
Biblioteka rankingowa TensorFlow pomaga w budowaniu skalowalnego uczenia się w celu rankingu modeli uczenia maszynowego przy użyciu dobrze ugruntowanych podejść i technik z ostatnich badań. Model rankingowy pobiera listę podobnych elementów, takich jak strony internetowe, i generuje zoptymalizowaną listę tych elementów, na przykład najbardziej odpowiednich dla najmniej odpowiednich stron. Nauka oceniania modeli ma zastosowanie w wyszukiwaniu, odpowiadaniu na pytania, systemach rekomendacyjnych i systemach dialogu. Możesz użyć tej biblioteki, aby przyspieszyć budowanie modelu rankingowego dla swojej aplikacji za pomocą interfejsu API Keras . Biblioteka Ranking udostępnia także narzędzia przepływu pracy, które ułatwiają skalowanie implementacji modelu w celu efektywnej pracy z dużymi zbiorami danych przy użyciu strategii przetwarzania rozproszonego.
Ten przegląd zawiera krótkie podsumowanie rozwoju nauki oceniania modeli za pomocą tej biblioteki, wprowadza niektóre zaawansowane techniki obsługiwane przez bibliotekę i omawia narzędzia przepływu pracy dostarczone w celu wspierania przetwarzania rozproszonego dla aplikacji oceniających.
Rozwijanie nauki oceniania modeli
Budowanie modelu za pomocą biblioteki rankingowej TensorFlow przebiega według następujących ogólnych kroków:
- Określ funkcję oceniania przy użyciu warstw Keras (
tf.keras.layers) - Zdefiniuj metryki, których chcesz użyć do oceny, takie jak
tfr.keras.metrics.NDCGMetric - Określ funkcję straty, np.
tfr.keras.losses.SoftmaxLoss - Skompiluj model za pomocą
tf.keras.Model.compile()i wytrenuj go przy użyciu swoich danych
Samouczek Polecanie filmów przeprowadzi Cię przez podstawy tworzenia modelu umożliwiającego naukę rankingu za pomocą tej biblioteki. Sprawdź sekcję Obsługa rankingów rozproszonych, aby uzyskać więcej informacji na temat tworzenia modeli rankingowych na dużą skalę.
Zaawansowane techniki rankingowe
Biblioteka rankingowa TensorFlow zapewnia wsparcie w stosowaniu zaawansowanych technik rankingowych opracowanych i wdrożonych przez badaczy i inżynierów Google. W poniższych sekcjach przedstawiono przegląd niektórych z tych technik oraz sposób rozpoczęcia korzystania z nich w aplikacji.
Porządkowanie danych wejściowych na liście BERT
Biblioteka Ranking zapewnia implementację TFR-BERT, architektury scoringowej, która łączy BERT z modelowaniem LTR w celu optymalizacji kolejności danych wejściowych na liście. Jako przykład zastosowania tego podejścia rozważ zapytanie i listę n dokumentów, które chcesz uszeregować w odpowiedzi na to zapytanie. Zamiast uczyć się reprezentacji BERT ocenianej niezależnie dla par <query, document> , modele LTR stosują stratę rankingową , aby wspólnie nauczyć się reprezentacji BERT, która maksymalizuje użyteczność całej listy rankingowej w odniesieniu do etykiet podstawowych. Poniższy rysunek ilustruje tę technikę:
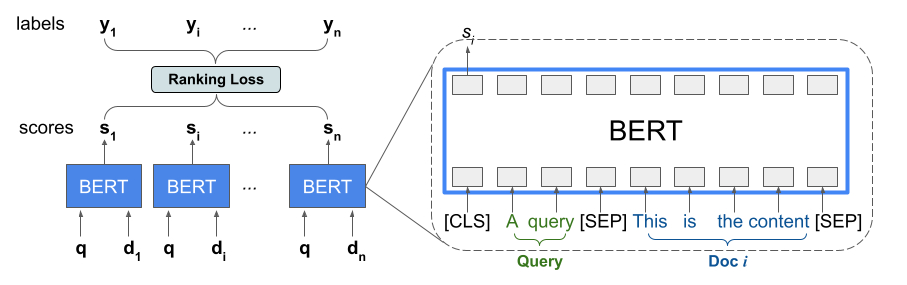
To podejście spłaszcza listę dokumentów, które mają zostać uszeregowane w odpowiedzi na zapytanie, do postaci listy krotek <query, document> . Te krotki są następnie wprowadzane do wstępnie wytrenowanego modelu języka BERT. Połączone wyniki BERT dla całej listy dokumentów są następnie wspólnie dostrajane za pomocą jednej ze specjalistycznych strat rankingowych dostępnych w rankingu TensorFlow.
Architektura ta może zapewnić znaczną poprawę wydajności wstępnie wytrenowanego modelu języka, zapewniając najnowocześniejszą wydajność w przypadku kilku popularnych zadań rankingowych, szczególnie w przypadku połączenia wielu wstępnie wytrenowanych modeli języka. Więcej informacji na temat tej techniki można znaleźć w powiązanych badaniach . Możesz zacząć od prostej implementacji w przykładowym kodzie TensorFlow Ranking.
Uogólnione modele addytywne rankingu neuronowego (GAM)
W przypadku niektórych systemów rankingowych, takich jak ocena kwalifikowalności pożyczki, kierowanie reklam lub wskazówki dotyczące leczenia, przejrzystość i wyjaśnialność mają kluczowe znaczenie. Stosowanie uogólnionych modeli addytywnych (GAM) z dobrze poznanymi współczynnikami wagowymi może sprawić, że model rankingowy stanie się łatwiejszy do wyjaśnienia i interpretacji.
GAM były szeroko badane za pomocą zadań regresji i klasyfikacji, ale mniej jasne jest, jak zastosować je w aplikacji rankingowej. Na przykład, chociaż GAM można po prostu zastosować do modelowania każdego pojedynczego elementu na liście, modelowanie zarówno interakcji elementów, jak i kontekstu, w którym te elementy są uszeregowane, stanowi trudniejszy problem. TensorFlow Ranking zapewnia implementację rankingu neuronowego GAM , rozszerzenia uogólnionych modeli addytywnych przeznaczonych do rozwiązywania problemów rankingowych. Implementacja GAM w rankingu TensorFlow pozwala na dodanie określonej wagi do funkcji modelu.
Na poniższej ilustracji systemu rankingowego hoteli głównymi cechami rankingu są trafność, cena i odległość. W tym modelu zastosowano technikę GAM, aby różnie ważyć te wymiary w zależności od kontekstu urządzenia użytkownika. Na przykład, jeśli zapytanie pochodzi z telefonu, ważona jest większa odległość, zakładając, że użytkownicy szukają pobliskiego hotelu.
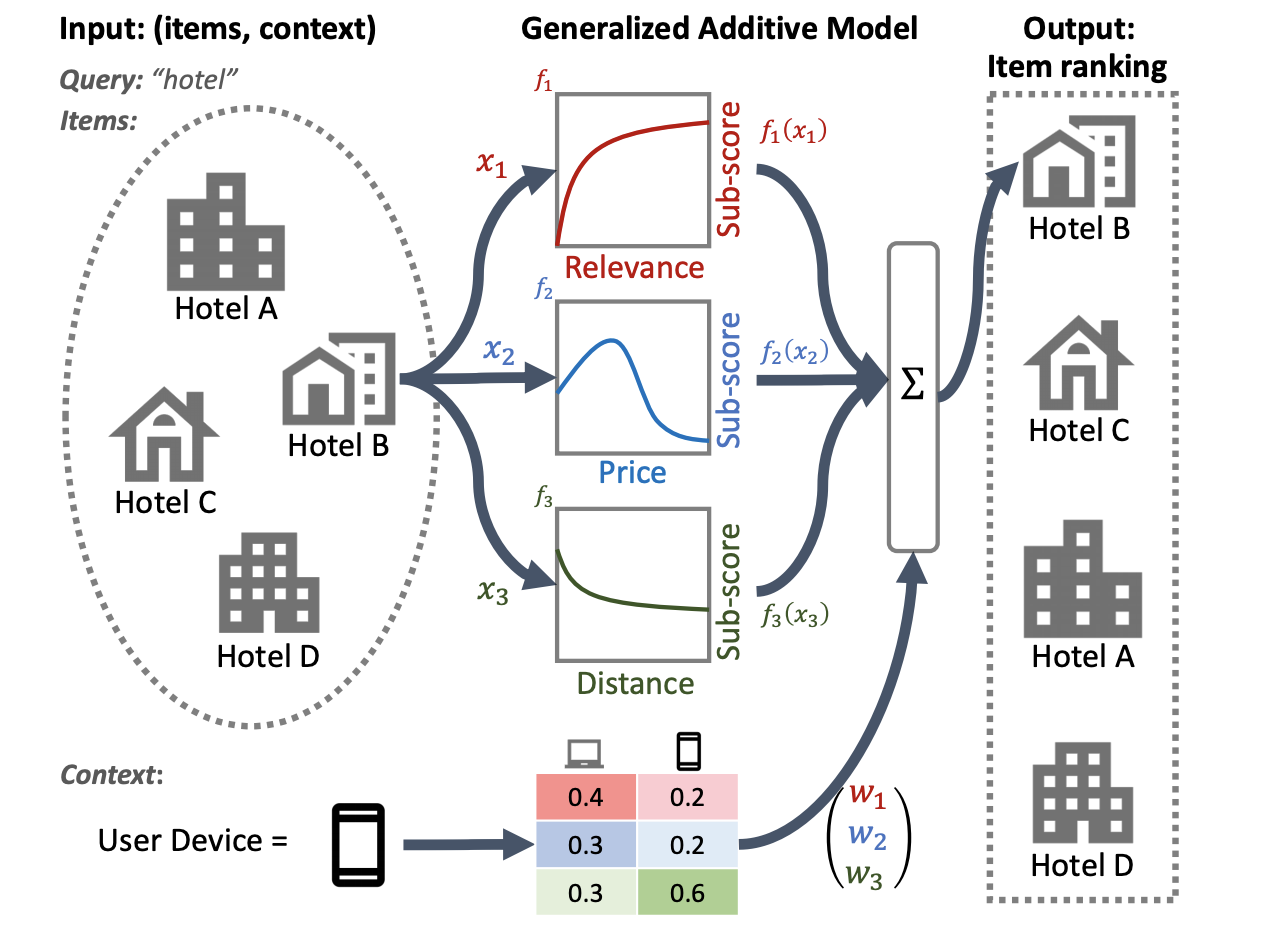
Więcej informacji na temat stosowania GAM z modelami rankingowymi można znaleźć w powiązanych badaniach . Możesz zacząć od przykładowej implementacji tej techniki w przykładowym kodzie rankingu TensorFlow.
Obsługa rankingów rozproszonych
Ranking TensorFlow jest przeznaczony do kompleksowego tworzenia wielkoskalowych systemów rankingowych: w tym przetwarzania danych, budowania modeli, oceny i wdrażania produkcyjnego. Może obsługiwać heterogeniczne, gęste i rzadkie funkcje, skalować do milionów punktów danych i jest przeznaczony do obsługi rozproszonego uczenia dla aplikacji rankingowych na dużą skalę.
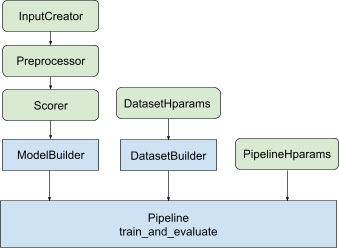
Biblioteka zapewnia zoptymalizowaną architekturę potoku rankingu, aby uniknąć powtarzalnego, szablonowego kodu i stworzyć rozproszone rozwiązania, które można zastosować od szkolenia modelu rankingowego do jego obsługi. Potok rankingowy obsługuje większość rozproszonych strategii TensorFlow, w tym MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy i ParameterServerStrategy . Potok rankingowy może wyeksportować wyszkolony model rankingowy w formacie tf.saved_model , który obsługuje kilka sygnatur wejściowych. Ponadto potok rankingowy zapewnia przydatne wywołania zwrotne, w tym obsługę wizualizacji danych TensorBoard i BackupAndRestore , aby pomóc w odzyskaniu sprawności po awariach w długotrwałych operacji szkoleniowych.
Biblioteka rankingowa pomaga w budowaniu rozproszonej implementacji szkoleniowej, udostępniając zestaw klas tfr.keras.pipeline , które jako dane wejściowe pobierają konstruktor modeli, konstruktor danych i hiperparametry. Oparta na Keras klasa tfr.keras.ModelBuilder umożliwia utworzenie modelu przetwarzania rozproszonego i współpracuje z rozszerzalnymi klasami InputCreator, Preprocessor i Scorer:
Klasy potoku TensorFlow Ranking współpracują również z DatasetBuilder w celu skonfigurowania danych szkoleniowych, które mogą zawierać hiperparametry . Wreszcie sam potok może zawierać zestaw hiperparametrów jako obiekt PipelineHparams .
Rozpocznij tworzenie modeli rankingu rozproszonego, korzystając z samouczka rankingu rozproszonego .