
کتابخانه رتبهبندی TensorFlow به شما کمک میکند تا یادگیری مقیاسپذیر را برای رتبهبندی مدلهای یادگیری ماشین با استفاده از روشها و تکنیکهای به خوبی تثبیت شده از تحقیقات اخیر بسازید. یک مدل رتبهبندی فهرستی از موارد مشابه، مانند صفحات وب، تهیه میکند و فهرست بهینهسازی شدهای از آن موارد را تولید میکند، برای مثال مرتبطترین صفحات با کمترین ارتباط. یادگیری رتبهبندی مدلها در جستجو، پاسخگویی به سؤال، سیستمهای توصیهگر و سیستمهای گفتگو کاربرد دارد. شما می توانید از این کتابخانه برای تسریع در ساخت یک مدل رتبه بندی برای برنامه خود با استفاده از Keras API استفاده کنید. کتابخانه رتبهبندی همچنین ابزارهای گردش کار را فراهم میکند تا مقیاسبندی پیادهسازی مدل خود را برای کار مؤثر با مجموعه دادههای بزرگ با استفاده از استراتژیهای پردازش توزیعشده آسانتر کند.
این بررسی اجمالی خلاصهای از توسعه یادگیری برای رتبهبندی مدلها با این کتابخانه را ارائه میکند، برخی از تکنیکهای پیشرفتهای را که توسط کتابخانه پشتیبانی میشوند معرفی میکند، و ابزارهای گردش کار ارائهشده برای پشتیبانی از پردازش توزیعشده برای رتبهبندی برنامهها را مورد بحث قرار میدهد.
توسعه یادگیری برای رتبه بندی مدل ها
ساخت مدل با کتابخانه رتبه بندی TensorFlow این مراحل کلی را دنبال می کند:
- با استفاده از لایههای Keras یک تابع امتیازدهی را مشخص کنید (
tf.keras.layers) - معیارهایی را که می خواهید برای ارزیابی استفاده کنید، تعریف کنید، مانند
tfr.keras.metrics.NDCGMetric - یک تابع ضرر، مانند
tfr.keras.losses.SoftmaxLossرا مشخص کنید - مدل را با
tf.keras.Model.compile()کامپایل کنید و با داده های خود آموزش دهید
آموزش فیلمهای پیشنهادی شما را با اصول ساخت یک مدل یادگیری برای رتبهبندی با این کتابخانه راهنمایی میکند. برای اطلاعات بیشتر در مورد ساخت مدل های رتبه بندی در مقیاس بزرگ، بخش پشتیبانی رتبه بندی توزیع شده را بررسی کنید.
تکنیک های پیشرفته رتبه بندی
کتابخانه رتبهبندی TensorFlow از بکارگیری تکنیکهای رتبهبندی پیشرفته که توسط محققان و مهندسان Google تحقیق و پیادهسازی شدهاند، پشتیبانی میکند. بخشهای زیر مروری بر برخی از این تکنیکها و نحوه شروع استفاده از آنها در برنامه شما ارائه میدهند.
فهرست BERT ترتیب ورودی
کتابخانه رتبهبندی پیادهسازی TFR-BERT را ارائه میدهد، یک معماری امتیازدهی که BERT را با مدلسازی LTR برای بهینهسازی ترتیب ورودیهای فهرست جفت میکند. به عنوان نمونه ای از کاربرد این رویکرد، یک پرس و جو و لیستی از n سند را در نظر بگیرید که می خواهید در پاسخ به این پرس و جو رتبه بندی کنید. مدلهای LTR بهجای یادگیری یک نمایش BERT که بهطور مستقل در بین جفتهای <query, document> امتیاز داده میشود، از دست دادن رتبهبندی برای یادگیری مشترک نمایش BERT استفاده میکنند که کاربرد کل فهرست رتبهبندیشده را با توجه به برچسبهای حقیقت پایه به حداکثر میرساند. شکل زیر این تکنیک را نشان می دهد:
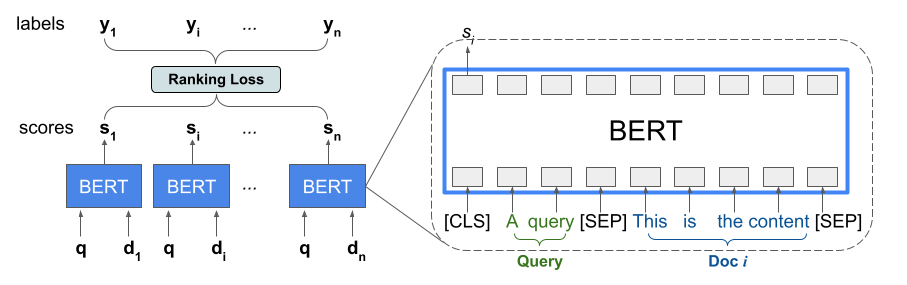
این رویکرد فهرستی از اسناد را برای رتبه بندی در پاسخ به یک پرس و جو به لیستی از تاپل های <query, document> مسطح می کند. سپس این تاپل ها به یک مدل زبانی از پیش آموزش دیده BERT وارد می شوند. سپس خروجی های BERT ادغام شده برای کل لیست اسناد به طور مشترک با یکی از زیان های رتبه بندی تخصصی موجود در رتبه بندی TensorFlow تنظیم می شوند.
این معماری میتواند پیشرفتهای قابلتوجهی در عملکرد مدل زبان از پیش آموزشدیده ارائه دهد، و عملکردی پیشرفته برای چندین کار رتبهبندی محبوب ایجاد کند ، بهویژه زمانی که چندین مدل زبان از پیش آموزشدیده با هم ترکیب شوند. برای اطلاعات بیشتر در مورد این تکنیک، به تحقیق مرتبط مراجعه کنید. می توانید با یک پیاده سازی ساده در کد نمونه رتبه بندی TensorFlow شروع کنید.
مدل های افزایشی تعمیم یافته رتبه بندی عصبی (GAM)
برای برخی از سیستم های رتبه بندی، مانند ارزیابی واجد شرایط بودن وام، هدف گذاری تبلیغات، یا راهنمایی برای درمان پزشکی، شفافیت و توضیح پذیری ملاحظات مهمی هستند. استفاده از مدلهای افزایشی تعمیمیافته (GAM) با فاکتورهای وزنی کاملاً درک شده میتواند به مدل رتبهبندی شما کمک کند تا توضیحپذیرتر و قابل تفسیرتر باشد.
GAM ها به طور گسترده با وظایف رگرسیون و طبقه بندی مورد مطالعه قرار گرفته اند، اما نحوه اعمال آنها در یک برنامه رتبه بندی کمتر مشخص است. به عنوان مثال، در حالی که GAM ها را می توان به سادگی برای مدل سازی هر یک از موارد در لیست به کار برد، مدل سازی هم تعاملات آیتم ها و هم زمینه ای که این آیتم ها در آن رتبه بندی می شوند، مشکل چالش برانگیزی است. رتبهبندی TensorFlow پیادهسازی GAM رتبهبندی عصبی ، توسعهای از مدلهای افزایشی تعمیمیافته طراحیشده برای مشکلات رتبهبندی را ارائه میدهد. اجرای رتبه بندی TensorFlow GAM ها به شما امکان می دهد وزن خاصی را به ویژگی های مدل خود اضافه کنید.
تصویر زیر از سیستم رتبه بندی هتل ها از ارتباط، قیمت و فاصله به عنوان ویژگی های رتبه بندی اولیه استفاده می کند. این مدل از یک تکنیک GAM برای وزن کردن این ابعاد متفاوت، بر اساس زمینه دستگاه کاربر استفاده می کند. به عنوان مثال، اگر درخواست از یک تلفن باشد، با این فرض که کاربران به دنبال هتلی در نزدیکی هستند، مسافت سنگینتر میشود.
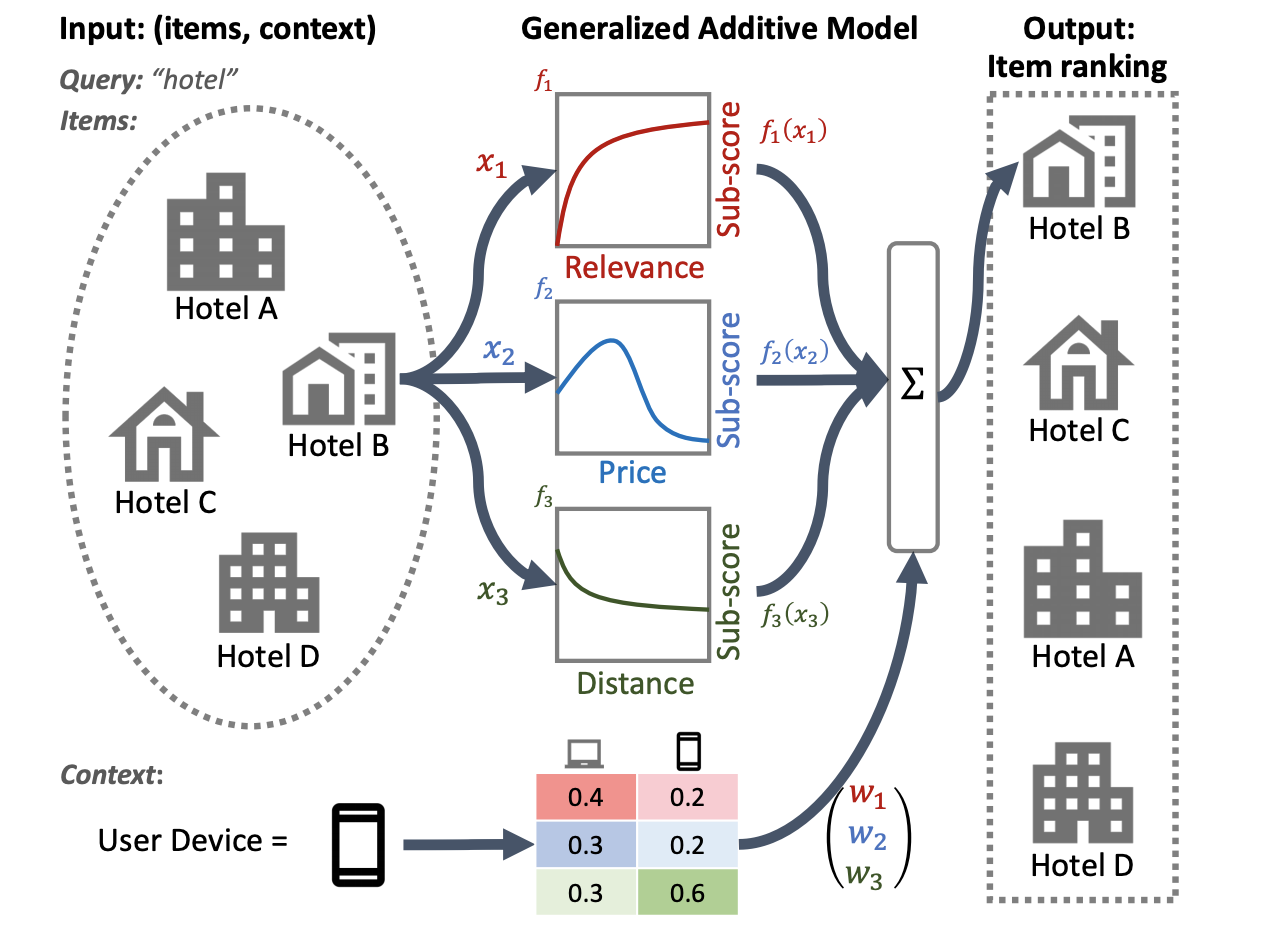
برای اطلاعات بیشتر در مورد استفاده از GAM ها با مدل های رتبه بندی، به تحقیق مربوطه مراجعه کنید. می توانید با نمونه ای از پیاده سازی این تکنیک در کد نمونه رتبه بندی TensorFlow شروع کنید.
پشتیبانی از رتبه بندی توزیع شده
رتبه بندی TensorFlow برای ساختن سیستم های رتبه بندی در مقیاس بزرگ به صورت سرتاسر طراحی شده است: از جمله پردازش داده ها، ساخت مدل، ارزیابی و استقرار تولید. این می تواند ویژگی های متراکم و پراکنده ناهمگن را مدیریت کند، تا میلیون ها نقطه داده را مقیاس کند، و برای پشتیبانی از آموزش توزیع شده برای برنامه های رتبه بندی در مقیاس بزرگ طراحی شده است.
این کتابخانه یک معماری خط لوله رتبه بندی بهینه را ارائه می دهد تا از تکرار کدهای دیگ بخار جلوگیری کند و راه حل های توزیع شده ای ایجاد کند که می تواند از آموزش مدل رتبه بندی شما تا ارائه آن اعمال شود. خط لوله رتبه بندی بیشتر استراتژی های توزیع شده TensorFlow از جمله MirroredStrategy ، TPUStrategy ، MultiWorkerMirroredStrategy و ParameterServerStrategy را پشتیبانی می کند. خط لوله رتبهبندی میتواند مدل رتبهبندی آموزشدیده را در قالب tf.saved_model صادر کند، که از چندین امضای ورودی پشتیبانی میکند . عملیات آموزشی
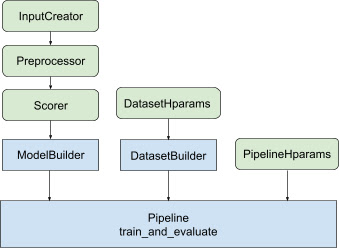
کتابخانه رتبهبندی با ارائه مجموعهای از کلاسهای tfr.keras.pipeline ، که یک سازنده مدل، سازنده داده و فراپارامترها را ورودی میگیرد، به ایجاد یک پیادهسازی آموزشی توزیعشده کمک میکند. کلاس tfr.keras.ModelBuilder مبتنی بر Keras شما را قادر می سازد یک مدل برای پردازش توزیع شده ایجاد کنید و با کلاس های InputCreator، Preprocessor و Scorer قابل توسعه کار می کند:
کلاسهای خط لوله رتبهبندی TensorFlow همچنین با DatasetBuilder برای تنظیم دادههای آموزشی کار میکنند که میتواند فراپارامترها را در خود جای دهد. در نهایت، خود خط لوله میتواند مجموعهای از فراپارامترها را به عنوان یک شی PipelineHparams شامل شود.
با استفاده از آموزش رتبه بندی توزیع شده، با ساخت مدل های رتبه بندی توزیع شده شروع کنید.