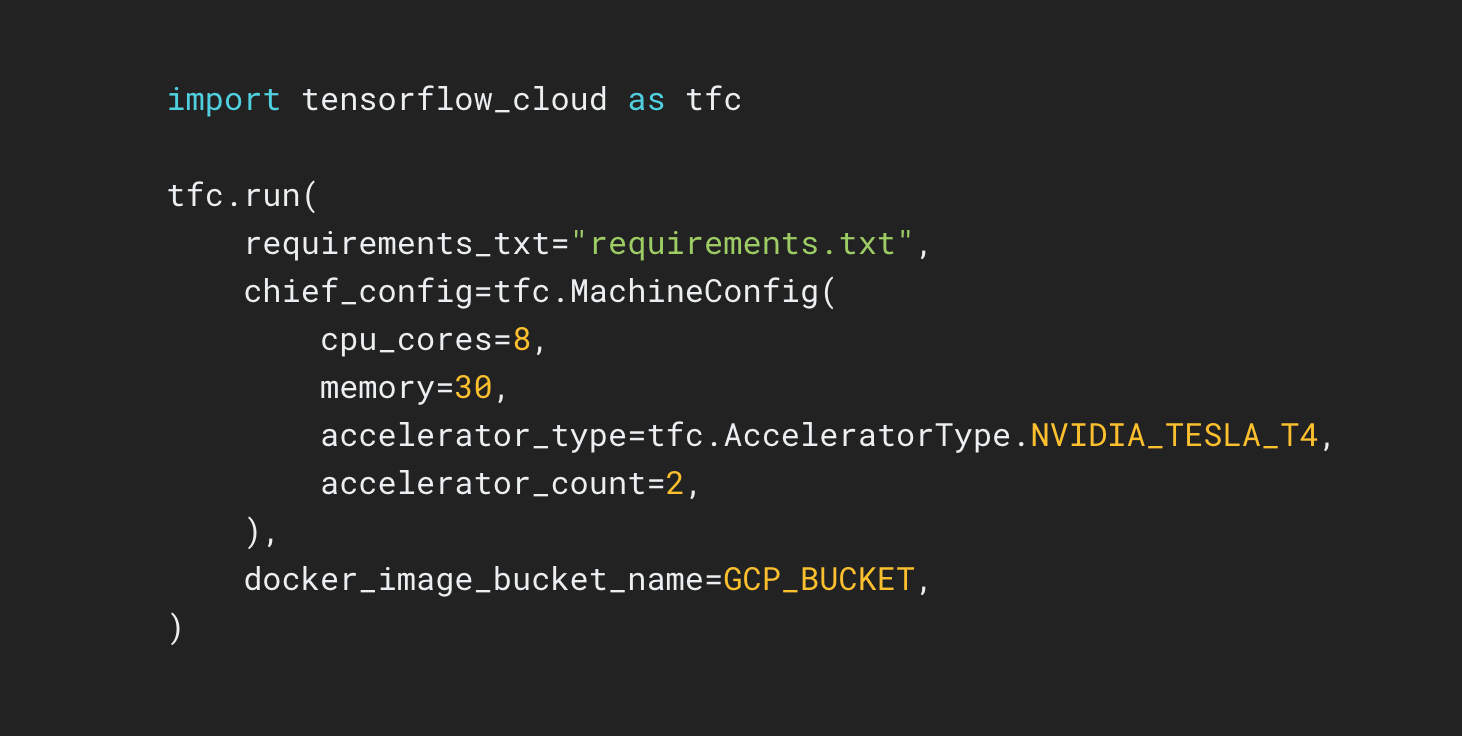
TensorFlow Cloud là một thư viện để kết nối môi trường cục bộ của bạn với Google Cloud.
import tensorflow_cloud as tfc TF_GPU_IMAGE = "tensorflow/tensorflow:latest-gpu" run_parameters = { distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} } tfc.run(**run_parameters) # Runs your training on Google Cloud!
Kho lưu trữ TensorFlow Cloud cung cấp các API giúp dễ dàng chuyển đổi từ xây dựng và gỡ lỗi mô hình cục bộ sang đào tạo phân tán và điều chỉnh siêu tham số trên Google Cloud. Từ bên trong Colab hoặc Kaggle Notebook hay tệp tập lệnh cục bộ, bạn có thể gửi mô hình của mình để điều chỉnh hoặc đào tạo trực tiếp trên Đám mây mà không cần sử dụng Cloud Console.