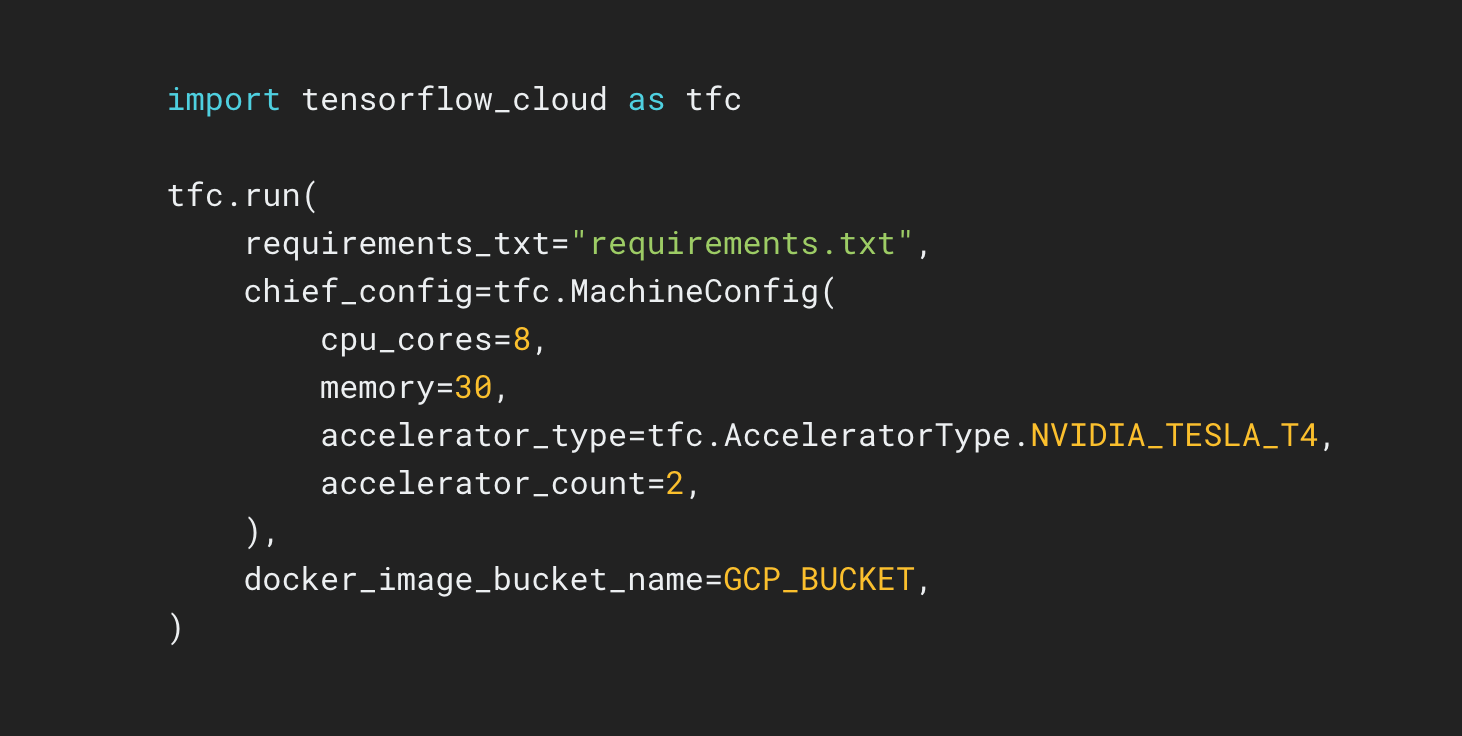
TensorFlow Cloud is a library to connect your local environment to Google Cloud.
import tensorflow_cloud as tfc TF_GPU_IMAGE = "tensorflow/tensorflow:latest-gpu" run_parameters = { distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} } tfc.run(**run_parameters) # Runs your training on Google Cloud!
The TensorFlow Cloud repository provides APIs that ease the transition from local model building and debugging to distributed training and hyperparameter tuning on Google Cloud. From inside a Colab or Kaggle Notebook or a local script file, you can send your model for tuning or training on Cloud directly, without needing to use the Cloud Console.