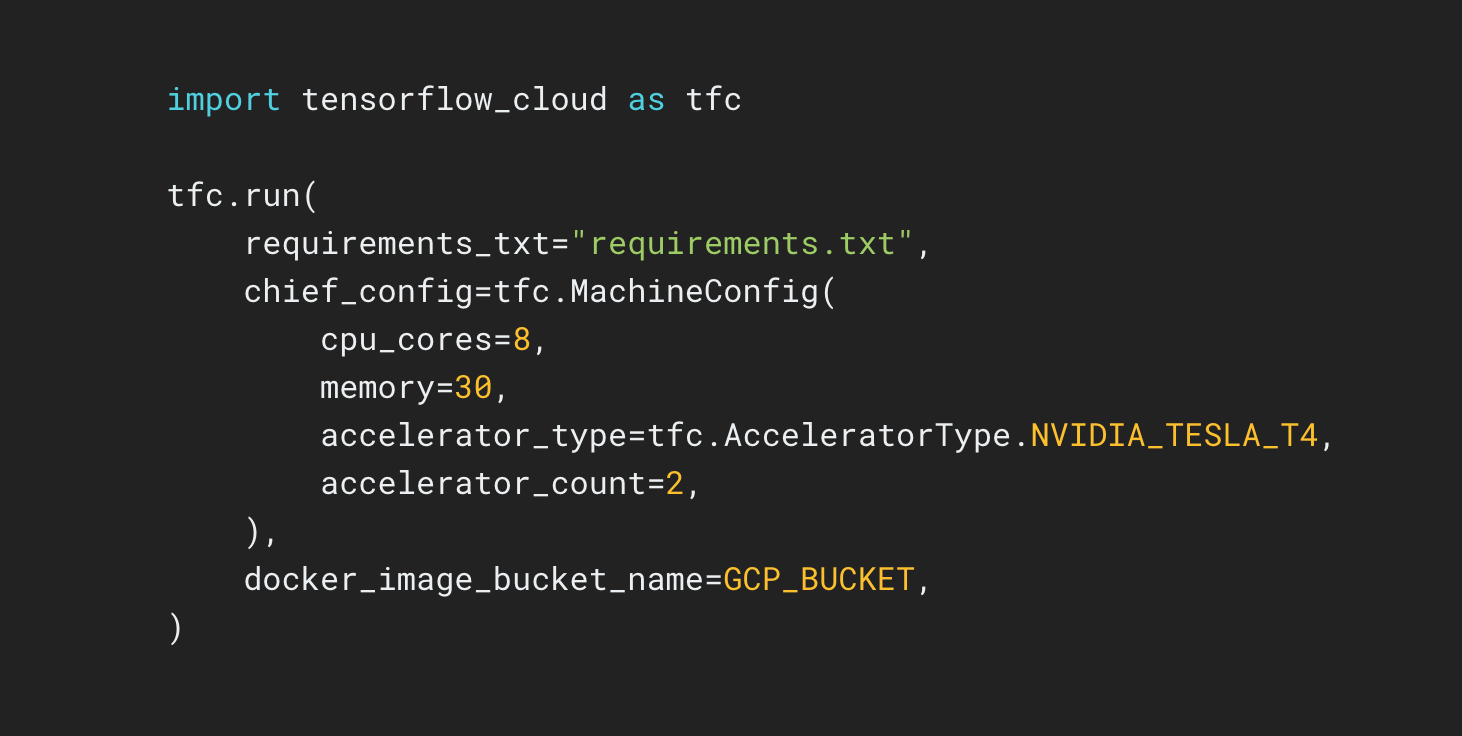
TensorFlow Cloud — это библиотека для подключения вашей локальной среды к Google Cloud.
import tensorflow_cloud as tfc TF_GPU_IMAGE = "tensorflow/tensorflow:latest-gpu" run_parameters = { distribution_strategy='auto', requirements_txt='requirements.txt', docker_config=tfc.DockerConfig( parent_image=TF_GPU_IMAGE, image_build_bucket=GCS_BUCKET ), chief_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_config=tfc.COMMON_MACHINE_CONFIGS['K80_1X'], worker_count=3, job_labels={'job': "my_job"} } tfc.run(**run_parameters) # Runs your training on Google Cloud!
Репозиторий TensorFlow Cloud предоставляет API, которые упрощают переход от построения и отладки локальной модели к распределенному обучению и настройке гиперпараметров в Google Cloud. Из блокнота Colab или Kaggle или из локального файла сценария вы можете отправить свою модель для настройки или обучения непосредственно в облаке без необходимости использования облачной консоли.