্পভাবে, B' > B এর জন্য নির্দেশের জন্য ইনপুট আকারের শেষ লজিক্যাল মাত্রাটি B'/B এর সমান হওয়া প্রয়োজন, এবং এই মাত্রাটি রূপান্তরের সময় বাদ দেওয়া হয়:
f32[10]{0} %output = f32[10]{0} bitcast-convert(f16[10,2]{1,0} %input)
মনে রাখবেন যে বিভিন্ন বিটউইথের মধ্যে রূপান্তরগুলি উপাদান অনুসারে নয়।
সম্প্রচার
এছাড়াও দেখুন XlaBuilder::Broadcast .
অ্যারেতে ডেটা সদৃশ করে একটি অ্যারেতে মাত্রা যোগ করে।
Broadcast(operand, broadcast_sizes)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | ডুপ্লিকেট করার জন্য অ্যারে |
broadcast_sizes | ArraySlice<int64> | নতুন মাত্রার মাপ |
নতুন মাত্রাগুলি বাম দিকে সন্নিবেশ করা হয়েছে, অর্থাৎ যদি broadcast_sizes মান থাকে {a0, ..., aN} এবং অপারেন্ড আকারের মাত্রা থাকে {b0, ..., bM} তাহলে আউটপুটের আকারের মাত্রা আছে {a0, ..., aN, b0, ..., bM} ।
অপারেন্ডের অনুলিপিতে নতুন মাত্রা সূচক, অর্থাৎ
output[i0, ..., iN, j0, ..., jM] = operand[j0, ..., jM]
উদাহরণস্বরূপ, যদি operand 2.0f মান সহ একটি স্কেলার f32 হয় এবং broadcast_sizes হয় {2, 3} , তাহলে ফলাফলটি আকার f32[2, 3] সহ একটি অ্যারে হবে এবং ফলাফলের সমস্ত মান 2.0f হবে।
ব্রডকাস্ট ইনডিম
এছাড়াও দেখুন XlaBuilder::BroadcastInDim ।
অ্যারেতে ডেটা সদৃশ করে একটি অ্যারের আকার এবং র্যাঙ্ক প্রসারিত করে।
BroadcastInDim(operand, out_dim_size, broadcast_dimensions)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | ডুপ্লিকেট করার জন্য অ্যারে |
out_dim_size | ArraySlice<int64> | লক্ষ্য আকৃতির মাত্রার মাপ |
broadcast_dimensions | ArraySlice<int64> | লক্ষ্য আকৃতির কোন মাত্রা অপারেন্ড আকৃতির প্রতিটি মাত্রার সাথে মিলে যায় |
সম্প্রচারের অনুরূপ, কিন্তু যে কোনো জায়গায় মাত্রা যোগ করতে এবং 1 আকারের সাথে বিদ্যমান মাত্রা প্রসারিত করার অনুমতি দেয়।
operand out_dim_size দ্বারা বর্ণিত আকারে সম্প্রচার করা হয়। broadcast_dimensions operand ডাইমেনশনকে টার্গেট আকৃতির ডাইমেনশনে ম্যাপ করে, অর্থাৎ অপারেন্ডের i'th ডাইমেনশন আউটপুট শেপের ব্রডকাস্ট_ডাইমেনশন[i]'ম ডাইমেনশনে ম্যাপ করা হয়। operand ডাইমেনশনের সাইজ 1 থাকতে হবে অথবা আউটপুট আকৃতিতে যে ডাইমেনশনে ম্যাপ করা হয়েছে সেই আকারের সমান হতে হবে। অবশিষ্ট মাত্রাগুলি 1 আকারের মাত্রা দিয়ে পূর্ণ। ডিজেনারেট-ডাইমেনশন সম্প্রচার তারপর আউটপুট আকারে পৌঁছানোর জন্য এই অধঃপতন মাত্রাগুলি বরাবর সম্প্রচার করে। শব্দার্থবিদ্যা সম্প্রচার পৃষ্ঠায় বিশদভাবে বর্ণনা করা হয়েছে।
কল
এছাড়াও দেখুন XlaBuilder::Call ।
প্রদত্ত আর্গুমেন্টের সাথে একটি গণনা আহ্বান করে।
Call(computation, args...)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
computation | XlaComputation | T_0, T_1, ..., T_{N-1} -> S প্রকারের নির্বিচারে টাইপের N প্যারামিটার সহ গণনা |
args | N XlaOp s এর ক্রম | স্বেচ্ছাচারী প্রকারের এন আর্গুমেন্ট |
args এর arity এবং প্রকারগুলি অবশ্যই computation পরামিতিগুলির সাথে মেলে। এটা কোন args আছে অনুমোদিত হয়.
চোলেস্কি
XlaBuilder::Cholesky আরও দেখুন।
সিমেট্রিক (হার্মিটিয়ান) ধনাত্মক নির্দিষ্ট ম্যাট্রিক্সের একটি ব্যাচের চোলেস্কি পচন গণনা করে।
Cholesky(a, lower)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
a | XlaOp | একটি জটিল বা ভাসমান-বিন্দু টাইপের একটি র্যাঙ্ক > 2 অ্যারে৷ |
lower | bool | a এর উপরের বা নীচের ত্রিভুজ ব্যবহার করবেন কিনা। |
lower true হলে, নিম্ন-ত্রিভুজাকার ম্যাট্রিক্স l গণনা করে যেমন $a = l। l^T$। যদি lower false হয়, u\(a = u^T . u\)ঊর্ধ্ব-ত্রিভুজাকার ম্যাট্রিক্স গণনা করে।
ইনপুট ডেটা কেবলমাত্র a এর নিম্ন/উপরের ত্রিভুজ থেকে পড়া হয়, lower মানের উপর নির্ভর করে। অন্য ত্রিভুজ থেকে মান উপেক্ষা করা হয়. আউটপুট ডেটা একই ত্রিভুজে ফেরত দেওয়া হয়; অন্য ত্রিভুজের মানগুলি বাস্তবায়ন-সংজ্ঞায়িত এবং কিছু হতে পারে।
a এর র্যাঙ্ক 2-এর বেশি হলে, a ম্যাট্রিক্সের একটি ব্যাচ হিসাবে গণ্য করা হয়, যেখানে ছোট 2 মাত্রা ছাড়া বাকি সবগুলিই ব্যাচের মাত্রা।
যদি a প্রতিসম (Hermitian) ধনাত্মক নির্দিষ্ট না হয়, ফলাফলটি বাস্তবায়ন-সংজ্ঞায়িত হয়।
বাতা
এছাড়াও দেখুন XlaBuilder::Clamp ।
ন্যূনতম এবং সর্বোচ্চ মানের মধ্যে একটি অপারেন্ডকে ক্ল্যাম্প করে।
Clamp(min, operand, max)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
min | XlaOp | T টাইপের অ্যারে |
operand | XlaOp | T টাইপের অ্যারে |
max | XlaOp | T টাইপের অ্যারে |
একটি অপারেন্ড এবং ন্যূনতম এবং সর্বোচ্চ মান দেওয়া হলে, অপারেন্ডটি ন্যূনতম এবং সর্বোচ্চের মধ্যে থাকলে তা ফেরত দেয়, অন্যথায় অপারেন্ডটি এই সীমার নীচে হলে সর্বনিম্ন মান বা অপারেন্ডটি এই সীমার উপরে থাকলে সর্বোচ্চ মান প্রদান করে। অর্থাৎ, clamp(a, x, b) = min(max(a, x), b)
তিনটি অ্যারে একই আকৃতির হতে হবে। বিকল্পভাবে, সম্প্রচারের একটি সীমাবদ্ধ রূপ হিসাবে, min এবং/অথবা max T টাইপের স্কেলার হতে পারে।
স্কেলার min এবং max সহ উদাহরণ:
let operand: s32[3] = {-1, 5, 9};
let min: s32 = 0;
let max: s32 = 6;
==>
Clamp(min, operand, max) = s32[3]{0, 5, 6};
সঙ্কুচিত
আরও দেখুন XlaBuilder::Collapse এবং tf.reshape অপারেশন।
একটি অ্যারের মাত্রাগুলিকে একটি মাত্রায় সঙ্কুচিত করে৷
Collapse(operand, dimensions)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | T টাইপের অ্যারে |
dimensions | int64 ভেক্টর | ইন-অর্ডার, T-এর মাত্রার পরপর উপসেট। |
সঙ্কুচিত একটি একক মাত্রা দ্বারা অপারেন্ডের মাত্রার প্রদত্ত উপসেট প্রতিস্থাপন করে। ইনপুট আর্গুমেন্ট হল T টাইপের একটি নির্বিচারে অ্যারে এবং মাত্রা সূচকগুলির একটি কম্পাইল-টাইম-কনস্ট্যান্ট ভেক্টর। মাত্রা সূচকগুলি অবশ্যই একটি ইন-অর্ডার হতে হবে (নিম্ন থেকে উচ্চ মাত্রার সংখ্যা), T-এর মাত্রার ধারাবাহিক উপসেট। এইভাবে, {0, 1, 2}, {0, 1}, বা {1, 2} সবই বৈধ মাত্রা সেট, কিন্তু {1, 0} বা {0, 2} নয়৷ এগুলিকে একটি একক নতুন মাত্রা দ্বারা প্রতিস্থাপিত করা হয়, তারা যেগুলি প্রতিস্থাপন করে সেই মাত্রার ক্রমানুসারে একই অবস্থানে, নতুন মাত্রার আকার মূল মাত্রার মাপের গুণফলের সমান। dimensions মধ্যে সর্বনিম্ন মাত্রা সংখ্যা হল লুপ নেস্টে সবচেয়ে ধীর পরিবর্তিত মাত্রা (সবচেয়ে বড়) যা এই মাত্রাগুলিকে ভেঙে দেয় এবং সর্বোচ্চ মাত্রা সংখ্যাটি দ্রুততম পরিবর্তিত (সবচেয়ে ছোট)। আরও সাধারণ পতনের ক্রম প্রয়োজন হলে tf.reshape অপারেটর দেখুন।
উদাহরণস্বরূপ, v 24 টি উপাদানের একটি অ্যারে হতে দিন:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
// Collapse to a single dimension, leaving one dimension.
let v012 = Collapse(v, {0,1,2});
then v012 == f32[24] {10, 11, 12, 15, 16, 17,
20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37,
40, 41, 42, 45, 46, 47};
// Collapse the two lower dimensions, leaving two dimensions.
let v01 = Collapse(v, {0,1});
then v01 == f32[4x6] { {10, 11, 12, 15, 16, 17},
{20, 21, 22, 25, 26, 27},
{30, 31, 32, 35, 36, 37},
{40, 41, 42, 45, 46, 47} };
// Collapse the two higher dimensions, leaving two dimensions.
let v12 = Collapse(v, {1,2});
then v12 == f32[8x3] { {10, 11, 12},
{15, 16, 17},
{20, 21, 22},
{25, 26, 27},
{30, 31, 32},
{35, 36, 37},
{40, 41, 42},
{45, 46, 47} };
কালেকটিভ পারমিউট
এছাড়াও দেখুন XlaBuilder::CollectivePermute .
CollectivePermute হল একটি যৌথ অপারেশন যা ডেটা ক্রস রেপ্লিকা পাঠায় এবং গ্রহণ করে।
CollectivePermute(operand, source_target_pairs)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | n মাত্রিক ইনপুট অ্যারে |
source_target_pairs | <int64, int64> ভেক্টর | (source_replica_id, target_replica_id) জোড়ার একটি তালিকা। প্রতিটি জোড়ার জন্য, অপারেন্ডটি উৎস প্রতিলিপি থেকে লক্ষ্য প্রতিলিপিতে পাঠানো হয়। |
উল্লেখ্য যে source_target_pair এ নিম্নলিখিত সীমাবদ্ধতা রয়েছে:
- যেকোনো দুই জোড়ার একই টার্গেট রেপ্লিকা আইডি থাকা উচিত নয় এবং তাদের একই সোর্স রেপ্লিকা আইডি থাকা উচিত নয়।
- যদি একটি প্রতিলিপি আইডি কোনো জোড়ায় লক্ষ্য না হয়, তাহলে সেই প্রতিরূপের আউটপুটটি ইনপুটের মতো একই আকৃতি সহ 0(গুলি) সমন্বিত একটি টেনসর।
শ্রেণীবদ্ধভাবে সংযুক্ত করা
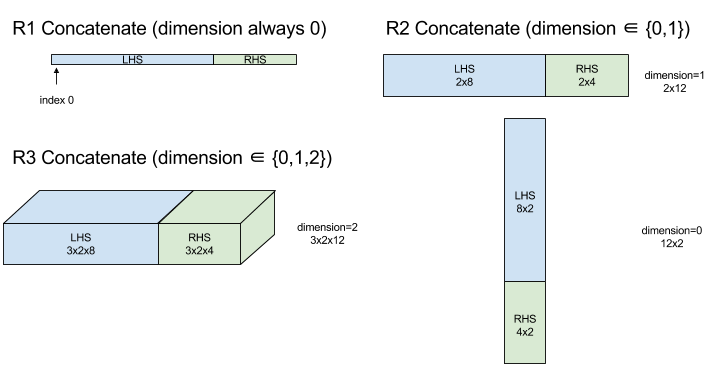
এছাড়াও দেখুন XlaBuilder::ConcatInDim ।
Concatenate একাধিক অ্যারে অপারেন্ড থেকে একটি অ্যারে রচনা করে। অ্যারেটি প্রতিটি ইনপুট অ্যারে অপারেন্ডের মতো একই র্যাঙ্কের (যা অবশ্যই একে অপরের মতো একই র্যাঙ্কের হতে হবে) এবং আর্গুমেন্টগুলিকে যে ক্রমে নির্দিষ্ট করা হয়েছিল সেই ক্রমে ধারণ করে৷
Concatenate(operands..., dimension)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operands | N XlaOp এর ক্রম | মাত্রা সহ T প্রকারের N অ্যারে [L0, L1, ...]। N >= 1 প্রয়োজন। |
dimension | int64 | ব্যবধানে একটি মান [0, N) যা operands মধ্যে সংযুক্ত করা মাত্রার নাম দেয়। |
dimension বাদ দিয়ে সব মাত্রা একই হতে হবে। এর কারণ হল XLA "ragged" অ্যারে সমর্থন করে না। এছাড়াও মনে রাখবেন যে র্যাঙ্ক-0 মানগুলিকে সংযুক্ত করা যাবে না (যেহেতু যে মাত্রার সাথে সংযুক্তি ঘটে তার নাম দেওয়া অসম্ভব)।
1-মাত্রিক উদাহরণ:
Concat({ {2, 3}, {4, 5}, {6, 7} }, 0)
>>> {2, 3, 4, 5, 6, 7}
2-মাত্রিক উদাহরণ:
let a = {
{1, 2},
{3, 4},
{5, 6},
};
let b = {
{7, 8},
};
Concat({a, b}, 0)
>>> {
{1, 2},
{3, 4},
{5, 6},
{7, 8},
}
চিত্র:
শর্তসাপেক্ষ
এছাড়াও দেখুন XlaBuilder::Conditional ।
Conditional(pred, true_operand, true_computation, false_operand, false_computation)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
pred | XlaOp | PRED টাইপের স্কেলার |
true_operand | XlaOp | \(T_0\)প্রকারের আর্গুমেন্ট |
true_computation | XlaComputation | \(T_0 \to S\)প্রকারের Xla কম্পিউটেশন |
false_operand | XlaOp | \(T_1\)প্রকারের আর্গুমেন্ট |
false_computation | XlaComputation | \(T_1 \to S\)প্রকারের Xla কম্পিউটেশন |
pred true হলে true_computation চালায়, pred false হলে false_computation , এবং ফলাফল প্রদান করে।
true_computation টাইপ \(T_0\) এর একটি একক আর্গুমেন্ট নিতে হবে এবং true_operand এর সাথে আহ্বান করা হবে যা অবশ্যই একই ধরনের হতে হবে। false_computation টাইপ \(T_1\) এর একটি একক আর্গুমেন্টে নিতে হবে এবং false_operand দিয়ে আহ্বান করা হবে যা অবশ্যই একই ধরনের হতে হবে। true_computation এবং false_computation এর প্রত্যাবর্তিত মানের ধরন অবশ্যই একই হতে হবে।
মনে রাখবেন pred এর মানের উপর নির্ভর করে true_computation এবং false_computation এর মধ্যে শুধুমাত্র একটি কার্যকর করা হবে।
Conditional(branch_index, branch_computations, branch_operands)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
branch_index | XlaOp | S32 প্রকারের স্কেলার |
branch_computations | এন XlaComputation ক্রম | \(T_0 \to S , T_1 \to S , ..., T_{N-1} \to S\)প্রকারের Xla কম্পিউটেশন |
branch_operands | N XlaOp এর ক্রম | \(T_0 , T_1 , ..., T_{N-1}\)প্রকারের আর্গুমেন্ট |
branch_computations[branch_index] সম্পাদন করে এবং ফলাফল প্রদান করে। branch_index যদি একটি S32 হয় যা < 0 বা >= N হয়, তাহলে branch_computations[N-1] ডিফল্ট শাখা হিসাবে কার্যকর করা হয়।
প্রতিটি branch_computations[b] \(T_b\) টাইপের একটি একক আর্গুমেন্ট নিতে হবে এবং branch_operands[b] দিয়ে আহ্বান করা হবে যা অবশ্যই একই ধরনের হতে হবে। প্রতিটি branch_computations[b] প্রত্যাবর্তিত মানের ধরন অবশ্যই একই হতে হবে।
উল্লেখ্য যে branch_index এর মানের উপর নির্ভর করে branch_computations মধ্যে শুধুমাত্র একটি কার্যকর করা হবে।
রূপান্তর (আবর্তন)
এছাড়াও দেখুন XlaBuilder::Conv ।
ConvWithGeneralPadding হিসাবে, কিন্তু প্যাডিংটি SAME বা VALID হিসাবে সংক্ষিপ্তভাবে নির্দিষ্ট করা হয়েছে৷ একই প্যাডিং ইনপুটকে ( lhs ) শূন্য দিয়ে প্যাড করে যাতে আউটপুটটি স্ট্রাইডিংকে বিবেচনায় না নেওয়ার সময় ইনপুটের মতো একই আকারে থাকে। ভ্যালিড প্যাডিং মানে প্যাডিং নেই।
ConvWithGeneralPadding (Convolution)
XlaBuilder::ConvWithGeneralPadding আরও দেখুন।
নিউরাল নেটওয়ার্কে ব্যবহৃত ধরনের একটি কনভল্যুশন গণনা করে। এখানে, একটি কনভোল্যুশনকে একটি এন-ডাইমেনশনাল উইন্ডো হিসাবে বিবেচনা করা যেতে পারে যা একটি এন-ডাইমেনশনাল বেস এলাকা জুড়ে চলে এবং উইন্ডোটির প্রতিটি সম্ভাব্য অবস্থানের জন্য একটি গণনা করা হয়।
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
lhs | XlaOp | ইনপুটগুলির র্যাঙ্ক n+2 অ্যারে |
rhs | XlaOp | কার্নেলের ওজনের র্যাঙ্ক n+2 অ্যারে |
window_strides | ArraySlice<int64> | কার্নেল স্ট্রাইডের nd অ্যারে |
padding | ArraySlice< pair<int64,int64>> | nd অ্যারে (নিম্ন, উচ্চ) প্যাডিং |
lhs_dilation | ArraySlice<int64> | nd lhs প্রসারণ ফ্যাক্টর অ্যারে |
rhs_dilation | ArraySlice<int64> | nd rhs প্রসারণ ফ্যাক্টর অ্যারে |
feature_group_count | int64 | বৈশিষ্ট্য গোষ্ঠীর সংখ্যা |
batch_group_count | int64 | ব্যাচ গ্রুপ সংখ্যা |
n হল স্থানিক মাত্রার সংখ্যা। lhs আর্গুমেন্ট হল একটি র্যাঙ্ক n+2 অ্যারে যা বেস এলাকা বর্ণনা করে। এটিকে ইনপুট বলা হয়, যদিও অবশ্যই rhs একটি ইনপুট। একটি নিউরাল নেটওয়ার্কে, এইগুলি ইনপুট সক্রিয়করণ। এই ক্রমে n+2 মাত্রাগুলি হল:
-
batch: এই মাত্রার প্রতিটি স্থানাঙ্ক একটি স্বাধীন ইনপুট উপস্থাপন করে যার জন্য কনভল্যুশন করা হয়। -
z/depth/features: বেস এলাকার প্রতিটি (y,x) অবস্থানের সাথে একটি ভেক্টর যুক্ত থাকে, যা এই মাত্রায় যায়। -
spatial_dims:nস্থানিক মাত্রা বর্ণনা করে যা ভিত্তি এলাকাকে সংজ্ঞায়িত করে যে উইন্ডোটি জুড়ে চলে।
rhs আর্গুমেন্ট হল একটি র্যাঙ্ক n+2 অ্যারে যা কনভোলিউশনাল ফিল্টার/কার্নেল/উইন্ডো বর্ণনা করে। মাত্রাগুলি এই ক্রমে:
-
output-z: আউটপুটেরzমাত্রা। -
input-z: এই মাত্রার সময়feature_group_countআকার lhs-এzমাত্রার আকারের সমান হওয়া উচিত। -
spatial_dims:nস্থানিক মাত্রা বর্ণনা করে যা nd উইন্ডোকে সংজ্ঞায়িত করে যা বেস এলাকা জুড়ে চলে।
window_strides আর্গুমেন্ট স্থানিক মাত্রায় কনভোল্যুশনাল উইন্ডোর স্ট্রাইড নির্দিষ্ট করে। উদাহরণস্বরূপ, যদি প্রথম স্থানিক মাত্রায় স্ট্রাইড 3 হয়, তাহলে উইন্ডোটি কেবলমাত্র স্থানাঙ্কগুলিতে স্থাপন করা যেতে পারে যেখানে প্রথম স্থানিক সূচকটি 3 দ্বারা বিভাজ্য।
padding আর্গুমেন্ট বেস এলাকায় প্রয়োগ করা শূন্য প্যাডিংয়ের পরিমাণ নির্দিষ্ট করে। প্যাডিংয়ের পরিমাণ ঋণাত্মক হতে পারে -- নেতিবাচক প্যাডিংয়ের পরম মান কনভল্যুশন করার আগে নির্দিষ্ট মাত্রা থেকে অপসারণের উপাদানের সংখ্যা নির্দেশ করে। padding[0] ডাইমেনশন y এর জন্য প্যাডিং নির্দিষ্ট করে এবং padding[1] ডাইমেনশন x এর জন্য প্যাডিং নির্দিষ্ট করে। প্রতিটি জোড়ার প্রথম উপাদান হিসাবে নিম্ন প্যাডিং এবং দ্বিতীয় উপাদান হিসাবে উচ্চ প্যাডিং রয়েছে। নিম্ন প্যাডিং নিম্ন সূচকের দিকে প্রয়োগ করা হয় যখন উচ্চ প্যাডিং উচ্চ সূচকের দিকে প্রয়োগ করা হয়। উদাহরণস্বরূপ, যদি padding[1] (2,3) হয় তাহলে দ্বিতীয় স্থানিক মাত্রায় বাম দিকে 2 শূন্য এবং ডানদিকে 3 শূন্য দ্বারা একটি প্যাডিং হবে। প্যাডিং ব্যবহার করা কনভোলিউশন করার আগে ইনপুটে ( lhs ) একই শূন্য মান ঢোকানোর সমতুল্য।
lhs_dilation এবং rhs_dilation আর্গুমেন্টগুলি প্রতিটি স্থানিক মাত্রায় যথাক্রমে lhs এবং rhs-এ প্রয়োগ করার জন্য প্রসারণ ফ্যাক্টর নির্দিষ্ট করে। যদি একটি স্থানিক মাত্রার প্রসারণ ফ্যাক্টর d হয়, তাহলে d-1 ছিদ্রগুলি সেই মাত্রার প্রতিটি এন্ট্রির মধ্যে নিহিতভাবে স্থাপন করা হয়, অ্যারের আকার বৃদ্ধি করে। গর্তগুলি একটি নো-অপ মান দিয়ে ভরা হয়, যা কনভল্যুশনের জন্য শূন্য বোঝায়।
আরএইচএসের প্রসারণকে অ্যাট্রাস কনভোলিউশনও বলা হয়। আরো বিস্তারিত জানার জন্য, tf.nn.atrous_conv2d দেখুন। Lhs এর প্রসারণকে ট্রান্সপোজড কনভোলিউশনও বলা হয়। আরো বিস্তারিত জানার জন্য, tf.nn.conv2d_transpose দেখুন।
feature_group_count আর্গুমেন্ট (ডিফল্ট মান 1) গ্রুপ করা কনভোলিউশনের জন্য ব্যবহার করা যেতে পারে। feature_group_count ইনপুট এবং আউটপুট বৈশিষ্ট্যের মাত্রা উভয়েরই একটি ভাজক হতে হবে। feature_group_count 1-এর বেশি হলে, এর অর্থ হল ধারণাগতভাবে ইনপুট এবং আউটপুট বৈশিষ্ট্যের মাত্রা এবং rhs আউটপুট বৈশিষ্ট্যের মাত্রা সমানভাবে অনেকগুলি feature_group_count গ্রুপে বিভক্ত, প্রতিটি গোষ্ঠী পরপর বৈশিষ্ট্যগুলির একটি ক্রমানুসারে গঠিত। rhs এর ইনপুট ফিচার ডাইমেনশন lhs ইনপুট ফিচার ডাইমেনশনকে feature_group_count দ্বারা ভাগ করা প্রয়োজন (তাই এটি ইতিমধ্যেই ইনপুট বৈশিষ্ট্যগুলির একটি গ্রুপের আকার রয়েছে)। i-th গ্রুপগুলিকে একসাথে ব্যবহার করা হয় feature_group_count গণনা করার জন্য অনেকগুলি আলাদা কনভল্যুশনের জন্য। এই আবর্তনের ফলাফলগুলি আউটপুট বৈশিষ্ট্য মাত্রার সাথে একত্রিত হয়।
গভীরতার দিক থেকে কনভল্যুশনের জন্য feature_group_count আর্গুমেন্টটি ইনপুট ফিচার ডাইমেনশনে সেট করা হবে এবং ফিল্টারটি [filter_height, filter_width, in_channels, channel_multiplier] থেকে [filter_height, filter_width, 1, in_channels * channel_multiplier] পুনরায় আকার দেওয়া হবে। আরো বিস্তারিত জানার জন্য, tf.nn.depthwise_conv2d দেখুন।
batch_group_count (ডিফল্ট মান 1) আর্গুমেন্ট ব্যাকপ্রোপেশনের সময় গোষ্ঠীবদ্ধ ফিল্টারের জন্য ব্যবহার করা যেতে পারে। batch_group_count lhs (ইনপুট) ব্যাচের মাত্রার একটি ভাজক হতে হবে। batch_group_count 1 এর বেশি হলে, এর মানে হল আউটপুট ব্যাচের মাত্রা input batch / batch_group_count আকারের হওয়া উচিত। batch_group_count অবশ্যই আউটপুট বৈশিষ্ট্য আকারের একটি ভাজক হতে হবে।
আউটপুট আকারের এই মাত্রা রয়েছে, এই ক্রমে:
-
batch:batch_group_countএই মাত্রার আকার lhs-এbatchমাত্রার সমান হওয়া উচিত। -
z: কার্নেলেরoutput-zমতো একই আকার (rhs)। -
spatial_dims: কনভোল্যুশনাল উইন্ডোর প্রতিটি বৈধ বসানোর জন্য একটি মান।

উপরের চিত্রটি দেখায় কিভাবে batch_group_count ক্ষেত্র কাজ করে। কার্যকরীভাবে, আমরা প্রতিটি lhs ব্যাচকে batch_group_count গ্রুপে ভাগ করি এবং আউটপুট বৈশিষ্ট্যগুলির জন্য একই কাজ করি। তারপর, এই গোষ্ঠীগুলির প্রতিটির জন্য আমরা যুগলভাবে কনভোলিউশন করি এবং আউটপুট বৈশিষ্ট্যের মাত্রা বরাবর আউটপুটকে সংযুক্ত করি। অন্যান্য সমস্ত মাত্রার (বৈশিষ্ট্য এবং স্থানিক) অপারেশনাল শব্দার্থ একই থাকে।
কনভোল্যুশনাল উইন্ডোর বৈধ স্থান নির্ধারণ করা হয় স্ট্রাইড এবং প্যাডিংয়ের পরে বেস এলাকার আকার দ্বারা।
একটি কনভোলিউশন কী করে তা বর্ণনা করতে, একটি 2d কনভোলিউশন বিবেচনা করুন এবং আউটপুটে কিছু নির্দিষ্ট batch , z , y , x স্থানাঙ্ক বেছে নিন। তারপর (y,x) হল বেস এলাকার মধ্যে উইন্ডোর একটি কোণার অবস্থান (যেমন উপরের বাম কোণে, আপনি স্থানিক মাত্রাগুলি কীভাবে ব্যাখ্যা করেন তার উপর নির্ভর করে)। আমাদের এখন একটি 2d উইন্ডো আছে, যা বেস এলাকা থেকে নেওয়া হয়েছে, যেখানে প্রতিটি 2d পয়েন্ট একটি 1d ভেক্টরের সাথে যুক্ত, তাই আমরা একটি 3d বক্স পাচ্ছি। কনভোলিউশনাল কার্নেল থেকে, যেহেতু আমরা আউটপুট স্থানাঙ্ক z ঠিক করেছি, আমাদের একটি 3d বক্সও রয়েছে। দুটি বাক্সের একই মাত্রা রয়েছে, তাই আমরা দুটি বাক্সের মধ্যে উপাদান-ভিত্তিক পণ্যগুলির যোগফল নিতে পারি (একটি ডট পণ্যের মতো)। যে আউটপুট মান.
মনে রাখবেন যে যদি output-z হয়, যেমন, 5, তাহলে উইন্ডোর প্রতিটি অবস্থান আউটপুটের z ডাইমেনশনে আউটপুটে 5 টি মান উৎপন্ন করে। কনভোলিউশনাল কার্নেলের কোন অংশ ব্যবহার করা হয় তার মধ্যে এই মানগুলি আলাদা - প্রতিটি output-z স্থানাঙ্কের জন্য ব্যবহৃত মানের একটি পৃথক 3d বক্স রয়েছে। সুতরাং আপনি তাদের প্রতিটির জন্য একটি আলাদা ফিল্টার সহ 5টি পৃথক কনভোলিউশন হিসাবে ভাবতে পারেন।
প্যাডিং এবং স্ট্রাইডিং সহ একটি 2d কনভোলিউশনের জন্য এখানে ছদ্ম-কোড রয়েছে:
for (b, oz, oy, ox) { // output coordinates
value = 0;
for (iz, ky, kx) { // kernel coordinates and input z
iy = oy*stride_y + ky - pad_low_y;
ix = ox*stride_x + kx - pad_low_x;
if ((iy, ix) inside the base area considered without padding) {
value += input(b, iz, iy, ix) * kernel(oz, iz, ky, kx);
}
}
output(b, oz, oy, ox) = value;
}
ConvertElementType
এছাড়াও দেখুন XlaBuilder::ConvertElementType ।
C++-এ একটি উপাদান-ভিত্তিক static_cast মতো, একটি ডেটা আকৃতি থেকে লক্ষ্য আকারে একটি উপাদান-ভিত্তিক রূপান্তর ক্রিয়া সম্পাদন করে। মাত্রা অবশ্যই মিলবে, এবং রূপান্তর একটি উপাদান-ভিত্তিক; যেমন s32 উপাদানগুলি একটি s32 - থেকে- f32 রূপান্তর রুটিনের মাধ্যমে f32 উপাদানে পরিণত হয়৷
ConvertElementType(operand, new_element_type)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | ডিমস ডি সহ T টাইপের অ্যারে |
new_element_type | PrimitiveType | U টাইপ করুন |
অপারেন্ডের মাত্রা এবং লক্ষ্য আকৃতি অবশ্যই মিলবে। উত্স এবং গন্তব্য উপাদানের প্রকারগুলি অবশ্যই টিপল হতে হবে না৷
একটি রূপান্তর যেমন T=s32 থেকে U=f32 একটি স্বাভাবিক int-to-float রূপান্তর রুটিন সম্পাদন করবে যেমন রাউন্ড-থেকে-নেয়ারস্ট-এমন।
let a: s32[3] = {0, 1, 2};
let b: f32[3] = convert(a, f32);
then b == f32[3]{0.0, 1.0, 2.0}
CrossReplicaSum
একটি সমষ্টি গণনা সহ AllReduce সম্পাদন করে।
কাস্টম কল
এছাড়াও দেখুন XlaBuilder::CustomCall ।
একটি গণনার মধ্যে একটি ব্যবহারকারী-প্রদত্ত ফাংশন কল করুন।
CustomCall(target_name, args..., shape)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
target_name | string | ফাংশনের নাম। একটি কল নির্দেশ নির্গত হবে যা এই চিহ্ন নামটিকে লক্ষ্য করে। |
args | N XlaOp s এর ক্রম | এন আরবিট্রারি টাইপের আর্গুমেন্ট, যা ফাংশনে পাস করা হবে। |
shape | Shape | ফাংশনের আউটপুট আকৃতি |
ফাংশন স্বাক্ষর একই, আরিটি বা আর্গের ধরন নির্বিশেষে:
extern "C" void target_name(void* out, void** in);
উদাহরণস্বরূপ, যদি CustomCall নিম্নরূপ ব্যবহার করা হয়:
let x = f32[2] {1,2};
let y = f32[2x3] { {10, 20, 30}, {40, 50, 60} };
CustomCall("myfunc", {x, y}, f32[3x3])
এখানে myfunc এর বাস্তবায়নের একটি উদাহরণ রয়েছে:
extern "C" void myfunc(void* out, void** in) {
float (&x)[2] = *static_cast<float(*)[2]>(in[0]);
float (&y)[2][3] = *static_cast<float(*)[2][3]>(in[1]);
EXPECT_EQ(1, x[0]);
EXPECT_EQ(2, x[1]);
EXPECT_EQ(10, y[0][0]);
EXPECT_EQ(20, y[0][1]);
EXPECT_EQ(30, y[0][2]);
EXPECT_EQ(40, y[1][0]);
EXPECT_EQ(50, y[1][1]);
EXPECT_EQ(60, y[1][2]);
float (&z)[3][3] = *static_cast<float(*)[3][3]>(out);
z[0][0] = x[1] + y[1][0];
// ...
}
ব্যবহারকারী-প্রদত্ত ফাংশনটির পার্শ্ব-প্রতিক্রিয়া থাকতে হবে না এবং এর সম্পাদন অবশ্যই অদম্য হতে হবে।
ডট
এছাড়াও দেখুন XlaBuilder::Dot ।
Dot(lhs, rhs)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
lhs | XlaOp | T টাইপের অ্যারে |
rhs | XlaOp | T টাইপের অ্যারে |
এই অপারেশনের সঠিক শব্দার্থবিদ্যা অপারেন্ডের পদের উপর নির্ভর করে:
| ইনপুট | আউটপুট | শব্দার্থবিদ্যা |
|---|---|---|
ভেক্টর [n] dot ভেক্টর [n] | স্কেলার | ভেক্টর ডট পণ্য |
ম্যাট্রিক্স [mxk] dot ভেক্টর [k] | ভেক্টর [মি] | ম্যাট্রিক্স-ভেক্টর গুণন |
ম্যাট্রিক্স [mxk] dot ম্যাট্রিক্স [kxn] | ম্যাট্রিক্স [mxn] | ম্যাট্রিক্স-ম্যাট্রিক্স গুণ |
অপারেশনটি lhs এর দ্বিতীয় মাত্রা (অথবা প্রথমটি যদি এটির র্যাঙ্ক 1 থাকে) এবং rhs এর প্রথম মাত্রার উপর পণ্যের সমষ্টি সম্পাদন করে। এগুলি হল "চুক্তিকৃত" মাত্রা। lhs এবং rhs এর সংকুচিত মাত্রা অবশ্যই একই আকারের হতে হবে। অনুশীলনে, এটি ভেক্টর, ভেক্টর/ম্যাট্রিক্স গুণ বা ম্যাট্রিক্স/ম্যাট্রিক্স গুণনের মধ্যে ডট পণ্য সম্পাদন করতে ব্যবহার করা যেতে পারে।
ডটজেনারেল
এছাড়াও দেখুন XlaBuilder::DotGeneral ।
DotGeneral(lhs, rhs, dimension_numbers)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
lhs | XlaOp | T টাইপের অ্যারে |
rhs | XlaOp | T টাইপের অ্যারে |
dimension_numbers | DotDimensionNumbers | চুক্তি এবং ব্যাচ মাত্রা সংখ্যা |
ডট-এর মতো, কিন্তু lhs এবং rhs উভয়ের জন্যই চুক্তি এবং ব্যাচের মাত্রা সংখ্যা নির্দিষ্ট করার অনুমতি দেয়।
| ডট ডাইমেনশন নম্বর ক্ষেত্র | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
lhs_contracting_dimensions | পুনরাবৃত্তি int64 | lhs চুক্তির মাত্রা সংখ্যা |
rhs_contracting_dimensions | পুনরাবৃত্তি int64 | rhs চুক্তির মাত্রা সংখ্যা |
lhs_batch_dimensions | পুনরাবৃত্তি int64 | lhs ব্যাচের মাত্রা সংখ্যা |
rhs_batch_dimensions | পুনরাবৃত্তি int64 | rhs ব্যাচের মাত্রা সংখ্যা |
DotGeneral dimension_numbers এ নির্দিষ্ট করা চুক্তির মাত্রার উপর পণ্যের সমষ্টি সম্পাদন করে।
lhs এবং rhs থেকে সংযুক্ত চুক্তির মাত্রা সংখ্যা একই হতে হবে না কিন্তু একই মাত্রার আকার থাকতে হবে।
চুক্তির মাত্রা সংখ্যা সহ উদাহরণ:
lhs = { {1.0, 2.0, 3.0},
{4.0, 5.0, 6.0} }
rhs = { {1.0, 1.0, 1.0},
{2.0, 2.0, 2.0} }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(1);
dnums.add_rhs_contracting_dimensions(1);
DotGeneral(lhs, rhs, dnums) -> { {6.0, 12.0},
{15.0, 30.0} }
lhs এবং rhs থেকে যুক্ত ব্যাচের মাত্রা সংখ্যার একই মাত্রার মাপ থাকতে হবে।
ব্যাচের মাত্রা সংখ্যা সহ উদাহরণ (ব্যাচের আকার 2, 2x2 ম্যাট্রিক্স):
lhs = { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
rhs = { { {1.0, 0.0},
{0.0, 1.0} },
{ {1.0, 0.0},
{0.0, 1.0} } }
DotDimensionNumbers dnums;
dnums.add_lhs_contracting_dimensions(2);
dnums.add_rhs_contracting_dimensions(1);
dnums.add_lhs_batch_dimensions(0);
dnums.add_rhs_batch_dimensions(0);
DotGeneral(lhs, rhs, dnums) -> { { {1.0, 2.0},
{3.0, 4.0} },
{ {5.0, 6.0},
{7.0, 8.0} } }
| ইনপুট | আউটপুট | শব্দার্থবিদ্যা |
|---|---|---|
[b0, m, k] dot [b0, k, n] | [b0, m, n] | ব্যাচ মাতমুল |
[b0, b1, m, k] dot [b0, b1, k, n] | [b0, b1, m, n] | ব্যাচ মাতমুল |
এটি অনুসরণ করে যে ফলিত মাত্রা সংখ্যাটি ব্যাচের মাত্রা দিয়ে শুরু হয়, তারপরে lhs নন-কন্ট্রাক্টিং/নন-ব্যাচ মাত্রা এবং অবশেষে rhs নন-কন্ট্রাক্টিং/নন-ব্যাচ মাত্রা।
ডাইনামিক স্লাইস
এছাড়াও দেখুন XlaBuilder::DynamicSlice ।
DynamicSlice ডাইনামিক start_indices এ ইনপুট অ্যারে থেকে একটি সাব-অ্যারে বের করে। প্রতিটি মাত্রায় স্লাইসের আকার size_indices পাস করা হয়, যা প্রতিটি মাত্রার একচেটিয়া স্লাইস ব্যবধানের শেষ বিন্দু নির্দিষ্ট করে: [শুরু, শুরু + আকার)। start_indices এর আকৃতি অবশ্যই rank == 1 হতে হবে, যার মাত্রা operand র্যাঙ্কের সমান।
DynamicSlice(operand, start_indices, size_indices)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | T টাইপের N মাত্রিক বিন্যাস |
start_indices | N XlaOp এর ক্রম | প্রতিটি মাত্রার জন্য স্লাইসের প্রারম্ভিক সূচক ধারণকারী N স্কেলার পূর্ণসংখ্যার তালিকা। মান অবশ্যই শূন্যের বেশি বা সমান হতে হবে। |
size_indices | ArraySlice<int64> | প্রতিটি মাত্রার জন্য স্লাইস আকার ধারণকারী N পূর্ণসংখ্যার তালিকা। প্রতিটি মান অবশ্যই শূন্যের থেকে কঠোরভাবে বড় হতে হবে এবং শুরু + আকার অবশ্যই মাত্রার আকারের চেয়ে কম বা সমান হতে হবে যাতে মডুলো ডাইমেনশনের আকারকে মোড়ানো না হয়। |
কার্যকর স্লাইস সূচকগুলি স্লাইস সম্পাদন করার আগে [1, N) প্রতিটি সূচক i এর জন্য নিম্নলিখিত রূপান্তর প্রয়োগ করে গণনা করা হয়:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - size_indices[i])
এটি নিশ্চিত করে যে নিষ্কাশিত স্লাইস সর্বদা অপারেন্ড অ্যারের সাপেক্ষে ইন-বাউন্ডে থাকে। রূপান্তর প্রয়োগ করার আগে যদি স্লাইস ইন-বাউন্ড হয়, তবে রূপান্তরের কোন প্রভাব নেই।
1-মাত্রিক উদাহরণ:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let s = {2}
DynamicSlice(a, s, {2}) produces:
{2.0, 3.0}
2-মাত্রিক উদাহরণ:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let s = {2, 1}
DynamicSlice(b, s, {2, 2}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
ডাইনামিকআপডেট স্লাইস
এছাড়াও দেখুন XlaBuilder::DynamicUpdateSlice ।
DynamicUpdateSlice একটি ফলাফল তৈরি করে যা ইনপুট অ্যারে operand মান, একটি স্লাইস update start_indices এ ওভাররাইট করা হয়। update আকারটি ফলাফলের সাব-অ্যারের আকার নির্ধারণ করে যা আপডেট হয়। start_indices আকারটি অবশ্যই র্যাঙ্ক == 1 হওয়া উচিত, যার সাথে মাত্রা আকারটি operand র্যাঙ্কের সমান।
DynamicUpdateSlice(operand, update, start_indices)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | টাইপ টি এর ডাইমেনশনাল অ্যারে |
update | XlaOp | স্লাইস আপডেটযুক্ত টাইপ টি এর ডাইমেনশনাল অ্যারে। আপডেটের আকারের প্রতিটি মাত্রা অবশ্যই শূন্যের চেয়ে কঠোরভাবে বড় হতে হবে এবং স্টার্ট + আপডেট অবশ্যই প্রতিটি মাত্রার জন্য অপারেন্ড আকারের চেয়ে কম বা সমান হতে হবে যাতে বাউন্ডের বাইরে থাকা আপডেট সূচকগুলি তৈরি করা এড়াতে হবে। |
start_indices | এন XlaOp এর ক্রম | প্রতিটি মাত্রার জন্য স্লাইসের প্রারম্ভিক সূচকগুলি সমন্বিত এন স্কেলার পূর্ণসংখ্যার তালিকা। মান অবশ্যই শূন্যের চেয়ে বড় বা সমান হতে হবে। |
কার্যকর স্লাইস সূচকগুলি স্লাইসটি সম্পাদন করার আগে [1, N) প্রতিটি i জন্য নিম্নলিখিত রূপান্তর প্রয়োগ করে গণনা করা হয়:
start_indices[i] = clamp(start_indices[i], 0, operand.dimension_size[i] - update.dimension_size[i])
এটি নিশ্চিত করে যে আপডেট হওয়া স্লাইসটি সর্বদা অপারেন্ড অ্যারের সাথে সম্পর্কিত হয়। রূপান্তর প্রয়োগের আগে যদি স্লাইসটি অন্তর্নিহিত হয় তবে রূপান্তরটির কোনও প্রভাব নেই।
1-মাত্রিক উদাহরণ:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
let u = {5.0, 6.0}
let s = {2}
DynamicUpdateSlice(a, u, s) produces:
{0.0, 1.0, 5.0, 6.0, 4.0}
2-মাত্রিক উদাহরণ:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
let u =
{ {12.0, 13.0},
{14.0, 15.0},
{16.0, 17.0} }
let s = {1, 1}
DynamicUpdateSlice(b, u, s) produces:
{ {0.0, 1.0, 2.0},
{3.0, 12.0, 13.0},
{6.0, 14.0, 15.0},
{9.0, 16.0, 17.0} }
উপাদান অনুসারে বাইনারি গাণিতিক ক্রিয়াকলাপ
XlaBuilder::Add করুন।
উপাদান-ভিত্তিক বাইনারি গাণিতিক ক্রিয়াকলাপগুলির একটি সেট সমর্থিত।
Op(lhs, rhs)
যেখানে Op হ'ল Add (সংযোজন), Sub (বিয়োগ), Mul (গুণ), Div (বিভাগ), Rem (অবশিষ্ট), Max (সর্বাধিক), Min (ন্যূনতম), LogicalAnd (লজিকাল এবং), বা লজিকালর ( LogicalOr (লজিকালর (লজিকালর বা)।
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
lhs | XlaOp | বাম-পাশের দিকের অপারেন্ড: টাইপ টি এর অ্যারে |
rhs | XlaOp | ডান-হাতের অপারেন্ড: টাইপ টি এর অ্যারে |
যুক্তিগুলির আকারগুলি হয় একই বা সামঞ্জস্যপূর্ণ হতে হবে। আকারগুলি সামঞ্জস্যপূর্ণ হওয়ার জন্য এর অর্থ কী তা সম্পর্কে সম্প্রচারের ডকুমেন্টেশন দেখুন। অপারেশনের ফলাফলের একটি আকার রয়েছে যা দুটি ইনপুট অ্যারে সম্প্রচারের ফলাফল। এই বৈকল্পিকভাবে, বিভিন্ন র্যাঙ্কের অ্যারেগুলির মধ্যে অপারেশনগুলি সমর্থিত নয় , যদি না অপারেন্ডগুলির মধ্যে একটি স্কেলার হয়।
যখন Op Rem হয়, ফলাফলের চিহ্নটি লভ্যাংশ থেকে নেওয়া হয় এবং ফলাফলের পরম মান সর্বদা বিভাজকের পরম মানের চেয়ে কম থাকে।
পূর্ণসংখ্যা বিভাগ ওভারফ্লো (স্বাক্ষরিত/স্বাক্ষরবিহীন বিভাগ/শূন্য দ্বারা অবশিষ্টাংশ বা স্বাক্ষরিত বিভাগ/ -1 এর সাথে INT_SMIN এর অবশিষ্টাংশ) একটি বাস্তবায়ন সংজ্ঞায়িত মান উত্পাদন করে।
বিভিন্ন র্যাঙ্ক সম্প্রচার সমর্থন সহ একটি বিকল্প বৈকল্পিক এই ক্রিয়াকলাপগুলির জন্য বিদ্যমান:
Op(lhs, rhs, broadcast_dimensions)
যেখানে Op উপরের মতো একই। অপারেশনের এই বৈকল্পিক বিভিন্ন র্যাঙ্কের অ্যারেগুলির মধ্যে গাণিতিক ক্রিয়াকলাপগুলির জন্য ব্যবহার করা উচিত (যেমন কোনও ভেক্টরে ম্যাট্রিক্স যুক্ত করা)।
অতিরিক্ত broadcast_dimensions অপারেন্ড হ'ল উচ্চ-র্যাঙ্ক অপারেন্ডের র্যাঙ্কটি উচ্চ-র্যাঙ্কের অপারেন্ডের র্যাঙ্ক পর্যন্ত প্রসারিত করতে ব্যবহৃত পূর্ণসংখ্যার একটি টুকরো। broadcast_dimensions নিম্ন-র্যাঙ্ক আকারের মাত্রাগুলিকে উচ্চ-র্যাঙ্ক আকারের মাত্রাগুলিতে মানচিত্র করে। প্রসারিত আকারের আনম্যাপড মাত্রাগুলি এক আকারের মাত্রা দিয়ে পূর্ণ হয়। অবক্ষয়-মাত্রা সম্প্রচারের পরে উভয় অপারেন্ডের আকারকে সমান করতে এই অবক্ষয় মাত্রা বরাবর আকারগুলি সম্প্রচার করে। শব্দার্থবিজ্ঞানগুলি সম্প্রচার পৃষ্ঠায় বিশদভাবে বর্ণনা করা হয়েছে।
উপাদান ভিত্তিক তুলনা অপারেশন
XlaBuilder::Eq দেখুন।
স্ট্যান্ডার্ড উপাদান-ভিত্তিক বাইনারি তুলনা অপারেশনগুলির একটি সেট সমর্থিত। নোট করুন যে স্ট্যান্ডার্ড আইইইই 754 ভাসমান-পয়েন্ট তুলনা শব্দার্থবিজ্ঞানগুলি ভাসমান-পয়েন্ট ধরণের তুলনা করার সময় প্রযোজ্য।
Op(lhs, rhs)
যেখানে Op হ'ল Eq (সমান-টু), Ne (সমান থেকে নয়), Ge (বৃহত্তর-বেশি-সমান-এর চেয়ে), Gt (বৃহত্তর-এর চেয়ে বেশি), Le (কম-বেশি-সমান), Lt (কম-কম) অপারেটরগুলির আরেকটি সেট, একটোটালর্ডার, নেটোটালর্ডার, গেটোটালর্ডার, জিটিটোটালর্ডার, লেটোটালর্ডার এবং এলটি টোটালর্ডার একই কার্যকারিতা সরবরাহ করে, তারা অতিরিক্তভাবে ভাসমান বিন্দু সংখ্যার উপর মোট অর্ডার সমর্থন করে, প্রয়োগ করে < -ইনফ < -ফিনাইট <-0 -0 প্রয়োগ করে <+0 < +সসীম < +ইনফ < +ন্যান।
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
lhs | XlaOp | বাম-পাশের দিকের অপারেন্ড: টাইপ টি এর অ্যারে |
rhs | XlaOp | ডান-হাতের অপারেন্ড: টাইপ টি এর অ্যারে |
যুক্তিগুলির আকারগুলি হয় একই বা সামঞ্জস্যপূর্ণ হতে হবে। আকারগুলি সামঞ্জস্যপূর্ণ হওয়ার জন্য এর অর্থ কী তা সম্পর্কে সম্প্রচারের ডকুমেন্টেশন দেখুন। অপারেশনের ফলাফলের একটি আকৃতি রয়েছে যা উপাদান ধরণের PRED সাথে দুটি ইনপুট অ্যারে সম্প্রচারের ফলাফল। এই বৈকল্পিকভাবে, বিভিন্ন র্যাঙ্কের অ্যারেগুলির মধ্যে অপারেশনগুলি সমর্থিত নয় , যদি না অপারেন্ডগুলির মধ্যে একটি স্কেলার হয়।
বিভিন্ন র্যাঙ্ক সম্প্রচার সমর্থন সহ একটি বিকল্প বৈকল্পিক এই ক্রিয়াকলাপগুলির জন্য বিদ্যমান:
Op(lhs, rhs, broadcast_dimensions)
যেখানে Op উপরের মতো একই। অপারেশনের এই রূপটি বিভিন্ন র্যাঙ্কের অ্যারেগুলির মধ্যে তুলনা ক্রিয়াকলাপের জন্য ব্যবহার করা উচিত (যেমন কোনও ভেক্টরে ম্যাট্রিক্স যুক্ত করা)।
অতিরিক্ত broadcast_dimensions অপারেন্ড হ'ল অপারেশনগুলি সম্প্রচারের জন্য ব্যবহারের জন্য মাত্রাগুলি নির্দিষ্ট করে এমন পূর্ণসংখ্যার একটি টুকরো। শব্দার্থবিজ্ঞানগুলি সম্প্রচার পৃষ্ঠায় বিশদভাবে বর্ণনা করা হয়েছে।
উপাদান ভিত্তিক অনারি ফাংশন
Xlabuilder এই উপাদান ভিত্তিক অনারি ফাংশন সমর্থন করে:
Abs(operand) উপাদান -ভিত্তিক অ্যাবস x -> |x| .
Ceil(operand) উপাদান -ভিত্তিক সিল x -> ⌈x⌉
Cos(operand) উপাদান -ভিত্তিক কোসাইন x -> cos(x) ।
Exp(operand) উপাদান -ভিত্তিক প্রাকৃতিক এক্সফোনেনশিয়াল x -> e^x ।
Floor(operand) উপাদান -ভিত্তিক মেঝে x -> ⌊x⌋
Imag(operand) একটি জটিল (বা বাস্তব) আকারের উপাদান-ভিত্তিক কাল্পনিক অংশ। x -> imag(x) । যদি অপারেন্ডটি একটি ভাসমান পয়েন্টের ধরণ হয় তবে 0 টি ফেরত দেয়।
IsFinite(operand) পরীক্ষা করে যে operand প্রতিটি উপাদান সীমাবদ্ধ, অর্থাত্, ইতিবাচক বা নেতিবাচক অনন্ত নয়, এবং NaN নয়। ইনপুট হিসাবে একই আকারের সাথে PRED মানগুলির একটি অ্যারে ফেরত দেয়, যেখানে প্রতিটি উপাদান যদি true হয় এবং কেবলমাত্র যদি সংশ্লিষ্ট ইনপুট উপাদানটি সীমাবদ্ধ থাকে।
Log(operand) উপাদান -ভিত্তিক প্রাকৃতিক লগারিদম x -> ln(x) ।
LogicalNot(operand) উপাদান -ভিত্তিক লজিক্যাল নয় x -> !(x) ।
Logistic(operand) উপাদান -ভিত্তিক লজিস্টিক ফাংশন গণনা x -> logistic(x) ।
PopulationCount(operand) operand প্রতিটি উপাদানগুলিতে সেট করা বিটগুলির সংখ্যা গণনা করে।
Neg(operand) উপাদান -ভিত্তিক অবহেলা x -> -x ।
Real(operand) উপাদান অনুসারে একটি জটিল (বা বাস্তব) আকারের বাস্তব অংশ। x -> real(x) । যদি অপারেন্ডটি একটি ভাসমান পয়েন্টের ধরণ হয় তবে একই মানটি ফেরত দেয়।
Rsqrt(operand) বর্গমূল অপারেশন x -> 1.0 / sqrt(x) এর উপাদান ভিত্তিক পারস্পরিক।
Sign(operand) উপাদান অনুসারে সাইন অপারেশন x -> sgn(x) যেখানে
\[\text{sgn}(x) = \begin{cases} -1 & x < 0\\ -0 & x = -0\\ NaN & x = NaN\\ +0 & x = +0\\ 1 & x > 0 \end{cases}\]
operand উপাদান ধরণের তুলনা অপারেটর ব্যবহার করে।
Sqrt(operand) উপাদান -ভিত্তিক স্কোয়ার রুট অপারেশন x -> sqrt(x) ।
Cbrt(operand) উপাদান অনুসারে কিউবিক রুট অপারেশন x -> cbrt(x) ।
Tanh(operand) উপাদান -ভিত্তিক হাইপারবোলিক ট্যানজেন্ট x -> tanh(x) ।
Round(operand) উপাদান-ভিত্তিক বৃত্তাকার, শূন্য থেকে দূরে বেঁধে।
RoundNearestEven(operand) উপাদান-ভিত্তিক রাউন্ডিং, নিকটবর্তী এমনকি বন্ধন।
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | ফাংশন অপারেন্ড |
ফাংশনটি operand অ্যারেতে প্রতিটি উপাদানের জন্য প্রয়োগ করা হয়, যার ফলে একই আকারের একটি অ্যারে হয়। এটি operand জন্য স্কেলার হওয়ার অনুমতি দেয় (র্যাঙ্ক 0)।
Fft
এক্সএলএ এফএফটি অপারেশন বাস্তব এবং জটিল ইনপুট/আউটপুটগুলির জন্য ফরোয়ার্ড এবং বিপরীত ফুরিয়ার রূপান্তরগুলি প্রয়োগ করে। 3 টি অক্ষের বহুমাত্রিক এফএফটিগুলি সমর্থিত।
XlaBuilder::Fft দেখুন।
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | অ্যারে আমরা ফুরিয়ার রূপান্তরকারী। |
fft_type | FftType | নীচের টেবিল দেখুন. |
fft_length | ArraySlice<int64> | অক্ষের সময়-ডোমেন দৈর্ঘ্য রূপান্তরিত হচ্ছে। এটি বিশেষত আইআরএফটি-র অন্তর্গত অক্ষকে ডান-আকারের করতে প্রয়োজন, যেহেতু RFFT(fft_length=[16]) RFFT(fft_length=[17]) এর মতো আউটপুট আকার রয়েছে। |
FftType | শব্দার্থবিদ্যা |
|---|---|
FFT | কমপ্লেক্স-টু-কমপ্লেক্স এফএফটি ফরোয়ার্ড। আকৃতি অপরিবর্তিত। |
IFFT | বিপরীত জটিল থেকে কমপ্লেক্স এফএফটি। আকৃতি অপরিবর্তিত। |
RFFT | ফরোয়ার্ড রিয়েল-টু-কমপ্লেক্স এফএফটি। অন্তর্নিহিত অক্ষের আকারটি fft_length[-1] // 2 + 1 এ হ্রাস করা হয় যদি fft_length[-1] একটি শূন্য মান হয়, Nyquist ফ্রিকোয়েন্সি ছাড়িয়ে রূপান্তরিত সংকেতের বিপরীত কনজুগেট অংশটি বাদ দেয়। |
IRFFT | বিপরীত রিয়েল-টু-কমপ্লেক্স এফএফটি (অর্থাত্ জটিল নেয়, বাস্তব রিটার্ন)। অন্তর্নিহিত অক্ষের আকারটি fft_length[-1] যদি fft_length[-1] একটি শূন্য মান হয়, 1 থেকে fft_length[-1] // 2 + 1 এন্ট্রি। |
বহুমাত্রিক এফএফটি
যখন 1 টিরও বেশি fft_length সরবরাহ করা হয়, তখন এটি প্রতিটি অভ্যন্তরীণ অক্ষগুলিতে এফএফটি অপারেশনগুলির একটি ক্যাসকেড প্রয়োগ করার সমতুল্য। নোট করুন যে বাস্তব-> জটিল এবং জটিল-> বাস্তব কেসগুলির জন্য, অন্তর্নিহিত অক্ষ রূপান্তরটি (কার্যকরভাবে) প্রথমে সম্পাদিত হয় (আরএফএফটি; আইআরএফটিটির জন্য শেষ), এ কারণেই অন্তর্নিহিত অক্ষটিই আকার পরিবর্তন করে। অন্যান্য অক্ষের রূপান্তরগুলি তখন জটিল-> জটিল হবে।
বাস্তবায়নের বিবরণ
সিপিইউ এফএফটি আইজেনের টেনসরফটি দ্বারা সমর্থিত। জিপিইউ এফএফটি ব্যবহার করে কাফ্ট।
জড়ো করা
এক্সএলএ একটি ইনপুট অ্যারের বেশ কয়েকটি স্লাইস (প্রতিটি স্লাইস সম্ভাব্য ভিন্ন রানটাইম অফসেটে প্রতিটি স্লাইস) একসাথে সেলাই করে।
সাধারণ শব্দার্থবিদ্যা
XlaBuilder::Gather । আরও স্বজ্ঞাত বর্ণনার জন্য, নীচে "অনানুষ্ঠানিক বিবরণ" বিভাগটি দেখুন।
gather(operand, start_indices, offset_dims, collapsed_slice_dims, slice_sizes, start_index_map)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | আমরা যে অ্যারে থেকে সংগ্রহ করছি। |
start_indices | XlaOp | আমরা যে স্লাইসগুলি সংগ্রহ করি তার প্রারম্ভিক সূচকগুলি ধারণকারী অ্যারে। |
index_vector_dim | int64 | প্রারম্ভিক সূচকগুলি "ধারণ" করে এমন start_indices মাত্রা। বিশদ বিবরণের জন্য নীচে দেখুন। |
offset_dims | ArraySlice<int64> | আউটপুট আকারে মাত্রাগুলির সেট যা অপারেন্ড থেকে কাটা একটি অ্যারেতে অফসেট করে। |
slice_sizes | ArraySlice<int64> | slice_sizes[i] মাত্রার উপর স্লাইসের সীমা i । |
collapsed_slice_dims | ArraySlice<int64> | প্রতিটি টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো টুকরো এই মাত্রাগুলির আকার 1 থাকতে হবে। |
start_index_map | ArraySlice<int64> | এমন একটি মানচিত্র যা কীভাবে start_indices সূচকগুলি অপারেন্ডে আইনী সূচকগুলিতে ম্যাপ করা যায় তা বর্ণনা করে। |
indices_are_sorted | bool | সূচকগুলি কলার দ্বারা বাছাই করার গ্যারান্টিযুক্ত কিনা। |
unique_indices | bool | সূচকগুলি কলারের দ্বারা অনন্য হওয়ার গ্যারান্টিযুক্ত কিনা। |
সুবিধার জন্য, আমরা আউটপুট অ্যারেতে offset_dims batch_dims হিসাবে নয়।
আউটপুটটি র্যাঙ্ক batch_dims.size + offset_dims.size একটি অ্যারে।
operand.rank অবশ্যই offset_dims.size যোগফলের সমান এবং collapsed_slice_dims.size সমান। এছাড়াও, slice_sizes.size operand.rank সমান হতে হবে।
start_indices index_vector_dim start_indices.rank start_indices 1 [6,7] index_vector_dim 2 start_indices [6,7,1] )
মাত্রা সহ আউটপুট অ্যারের সীমাটি i গণনা করা হয়:
যদি
ibatch_dimsউপস্থিত থাকি (অর্থাত্ কিছুkএর জন্যbatch_dims[k]এর সমান) তবে আমরাstart_indices.shapeবাইরে সম্পর্কিত মাত্রা সীমাটি বেছে নিই, স্কিপিংindex_vector_dim(অর্থাত্start_indices.shape.dims[k] যদিk<index_vector_dimএবংstart_indices.shape.dims[k+1] অন্যথায়)।যদি
ioffset_dimsউপস্থিত থাকি (অর্থাত্offset_dims[k] এর সমান কিছুk) তবে আমরাcollapsed_slice_dimsজন্য অ্যাকাউন্টিংয়ের পরেadjusted_slice_sizesসাথে সম্পর্কিত সীমাবদ্ধটি বেছে নিয়েছি_স্লাইস_ডিমস (যেমন আমরা অ্যাডজাস্টড_স্লাইস_সাইজগুলি বেছেslice_sizes[k] যেখানেadjusted_slice_sizescollapsed_slice_dimsসাথেslice_sizesহয় )
আনুষ্ঠানিকভাবে, প্রদত্ত Out সূচকের সাথে In অপারেন্ড সূচকটি নিম্নলিখিত হিসাবে গণনা করা হয়:
G= {Out[k] কেbatch_dimskএর জন্য} কোনও ভেক্টরSটুকরো টুকরো করার জন্যGব্যবহার করুন যাS[i] =start_indices[কম্বাইন (G,i)] যেখানে একত্রিত করুন (ক, খ) এindex_vector_dimবি সন্নিবেশ করে এ। নোট করুন যেGখালি থাকলেও এটি ভালভাবে সংজ্ঞায়িত করা হয়েছে : যদিGখালি থাকে তবেS=start_indices।start_index_mapoperandকরে স্ক্র্যাটারিংSSSinএকটি প্রারম্ভিক সূচক তৈরি করুন। আরো স্পষ্ট করে:Sin[start_index_map[k]] =S[k] যদিk<start_index_map.size।Sin[_] =0অন্যথায়।
collapsed_slice_dimsসেট অনুসারেOutমাত্রাগুলিতে সূচকগুলি ছড়িয়ে দিয়েoperandএকটিinOতৈরি করুন। আরো স্পষ্ট করে:O[remapped_offset_dims(k)] =Out[offset_dims[k]] যদিk<offset_dims.size(remapped_offset_dimsনীচে সংজ্ঞায়িত করা হয়)inOin_] =0অন্যথায়।
InOin+Sinযেখানে + উপাদান-ভিত্তিক সংযোজন।
remapped_offset_dims হ'ল ডোমেন [ 0 , offset_dims.size ) এবং পরিসীমা [ 0 , operand.rank ) সহ একটি একঘেয়ে ফাংশন যা \ collapsed_slice_dims । সুতরাং, যেমন, যেমন, offset_dims.size 4 হয়, operand.rank 6 এবং collapsed_slice_dims { 0 , 2 } তবে remapped_offset_dims হয় { 0 → 1 , 1 → 3 , 2 → 4 , 3 → 5 }}
যদি indices_are_sorted সত্যে সেট করা থাকে তবে এক্সএলএ ধরে নিতে পারে যে ব্যবহারকারী দ্বারা start_indices বাছাই করা হয় (আরোহী start_index_map ক্রমে) ব্যবহারকারী দ্বারা। যদি সেগুলি না হয় তবে শব্দার্থবিজ্ঞানগুলি বাস্তবায়ন সংজ্ঞায়িত করা হয়।
যদি unique_indices সত্যে সেট করা থাকে তবে এক্সএলএ ধরে নিতে পারে যে ছড়িয়ে ছিটিয়ে থাকা সমস্ত উপাদানগুলি অনন্য। সুতরাং এক্সএলএ অ-পারমাণবিক ক্রিয়াকলাপ ব্যবহার করতে পারে। যদি unique_indices সত্যে সেট করা থাকে এবং সূচকগুলি ছড়িয়ে ছিটিয়ে থাকা অনন্য না হয় তবে শব্দার্থবিজ্ঞানগুলি বাস্তবায়ন সংজ্ঞায়িত করা হয়।
অনানুষ্ঠানিক বিবরণ এবং উদাহরণ
অনানুষ্ঠানিকভাবে, Out অ্যারেতে প্রতিটি সূচকগুলি অপারেন্ড অ্যারেতে একটি উপাদান E এর সাথে মিলে যায়, নিম্নলিখিত হিসাবে গণনা করা হয়:
আমরা
start_indicesথেকে একটি প্রারম্ভিক সূচকOutকরতে ব্যাচের মাত্রাগুলি ব্যবহার করি।আমরা প্রারম্ভিক সূচকটি মানচিত্র করতে
start_index_mapব্যবহার করি (যার আকার অপারেন্ডের চেয়ে কম হতে পারে)operandএকটি "পূর্ণ" সূচনা সূচকে।আমরা সম্পূর্ণ প্রারম্ভিক সূচক ব্যবহার করে আকারের
slice_sizesসহ একটি স্লাইসকে গতিশীল করি।আমরা ধসে
collapsed_slice_dimsমাত্রাগুলি ভেঙে টুকরোটি পুনরায় আকার দিয়েছি। যেহেতু সমস্ত ধসে পড়া স্লাইস মাত্রাগুলির অবশ্যই 1 টি সীমা থাকতে হবে, তাই এই পুনর্নির্মাণটি সর্বদা আইনী।আউটপুট
Outসাথে সম্পর্কিতOutউপাদান,Eপেতে আমরা এই স্লাইসে সূচক থেকে অফসেট মাত্রাগুলি ব্যবহার করি।
index_vector_dim start_indices.rank - 1 এ সেট করা আছে যা অনুসরণ করে এমন সমস্ত উদাহরণে। index_vector_dim জন্য আরও আকর্ষণীয় মানগুলি মূলত অপারেশনটিকে পরিবর্তন করে না, তবে ভিজ্যুয়াল উপস্থাপনাটিকে আরও জটিল করে তুলেছে।
উপরের সমস্তগুলি কীভাবে একসাথে ফিট করে সে সম্পর্কে একটি অন্তর্দৃষ্টি পেতে, আসুন একটি উদাহরণ দেখুন যা একটি [16,11] অ্যারে থেকে 5 টি টুকরো আকারের [8,6] সংগ্রহ করে। [16,11] অ্যারেতে একটি স্লাইসের অবস্থানটি শেপ S64[2] এর সূচক ভেক্টর হিসাবে প্রতিনিধিত্ব করা যেতে পারে, সুতরাং 5 পজিশনের সেটটি S64[5,2] অ্যারে হিসাবে প্রতিনিধিত্ব করা যেতে পারে।
জড়ো অপারেশনের আচরণটি তখন একটি সূচক রূপান্তর হিসাবে চিত্রিত করা যেতে পারে যা [ G , O 0 , O 1 ], আউটপুট আকারের একটি সূচক নেয় এবং এটি নিম্নলিখিত উপায়ে ইনপুট অ্যারেতে কোনও উপাদানকে মানচিত্র করে:

আমরা প্রথমে G ব্যবহার করে সূচক সূচকগুলি থেকে একটি ( X , Y ) ভেক্টর নির্বাচন করি। সূচক [ G , O 0 , O 1 ] এর আউটপুট অ্যারেতে উপাদানটি তখন সূচক [ X + O 0 , Y + O 1 ] এ ইনপুট অ্যারেতে উপাদান।
slice_sizes হ'ল [8,6] , যা ও 0 এবং ও 1 এর পরিসীমা স্থির করে এবং এটি ফলস্বরূপ স্লাইসের সীমানা স্থির করে।
এই সংগ্রহটি অপারেশন ব্যাচের মাত্রা হিসাবে G সহ ব্যাচের গতিশীল স্লাইস হিসাবে কাজ করে।
সংগ্রহ সূচকগুলি বহুমাত্রিক হতে পারে। উদাহরণস্বরূপ, উপরের উদাহরণের আরও সাধারণ সংস্করণ "সংগ্রহ সূচকগুলি" আকারের [4,5,2] ব্যবহার করে এরকম সূচকগুলি অনুবাদ করবে:

আবার, এটি ব্যাচের ডায়নামিক স্লাইস G 0 এবং G 1 হিসাবে ব্যাচের মাত্রা হিসাবে কাজ করে। স্লাইস আকার এখনও [8,6] ।
এক্সএলএ -তে জড়ো হওয়া অপারেশনটি নিম্নলিখিত উপায়ে বর্ণিত অনানুষ্ঠানিক শব্দার্থবিজ্ঞানের সাধারণীকরণ করে:
আমরা আউটপুট আকারে কোন মাত্রাগুলি কনফিগার করতে পারি তা হ'ল অফসেট মাত্রা (শেষ উদাহরণে
O0,O1সমন্বিত মাত্রা)। আউটপুট ব্যাচের মাত্রা (শেষ উদাহরণেG0,G1সমন্বিত মাত্রা) আউটপুট মাত্রা হিসাবে সংজ্ঞায়িত করা হয় যা অফসেট মাত্রা নয়।আউটপুট আকারে স্পষ্টভাবে উপস্থিত আউটপুট অফসেট মাত্রার সংখ্যা ইনপুট র্যাঙ্কের চেয়ে ছোট হতে পারে। এই "অনুপস্থিত" মাত্রাগুলি, যা স্পষ্টভাবে
collapsed_slice_dimsহিসাবে তালিকাভুক্ত রয়েছে, অবশ্যই1এর স্লাইস আকার থাকতে হবে। যেহেতু তাদের 1 টির আকার রয়েছে1টির জন্য একমাত্র বৈধ সূচক0এবং তাদেরকে এলোমেলো করে অস্পষ্টতা প্রবর্তন করে না।"সূচকগুলি সংগ্রহ করুন" অ্যারে ((
X,Y) থেকে শেষ উদাহরণে) থেকে প্রাপ্ত স্লাইসটিতে ইনপুট অ্যারে র্যাঙ্কের চেয়ে কম উপাদান থাকতে পারে এবং একটি সুস্পষ্ট ম্যাপিং নির্দেশ দেয় যে কীভাবে সূচকটি ইনপুট হিসাবে একই র্যাঙ্কটি প্রসারিত করা উচিত .
চূড়ান্ত উদাহরণ হিসাবে, আমরা tf.gather_nd প্রয়োগ করতে (2) এবং (3) ব্যবহার করি:

G 0 এবং G 1 যথারীতি সংগ্রহ সূচকগুলি থেকে একটি প্রারম্ভিক সূচকগুলি টুকরো টুকরো করার জন্য ব্যবহৃত হয়, প্রারম্ভিক সূচকের কেবলমাত্র একটি উপাদান রয়েছে, X । একইভাবে, O 0 মান সহ কেবলমাত্র একটি আউটপুট অফসেট সূচক রয়েছে। যাইহোক, ইনপুট অ্যারেতে সূচক হিসাবে ব্যবহার করার আগে এগুলি "সূচক ম্যাপিং সংগ্রহ করুন" (আনুষ্ঠানিক বিবরণে start_index_map ) এবং "অফসেট ম্যাপিং" (আনুষ্ঠানিক বর্ণনায় remapped_offset_dims ) [x, 0] এবং [ X , 0 ] এবং [তে প্রসারিত করা হয়। 0 , O 0 ] যথাক্রমে [ X , O 0 ] যোগ করে। অন্য কথায়, আউটপুট সূচক [ G 0 , G 1 , O 0 ] ইনপুট সূচকগুলিতে মানচিত্র [ GatherIndices [ G 0 , G 1 , 0 ], O 0 ] যা আমাদের tf.gather_nd জন্য শব্দার্থবিজ্ঞান দেয়।
এই মামলার জন্য slice_sizes [1,11] । স্বজ্ঞাতভাবে এর অর্থ হ'ল সংগ্রহের সূচকগুলির প্রতিটি সূচক X অ্যারে একটি পুরো সারি বাছাই করে এবং ফলাফলটি এই সমস্ত সারিগুলির সংমিশ্রণ।
GetDemensionsize
XlaBuilder::GetDimensionSize দেখুন।
অপারেন্ডের প্রদত্ত মাত্রার আকারটি ফেরত দেয়। অপারেন্ড অবশ্যই অ্যারে আকৃতির হতে হবে।
GetDimensionSize(operand, dimension)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | n মাত্রিক ইনপুট অ্যারে |
dimension | int64 | ব্যবধানে একটি মান [0, n) যা মাত্রা নির্দিষ্ট করে |
সেটডিমেনশনসাইজ
XlaBuilder::SetDimensionSize দেখুন।
এক্সএলওপি -র প্রদত্ত মাত্রার গতিশীল আকার সেট করে। অপারেন্ড অবশ্যই অ্যারে আকৃতির হতে হবে।
SetDimensionSize(operand, size, dimension)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | n মাত্রিক ইনপুট অ্যারে। |
size | XlaOp | INT32 রানটাইম গতিশীল আকারের প্রতিনিধিত্ব করে। |
dimension | int64 | ব্যবধানে একটি মান [0, n) যা মাত্রা নির্দিষ্ট করে। |
সংকলক দ্বারা ট্র্যাক করা গতিশীল মাত্রা সহ ফলস্বরূপ অপারেন্ডের মধ্য দিয়ে যান।
প্যাডেড মানগুলি ডাউন স্ট্রিম হ্রাস ওপিএস দ্বারা উপেক্ষা করা হবে।
let v: f32[10] = f32[10]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10};
let five: s32 = 5;
let six: s32 = 6;
// Setting dynamic dimension size doesn't change the upper bound of the static
// shape.
let padded_v_five: f32[10] = set_dimension_size(v, five, /*dimension=*/0);
let padded_v_six: f32[10] = set_dimension_size(v, six, /*dimension=*/0);
// sum == 1 + 2 + 3 + 4 + 5
let sum:f32[] = reduce_sum(padded_v_five);
// product == 1 * 2 * 3 * 4 * 5
let product:f32[] = reduce_product(padded_v_five);
// Changing padding size will yield different result.
// sum == 1 + 2 + 3 + 4 + 5 + 6
let sum:f32[] = reduce_sum(padded_v_six);
GetTupleelement
XlaBuilder::GetTupleElement দেখুন।
একটি সংকলন-সময়-ধ্রুবক মান সহ একটি টুপলে সূচকগুলি।
মানটি অবশ্যই একটি সংকলন-সময়-ধ্রুবক হতে হবে যাতে আকার অনুমানটি ফলাফলের মান নির্ধারণ করতে পারে।
এটি স্ট্যান্ড std::get<int N>(t) । ধারণাগতভাবে:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
let element_1: s32 = gettupleelement(t, 1); // Inferred shape matches s32.
tf.tuple দেখুন।
ইনফিড
XlaBuilder::Infeed দেখুন।
Infeed(shape)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
shape | Shape | ইনফিড ইন্টারফেস থেকে পড়া ডেটার আকার। আকারের বিন্যাস ক্ষেত্রটি ডিভাইসে প্রেরিত ডেটার বিন্যাসের সাথে মেলে সেট করতে হবে; অন্যথায় এর আচরণ অপরিজ্ঞাত। |
ডিভাইসের অন্তর্নিহিত ইনফিড স্ট্রিমিং ইন্টারফেস থেকে একটি একক ডেটা আইটেম পড়ে, প্রদত্ত আকার এবং এর বিন্যাস হিসাবে ডেটা ব্যাখ্যা করে এবং ডেটার একটি XlaOp প্রদান করে। একাধিক ইনফিড অপারেশন একটি গণনায় অনুমোদিত, তবে ইনফিড অপারেশনগুলির মধ্যে অবশ্যই একটি মোট অর্ডার থাকতে হবে। উদাহরণস্বরূপ, নীচের কোডে দুটি ইনফিডের মোট অর্ডার রয়েছে যেহেতু লুপগুলির মধ্যে নির্ভরতা রয়েছে।
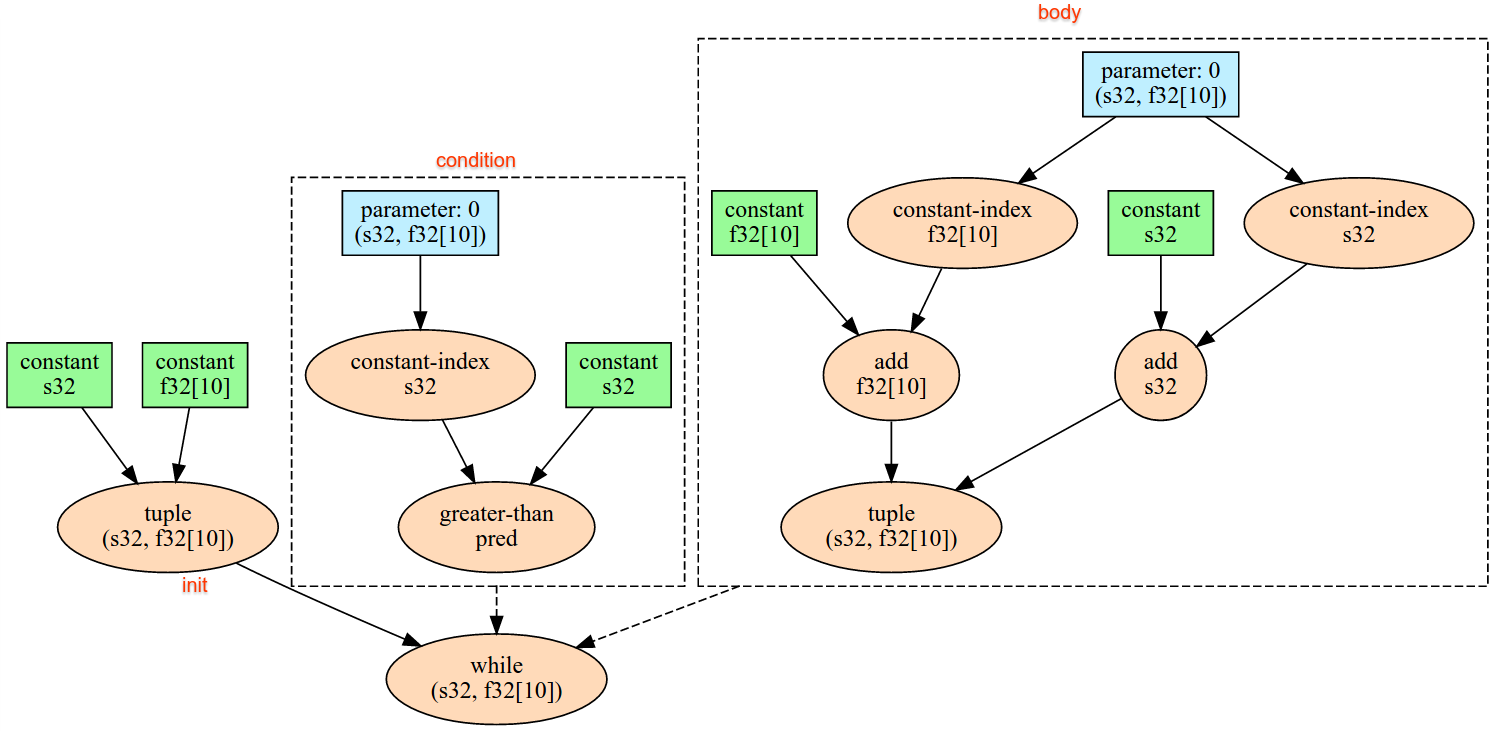
result1 = while (condition, init = init_value) {
Infeed(shape)
}
result2 = while (condition, init = result1) {
Infeed(shape)
}
নেস্টেড টুপল আকারগুলি সমর্থিত নয়। খালি টুপল আকারের জন্য, ইনফিড অপারেশন কার্যকরভাবে একটি নো-অপ এবং ডিভাইসের ইনফিড থেকে কোনও ডেটা না পড়ে এগিয়ে যায়।
আইওটা
XlaBuilder::Iota দেখুন।
Iota(shape, iota_dimension)
সম্ভাব্য বৃহত হোস্ট স্থানান্তরের পরিবর্তে ডিভাইসে একটি ধ্রুবক আক্ষরিক তৈরি করে। একটি অ্যারে তৈরি করে যা নির্দিষ্ট আকার নির্দিষ্ট করে এবং নির্দিষ্ট মাত্রা বরাবর একটি দ্বারা বর্ধিত করে মানগুলি ধরে রাখে। ভাসমান-পয়েন্ট ধরণের জন্য, উত্পাদিত অ্যারে ConvertElementType(Iota(...)) এর সমতুল্য যেখানে Iota অবিচ্ছেদ্য ধরণের এবং রূপান্তরটি ভাসমান-পয়েন্টের ধরণের।
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
shape | Shape | Iota() |
iota_dimension | int64 | বরাবর বৃদ্ধি করার মাত্রা। |
উদাহরণস্বরূপ, Iota(s32[4, 8], 0) রিটার্ন
[[0, 0, 0, 0, 0, 0, 0, 0 ],
[1, 1, 1, 1, 1, 1, 1, 1 ],
[2, 2, 2, 2, 2, 2, 2, 2 ],
[3, 3, 3, 3, 3, 3, 3, 3 ]]
Iota(s32[4, 8], 1) রিটার্ন
[[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ],
[0, 1, 2, 3, 4, 5, 6, 7 ]]
মানচিত্র
XlaBuilder::Map দেখুন।
Map(operands..., computation)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operands | এন XlaOp s এর ক্রম | N প্রকারের অ্যারে টি 0..t {n-1} |
computation | XlaComputation | টাইপ T_0, T_1, .., T_{N + M -1} -> S টাইপ টি এবং এম এর টাইপের এন প্যারামিটার সহ স্বেচ্ছাসেবী প্রকারের গণনা |
dimensions | int64 অ্যারে | মানচিত্রের মাত্রা অ্যারে |
প্রদত্ত operands অ্যারেগুলির উপরে একটি স্কেলার ফাংশন প্রয়োগ করে, একই মাত্রার একটি অ্যারে উত্পাদন করে যেখানে প্রতিটি উপাদান ইনপুট অ্যারে সম্পর্কিত উপাদানগুলিতে প্রয়োগ করা ম্যাপযুক্ত ফাংশনের ফলাফল।
ম্যাপযুক্ত ফাংশনটি হ'ল সীমাবদ্ধতার সাথে একটি স্বেচ্ছাসেবী গণনা যা এতে স্কেলার টাইপ T এর এন ইনপুট এবং টাইপ S সহ একটি একক আউটপুট রয়েছে। আউটপুটটির অপারেন্ডগুলির মতো একই মাত্রা রয়েছে ব্যতীত উপাদান টাইপ টি এস দিয়ে প্রতিস্থাপন করা হয়েছে
উদাহরণস্বরূপ: আউটপুট অ্যারে উত্পাদন করতে ইনপুট অ্যারে প্রতিটি (বহুমাত্রিক) সূচকটিতে এমএপি ( Map(op1, op2, op3, computation, par1) elem_out <- computation(elem1, elem2, elem3, par1)
অপ্টিমাইজেশনবারিয়ার
বাধা পেরিয়ে গণনা চলমান থেকে কোনও অপ্টিমাইজেশন পাস ব্লক করে।
বাধার আউটপুটগুলির উপর নির্ভর করে এমন কোনও অপারেটরগুলির আগে সমস্ত ইনপুটগুলি মূল্যায়ন করা হয় তা নিশ্চিত করে।
প্যাড
XlaBuilder::Pad দেখুন।
Pad(operand, padding_value, padding_config)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | টাইপ T এর অ্যারে |
padding_value | XlaOp | যুক্ত প্যাডিং পূরণ করতে টাইপ T এর স্কেলার |
padding_config | PaddingConfig | উভয় প্রান্তে (নিম্ন, উচ্চ) এবং প্রতিটি মাত্রার উপাদানগুলির মধ্যে প্যাডিংয়ের পরিমাণ |
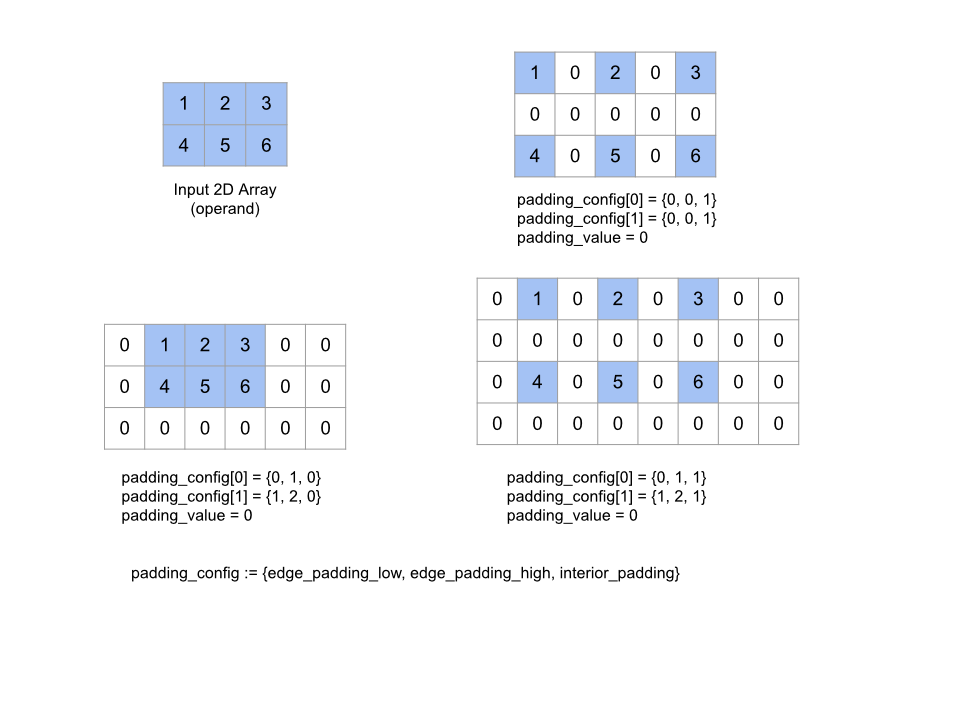
প্রদত্ত padding_value সহ অ্যারের উপাদানগুলির মধ্যে অ্যারের চারপাশে প্যাডিং দ্বারা প্রদত্ত operand অ্যারে প্রসারিত করে। padding_config প্রতিটি মাত্রার জন্য প্রান্ত প্যাডিংয়ের পরিমাণ এবং অভ্যন্তরীণ প্যাডিং নির্দিষ্ট করে।
PaddingConfig হ'ল PaddingConfigDimension একটি পুনরাবৃত্তি ক্ষেত্র, যা প্রতিটি মাত্রার জন্য তিনটি ক্ষেত্র ধারণ করে: edge_padding_low , edge_padding_high এবং interior_padding ।
edge_padding_low এবং edge_padding_high প্রতিটি মাত্রার যথাক্রমে নিম্ন-প্রান্তে (সূচক 0 এর পাশে) এবং উচ্চ-প্রান্তের (সর্বোচ্চ সূচকের পাশে) যুক্ত প্যাডিংয়ের পরিমাণ নির্দিষ্ট করে। প্রান্ত প্যাডিংয়ের পরিমাণ নেতিবাচক হতে পারে - নেতিবাচক প্যাডিংয়ের পরম মান নির্দিষ্ট মাত্রা থেকে সরানোর জন্য উপাদানগুলির সংখ্যা নির্দেশ করে।
interior_padding প্রতিটি মাত্রায় যে কোনও দুটি উপাদানের মধ্যে যুক্ত প্যাডিংয়ের পরিমাণ নির্দিষ্ট করে; এটি নেতিবাচক নাও হতে পারে। অভ্যন্তর প্যাডিং এজ প্যাডিংয়ের আগে যৌক্তিকভাবে ঘটে, সুতরাং নেতিবাচক প্রান্ত প্যাডিংয়ের ক্ষেত্রে উপাদানগুলি অভ্যন্তরীণ-প্যাডযুক্ত অপারেন্ড থেকে সরানো হয়।
এই অপারেশনটি একটি নো-অপ-যদি প্রান্ত প্যাডিং জোড়গুলি সমস্ত হয় edge_padding 0, 0) এবং interior_padding প্যাডিং মানগুলি সমস্ত 0 হয় 0
Recv
XlaBuilder::Recv দেখুন।
Recv(shape, channel_handle)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
shape | Shape | প্রাপ্ত ডেটা আকার |
channel_handle | ChannelHandle | প্রতিটি প্রেরণ/আরইসিভি জুটির জন্য অনন্য শনাক্তকারী |
একই চ্যানেল হ্যান্ডেলটি ভাগ করে এমন অন্য গণনায় Send নির্দেশ থেকে প্রদত্ত আকারের ডেটা গ্রহণ করে। প্রাপ্ত ডেটার জন্য একটি এক্সএলওপি ফেরত দেয়।
Recv অপারেশনের ক্লায়েন্ট এপিআই সিঙ্ক্রোনাস যোগাযোগের প্রতিনিধিত্ব করে। যাইহোক, অ্যাসিঙ্ক্রোনাস ডেটা ট্রান্সফার সক্ষম করতে নির্দেশটি অভ্যন্তরীণভাবে 2 এইচএলও নির্দেশাবলীতে ( Recv এবং RecvDone ) পচে যায়। HloInstruction::CreateRecv এবং HloInstruction::CreateRecvDone দেখুন।
Recv(const Shape& shape, int64 channel_id)
একই চ্যানেল_আইডি সহ Send নির্দেশ থেকে ডেটা গ্রহণের জন্য প্রয়োজনীয় সংস্থানগুলি বরাদ্দ করে। বরাদ্দকৃত সংস্থানগুলির জন্য একটি প্রসঙ্গ প্রদান করে, যা ডেটা স্থানান্তর সমাপ্তির জন্য অপেক্ষা করতে নিম্নলিখিত RecvDone নির্দেশ দ্বারা ব্যবহৃত হয়। প্রসঙ্গটি হ'ল {রিসিভ বাফার (শেপ), অনুরোধ শনাক্তকারী (u32)} এর একটি টিপল এবং এটি কেবল একটি RecvDone নির্দেশ দ্বারা ব্যবহার করা যেতে পারে।
RecvDone(HloInstruction context)
একটি Recv নির্দেশাবলী দ্বারা তৈরি একটি প্রসঙ্গ দেওয়া, ডেটা স্থানান্তর সম্পূর্ণ করার জন্য অপেক্ষা করে এবং প্রাপ্ত ডেটা ফেরত দেয়।
কমিয়ে দিন
সমান্তরালে এক বা একাধিক অ্যারে হ্রাস ফাংশন প্রয়োগ করে।
Reduce(operands..., init_values..., computation, dimensions)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operands | এন XlaOp এর ক্রম | N প্রকারের T_0, ..., T_{N-1} এর অ্যারে} |
init_values | এন XlaOp এর ক্রম | N টাইপের স্কেলার T_0, ..., T_{N-1} |
computation | XlaComputation | T_0, ..., T_{N-1}, T_0, ..., T_{N-1} -> Collate(T_0, ..., T_{N-1}) টাইপের গণনা। |
dimensions | int64 অ্যারে | হ্রাস করার জন্য মাত্রাগুলির আন্ডার অর্ডার করা অ্যারে। |
কোথায়:
- N বৃহত্তর বা 1 এর সমান হতে হবে।
- গণনাটি "মোটামুটি" সহযোগী হতে হবে (নীচে দেখুন)।
- সমস্ত ইনপুট অ্যারে একই মাত্রা থাকতে হবে।
- সমস্ত প্রাথমিক মানগুলি
computationঅধীনে একটি পরিচয় তৈরি করতে হবে। - যদি
N = 1,Collate(T)Tহয়। - যদি
N > 1,Collate(T_0, ..., T_{N-1})টাইপTএরNউপাদানগুলির একটি টিপল।
এই অপারেশন প্রতিটি ইনপুট অ্যারের এক বা একাধিক মাত্রা স্কেলারে হ্রাস করে। প্রতিটি প্রত্যাবর্তিত অ্যারের র্যাঙ্ক হ'ল rank(operand) - len(dimensions) । ওপিটির আউটপুটটি হ'ল Collate(Q_0, ..., Q_N) যেখানে Q_i টাইপ T_i এর একটি অ্যারে, যার মাত্রা নীচে বর্ণিত হয়েছে।
বিভিন্ন ব্যাকেন্ডকে হ্রাস গণনা পুনরায় সংস্কার করার অনুমতি দেওয়া হয়। এটি সংখ্যার পার্থক্যের দিকে নিয়ে যেতে পারে, কারণ সংযোজনের মতো কিছু হ্রাস ফাংশনগুলি ভাসমানগুলির জন্য সংযুক্ত নয়। তবে, যদি ডেটার পরিসীমা সীমিত হয় তবে ভাসমান-পয়েন্ট সংযোজন বেশিরভাগ ব্যবহারিক ব্যবহারের জন্য সহযোগী হওয়ার পক্ষে যথেষ্ট কাছাকাছি।
উদাহরণ
যখন মান [10, 11, 12, 13] এর সাথে একক 1 ডি অ্যারেতে একটি মাত্রা জুড়ে হ্রাস করার সময়, হ্রাস ফাংশন f (এটি computation ) সহ এটি হিসাবে গণনা করা যেতে পারে
f(10, f(11, f(12, f(init_value, 13)))
তবে আরও অনেক সম্ভাবনা রয়েছে, যেমন
f(init_value, f(f(10, f(init_value, 11)), f(f(init_value, 12), f(init_value, 13))))
নীচে 0 এর প্রাথমিক মান সহ হ্রাস গণনা হিসাবে সংক্ষিপ্তকরণ ব্যবহার করে কীভাবে হ্রাস প্রয়োগ করা যেতে পারে তার একটি রুক্ষ সিউডো-কোডের উদাহরণ নীচে দেওয়া হয়েছে।
result_shape <- remove all dims in dimensions from operand_shape
# Iterate over all elements in result_shape. The number of r's here is equal
# to the rank of the result
for r0 in range(result_shape[0]), r1 in range(result_shape[1]), ...:
# Initialize this result element
result[r0, r1...] <- 0
# Iterate over all the reduction dimensions
for d0 in range(dimensions[0]), d1 in range(dimensions[1]), ...:
# Increment the result element with the value of the operand's element.
# The index of the operand's element is constructed from all ri's and di's
# in the right order (by construction ri's and di's together index over the
# whole operand shape).
result[r0, r1...] += operand[ri... di]
এখানে 2 ডি অ্যারে (ম্যাট্রিক্স) হ্রাস করার উদাহরণ রয়েছে। আকৃতির 2 র্যাঙ্ক 2, আকারের 2 এর মাত্রা 0 এবং আকার 3 এর মাত্রা 1:
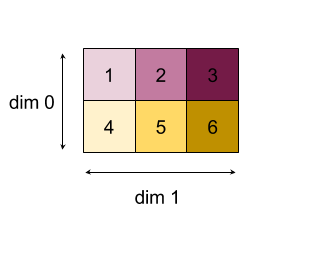
"অ্যাড" ফাংশন সহ 0 বা 1 মাত্রা হ্রাস করার ফলাফল:
নোট করুন যে উভয় হ্রাস ফলাফল 1D অ্যারে। ডায়াগ্রামটি একটি কলাম হিসাবে এবং অন্যটি কেবল ভিজ্যুয়াল সুবিধার জন্য সারি হিসাবে দেখায়।
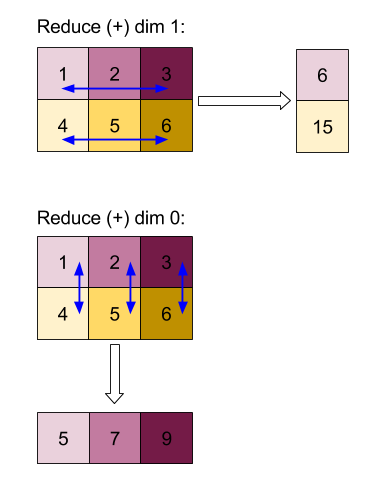
আরও জটিল উদাহরণের জন্য, এখানে একটি 3 ডি অ্যারে রয়েছে। এর র্যাঙ্কটি 3, আকারের 4 এর মাত্রা 0, আকারের 2 এর মাত্রা 1 এবং আকারের 2 মাত্রা 2 3 সরলতার জন্য, 1 থেকে 6 মানগুলি মাত্রা 0 জুড়ে প্রতিলিপি করা হয়।
একইভাবে 2 ডি উদাহরণ হিসাবে, আমরা কেবল একটি মাত্রা হ্রাস করতে পারি। উদাহরণস্বরূপ, আমরা যদি মাত্রা 0 হ্রাস করি, উদাহরণস্বরূপ, আমরা একটি র্যাঙ্ক -২ অ্যারে পাই যেখানে মাত্রা 0 জুড়ে সমস্ত মান একটি স্কেলারে ভাঁজ করা হয়েছিল:
| 4 8 12 |
| 16 20 24 |
যদি আমরা মাত্রা 2 হ্রাস করি তবে আমরা একটি র্যাঙ্ক -2 অ্যারেও পাই যেখানে মাত্রা 2 জুড়ে সমস্ত মান একটি স্কেলারে ভাঁজ করা হয়েছিল:
| 6 15 |
| 6 15 |
| 6 15 |
| 6 15 |
নোট করুন যে ইনপুটটিতে অবশিষ্ট মাত্রাগুলির মধ্যে আপেক্ষিক ক্রমটি আউটপুটটিতে সংরক্ষণ করা হয়েছে, তবে কিছু মাত্রা নতুন সংখ্যা নির্ধারিত হতে পারে (যেহেতু র্যাঙ্ক পরিবর্তনের পরে)।
আমরা একাধিক মাত্রা হ্রাস করতে পারি। 0 এবং 1 অ্যাড-হ্রাসের মাত্রা 1D অ্যারে [20, 28, 36] উত্পাদন করে।
এর সমস্ত মাত্রার উপরে 3 ডি অ্যারে হ্রাস করা স্কেলার 84 উত্পাদন করে।
ভেরিয়াডিক হ্রাস
যখন N > 1 , ফাংশন অ্যাপ্লিকেশন হ্রাস করুন কিছুটা জটিল, কারণ এটি সমস্ত ইনপুটগুলিতে একই সাথে প্রয়োগ করা হয়। অপারেশনগুলি নিম্নলিখিত ক্রমে গণনায় সরবরাহ করা হয়:
- প্রথম অপারেন্ডের জন্য হ্রাস মান চলমান
- ...
- N'th operand এর জন্য হ্রাস মূল্য চলমান
- প্রথম অপারেন্ডের জন্য ইনপুট মান
- ...
- N'th অপারেন্ডের জন্য ইনপুট মান
উদাহরণস্বরূপ, নিম্নলিখিত হ্রাস ফাংশনটি বিবেচনা করুন, যা সমান্তরালে 1-ডি অ্যারের সর্বোচ্চ এবং আরগম্যাক্স গণনা করতে ব্যবহার করা যেতে পারে:
f: (Float, Int, Float, Int) -> Float, Int
f(max, argmax, value, index):
if value >= max:
return (value, index)
else:
return (max, argmax)
1-ডি ইনপুট অ্যারে V = Float[N], K = Int[N] , এবং ইনিশ মানগুলি I_V = Float, I_K = Int , ফলাফলের f_(N-1) কেবলমাত্র ইনপুট মাত্রা হ্রাস করার সমতুল্য নিম্নলিখিত পুনরাবৃত্ত অ্যাপ্লিকেশন:
f_0 = f(I_V, I_K, V_0, K_0)
f_1 = f(f_0.first, f_0.second, V_1, K_1)
...
f_(N-1) = f(f_(N-2).first, f_(N-2).second, V_(N-1), K_(N-1))
মানগুলির একটি অ্যারে এবং সিক্যুয়াল সূচকগুলির একটি অ্যারে (অর্থাত্ আইওটিএ) এই হ্রাস প্রয়োগ করা অ্যারেগুলির উপর সহযোগিতা করবে এবং সর্বাধিক মান এবং ম্যাচিং সূচকযুক্ত একটি টিপল ফিরিয়ে দেবে।
হ্রাস
XlaBuilder::ReducePrecision দেখুন।
মডেলগুলি ভাসমান-পয়েন্ট মানগুলিকে একটি নিম্ন-নির্ভুলতা বিন্যাসে (যেমন আইইইইই-এফপি 16) রূপান্তর করার এবং মূল বিন্যাসে ফিরে যাওয়ার প্রভাব। নিম্ন-নির্ভুলতা বিন্যাসে এক্সপোনেন্ট এবং ম্যান্টিসা বিটের সংখ্যা নির্বিচারে নির্দিষ্ট করা যেতে পারে, যদিও সমস্ত বিট আকারগুলি সমস্ত হার্ডওয়্যার বাস্তবায়নে সমর্থিত হতে পারে না।
ReducePrecision(operand, mantissa_bits, exponent_bits)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | ভাসমান-পয়েন্ট টাইপ T এর অ্যারে। |
exponent_bits | int32 | নিম্ন-নির্ভুলতা বিন্যাসে এক্সপোনেন্ট বিটের সংখ্যা |
mantissa_bits | int32 | নিম্ন-নির্ভুলতা বিন্যাসে ম্যান্টিসা বিটের সংখ্যা |
ফলাফলটি টাইপ T এর একটি অ্যারে। ইনপুট মানগুলি প্রদত্ত ম্যান্টিসা বিটগুলির সাথে প্রতিনিধিত্বযোগ্য নিকটতম মানকে গোল করা হয় ("এমনকি" শব্দার্থবিজ্ঞানের সাথে "সম্পর্কগুলি ব্যবহার করে) এবং এক্সপোনেন্ট বিটগুলির সংখ্যা দ্বারা নির্দিষ্ট পরিসীমা অতিক্রম করে এমন কোনও মানকে ইতিবাচক বা নেতিবাচক অনন্তে আবদ্ধ করা হয়। NaN মানগুলি ধরে রাখা হয়, যদিও এগুলি ক্যানোনিকাল NaN মানগুলিতে রূপান্তরিত হতে পারে।
নিম্ন-নির্ভুলতা ফর্ম্যাটটিতে অবশ্যই কমপক্ষে একটি এক্সপোনেন্ট বিট থাকতে হবে (একটি অনন্ত থেকে শূন্য মানকে আলাদা করার জন্য, যেহেতু উভয়েরই শূন্য ম্যান্টিসা রয়েছে) এবং অবশ্যই ম্যান্টিসা বিটগুলির একটি অ-নেতিবাচক সংখ্যা থাকতে হবে। এক্সপোনেন্ট বা ম্যান্টিসা বিটগুলির সংখ্যা টাইপ T এর জন্য সংশ্লিষ্ট মান ছাড়িয়ে যেতে পারে; রূপান্তরটির সংশ্লিষ্ট অংশটি তখন কেবল একটি নো-অপ।
হ্রাস করা
XlaBuilder::ReduceScatter এছাড়াও দেখুন।
রিডুসেস্টার হ'ল একটি সম্মিলিত অপারেশন যা কার্যকরভাবে একটি অ্যাল্রেডুস করে এবং তারপরে ফলাফলটি ছড়িয়ে দেয় এটি scatter_dimension বরাবর shard_count ব্লকগুলিতে বিভক্ত করে এবং প্রতিলিপি গ্রুপে i ith শার্ড গ্রহণ করে।
ReduceScatter(operand, computation, scatter_dim, shard_count, replica_group_ids, channel_id)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | প্রতিলিপিগুলি হ্রাস করতে অ্যারে বা অ্যারে-খালি অ্যারে। |
computation | XlaComputation | হ্রাস গণনা |
scatter_dimension | int64 | বিক্ষিপ্ত মাত্রা। |
shard_count | int64 | scatter_dimension বিভক্ত করতে ব্লকের সংখ্যা |
replica_groups | int64 এর ভেক্টর ভেক্টর | এর মধ্যে গ্রুপগুলি হ্রাস করা হয় |
channel_id | ঐচ্ছিক int64 | ক্রস-মডিউল যোগাযোগের জন্য al চ্ছিক চ্যানেল আইডি |
- যখন
operandঅ্যারেগুলির একটি টুপল হয়, তখন হ্রাস-ছানাটি টিপলের প্রতিটি উপাদানটিতে সঞ্চালিত হয়। -
replica_groupsহ'ল প্রতিলিপি গোষ্ঠীর একটি তালিকা যার মধ্যে হ্রাস সম্পাদন করা হয় (বর্তমান প্রতিরূপের জন্য প্রতিরূপ আইডি প্রতিলিপি ব্যবহার করেReplicaIdকরা যেতে পারে)। প্রতিটি গ্রুপে প্রতিলিপিগুলির ক্রমটি সেই ক্রমটি নির্ধারণ করে যেখানে সর্ব-হ্রাসের ফলাফলটি ছড়িয়ে ছিটিয়ে থাকবে।replica_groupsঅবশ্যই খালি থাকতে হবে (সেক্ষেত্রে সমস্ত প্রতিলিপিগুলি একক গোষ্ঠীর অন্তর্গত), বা প্রতিরূপের সংখ্যার সমান সংখ্যক উপাদান থাকতে পারে। যখন একাধিক প্রতিলিপি গোষ্ঠী থাকে তখন সেগুলি অবশ্যই একই আকারের হতে হবে। উদাহরণস্বরূপ,replica_groups = {0, 2}, {1, 3}প্রতিলিপি0এবং2, এবং1এবং3এর মধ্যে হ্রাস সম্পাদন করে এবং তারপরে ফলাফলটি ছড়িয়ে দেয়। -
shard_countহ'ল প্রতিটি প্রতিলিপি গোষ্ঠীর আকার।replica_groupsখালি রয়েছে এমন ক্ষেত্রে আমাদের এটি প্রয়োজন। যদিreplica_groupsখালি না থাকে তবেshard_countঅবশ্যই প্রতিটি প্রতিরূপ গোষ্ঠীর আকারের সমান হতে হবে। -
channel_idক্রস-মডিউল যোগাযোগের জন্য ব্যবহৃত হয়: কেবলমাত্র একইchannel_idসহreduce-scatterঅপারেশনগুলি একে অপরের সাথে যোগাযোগ করতে পারে।
আউটপুট আকৃতিটি scatter_dimension তৈরি shard_count বার ছোট সহ ইনপুট আকার। উদাহরণস্বরূপ, যদি দুটি প্রতিলিপি থাকে এবং অপারেন্ডের মানটি যথাক্রমে [1.0, 2.25] এবং [3.0, 5.25] থাকে যথাক্রমে দুটি প্রতিরূপের উপর, তবে এই ওপি থেকে আউটপুট মান যেখানে scatter_dim 0 হয় [4.0] প্রথমটির জন্য [4.0] হবে [4.0] দ্বিতীয় প্রতিরূপের জন্য প্রতিলিপি এবং [7.5] ।
হ্রাস করুন
আউটপুট হিসাবে এন বহু-মাত্রিক অ্যারেগুলির একক বা একটি টুপল উত্পাদন করে এন বহুমাত্রিক অ্যারেগুলির ক্রমের প্রতিটি উইন্ডোতে সমস্ত উপাদানগুলিতে হ্রাস ফাংশন প্রয়োগ করে। প্রতিটি আউটপুট অ্যারে উইন্ডোর বৈধ অবস্থানের সংখ্যার সমান সংখ্যক উপাদান থাকে। একটি পুলিং স্তর ReduceWindow হিসাবে প্রকাশ করা যেতে পারে। Reduce মতো, প্রয়োগ করা computation সর্বদা বাম-হাতের init_values পাস করা হয়।
ReduceWindow(operands..., init_values..., computation, window_dimensions, window_strides, padding)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operands | N XlaOps | T_0,..., T_{N-1} প্রকারের n বহুমাত্রিক অ্যারেগুলির একটি ক্রম, প্রতিটি বেস অঞ্চলটি প্রতিনিধিত্ব করে যেখানে উইন্ডোটি স্থাপন করা হয়। |
init_values | N XlaOps | হ্রাসের জন্য এন প্রারম্ভিক মানগুলি, প্রতিটি এন অপারেন্ডের জন্য একটি। বিশদ জন্য হ্রাস দেখুন। |
computation | XlaComputation | টাইপ T_0, ..., T_{N-1}, T_0, ..., T_{N-1} -> Collate(T_0, ..., T_{N-1}) হ্রাস ফাংশন সমস্ত ইনপুট অপারেশনগুলির প্রতিটি উইন্ডোতে উপাদান। |
window_dimensions | ArraySlice<int64> | উইন্ডো মাত্রা মানগুলির জন্য পূর্ণসংখ্যার অ্যারে |
window_strides | ArraySlice<int64> | উইন্ডো স্ট্রাইড মানগুলির জন্য পূর্ণসংখ্যার অ্যারে |
base_dilations | ArraySlice<int64> | বেস ডিলেশন মানগুলির জন্য পূর্ণসংখ্যার অ্যারে |
window_dilations | ArraySlice<int64> | উইন্ডো ডিলেশন মানগুলির জন্য পূর্ণসংখ্যার অ্যারে |
padding | Padding | উইন্ডোটির জন্য প্যাডিং টাইপ (প্যাডিং :: কেমে, যা প্যাডগুলি যাতে ইনপুট হিসাবে একই আউটপুট আকৃতি থাকে যদি স্ট্রাইড 1 হয়, বা প্যাডিং :: কেভালিড, যা কোনও প্যাডিং ব্যবহার করে না এবং উইন্ডোটি আর ফিট না হলে "থামে" |
কোথায়:
- N বৃহত্তর বা 1 এর সমান হতে হবে।
- সমস্ত ইনপুট অ্যারে একই মাত্রা থাকতে হবে।
- যদি
N = 1,Collate(T)Tহয়। - যদি
N > 1,Collate(T_0, ..., T_{N-1})টাইপেরNউপাদানগুলির একটি টুপল(T0,...T{N-1})।
কোড এবং চিত্রের নীচে ReduceWindow ব্যবহারের একটি উদাহরণ দেখায়। ইনপুট আকারের একটি ম্যাট্রিক্স [4x6] এবং উভয় উইন্ডো_ডিমেনশন এবং উইন্ডো_স্ট্রাইড_ডিমেনশনগুলি [2x3]।
// Create a computation for the reduction (maximum).
XlaComputation max;
{
XlaBuilder builder(client_, "max");
auto y = builder.Parameter(0, ShapeUtil::MakeShape(F32, {}), "y");
auto x = builder.Parameter(1, ShapeUtil::MakeShape(F32, {}), "x");
builder.Max(y, x);
max = builder.Build().value();
}
// Create a ReduceWindow computation with the max reduction computation.
XlaBuilder builder(client_, "reduce_window_2x3");
auto shape = ShapeUtil::MakeShape(F32, {4, 6});
auto input = builder.Parameter(0, shape, "input");
builder.ReduceWindow(
input,
/*init_val=*/builder.ConstantLiteral(LiteralUtil::MinValue(F32)),
*max,
/*window_dimensions=*/{2, 3},
/*window_stride_dimensions=*/{2, 3},
Padding::kValid);
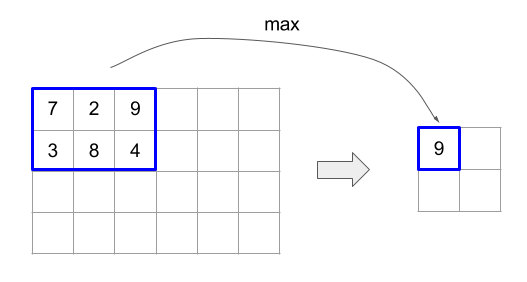
একটি মাত্রায় 1 এর স্ট্রাইড নির্দিষ্ট করে যে মাত্রায় একটি উইন্ডোর অবস্থান তার সংলগ্ন উইন্ডো থেকে 1 উপাদান দূরে। একে অপরের সাথে কোনও উইন্ডো ওভারল্যাপ করে না এমন নির্দিষ্ট করার জন্য, উইন্ডো_স্ট্রাইড_ডিমেনশনগুলি উইন্ডো_ডিমেনশনের সমান হওয়া উচিত। নীচের চিত্রটি দুটি পৃথক স্ট্রাইড মান ব্যবহারের চিত্রিত করে। প্যাডিং ইনপুটটির প্রতিটি মাত্রায় প্রয়োগ করা হয় এবং গণনাগুলি একই রকম হয় যদিও প্যাডিংয়ের পরে এটি যে মাত্রা রয়েছে তার সাথে ইনপুটটি এসেছিল।
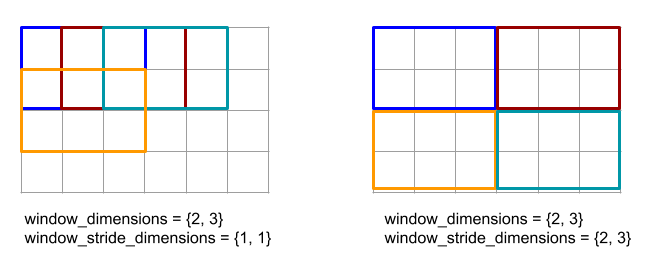
একটি অ-তুচ্ছ প্যাডিংয়ের উদাহরণের জন্য, ডাইমেনশন 3 সহ কমন-উইন্ডো ন্যূনতম (প্রাথমিক মানটি MAX_FLOAT ) এবং ইনপুট অ্যারে [10000, 1000, 100, 10, 1] এর উপরে স্ট্রাইড 2 এর কমপুটকে বিবেচনা করুন। Padding kValid computes minimums over two valid windows: [10000, 1000, 100] and [100, 10, 1] , resulting in the output [100, 1] . Padding kSame first pads the array so that the shape after the reduce-window would be the same as input for stride one by adding initial elements on both sides, getting [MAX_VALUE, 10000, 1000, 100, 10, 1, MAX_VALUE] . Running reduce-window over the padded array operates on three windows [MAX_VALUE, 10000, 1000] , [1000, 100, 10] , [10, 1, MAX_VALUE] , and yields [1000, 10, 1] .
The evaluation order of the reduction function is arbitrary and may be non-deterministic. Therefore, the reduction function should not be overly sensitive to reassociation. See the discussion about associativity in the context of Reduce for more details.
ReplicaId
See also XlaBuilder::ReplicaId .
Returns the unique ID (U32 scalar) of the replica.
ReplicaId()
The unique ID of each replica is an unsigned integer in the interval [0, N) , where N is the number of replicas. Since all the replicas are running the same program, a ReplicaId() call in the program will return a different value on each replica.
পুনরায় আকার দিন
See also XlaBuilder::Reshape and the Collapse operation.
Reshapes the dimensions of an array into a new configuration.
Reshape(operand, new_sizes) Reshape(operand, dimensions, new_sizes)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | array of type T |
dimensions | int64 vector | order in which dimensions are collapsed |
new_sizes | int64 vector | vector of sizes of new dimensions |
Conceptually, reshape first flattens an array into a one-dimensional vector of data values, and then refines this vector into a new shape. The input arguments are an arbitrary array of type T, a compile-time-constant vector of dimension indices, and a compile-time-constant vector of dimension sizes for the result. The values in the dimension vector, if given, must be a permutation of all of T's dimensions; the default if not given is {0, ..., rank - 1} . The order of the dimensions in dimensions is from slowest-varying dimension (most major) to fastest-varying dimension (most minor) in the loop nest which collapses the input array into a single dimension. The new_sizes vector determines the size of the output array. The value at index 0 in new_sizes is the size of dimension 0, the value at index 1 is the size of dimension 1, and so on. The product of the new_size dimensions must equal the product of the operand's dimension sizes. When refining the collapsed array into the multidimensional array defined by new_sizes , the dimensions in new_sizes are ordered from slowest varying (most major) and to fastest varying (most minor).
For example, let v be an array of 24 elements:
let v = f32[4x2x3] { { {10, 11, 12}, {15, 16, 17} },
{ {20, 21, 22}, {25, 26, 27} },
{ {30, 31, 32}, {35, 36, 37} },
{ {40, 41, 42}, {45, 46, 47} } };
In-order collapse:
let v012_24 = Reshape(v, {0,1,2}, {24});
then v012_24 == f32[24] {10, 11, 12, 15, 16, 17, 20, 21, 22, 25, 26, 27,
30, 31, 32, 35, 36, 37, 40, 41, 42, 45, 46, 47};
let v012_83 = Reshape(v, {0,1,2}, {8,3});
then v012_83 == f32[8x3] { {10, 11, 12}, {15, 16, 17},
{20, 21, 22}, {25, 26, 27},
{30, 31, 32}, {35, 36, 37},
{40, 41, 42}, {45, 46, 47} };
Out-of-order collapse:
let v021_24 = Reshape(v, {1,2,0}, {24});
then v012_24 == f32[24] {10, 20, 30, 40, 11, 21, 31, 41, 12, 22, 32, 42,
15, 25, 35, 45, 16, 26, 36, 46, 17, 27, 37, 47};
let v021_83 = Reshape(v, {1,2,0}, {8,3});
then v021_83 == f32[8x3] { {10, 20, 30}, {40, 11, 21},
{31, 41, 12}, {22, 32, 42},
{15, 25, 35}, {45, 16, 26},
{36, 46, 17}, {27, 37, 47} };
let v021_262 = Reshape(v, {1,2,0}, {2,6,2});
then v021_262 == f32[2x6x2] { { {10, 20}, {30, 40},
{11, 21}, {31, 41},
{12, 22}, {32, 42} },
{ {15, 25}, {35, 45},
{16, 26}, {36, 46},
{17, 27}, {37, 47} } };
As a special case, reshape can transform a single-element array to a scalar and vice versa. উদাহরণ স্বরূপ,
Reshape(f32[1x1] { {5} }, {0,1}, {}) == 5;
Reshape(5, {}, {1,1}) == f32[1x1] { {5} };
Rev (reverse)
See also XlaBuilder::Rev .
Rev(operand, dimensions)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | array of type T |
dimensions | ArraySlice<int64> | dimensions to reverse |
Reverses the order of elements in the operand array along the specified dimensions , generating an output array of the same shape. Each element of the operand array at a multidimensional index is stored into the output array at a transformed index. The multidimensional index is transformed by reversing the index in each dimension to be reversed (ie, if a dimension of size N is one of the reversing dimensions, its index i is transformed into N - 1 - i).
One use for the Rev operation is to reverse the convolution weight array along the two window dimensions during the gradient computation in neural networks.
RngNormal
See also XlaBuilder::RngNormal .
Constructs an output of a given shape with random numbers generated following the \(N(\mu, \sigma)\) normal distribution. The parameters \(\mu\) and \(\sigma\), and output shape have to have a floating point elemental type. The parameters furthermore have to be scalar valued.
RngNormal(mu, sigma, shape)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
mu | XlaOp | Scalar of type T specifying mean of generated numbers |
sigma | XlaOp | Scalar of type T specifying standard deviation of generated |
shape | Shape | Output shape of type T |
RngUniform
See also XlaBuilder::RngUniform .
Constructs an output of a given shape with random numbers generated following the uniform distribution over the interval \([a,b)\). The parameters and output element type have to be a boolean type, an integral type or a floating point types, and the types have to be consistent. The CPU and GPU backends currently only support F64, F32, F16, BF16, S64, U64, S32 and U32. Furthermore, the parameters need to be scalar valued. If \(b <= a\) the result is implementation-defined.
RngUniform(a, b, shape)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
a | XlaOp | Scalar of type T specifying lower limit of interval |
b | XlaOp | Scalar of type T specifying upper limit of interval |
shape | Shape | Output shape of type T |
RngBitGenerator
Generates an output with a given shape filled with uniform random bits using the specified algorithm (or backend default) and returns an updated state (with the same shape as initial state) and the generated random data.
Initial state is the initial state of the current random number generation. It and the required shape and valid values are dependent on the algorithm used.
The output is guaranteed to be a deterministic function of the initial state but it is not guaranteed to be deterministic between backends and different compiler versions.
RngBitGenerator(algorithm, key, shape)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
algorithm | RandomAlgorithm | PRNG algorithm to be used. |
initial_state | XlaOp | Initial state for the PRNG algorithm. |
shape | Shape | Output shape for generated data. |
Available values for algorithm :
rng_default: Backend specific algorithm with backend specific shape requirements.rng_three_fry: ThreeFry counter-based PRNG algorithm. Theinitial_stateshape isu64[2]with arbitrary values. সালমন এট আল। SC 2011. Parallel random numbers: as easy as 1, 2, 3.rng_philox: Philox algorithm to generate random numbers in parallel. Theinitial_stateshape isu64[3]with arbitrary values. সালমন এট আল। SC 2011. Parallel random numbers: as easy as 1, 2, 3.
ছিটান
The XLA scatter operation generates a sequence of results which are the values of the input array operands , with several slices (at indices specified by scatter_indices ) updated with the sequence of values in updates using update_computation .
See also XlaBuilder::Scatter .
scatter(operands..., scatter_indices, updates..., update_computation, index_vector_dim, update_window_dims, inserted_window_dims, scatter_dims_to_operand_dims)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operands | Sequence of N XlaOp | N arrays of types T_0, ..., T_N to be scattered into. |
scatter_indices | XlaOp | Array containing the starting indices of the slices that must be scattered to. |
updates | Sequence of N XlaOp | N arrays of types T_0, ..., T_N . updates[i] contains the values that must be used for scattering operands[i] . |
update_computation | XlaComputation | Computation to be used for combining the existing values in the input array and the updates during scatter. This computation should be of type T_0, ..., T_N, T_0, ..., T_N -> Collate(T_0, ..., T_N) . |
index_vector_dim | int64 | The dimension in scatter_indices that contains the starting indices. |
update_window_dims | ArraySlice<int64> | The set of dimensions in updates shape that are window dimensions . |
inserted_window_dims | ArraySlice<int64> | The set of window dimensions that must be inserted into updates shape. |
scatter_dims_to_operand_dims | ArraySlice<int64> | A dimensions map from the scatter indices to the operand index space. This array is interpreted as mapping i to scatter_dims_to_operand_dims[i] . It has to be one-to-one and total. |
indices_are_sorted | bool | Whether the indices are guaranteed to be sorted by the caller. |
কোথায়:
- N is required to be greater or equal to 1.
-
operands[0], ...,operands[N-1] must all have the same dimensions. -
updates[0], ...,updates[N-1] must all have the same dimensions. - If
N = 1,Collate(T)isT. - If
N > 1,Collate(T_0, ..., T_N)is a tuple ofNelements of typeT.
If index_vector_dim is equal to scatter_indices.rank we implicitly consider scatter_indices to have a trailing 1 dimension.
We define update_scatter_dims of type ArraySlice<int64> as the set of dimensions in updates shape that are not in update_window_dims , in ascending order.
The arguments of scatter should follow these constraints:
Each
updatesarray must be of rankupdate_window_dims.size + scatter_indices.rank - 1.Bounds of dimension
iin eachupdatesarray must conform to the following:- If
iis present inupdate_window_dims(ie equal toupdate_window_dims[k] for somek), then the bound of dimensioniinupdatesmust not exceed the corresponding bound ofoperandafter accounting for theinserted_window_dims(ieadjusted_window_bounds[k], whereadjusted_window_boundscontains the bounds ofoperandwith the bounds at indicesinserted_window_dimsremoved). - If
iis present inupdate_scatter_dims(ie equal toupdate_scatter_dims[k] for somek), then the bound of dimensioniinupdatesmust be equal to the corresponding bound ofscatter_indices, skippingindex_vector_dim(iescatter_indices.shape.dims[k], ifk<index_vector_dimandscatter_indices.shape.dims[k+1] otherwise).
- If
update_window_dimsmust be in ascending order, not have any repeating dimension numbers, and be in the range[0, updates.rank).inserted_window_dimsmust be in ascending order, not have any repeating dimension numbers, and be in the range[0, operand.rank).operand.rankmust equal the sum ofupdate_window_dims.sizeandinserted_window_dims.size.scatter_dims_to_operand_dims.sizemust be equal toscatter_indices.shape.dims[index_vector_dim], and its values must be in the range[0, operand.rank).
For a given index U in each updates array, the corresponding index I in the corresponding operands array into which this update has to be applied is computed as follows:
- Let
G= {U[k] forkinupdate_scatter_dims}. UseGto look up an index vectorSin thescatter_indicesarray such thatS[i] =scatter_indices[Combine(G,i)] where Combine(A, b) inserts b at positionsindex_vector_diminto A. - Create an index
SinintooperandusingSby scatteringSusing thescatter_dims_to_operand_dimsmap. আরো আনুষ্ঠানিকভাবে:-
Sin[scatter_dims_to_operand_dims[k]] =S[k] ifk<scatter_dims_to_operand_dims.size. -
Sin[_] =0otherwise.
-
- Create an index
Wininto eachoperandsarray by scattering the indices atupdate_window_dimsinUaccording toinserted_window_dims. আরো আনুষ্ঠানিকভাবে:-
Win[window_dims_to_operand_dims(k)] =U[k] ifkis inupdate_window_dims, wherewindow_dims_to_operand_dimsis the monotonic function with domain [0,update_window_dims.size) and range [0,operand.rank) \inserted_window_dims. (For example, ifupdate_window_dims.sizeis4,operand.rankis6, andinserted_window_dimsis {0,2} thenwindow_dims_to_operand_dimsis {0→1,1→3,2→4,3→5}). -
Win[_] =0otherwise.
-
-
IisWin+Sinwhere + is element-wise addition.
In summary, the scatter operation can be defined as follows.
- Initialize
outputwithoperands, ie for all indicesJ, for all indicesOin theoperands[J] array:
output[J][O] =operands[J][O] - For every index
Uin theupdates[J] array and the corresponding indexOin theoperand[J] array, ifOis a valid index foroutput:
(output[0][O], ...,output[N-1][O]) =update_computation(output[0][O], ..., ,output[N-1][O],updates[0][U], ...,updates[N-1][U])
The order in which updates are applied is non-deterministic. So, when multiple indices in updates refer to the same index in operands , the corresponding value in output will be non-deterministic.
Note that the first parameter that is passed into the update_computation will always be the current value from the output array and the second parameter will always be the value from the updates array. This is important specifically for cases when the update_computation is not commutative .
If indices_are_sorted is set to true then XLA can assume that start_indices are sorted (in ascending start_index_map order) by the user. If they are not then the semantics is implementation defined.
Informally, the scatter op can be viewed as an inverse of the gather op, ie the scatter op updates the elements in the input that are extracted by the corresponding gather op.
For a detailed informal description and examples, refer to the "Informal Description" section under Gather .
নির্বাচন করুন
See also XlaBuilder::Select .
Constructs an output array from elements of two input arrays, based on the values of a predicate array.
Select(pred, on_true, on_false)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
pred | XlaOp | array of type PRED |
on_true | XlaOp | array of type T |
on_false | XlaOp | array of type T |
The arrays on_true and on_false must have the same shape. This is also the shape of the output array. The array pred must have the same dimensionality as on_true and on_false , with the PRED element type.
For each element P of pred , the corresponding element of the output array is taken from on_true if the value of P is true , and from on_false if the value of P is false . As a restricted form of broadcasting , pred can be a scalar of type PRED . In this case, the output array is taken wholly from on_true if pred is true , and from on_false if pred is false .
Example with non-scalar pred :
let pred: PRED[4] = {true, false, false, true};
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 200, 300, 4};
Example with scalar pred :
let pred: PRED = true;
let v1: s32[4] = {1, 2, 3, 4};
let v2: s32[4] = {100, 200, 300, 400};
==>
Select(pred, v1, v2) = s32[4]{1, 2, 3, 4};
Selections between tuples are supported. Tuples are considered to be scalar types for this purpose. If on_true and on_false are tuples (which must have the same shape!) then pred has to be a scalar of type PRED .
SelectAndScatter
See also XlaBuilder::SelectAndScatter .
This operation can be considered as a composite operation that first computes ReduceWindow on the operand array to select an element from each window, and then scatters the source array to the indices of the selected elements to construct an output array with the same shape as the operand অ্যারে The binary select function is used to select an element from each window by applying it across each window, and it is called with the property that the first parameter's index vector is lexicographically less than the second parameter's index vector. The select function returns true if the first parameter is selected and returns false if the second parameter is selected, and the function must hold transitivity (ie, if select(a, b) and select(b, c) are true , then select(a, c) is also true ) so that the selected element does not depend on the order of the elements traversed for a given window.
The function scatter is applied at each selected index in the output array. It takes two scalar parameters:
- Current value at the selected index in the output array
- The scatter value from
sourcethat applies to the selected index
It combines the two parameters and returns a scalar value that's used to update the value at the selected index in the output array. Initially, all indices of the output array are set to init_value .
The output array has the same shape as the operand array and the source array must have the same shape as the result of applying a ReduceWindow operation on the operand array. SelectAndScatter can be used to backpropagate the gradient values for a pooling layer in a neural network.
SelectAndScatter(operand, select, window_dimensions, window_strides, padding, source, init_value, scatter)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | array of type T over which the windows slide |
select | XlaComputation | binary computation of type T, T -> PRED , to apply to all elements in each window; returns true if the first parameter is selected and returns false if the second parameter is selected |
window_dimensions | ArraySlice<int64> | array of integers for window dimension values |
window_strides | ArraySlice<int64> | array of integers for window stride values |
padding | Padding | padding type for window (Padding::kSame or Padding::kValid) |
source | XlaOp | array of type T with the values to scatter |
init_value | XlaOp | scalar value of type T for the initial value of the output array |
scatter | XlaComputation | binary computation of type T, T -> T , to apply each scatter source element with its destination element |
The figure below shows examples of using SelectAndScatter , with the select function computing the maximal value among its parameters. Note that when the windows overlap, as in the figure (2) below, an index of the operand array may be selected multiple times by different windows. In the figure, the element of value 9 is selected by both of the top windows (blue and red) and the binary addition scatter function produces the output element of value 8 (2 + 6).
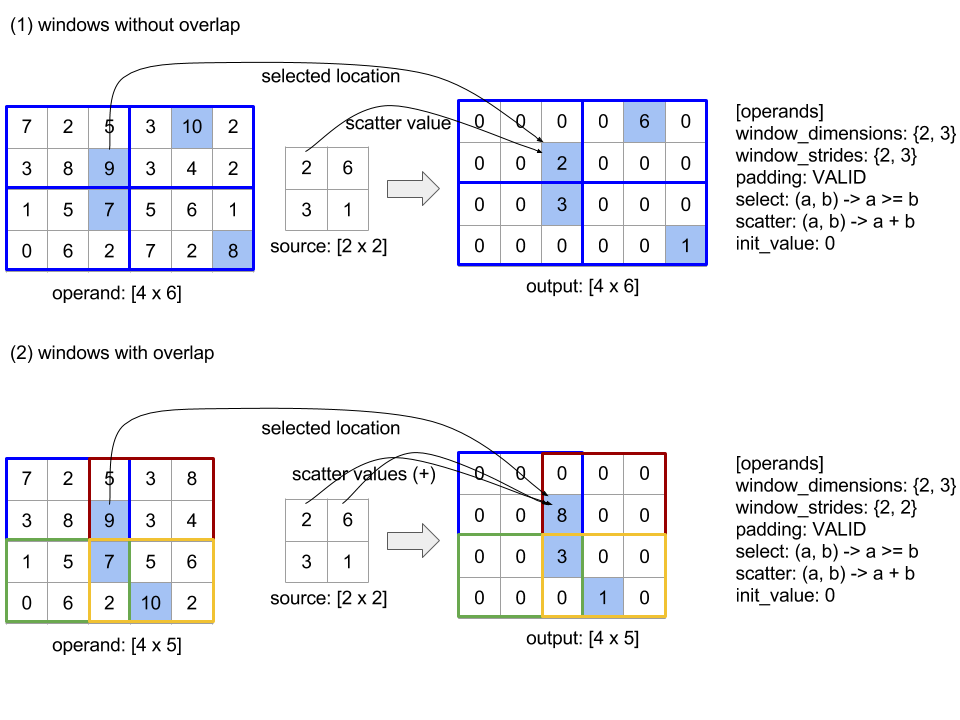
The evaluation order of the scatter function is arbitrary and may be non-deterministic. Therefore, the scatter function should not be overly sensitive to reassociation. See the discussion about associativity in the context of Reduce for more details.
পাঠান
See also XlaBuilder::Send .
Send(operand, channel_handle)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | data to send (array of type T) |
channel_handle | ChannelHandle | unique identifier for each send/recv pair |
Sends the given operand data to a Recv instruction in another computation that shares the same channel handle. Does not return any data.
Similar to the Recv operation, the client API of Send operation represents synchronous communication, and is internally decomposed into 2 HLO instructions ( Send and SendDone ) to enable asynchronous data transfers. See also HloInstruction::CreateSend and HloInstruction::CreateSendDone .
Send(HloInstruction operand, int64 channel_id)
Initiates an asynchronous transfer of the operand to the resources allocated by the Recv instruction with the same channel id. Returns a context, which is used by a following SendDone instruction to wait for the completion of the data transfer. The context is a tuple of {operand (shape), request identifier (U32)} and it can only be used by a SendDone instruction.
SendDone(HloInstruction context)
Given a context created by a Send instruction, waits for the data transfer to complete. The instruction does not return any data.
Scheduling of channel instructions
The execution order of the 4 instructions for each channel ( Recv , RecvDone , Send , SendDone ) is as below.
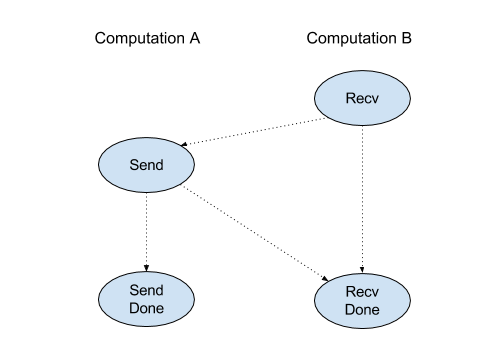
-
Recvhappens beforeSend -
Sendhappens beforeRecvDone -
Recvhappens beforeRecvDone -
Sendhappens beforeSendDone
When the backend compilers generate a linear schedule for each computation that communicates via channel instructions, there must not be cycles across the computations. For example, below schedules lead to deadlocks.
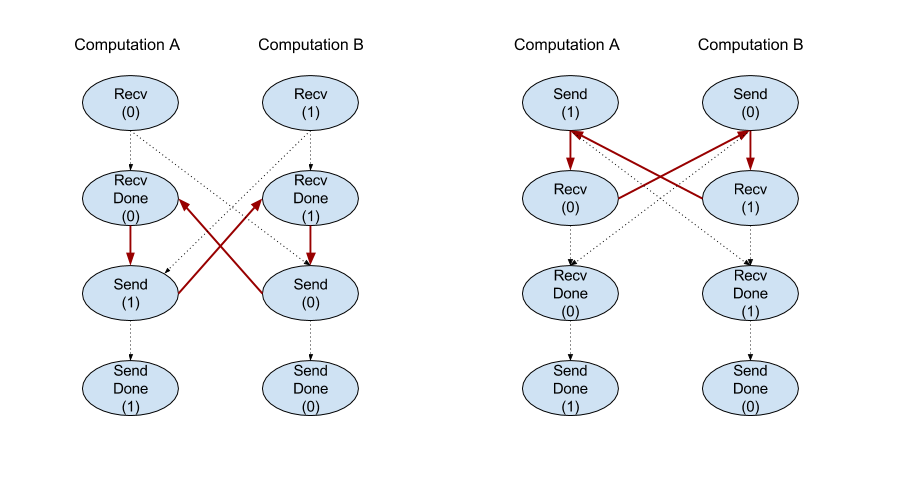
স্লাইস
See also XlaBuilder::Slice .
Slicing extracts a sub-array from the input array. The sub-array is of the same rank as the input and contains the values inside a bounding box within the input array where the dimensions and indices of the bounding box are given as arguments to the slice operation.
Slice(operand, start_indices, limit_indices, strides)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | N dimensional array of type T |
start_indices | ArraySlice<int64> | List of N integers containing the starting indices of the slice for each dimension. Values must be greater than or equal to zero. |
limit_indices | ArraySlice<int64> | List of N integers containing the ending indices (exclusive) for the slice for each dimension. Each value must be greater than or equal to the respective start_indices value for the dimension and less than or equal to the size of the dimension. |
strides | ArraySlice<int64> | List of N integers that decides the input stride of the slice. The slice picks every strides[d] element in dimension d . |
1-dimensional example:
let a = {0.0, 1.0, 2.0, 3.0, 4.0}
Slice(a, {2}, {4}) produces:
{2.0, 3.0}
2-dimensional example:
let b =
{ {0.0, 1.0, 2.0},
{3.0, 4.0, 5.0},
{6.0, 7.0, 8.0},
{9.0, 10.0, 11.0} }
Slice(b, {2, 1}, {4, 3}) produces:
{ { 7.0, 8.0},
{10.0, 11.0} }
সাজান
See also XlaBuilder::Sort .
Sort(operands, comparator, dimension, is_stable)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operands | ArraySlice<XlaOp> | The operands to sort. |
comparator | XlaComputation | The comparator computation to use. |
dimension | int64 | The dimension along which to sort. |
is_stable | bool | Whether stable sorting should be used. |
If only one operand is provided:
If the operand is a rank-1 tensor (an array), the result is a sorted array. If you want to sort the array into ascending order, the comparator should perform a less-than comparison. Formally, after the array is sorted, it holds for all index positions
i, jwithi < jthat eithercomparator(value[i], value[j]) = comparator(value[j], value[i]) = falseorcomparator(value[i], value[j]) = true.If the operand has higher rank, the operand is sorted along the provided dimension. For example, for a rank-2 tensor (a matrix), a dimension value of
0will independently sort every column, and a dimension value of1will independently sort each row. If no dimension number is provided, then the last dimension is chosen by default. For the dimension which is sorted, the same sorting order applies as in the rank-1 case.
If n > 1 operands are provided:
All
noperands must be tensors with the same dimensions. The element types of the tensors may be different.All operands are sorted together, not individually. Conceptually the operands are treated as a tuple. When checking whether the elements of each operand at index positions
iandjneed to be swapped, the comparator is called with2 * nscalar parameters, where parameter2 * kcorresponds to the value at positionifrom thek-thoperand, and parameter2 * k + 1corresponds to the value at positionjfrom thek-thoperand. Usually, the comparator would thus compare parameters2 * kand2 * k + 1with each other and possibly use other parameter pairs as tie breakers.The result is a tuple that consists of the operands in sorted order (along the provided dimension, as above). The
i-thoperand of the tuple corresponds to thei-thoperand of Sort.
For example, if there are three operands operand0 = [3, 1] , operand1 = [42, 50] , operand2 = [-3.0, 1.1] , and the comparator compares only the values of operand0 with less-than, then the output of the sort is the tuple ([1, 3], [50, 42], [1.1, -3.0]) .
If is_stable is set to true, the sort is guaranteed to be stable, that is, if there are elements which are considered to be equal by the comparator, the relative order of the equal values is preserved. Two elements e1 and e2 are equal if and only if comparator(e1, e2) = comparator(e2, e1) = false . By default, is_stable is set to false.
স্থানান্তর
See also the tf.reshape operation.
Transpose(operand)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
operand | XlaOp | The operand to transpose. |
permutation | ArraySlice<int64> | How to permute the dimensions. |
Permutes the operand dimensions with the given permutation, so ∀ i . 0 ≤ i < rank ⇒ input_dimensions[permutation[i]] = output_dimensions[i] .
This is the same as Reshape(operand, permutation, Permute(permutation, operand.shape.dimensions)).
TriangularSolve
See also XlaBuilder::TriangularSolve .
Solves systems of linear equations with lower or upper triangular coefficient matrices by forward- or back-substitution. Broadcasting along leading dimensions, this routine solves one of the matrix systems op(a) * x = b , or x * op(a) = b , for the variable x , given a and b , where op(a) is either op(a) = a , or op(a) = Transpose(a) , or op(a) = Conj(Transpose(a)) .
TriangularSolve(a, b, left_side, lower, unit_diagonal, transpose_a)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
a | XlaOp | a rank > 2 array of a complex or floating-point type with shape [..., M, M] . |
b | XlaOp | a rank > 2 array of the same type with shape [..., M, K] if left_side is true, [..., K, M] otherwise. |
left_side | bool | indicates whether to solve a system of the form op(a) * x = b ( true ) or x * op(a) = b ( false ). |
lower | bool | whether to use the upper or lower triangle of a . |
unit_diagonal | bool | if true , the diagonal elements of a are assumed to be 1 and not accessed. |
transpose_a | Transpose | whether to use a as is, transpose it or take its conjugate transpose. |
Input data is read only from the lower/upper triangle of a , depending on the value of lower . Values from the other triangle are ignored. Output data is returned in the same triangle; the values in the other triangle are implementation-defined and may be anything.
If the rank of a and b are greater than 2, they are treated as batches of matrices, where all except the minor 2 dimensions are batch dimensions. a and b must have equal batch dimensions.
টুপল
See also XlaBuilder::Tuple .
A tuple containing a variable number of data handles, each of which has its own shape.
This is analogous to std::tuple in C++. Conceptually:
let v: f32[10] = f32[10]{0, 1, 2, 3, 4, 5, 6, 7, 8, 9};
let s: s32 = 5;
let t: (f32[10], s32) = tuple(v, s);
Tuples can be deconstructed (accessed) via the GetTupleElement operation.
যখন
See also XlaBuilder::While .
While(condition, body, init)
| যুক্তি | টাইপ | শব্দার্থবিদ্যা |
|---|---|---|
condition | XlaComputation | XlaComputation of type T -> PRED which defines the termination condition of theloop. |
body | XlaComputation | XlaComputation of type T -> T which defines the body of the loop. |
init | T | Initial value for the parameter of condition and body . |
Sequentially executes the body until the condition fails. This is similar to a typical while loop in many other languages except for the differences and restrictions listed below.
- A
Whilenode returns a value of typeT, which is the result from the last execution of thebody. - The shape of the type
Tis statically determined and must be the same across all iterations.
The T parameters of the computations are initialized with the init value in the first iteration and are automatically updated to the new result from body in each subsequent iteration.
One main use case of the While node is to implement the repeated execution of training in neural networks. Simplified pseudocode is shown below with a graph that represents the computation. The code can be found in while_test.cc . The type T in this example is a Tuple consisting of an int32 for the iteration count and a vector[10] for the accumulator. For 1000 iterations, the loop keeps adding a constant vector to the accumulator.
// Pseudocode for the computation.
init = {0, zero_vector[10]} // Tuple of int32 and float[10].
result = init;
while (result(0) < 1000) {
iteration = result(0) + 1;
new_vector = result(1) + constant_vector[10];
result = {iteration, new_vector};
}