
يمكن أن يؤدي استخدام وحدات معالجة الرسومات (GPUs) لتشغيل نماذج التعلم الآلي (ML) إلى تحسين أداء النموذج الخاص بك بشكل كبير وتجربة المستخدم للتطبيقات التي تدعم التعلم الآلي (ML). على أجهزة iOS، يمكنك تمكين استخدام التنفيذ المسرع بواسطة GPU لنماذجك باستخدام المفوض . يعمل المندوبون بمثابة برامج تشغيل الأجهزة لـ TensorFlow Lite، مما يسمح لك بتشغيل التعليمات البرمجية الخاصة بنموذجك على معالجات GPU.
توضح هذه الصفحة كيفية تمكين تسريع GPU لنماذج TensorFlow Lite في تطبيقات iOS. لمزيد من المعلومات حول استخدام مندوب GPU لـ TensorFlow Lite، بما في ذلك أفضل الممارسات والتقنيات المتقدمة، راجع صفحة مندوبي GPU .
استخدم GPU مع Interpreter API
توفر TensorFlow Lite Interpreter API مجموعة من واجهات برمجة التطبيقات للأغراض العامة لبناء تطبيقات التعلم الآلي. ترشدك الإرشادات التالية خلال إضافة دعم GPU إلى تطبيق iOS. يفترض هذا الدليل أن لديك بالفعل تطبيق iOS يمكنه تنفيذ نموذج ML بنجاح باستخدام TensorFlow Lite.
قم بتعديل ملف Podfile ليشمل دعم GPU
بدءًا من الإصدار TensorFlow Lite 2.3.0، تم استبعاد مندوب GPU من الكبسولة لتقليل الحجم الثنائي. يمكنك تضمينها عن طريق تحديد مواصفات فرعية لحجرة TensorFlowLiteSwift :
pod 'TensorFlowLiteSwift/Metal', '~> 0.0.1-nightly',
أو
pod 'TensorFlowLiteSwift', '~> 0.0.1-nightly', :subspecs => ['Metal']
يمكنك أيضًا استخدام TensorFlowLiteObjC أو TensorFlowLiteC إذا كنت تريد استخدام Objective-C، المتوفر للإصدارات 2.4.0 والإصدارات الأحدث، أو واجهة برمجة تطبيقات C.
تهيئة واستخدام مندوب GPU
يمكنك استخدام مندوب GPU مع TensorFlow Lite Interpreter API مع عدد من لغات البرمجة. يوصى باستخدام Swift وObjective-C، ولكن يمكنك أيضًا استخدام C++ وC. يلزم استخدام لغة C إذا كنت تستخدم إصدارًا من TensorFlow Lite أقدم من 2.4. توضح أمثلة التعليمات البرمجية التالية كيفية استخدام المفوض مع كل لغة من هذه اللغات.
سويفت
import TensorFlowLite
// Load model ...
// Initialize TensorFlow Lite interpreter with the GPU delegate.
let delegate = MetalDelegate()
if let interpreter = try Interpreter(modelPath: modelPath,
delegates: [delegate]) {
// Run inference ...
}
ج موضوعية
// Import module when using CocoaPods with module support
@import TFLTensorFlowLite;
// Or import following headers manually
#import "tensorflow/lite/objc/apis/TFLMetalDelegate.h"
#import "tensorflow/lite/objc/apis/TFLTensorFlowLite.h"
// Initialize GPU delegate
TFLMetalDelegate* metalDelegate = [[TFLMetalDelegate alloc] init];
// Initialize interpreter with model path and GPU delegate
TFLInterpreterOptions* options = [[TFLInterpreterOptions alloc] init];
NSError* error = nil;
TFLInterpreter* interpreter = [[TFLInterpreter alloc]
initWithModelPath:modelPath
options:options
delegates:@[ metalDelegate ]
error:&error];
if (error != nil) { /* Error handling... */ }
if (![interpreter allocateTensorsWithError:&error]) { /* Error handling... */ }
if (error != nil) { /* Error handling... */ }
// Run inference ...
سي ++
// Set up interpreter.
auto model = FlatBufferModel::BuildFromFile(model_path);
if (!model) return false;
tflite::ops::builtin::BuiltinOpResolver op_resolver;
std::unique_ptr<Interpreter> interpreter;
InterpreterBuilder(*model, op_resolver)(&interpreter);
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(/*default options=*/nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
// Run inference.
WriteToInputTensor(interpreter->typed_input_tensor<float>(0));
if (interpreter->Invoke() != kTfLiteOk) return false;
ReadFromOutputTensor(interpreter->typed_output_tensor<float>(0));
// Clean up.
TFLGpuDelegateDelete(delegate);
ج (قبل 2.4.0)
#include "tensorflow/lite/c/c_api.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
// Initialize model
TfLiteModel* model = TfLiteModelCreateFromFile(model_path);
// Initialize interpreter with GPU delegate
TfLiteInterpreterOptions* options = TfLiteInterpreterOptionsCreate();
TfLiteDelegate* delegate = TFLGPUDelegateCreate(nil); // default config
TfLiteInterpreterOptionsAddDelegate(options, metal_delegate);
TfLiteInterpreter* interpreter = TfLiteInterpreterCreate(model, options);
TfLiteInterpreterOptionsDelete(options);
TfLiteInterpreterAllocateTensors(interpreter);
NSMutableData *input_data = [NSMutableData dataWithLength:input_size * sizeof(float)];
NSMutableData *output_data = [NSMutableData dataWithLength:output_size * sizeof(float)];
TfLiteTensor* input = TfLiteInterpreterGetInputTensor(interpreter, 0);
const TfLiteTensor* output = TfLiteInterpreterGetOutputTensor(interpreter, 0);
// Run inference
TfLiteTensorCopyFromBuffer(input, inputData.bytes, inputData.length);
TfLiteInterpreterInvoke(interpreter);
TfLiteTensorCopyToBuffer(output, outputData.mutableBytes, outputData.length);
// Clean up
TfLiteInterpreterDelete(interpreter);
TFLGpuDelegateDelete(metal_delegate);
TfLiteModelDelete(model);
ملاحظات استخدام لغة GPU API
- يمكن لإصدارات TensorFlow Lite الأقدم من 2.4.0 استخدام واجهة برمجة تطبيقات C لـ Objective-C فقط.
- تتوفر واجهة برمجة تطبيقات C++ فقط عند استخدام bazel أو إنشاء TensorFlow Lite بنفسك. لا يمكن استخدام واجهة برمجة تطبيقات C++ مع CocoaPods.
- عند استخدام TensorFlow Lite مع مندوب GPU مع C++، احصل على مندوب GPU عبر وظيفة
TFLGpuDelegateCreate()ثم قم بتمريره إلىInterpreter::ModifyGraphWithDelegate()، بدلاً من استدعاءInterpreter::AllocateTensors().
بناء واختبار مع وضع الإصدار
قم بالتغيير إلى إصدار الإصدار باستخدام إعدادات تسريع Metal API المناسبة للحصول على أداء أفضل والاختبار النهائي. يشرح هذا القسم كيفية تمكين إنشاء الإصدار وتكوين الإعداد لتسريع Metal.
للتغيير إلى إصدار الإصدار:
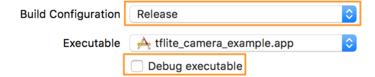
- قم بتحرير إعدادات البناء عن طريق تحديد المنتج > المخطط > تحرير المخطط... ثم تحديد تشغيل .
- في علامة التبويب "معلومات "، قم بتغيير "تكوين التكوين" إلى "إصدار " وقم بإلغاء تحديد "تصحيح الأخطاء القابل للتنفيذ" .
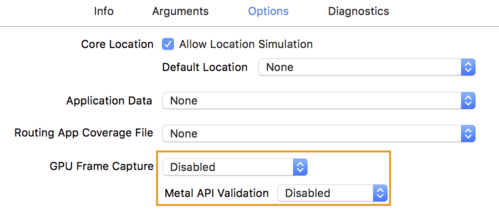
- انقر فوق علامة التبويب Options وقم بتغيير GPU Frame Capture إلى Disabled و Metal API Validation إلى Disabled .
- تأكد من تحديد إصدارات الإصدار فقط المستندة إلى بنية 64 بت. ضمن متصفح المشروع > tflite_camera_example > PROJECT > your_project_name > إعدادات البناء، قم بتعيين إنشاء بنية نشطة فقط > تحرير إلى نعم .

دعم GPU المتقدم
يغطي هذا القسم الاستخدامات المتقدمة لمفوض GPU لنظام iOS، بما في ذلك خيارات المفوض، والمخازن المؤقتة للإدخال والإخراج، واستخدام النماذج الكمية.
خيارات التفويض لنظام iOS
يقبل مُنشئ مندوب GPU struct من الخيارات في Swift API و Objective-C API و C API . يؤدي تمرير nullptr (C API) أو لا شيء (Objective-C وSwift API) إلى المُهيئ إلى تعيين الخيارات الافتراضية (الموضحة في مثال الاستخدام الأساسي أعلاه).
سويفت
// THIS:
var options = MetalDelegate.Options()
options.isPrecisionLossAllowed = false
options.waitType = .passive
options.isQuantizationEnabled = true
let delegate = MetalDelegate(options: options)
// IS THE SAME AS THIS:
let delegate = MetalDelegate()
ج موضوعية
// THIS:
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.precisionLossAllowed = false;
options.waitType = TFLMetalDelegateThreadWaitTypePassive;
options.quantizationEnabled = true;
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] initWithOptions:options];
// IS THE SAME AS THIS:
TFLMetalDelegate* delegate = [[TFLMetalDelegate alloc] init];
ج
// THIS:
const TFLGpuDelegateOptions options = {
.allow_precision_loss = false,
.wait_type = TFLGpuDelegateWaitType::TFLGpuDelegateWaitTypePassive,
.enable_quantization = true,
};
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
// IS THE SAME AS THIS:
TfLiteDelegate* delegate = TFLGpuDelegateCreate(nullptr);
مخازن الإدخال/الإخراج المؤقتة باستخدام C++ API
يتطلب الحساب على وحدة معالجة الرسومات أن تكون البيانات متاحة لوحدة معالجة الرسومات. يعني هذا المتطلب غالبًا أنه يجب عليك إجراء نسخة من الذاكرة. يجب عليك تجنب تجاوز بياناتك لحدود ذاكرة وحدة المعالجة المركزية/وحدة معالجة الرسومات إن أمكن، لأن ذلك قد يستغرق قدرًا كبيرًا من الوقت. عادةً ما يكون هذا العبور أمرًا لا مفر منه، ولكن في بعض الحالات الخاصة، يمكن حذف أحدهما أو الآخر.
إذا كان إدخال الشبكة عبارة عن صورة تم تحميلها بالفعل في ذاكرة وحدة معالجة الرسومات (على سبيل المثال، مادة وحدة معالجة الرسومات التي تحتوي على تغذية الكاميرا) فيمكنها البقاء في ذاكرة وحدة معالجة الرسومات دون الدخول إلى ذاكرة وحدة المعالجة المركزية على الإطلاق. وبالمثل، إذا كان مخرج الشبكة في شكل صورة قابلة للعرض، مثل عملية نقل نمط الصورة ، فيمكنك عرض النتيجة مباشرة على الشاشة.
لتحقيق أفضل أداء، يتيح TensorFlow Lite للمستخدمين القراءة مباشرة من المخزن المؤقت لجهاز TensorFlow والكتابة إليه وتجاوز نسخ الذاكرة التي يمكن تجنبها.
بافتراض أن الصورة المدخلة موجودة في ذاكرة وحدة معالجة الرسومات، يجب عليك أولاً تحويلها إلى كائن MTLBuffer لـ Metal. يمكنك ربط TfLiteTensor بـ MTLBuffer المُعد بواسطة المستخدم مع وظيفة TFLGpuDelegateBindMetalBufferToTensor() . لاحظ أنه يجب استدعاء هذه الوظيفة بعد Interpreter::ModifyGraphWithDelegate() . بالإضافة إلى ذلك، يتم بشكل افتراضي نسخ مخرجات الاستدلال من ذاكرة وحدة معالجة الرسومات إلى ذاكرة وحدة المعالجة المركزية. يمكنك إيقاف تشغيل هذا السلوك عن طريق استدعاء Interpreter::SetAllowBufferHandleOutput(true) أثناء التهيئة.
سي ++
#include "tensorflow/lite/delegates/gpu/metal_delegate.h"
#include "tensorflow/lite/delegates/gpu/metal_delegate_internal.h"
// ...
// Prepare GPU delegate.
auto* delegate = TFLGpuDelegateCreate(nullptr);
if (interpreter->ModifyGraphWithDelegate(delegate) != kTfLiteOk) return false;
interpreter->SetAllowBufferHandleOutput(true); // disable default gpu->cpu copy
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->inputs()[0], user_provided_input_buffer)) {
return false;
}
if (!TFLGpuDelegateBindMetalBufferToTensor(
delegate, interpreter->outputs()[0], user_provided_output_buffer)) {
return false;
}
// Run inference.
if (interpreter->Invoke() != kTfLiteOk) return false;
بمجرد إيقاف تشغيل السلوك الافتراضي، يتطلب نسخ مخرجات الاستدلال من ذاكرة وحدة معالجة الرسومات إلى ذاكرة وحدة المعالجة المركزية استدعاء صريح لـ Interpreter::EnsureTensorDataIsReadable() لكل موتر إخراج. يعمل هذا الأسلوب أيضًا مع النماذج الكمية، لكنك لا تزال بحاجة إلى استخدام مخزن مؤقت بحجم float32 مع بيانات float32 ، لأن المخزن المؤقت مرتبط بالمخزن المؤقت الداخلي غير المكمّم.
النماذج الكمية
تدعم مكتبات تفويض GPU لنظام التشغيل iOS النماذج الكمية بشكل افتراضي . لا تحتاج إلى إجراء أي تغييرات في التعليمات البرمجية لاستخدام النماذج الكمية مع مندوب GPU. يشرح القسم التالي كيفية تعطيل الدعم الكمي لأغراض الاختبار أو الاختبار.
تعطيل دعم النموذج الكمي
يوضح التعليمة البرمجية التالية كيفية تعطيل دعم النماذج الكمية.
سويفت
var options = MetalDelegate.Options()
options.isQuantizationEnabled = false
let delegate = MetalDelegate(options: options)
ج موضوعية
TFLMetalDelegateOptions* options = [[TFLMetalDelegateOptions alloc] init];
options.quantizationEnabled = false;
ج
TFLGpuDelegateOptions options = TFLGpuDelegateOptionsDefault();
options.enable_quantization = false;
TfLiteDelegate* delegate = TFLGpuDelegateCreate(options);
لمزيد من المعلومات حول تشغيل النماذج الكمية مع تسريع GPU، راجع نظرة عامة على مندوب GPU .