
하드웨어 가속을 위해 GPU, NPU 또는 DSP와 같은 특수 프로세서를 사용하면 추론 성능(어떤 경우에는 최대 10배 더 빠른 추론)과 ML 지원 Android 애플리케이션의 사용자 경험을 크게 향상시킬 수 있습니다. 그러나 사용자가 보유하고 있는 다양한 하드웨어와 드라이버를 고려할 때 각 사용자의 장치에 대한 최적의 하드웨어 가속 구성을 선택하는 것이 어려울 수 있습니다. 또한 장치에서 잘못된 구성을 활성화하면 높은 대기 시간으로 인해 사용자 경험이 저하될 수 있으며, 드문 경우지만 하드웨어 비호환성으로 인한 런타임 오류나 정확성 문제가 발생할 수 있습니다.
Android용 가속 서비스는 특정 사용자 장치 및 .tflite 모델에 대한 최적의 하드웨어 가속 구성을 선택하는 동시에 런타임 오류 또는 정확성 문제의 위험을 최소화하는 데 도움이 되는 API입니다.
Acceleration Service는 TensorFlow Lite 모델로 내부 추론 벤치마크를 실행하여 사용자 장치의 다양한 가속 구성을 평가합니다. 이러한 테스트 실행은 모델에 따라 일반적으로 몇 초 안에 완료됩니다. 추론 시간 전에 모든 사용자 장치에서 벤치마크를 한 번 실행하고 결과를 캐시하여 추론 중에 사용할 수 있습니다. 이러한 벤치마크는 프로세스 외부에서 실행됩니다. 이는 앱 충돌 위험을 최소화합니다.
모델, 데이터 샘플 및 예상 결과("골든" 입력 및 출력)를 제공하면 Acceleration Service가 내부 TFLite 추론 벤치마크를 실행하여 하드웨어 권장 사항을 제공합니다.
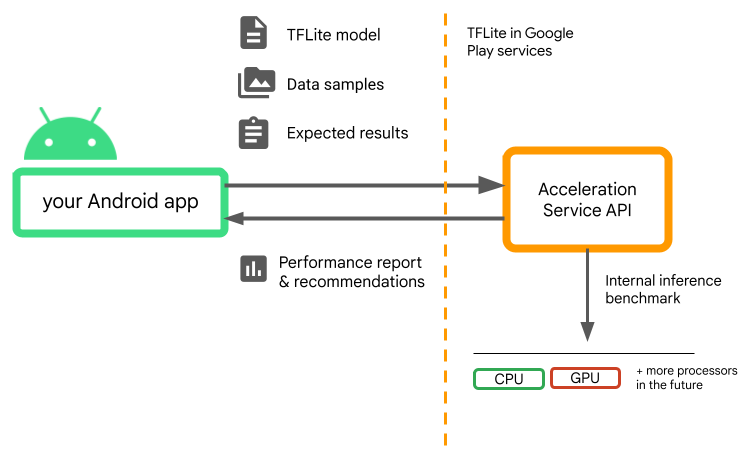
Acceleration Service는 Android의 맞춤 ML 스택의 일부이며 Google Play 서비스의 TensorFlow Lite 와 함께 작동합니다.
프로젝트에 종속성을 추가하세요.
애플리케이션의 build.gradle 파일에 다음 종속성을 추가합니다.
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.0.0-beta01"
Acceleration Service API는 Google Play 서비스의 TensorFlow Lite 와 함께 작동합니다. Play 서비스를 통해 제공되는 TensorFlow Lite 런타임을 아직 사용하지 않는 경우 종속성을 업데이트해야 합니다.
가속 서비스 API를 사용하는 방법
가속 서비스를 사용하려면 먼저 모델에 대해 평가하려는 가속 구성(예: OpenGL이 포함된 GPU)을 생성하세요. 그런 다음 모델, 일부 샘플 데이터 및 예상 모델 출력을 사용하여 유효성 검사 구성을 만듭니다. 마지막으로 가속 구성과 유효성 검사 구성을 모두 전달할 때 validateConfig() 호출하세요.

가속 구성 만들기
가속 구성은 실행 시간 동안 대리자로 변환되는 하드웨어 구성을 나타냅니다. 그런 다음 가속 서비스는 이러한 구성을 내부적으로 사용하여 테스트 추론을 수행합니다.
현재 가속 서비스를 사용하면 GpuAccelerationConfig 및 CPU 추론( CpuAccelerationConfig 사용)을 통해 GPU 구성(실행 시간 동안 GPU 대리자로 변환됨)을 평가할 수 있습니다. 우리는 앞으로 더 많은 대표자가 다른 하드웨어에 액세스할 수 있도록 지원하기 위해 노력하고 있습니다.
GPU 가속 구성
다음과 같이 GPU 가속 구성을 만듭니다.
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
모델이 setEnableQuantizedInference() 를 사용하여 양자화를 사용하는지 여부를 지정해야 합니다.
CPU 가속 구성
다음과 같이 CPU 가속을 생성합니다.
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
setNumThreads() 메서드를 사용하여 CPU 추론을 평가하는 데 사용할 스레드 수를 정의합니다.
검증 구성 생성
검증 구성을 사용하면 가속 서비스가 추론을 평가하는 방법을 정의할 수 있습니다. 이를 사용하여 다음을 통과합니다.
- 입력 샘플,
- 예상 출력,
- 정확성 검증 논리.
모델의 좋은 성능을 기대하는 입력 샘플("골든" 샘플이라고도 함)을 제공해야 합니다.
다음과 같이 CustomValidationConfig.Builder 사용하여 ValidationConfig 만듭니다.
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
setBatchSize() 사용하여 골든 샘플 수를 지정합니다. setGoldenInputs() 사용하여 골든 샘플의 입력을 전달합니다. setGoldenOutputs() 로 전달된 입력에 대해 예상되는 출력을 제공합니다.
setInferenceTimeoutMillis() 사용하여 최대 추론 시간을 정의할 수 있습니다(기본적으로 5000ms). 추론이 정의한 시간보다 오래 걸리면 구성이 거부됩니다.
선택적으로 다음과 같이 사용자 정의 AccuracyValidator 생성할 수도 있습니다.
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
사용 사례에 적합한 유효성 검사 논리를 정의해야 합니다.
유효성 검사 데이터가 이미 모델에 포함되어 있는 경우 EmbeddedValidationConfig 사용할 수 있습니다.
검증 출력 생성
골든 출력은 선택 사항이며, 골든 입력을 제공하는 한 가속 서비스는 내부적으로 골든 출력을 생성할 수 있습니다. setGoldenConfig() 를 호출하여 이러한 골든 출력을 생성하는 데 사용되는 가속 구성을 정의할 수도 있습니다.
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
가속 구성 검증
가속 구성과 검증 구성을 생성한 후에는 모델에 대해 이를 평가할 수 있습니다.
다음을 실행하여 TensorFlow Lite with Play Services 런타임이 제대로 초기화되었는지, GPU 대리자를 기기에서 사용할 수 있는지 확인하세요.
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
AccelerationService.create() 호출하여 AccelerationService 인스턴스화합니다.
그런 다음 validateConfig() 호출하여 모델에 대한 가속 구성의 유효성을 검사할 수 있습니다.
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
또한 validateConfigs() 호출하고 Iterable<AccelerationConfig> 객체를 매개변수로 전달하여 여러 구성의 유효성을 검사할 수도 있습니다.
validateConfig() 비동기 작업을 활성화하는 Google Play 서비스 Task Api 에서 Task< ValidatedAccelerationConfigResult > 반환합니다.
유효성 검사 호출의 결과를 얻으려면 addOnSuccessListener() 콜백을 추가하세요.
인터프리터에서 검증된 구성을 사용하세요.
콜백에 반환된 ValidatedAccelerationConfigResult 유효한지 확인한 후, interpreterOptions.setAccelerationConfig() 를 호출하는 인터프리터의 가속 구성으로 검증된 구성을 설정할 수 있습니다.
구성 캐싱
모델에 대한 최적의 가속 구성은 장치에서 변경될 가능성이 없습니다. 따라서 만족스러운 가속 구성을 받으면 이를 장치에 저장하고 애플리케이션이 이를 검색하여 다른 검증을 실행하는 대신 다음 세션 중에 InterpreterOptions 생성하는 데 사용하도록 해야 합니다. ValidatedAccelerationConfigResult 의 serialize() 및 deserialize() 메서드는 저장 및 검색 프로세스를 더 쉽게 만듭니다.
샘플 애플리케이션
Acceleration Service의 현장 통합을 검토하려면 샘플 앱을 살펴보세요.
제한사항
가속 서비스에는 현재 다음과 같은 제한 사항이 있습니다.
- 현재는 CPU 및 GPU 가속 구성만 지원됩니다.
- Google Play 서비스에서는 TensorFlow Lite만 지원하며, TensorFlow Lite 번들 버전을 사용하는 경우에는 사용할 수 없습니다.
-
ValidatedAccelerationConfigResult객체를 사용하여BaseOptions직접 초기화할 수 없으므로 TensorFlow Lite 작업 라이브러리를 지원하지 않습니다. - Acceleration Service SDK는 API 레벨 22 이상만 지원합니다.
주의사항
특히 프로덕션에서 이 SDK를 사용하려는 경우 다음 주의 사항을 주의 깊게 검토하십시오.
베타를 종료하고 Acceleration Service API의 안정적인 버전을 출시하기 전에 현재 베타 버전과 일부 다를 수 있는 새 SDK를 게시할 예정입니다. Acceleration Service를 계속 사용하려면 이 새로운 SDK로 마이그레이션하고 적시에 앱 업데이트를 푸시해야 합니다. 그렇게 하지 않으면 일정 시간이 지나면 베타 SDK가 더 이상 Google Play 서비스와 호환되지 않을 수 있으므로 문제가 발생할 수 있습니다.
Acceleration Service API 또는 API 전체의 특정 기능이 일반적으로 사용 가능해진다는 보장은 없습니다. 베타 버전으로 무기한 유지되거나, 종료되거나, 특정 개발자 대상을 위해 설계된 패키지로 다른 기능과 결합될 수 있습니다. Acceleration Service API의 일부 기능 또는 전체 API 자체가 결국 일반 공개될 수 있지만 이에 대한 고정된 일정은 없습니다.
이용약관 및 개인정보 보호
서비스 약관
Acceleration Service API 사용에는 Google API 서비스 약관이 적용됩니다.
또한 Acceleration Service API는 현재 베타 버전이므로 이를 사용함으로써 귀하는 위의 주의 사항 섹션에 설명된 잠재적인 문제를 인정하고 Acceleration Service가 항상 지정된 대로 수행되지 않을 수 있음을 인정합니다.
은둔
Acceleration Service API를 사용하면 입력 데이터(예: 이미지, 동영상, 텍스트) 처리가 모두 기기 내에서 이루어지며 Acceleration Service는 해당 데이터를 Google 서버로 보내지 않습니다 . 결과적으로, 장치 외부로 나가면 안 되는 입력 데이터를 처리하기 위해 당사의 API를 사용할 수 있습니다.
Acceleration Service API는 버그 수정, 업데이트된 모델, 하드웨어 가속기 호환성 정보 등을 수신하기 위해 수시로 Google 서버에 접속할 수 있습니다. Acceleration Service API는 또한 앱의 API 성능 및 활용도에 대한 측정항목을 Google에 보냅니다. Google은 개인정보취급방침 에 자세히 설명된 대로 이 측정항목 데이터를 사용하여 성능을 측정하고, API를 디버깅하고, 유지관리 및 개선하고, 오용이나 남용을 감지합니다.
귀하는 관련 법률에서 요구하는 대로 Google의 Acceleration Service 측정항목 데이터 처리에 대해 앱 사용자에게 알릴 책임이 있습니다.
당사가 수집하는 데이터에는 다음이 포함됩니다.
- 장치 정보(제조업체, 모델, OS 버전, 빌드 등) 및 사용 가능한 ML 하드웨어 가속기(GPU 및 DSP). 진단 및 사용량 분석에 사용됩니다.
- 앱 정보(패키지 이름/번들 ID, 앱 버전) 진단 및 사용량 분석에 사용됩니다.
- API 구성(예: 이미지 형식 및 해상도) 진단 및 사용량 분석에 사용됩니다.
- 이벤트 유형(예: 초기화, 모델 다운로드, 업데이트, 실행, 감지) 진단 및 사용량 분석에 사용됩니다.
- 오류 코드. 진단에 사용됩니다.
- 성능 지표. 진단에 사용됩니다.
- 사용자나 물리적 장치를 고유하게 식별하지 않는 설치별 식별자입니다. 원격 구성 작업 및 사용량 분석에 사용됩니다.
- 네트워크 요청 발신자 IP 주소입니다. 원격 구성 진단에 사용됩니다. 수집된 IP 주소는 일시적으로 보관됩니다.
지원 및 피드백
TensorFlow Issue Tracker를 통해 피드백을 제공하고 지원을 받을 수 있습니다. Google Play 서비스의 TensorFlow Lite용 문제 템플릿을 사용하여 문제를 보고하고 지원 요청하세요.