
TensorFlow Lite のメタデータによって、モデル記述を標準化することができます。メタデータは、モデルが何を行うのか、その入力と出力は何であるかということを知るための重要な情報源です。メタデータには、次の両方の項目が含まれます。
- モデルを使用する際のベストプラクティスを説明した、人間が読み取れる部分
- TensorFlow Lite Android コードジェネレータや Android Studio ML バインド機能などのコードジェネレータによって利用されるマシンが読み取れる部分
TensorFlow Lite Hub/a0} で公開されたすべての画像モデルには、メタデータが入力されています。
メタデータ形式付きのモデル
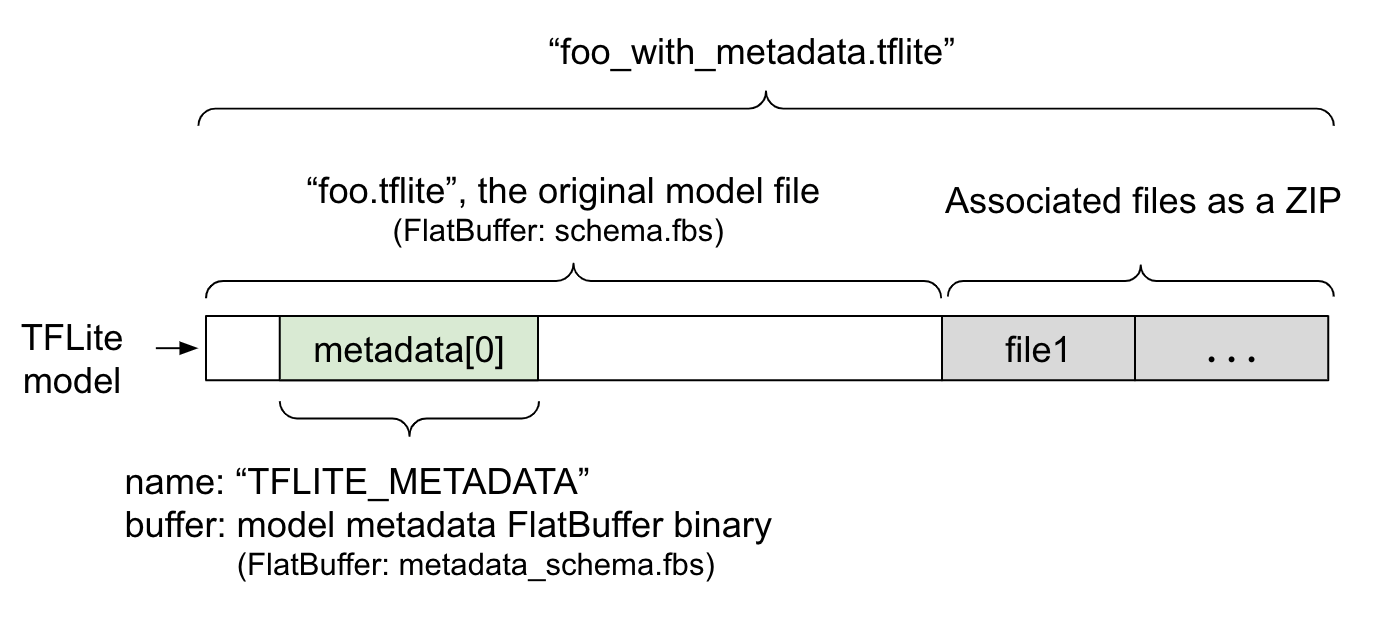
モデルのメタデータは、metadata_schema.fbs という FlatBuffer ファイルに定義されています。図 1 に示されるとおり、このファイルは metadata フィールド(TFLite model schema 内)に、"TFLITE_METADATA" という名前で保存されています。一部のモデルには、分類ラベルファイルなどの関連ファイルがあります。これらのファイルは、ZipFile の "append" モード('a' モード)を使って、元のモデルファイルの最後に ZIP として結合されています。TFLite インタプリタは、以前と同じ方法で新しいファイル形式を消費できます。詳細については、関連ファイルのパッキングをご覧ください。
メタデータの入力方法、可視化方法、および読み取り方法について、以下の説明をご覧ください。
メタデータツールをセットアップする
モデルにメタデータを追加する前に、TensorFlow を実行するための Python プログラミング環境がセットアップされている必要があります。セットアップに関する詳細なガイドは、こちらをご覧ください。
Python プログラミング環境をセットアップしたら、ツールを追加インストールする必要があります。
pip install tflite-support
TensorFlow Lite メタデータツールでは、Python 3 がサポートされています。
Flatbuffers Python API を使ってメタデータを追加する
注意: TensorFlow Lite Task ライブラリでサポートされている一般的な ML タスク用のメタデータを作成するには、TensorFlow Lite Metadata Writer ライブラリで高位 API を使用してください。
モデルのメタデータには、スキーマ として 3 つの部分があります。
- モデルの情報 - モデルの全体的な説明とライセンス条件などの項目。ModelMetadata をご覧ください。
- 入力情報 - 入力と、正規化などの必要な前処理の説明。SubGraphMetadata.input_tensor_metadata をご覧ください。
- 出力情報 - 出力と、ラベルへのマッピングといった必要な後処理の説明。SubGraphMetadata.output_tensor_metadata をご覧ください。
TensorFlow Lite は、現在のところ単一のサブグラフのみをサポートしているため、TensorFlow Lite コードジェネレータと Android Studio ML バインド機能では、メタデータの表示とコードの生成において、SubGraphMetadata.name と SubGraphMetadata.description の代わりに ModelMetadata.name と ModelMetadata.description が使用されます。
サポートされている入力 / 出力の種類
入力と出力に関する TensorFlow Lite メタデータは、特定のモデルの種類を念頭にしたのではなく、入力と出力の型向けに設計されています。モデルの機能が何であるのかは関係なく、入力と出力に次の種類またはそれらを組み合わせたものが含まれている限り、TensorFlow Lite メタデータによってサポートされます。
- 特徴量 - シグネチャのない整数または float32 の数値。
- 画像 - メタデータは現在 RGB とグレースケール画像をサポートしています。
- バウンディングボックス - 矩形の形状のバウンディングボックス。スキーマは さまざまな採番スキーマをサポートします。
関連ファイルをパッキングする
TensorFlow Lite モデルにはさまざまな関連ファイルが含まれる場合があります。たとえば、自然言語モデルには通常、単語ピースを単語 IDにマッピングする語彙ファイルがあり、分類モデルには、オブジェクトのカテゴリを示すラベルファイルが含まれます。(存在するにも関わらず)関連ファイルがない場合、モデルはうまく機能しません。
関連ファイルは、メタデータ Python ライブラリを通じてモデルとバンドル化することができます。新しい TensorFlow Lite モデルは、モデルと関連ファイルの両方を含む zip ファイルにすることができるのです。解凍には一般的な zip ツールを使用できます。この新しいモデル形式では同じファイル拡張子 .tflite を使用しているため、既存の TFLite フレームワークとインタプリタとの互換性があります。詳細は、メタデータと関連ファイルをモデルにパッキングするをご覧ください。
関連ファイル情報は、メタデータに記録されます。ファイルタイプとファイルが添付される場所(ModelMetadata、SubGraphMetadata、および TensorMetadata)に応じて、TensorFlow Lite Android コードジェネレータは、対応する前処理/後処理をオブジェクトに自動的に適用します。詳細は、各関連ファイルタイプの <Codegen usage> セクションをご覧ください。
正規化と量子化のパラメータ
正規化は、機械学習における一般的なデータ前処理テクニックです。正規化の目標は、値の範囲で差を歪ませることなく、値を共通スケールに変更することです。
モデル量子化は、重みと、オプションとしてストレージと計算用の活性化の精度表現の縮小を可能にするテクニックです。
前処理と後処理の観点では、正規化と量子化は 2 つの独立したステップです。次に詳細を示します。
| 正規化 | Quantization | |
|---|---|---|
| \ | Float モデル: \ | Float モデル: \ |
| : An example of the : - mean: 127.5 \ : - zeroPoint: 0 \ : | ||
| : parameter values of the : - std: 127.5 \ : - scale: 1.0 \ : | ||
| : input image in : Quant model: \ : Quant model: \ : | ||
| : MobileNet for float and : - mean: 127.5 \ : - zeroPoint: 128.0 \ : | ||
| : quant models, : - std: 127.5 : - scale:0.0078125f \ : | ||
| : respectively. : : : | ||
| \ | \ | 浮動小数点数モデル |
| : \ : \ : not need quantization. \ : | ||
| : \ : Inputs: If input : Quantized model may : | ||
| : \ : data is normalized in : or may not need : | ||
| : When to invoke? : training, the input : quantization in pre/post : | ||
| : : data of inference needs : processing. It depends : | ||
| : : to be normalized : on the datatype of : | ||
| : : accordingly. \ : input/output tensors. \ : | ||
| : : Outputs: output : - float tensors: no : | ||
| : : data will not be : quantization in pre/post : | ||
| : : normalized in general. : processing needed. Quant : | ||
| : : : op and dequant op are : | ||
| : : : baked into the model : | ||
| : : : graph. \ : | ||
| : : : - int8/uint8 tensors: : | ||
| : : : need quantization in : | ||
| : : : pre/post processing. : | ||
| \ | \ | 入力の量子化: |
| : \ : \ : \ : | ||
| : Formula : normalized_input = : q = f / scale + : | ||
| : : (input - mean) / std : zeroPoint \ : | ||
| : : : **Dequantize for : | ||
| : : : outputs**: \ : | ||
| : : : f = (q - zeroPoint) * : | ||
| : : : scale : | ||
| \ | モデル作成者が提出 | 自動的に提出 |
| : Where are the : and stored in model : TFLite converter, and : | ||
| : parameters : metadata, as : stored in tflite model : | ||
: : NormalizationOptions : file. : |
||
| How to get the | 方法 | Through the TFLite |
: parameters? : MetadataExtractor API : Tensor API [1] or : |
||
| : : [2] : through the : | ||
: : : MetadataExtractor API : |
||
| : : : [2] : | ||
| Do float and quant | Yes, float and quant | No, the float model does |
| : models share the same : models have the same : not need quantization. : | ||
| : value? : Normalization : : | ||
| : : parameters : : | ||
| Does TFLite Code | \ | \ |
| : generator or Android : Yes : Yes : | ||
| : Studio ML binding : : : | ||
| : automatically generate : : : | ||
| : it in data processing? : : : |
[1] TensorFlow Lite Java API および TensorFlow Lite C++ API。
[2] メタデータ抽出ライブラリ
unit8 モデルの画像データファイルを処理する場合、正規化と量子化が省略されることがたまにあります。ピクセル値が [0, 255] の範囲にある場合には、省略しても構いませんが、一般的には、該当する場合に正規化と量子化のパラメータに基づいてデータを処理する必要があります。
TensorFlow Lite Task ライブラリは、NormalizationOptions をメタデータにセットアップする場合の正規化を処理できます。量子化および非量子化処理は常にカプセル化されます。
例
注意: 指定されるエクスポートディレクトリは、スクリプトを実行する前に存在する必要があります。プロセスの過程で作成されることはありません。
様々な種類のモデルに対してメタデータをどのように作成するかの例は、以下をご覧ください。
画像分類
スクリプトはここからダウンロードできます。これはメタデータを mobilenet_v1_0.75_160_quantized.tflite に入力します。次のようにスクリプトを実行してください。
python ./metadata_writer_for_image_classifier.py \
--model_file=./model_without_metadata/mobilenet_v1_0.75_160_quantized.tflite \
--label_file=./model_without_metadata/labels.txt \
--export_directory=model_with_metadata
ほかの画像分類モデルのメタデータを入力するには、このようなモデルの仕様をスクリプトに追加します。このガイドの残りの部分では、画像分類の例の主要なセクションに焦点を当て、主な要素を説明します。
画像分類の例の詳細
モデルの情報
メタデータは新しいモデル情報を作成することから始まります。
from tflite_support import flatbuffers
from tflite_support import metadata as _metadata
from tflite_support import metadata_schema_py_generated as _metadata_fb
""" ... """
"""Creates the metadata for an image classifier."""
# Creates model info.
model_meta = _metadata_fb.ModelMetadataT()
model_meta.name = "MobileNetV1 image classifier"
model_meta.description = ("Identify the most prominent object in the "
"image from a set of 1,001 categories such as "
"trees, animals, food, vehicles, person etc.")
model_meta.version = "v1"
model_meta.author = "TensorFlow"
model_meta.license = ("Apache License. Version 2.0 "
"http://www.apache.org/licenses/LICENSE-2.0.")
入力 / 出力の情報
このセクションは、モデルの入力と出力のシグネチャを記述する方法を示します。このメタデータは、前処理と後処理のコードを作成するために、自動コードジェネレータによって使用されることがあります。テンソルに関する入力または出力情報を作成するには、次のようにします。
# Creates input info.
input_meta = _metadata_fb.TensorMetadataT()
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
画像入力
画像は、機械学習の一般的な入力です。TensorFlow Lite メタデータは色空間などの情報や正規化などの前処理情報をサポートしています。画像の次元は、入力テンソルの形状で提供されており、自動的に推論できるため、それを手動で指定する必要はありません。
input_meta.name = "image"
input_meta.description = (
"Input image to be classified. The expected image is {0} x {1}, with "
"three channels (red, blue, and green) per pixel. Each value in the "
"tensor is a single byte between 0 and 255.".format(160, 160))
input_meta.content = _metadata_fb.ContentT()
input_meta.content.contentProperties = _metadata_fb.ImagePropertiesT()
input_meta.content.contentProperties.colorSpace = (
_metadata_fb.ColorSpaceType.RGB)
input_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.ImageProperties)
input_normalization = _metadata_fb.ProcessUnitT()
input_normalization.optionsType = (
_metadata_fb.ProcessUnitOptions.NormalizationOptions)
input_normalization.options = _metadata_fb.NormalizationOptionsT()
input_normalization.options.mean = [127.5]
input_normalization.options.std = [127.5]
input_meta.processUnits = [input_normalization]
input_stats = _metadata_fb.StatsT()
input_stats.max = [255]
input_stats.min = [0]
input_meta.stats = input_stats
ラベルの出力
ラベルは、TENSOR_AXIS_LABELS を使用して、関連ファイルを通じて出力テンソルにマッピングできます。
# Creates output info.
output_meta = _metadata_fb.TensorMetadataT()
output_meta.name = "probability"
output_meta.description = "Probabilities of the 1001 labels respectively."
output_meta.content = _metadata_fb.ContentT()
output_meta.content.content_properties = _metadata_fb.FeaturePropertiesT()
output_meta.content.contentPropertiesType = (
_metadata_fb.ContentProperties.FeatureProperties)
output_stats = _metadata_fb.StatsT()
output_stats.max = [1.0]
output_stats.min = [0.0]
output_meta.stats = output_stats
label_file = _metadata_fb.AssociatedFileT()
label_file.name = os.path.basename("your_path_to_label_file")
label_file.description = "Labels for objects that the model can recognize."
label_file.type = _metadata_fb.AssociatedFileType.TENSOR_AXIS_LABELS
output_meta.associatedFiles = [label_file]
メタデータ Flatbuffers を作成する
次のコードは、モデル情報と入力・出力の情報を組み合わせます。
# Creates subgraph info.
subgraph = _metadata_fb.SubGraphMetadataT()
subgraph.inputTensorMetadata = [input_meta]
subgraph.outputTensorMetadata = [output_meta]
model_meta.subgraphMetadata = [subgraph]
b = flatbuffers.Builder(0)
b.Finish(
model_meta.Pack(b),
_metadata.MetadataPopulator.METADATA_FILE_IDENTIFIER)
metadata_buf = b.Output()
メタデータと関連ファイルをモデルにパッキングする
メタデータ Flatbuffers が作成されると、メタデータとラベルファイルは、populate メソッドを使って TFLite ファイルに書き込まれます。
populator = _metadata.MetadataPopulator.with_model_file(model_file)
populator.load_metadata_buffer(metadata_buf)
populator.load_associated_files(["your_path_to_label_file"])
populator.populate()
関連ファイルは、load_associated_files を使って必要なだけモデルにパックすることができますが、少なくともメタデータに記録されたファイルをパックする必要があります。この例では、ラベルファイルをパックすることが必要です。
メタデータを視覚化する
メタデータの視覚化にはニューロンを使用するか、MetadataDisplayer を使って、TensorFlow Lite モデルを json 形式に読み出すことができます。
displayer = _metadata.MetadataDisplayer.with_model_file(export_model_path)
export_json_file = os.path.join(FLAGS.export_directory,
os.path.splitext(model_basename)[0] + ".json")
json_file = displayer.get_metadata_json()
# Optional: write out the metadata as a json file
with open(export_json_file, "w") as f:
f.write(json_file)
Android Studio も Android Studio ML Binding 機能によって、メタデータの表示をサポートしています。
メタデータのバージョン管理
メタデータスキーマは、スキーマファイルの変更を追跡するセマンティックバージョニング番号と真のバージョン互換性を示す Flatbuffers ファイル ID の両方を使ってバージョン管理されています。
セマンティックバージョン管理番号
メタデータスキーマは、MAJOR.MINOR.PATCH などのセマンティックバージョン管理番号でバージョン管理されています。こちらのルールに従って、スキーマの変更を追跡します。バージョン 1.0.0 の後に追加されたフィールドの履歴をご覧ください。
Flatbuffers ファイル ID
セマンティックバージョニングは、ルールに従っている場合に互換性を保証しますが、真の非互換性を暗示するものではありません。MEJOR 番号が増加しても、下位互換性が必ずしも崩れるわけではないため、Flatbuffers ファイル ID である file_identifiler を使用して、メタデータスキーマの真の互換性を示しています。ファイル ID は 4 文字です。特定のメタデータスキーマに固定されており、ユーザーが変更できるものではありません。何らかの理由でメタデータスキーマの下位互換性を崩す必要がある場合は、たとえば “M001” から “M002” のように、file_identifier が増加します。file_identifiler は通常、metadata_version より少ない頻度で変更されます。
最小限必要なメタデータパーサーバージョン
最小限必要なメタデータパーサーバージョンは、メタデータ Flatbuffers をすべて読み取ることのできる最低バージョンのメタデータパーサー(Flatbuffers が生成するコード)です。バージョンは、実質的に
、すべてのフィールドが入力されているバージョンのうち最も高いバージョンで、ファイル ID が示す最低互換バージョンです。最小限必要なメタデータパーサーバージョンは、メタデータが TFLite モデルに入力されたときに、MetadataPopulator によって自動的に入力されます。最小限必要なメタデータパーサーバージョンの使用方法については、Metadata Extractor をご覧ください。
モデルからメタデータを読み取る
Metadata Extractor ライブラリは、さまざまなプラットフォームのモデルからメタデータと関連するファイルを読み取るための便利なツールです(Java バージョンと C++ バージョンをご覧ください)。Flatbuffers ライブラリを使用して、ほかの言語で独自のメタデータエクストラクタを構築できます。
Java でメタデータを読み取る
Android アプリで Metadata Extractor ライブラリを使用するには、JCenter にホストされている TensorFlow Lite Metadata AAR がお勧めです。MetadataExtractor クラスだけでなく、メタデータスキーマとモデルスキーマの FlatBuffers Java バインディングも含まれています。
これは、build.gradle 依存関係に次のように指定できます。
dependencies {
implementation 'org.tensorflow:tensorflow-lite-metadata:0.1.0'
}
ナイトリーのスナップショットを使用するには、Sonatype スナップショットリポジトリが追加されていることを確認してください。
モデルにポイントする ByteBuffer を使って、MetadataExtractor オブジェクトを初期化できます。
public MetadataExtractor(ByteBuffer buffer);
ByteBuffer は MetadataExtractor が存続する限り、変更してはいけません。モデルメタデータの Flatbuffers ファイル識別子がメタデータのパーサーの識別子と一致しない場合、初期化に失敗する可能性があります。詳細は、メタデータのバージョン管理をご覧ください。
ファイル識別子が一致している場合、メタデータエクストラクタは、Flatbuffers の上位および下位互換性メカニズムにより、これまでのスキーマと今後のスキーマから生成されるメタデータを読み取るようになります。ただし、未来のスキーマを古いメタデータエクストラクタで抽出することはできません。メタデータの必要最低限のパーサーバージョンには、メタデータ Flatbuffers を完全に読み取れるメタデータパーサーの最低バージョンが示されています。次のメソッドを使用すると、必要最低限のパーサーバージョンの条件を満たしていることを確認できます。
public final boolean isMinimumParserVersionSatisfied();
メタデータを使用せずにモデルを渡すことは可能ですが、メタデータから読み取られるメソッドを呼び出すと、ランタイムエラーが発生します。モデルにメタデータがあることを確認するには、次のようにして hasMetadata メソッドを呼び出します。
public boolean hasMetadata();
MetadataExtractor には、入力/出力テンソルのメタデータを取得するために、次のような便利な関数が用意されています。
public int getInputTensorCount();
public TensorMetadata getInputTensorMetadata(int inputIndex);
public QuantizationParams getInputTensorQuantizationParams(int inputIndex);
public int[] getInputTensorShape(int inputIndex);
public int getoutputTensorCount();
public TensorMetadata getoutputTensorMetadata(int inputIndex);
public QuantizationParams getoutputTensorQuantizationParams(int inputIndex);
public int[] getoutputTensorShape(int inputIndex);
TensorFlow Lite モデルスキーマは複数のサブグラフをサポートしていますが、TFLite インタプリタは現在、単一のサブグラフのみをサポートしています。そのため、MetadataExtractor は、メソッドの入力引数としてのサブグラフインデックスを省略します。
モデルから関連ファイルを読み取る
メタデータと関連ファイルのある TensorFlow Lite モデルは、基本的に一般的な zip ツールで解凍して関連ファイルを取得できる zip ファイルです。たとえば次のようにして、mobilenet_v1_0.75_160_quantized を解凍して、モデルのラベルファイルを抽出できます。
$ unzip mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
Archive: mobilenet_v1_0.75_160_quantized_1_metadata_1.tflite
extracting: labels.txt
また、Metadata Extractor ライブラリを使って、関連ファイルを読み取ることもできます。
Java で、ファイル名を MetadataExtractor.getAssociatedFile メソッドに渡します。
public InputStream getAssociatedFile(String fileName);
同様に、C++ では ModelMetadataExtractor::GetAssociatedFile メソッドを使って行えます。
tflite::support::StatusOr<absl::string_view> GetAssociatedFile(
const std::string& filename) const;