
TensorFlow रैंकिंग लाइब्रेरी आपको हाल के शोध से अच्छी तरह से स्थापित दृष्टिकोण और तकनीकों का उपयोग करके मशीन लर्निंग मॉडल को रैंक करने के लिए स्केलेबल लर्निंग बनाने में मदद करती है। एक रैंकिंग मॉडल समान वस्तुओं की एक सूची लेता है, जैसे कि वेब पेज, और उन वस्तुओं की एक अनुकूलित सूची तैयार करता है, उदाहरण के लिए सबसे कम प्रासंगिक पृष्ठों के लिए सबसे अधिक प्रासंगिक। मॉडलों को रैंक करना सीखने में खोज, प्रश्न उत्तर, अनुशंसा प्रणाली और संवाद प्रणाली में अनुप्रयोग होते हैं। आप केरस एपीआई का उपयोग करके अपने एप्लिकेशन के लिए रैंकिंग मॉडल बनाने में तेजी लाने के लिए इस लाइब्रेरी का उपयोग कर सकते हैं। रैंकिंग लाइब्रेरी वितरित प्रसंस्करण रणनीतियों का उपयोग करके बड़े डेटासेट के साथ प्रभावी ढंग से काम करने के लिए आपके मॉडल कार्यान्वयन को बढ़ाना आसान बनाने के लिए वर्कफ़्लो उपयोगिताएँ भी प्रदान करती है।
यह अवलोकन इस लाइब्रेरी के साथ मॉडलों को रैंक करने के लिए विकासशील शिक्षण का एक संक्षिप्त सारांश प्रदान करता है, लाइब्रेरी द्वारा समर्थित कुछ उन्नत तकनीकों का परिचय देता है, और रैंकिंग अनुप्रयोगों के लिए वितरित प्रसंस्करण का समर्थन करने के लिए प्रदान की गई वर्कफ़्लो उपयोगिताओं पर चर्चा करता है।
मॉडलों को रैंक करने के लिए सीखने का विकास करना
TensorFlow रैंकिंग लाइब्रेरी के साथ मॉडल बनाना इन सामान्य चरणों का पालन करता है:
- केरस परतों (
tf.keras.layers) का उपयोग करके स्कोरिंग फ़ंक्शन निर्दिष्ट करें - उन मेट्रिक्स को परिभाषित करें जिन्हें आप मूल्यांकन के लिए उपयोग करना चाहते हैं, जैसे
tfr.keras.metrics.NDCGMetric - एक हानि फ़ंक्शन निर्दिष्ट करें, जैसे कि
tfr.keras.losses.SoftmaxLoss - मॉडल को
tf.keras.Model.compile()के साथ संकलित करें और इसे अपने डेटा के साथ प्रशिक्षित करें
सिफ़ारिश मूवीज़ ट्यूटोरियल आपको इस लाइब्रेरी के साथ लर्निंग टू रैंक मॉडल बनाने की बुनियादी बातों से परिचित कराता है। बड़े पैमाने पर रैंकिंग मॉडल बनाने के बारे में अधिक जानकारी के लिए वितरित रैंकिंग सहायता अनुभाग देखें।
उन्नत रैंकिंग तकनीकें
TensorFlow रैंकिंग लाइब्रेरी Google शोधकर्ताओं और इंजीनियरों द्वारा शोध और कार्यान्वित उन्नत रैंकिंग तकनीकों को लागू करने के लिए सहायता प्रदान करती है। निम्नलिखित अनुभाग इनमें से कुछ तकनीकों का अवलोकन प्रदान करते हैं और अपने एप्लिकेशन में उनका उपयोग कैसे शुरू करें।
BERT सूची इनपुट ऑर्डरिंग
रैंकिंग लाइब्रेरी टीएफआर-बीईआरटी का कार्यान्वयन प्रदान करती है, एक स्कोरिंग आर्किटेक्चर जो सूची इनपुट के क्रम को अनुकूलित करने के लिए एलटीआर मॉडलिंग के साथ बीईआरटी को जोड़ता है। इस दृष्टिकोण के एक उदाहरण अनुप्रयोग के रूप में, एक क्वेरी और n दस्तावेज़ों की एक सूची पर विचार करें जिन्हें आप इस क्वेरी के जवाब में रैंक करना चाहते हैं। <query, document> जोड़ियों में स्वतंत्र रूप से स्कोर किए गए BERT प्रतिनिधित्व को सीखने के बजाय, LTR मॉडल संयुक्त रूप से BERT प्रतिनिधित्व को सीखने के लिए एक रैंकिंग हानि लागू करते हैं जो जमीनी सच्चाई लेबल के संबंध में संपूर्ण रैंक की गई सूची की उपयोगिता को अधिकतम करता है। निम्नलिखित चित्र इस तकनीक को दर्शाता है:
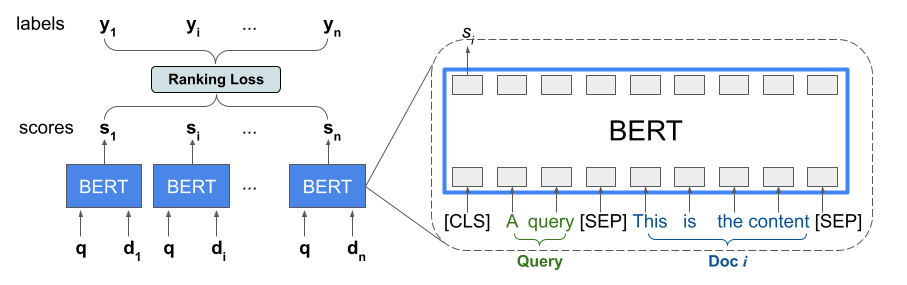
यह दृष्टिकोण किसी क्वेरी के जवाब में रैंक करने के लिए दस्तावेज़ों की सूची को <query, document> टुपल्स की सूची में समतल कर देता है। फिर इन टुपल्स को BERT पूर्व-प्रशिक्षित भाषा मॉडल में फीड किया जाता है। संपूर्ण दस्तावेज़ सूची के लिए एकत्रित BERT आउटपुट को TensorFlow रैंकिंग में उपलब्ध विशेष रैंकिंग हानियों में से एक के साथ संयुक्त रूप से ठीक किया जाता है।
यह आर्किटेक्चर पूर्व-प्रशिक्षित भाषा मॉडल के प्रदर्शन में महत्वपूर्ण सुधार प्रदान कर सकता है, कई लोकप्रिय रैंकिंग कार्यों के लिए अत्याधुनिक प्रदर्शन का उत्पादन कर सकता है , खासकर जब कई पूर्व-प्रशिक्षित भाषा मॉडल संयुक्त होते हैं। इस तकनीक पर अधिक जानकारी के लिए संबंधित शोध देखें। आप TensorFlow रैंकिंग उदाहरण कोड में एक सरल कार्यान्वयन के साथ शुरुआत कर सकते हैं।
तंत्रिका रैंकिंग सामान्यीकृत योजक मॉडल (जीएएम)
कुछ रैंकिंग प्रणालियों के लिए, जैसे ऋण पात्रता मूल्यांकन, विज्ञापन लक्ष्यीकरण, या चिकित्सा उपचार के लिए मार्गदर्शन, पारदर्शिता और व्याख्यात्मकता महत्वपूर्ण विचार हैं। अच्छी तरह से समझे गए भार कारकों के साथ सामान्यीकृत एडिटिव मॉडल (जीएएम) को लागू करने से आपके रैंकिंग मॉडल को अधिक समझाने और व्याख्या करने में मदद मिल सकती है।
जीएएम का प्रतिगमन और वर्गीकरण कार्यों के साथ बड़े पैमाने पर अध्ययन किया गया है, लेकिन यह कम स्पष्ट है कि उन्हें रैंकिंग एप्लिकेशन पर कैसे लागू किया जाए। उदाहरण के लिए, जबकि जीएएम को सूची में प्रत्येक व्यक्तिगत आइटम को मॉडल करने के लिए आसानी से लागू किया जा सकता है, आइटम इंटरैक्शन और जिस संदर्भ में इन आइटमों को रैंक किया गया है, दोनों को मॉडलिंग करना एक अधिक चुनौतीपूर्ण समस्या है। TensorFlow रैंकिंग तंत्रिका रैंकिंग GAM का कार्यान्वयन प्रदान करती है, जो रैंकिंग समस्याओं के लिए डिज़ाइन किए गए सामान्यीकृत एडिटिव मॉडल का विस्तार है। GAMs का TensorFlow रैंकिंग कार्यान्वयन आपको अपने मॉडल की सुविधाओं में विशिष्ट भार जोड़ने की अनुमति देता है।
होटल रैंकिंग प्रणाली का निम्नलिखित चित्रण प्राथमिक रैंकिंग सुविधाओं के रूप में प्रासंगिकता, कीमत और दूरी का उपयोग करता है। यह मॉडल उपयोगकर्ता के डिवाइस संदर्भ के आधार पर इन आयामों को अलग-अलग तरीके से तौलने के लिए GAM तकनीक लागू करता है। उदाहरण के लिए, यदि क्वेरी फ़ोन से आई है, तो दूरी को अधिक महत्व दिया जाता है, यह मानते हुए कि उपयोगकर्ता पास के होटल की तलाश कर रहे हैं।
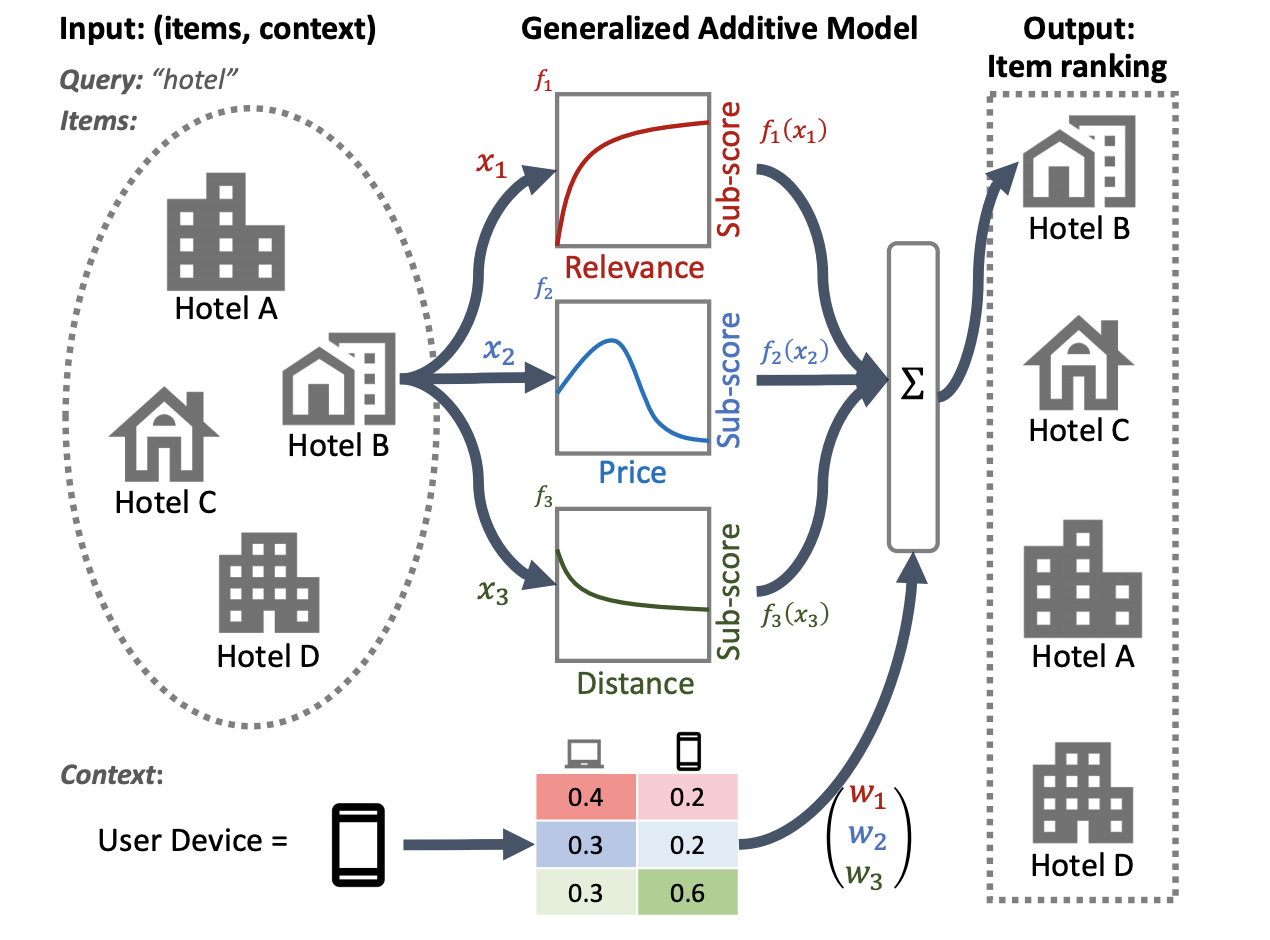
रैंकिंग मॉडल के साथ GAM का उपयोग करने के बारे में अधिक जानकारी के लिए, संबंधित शोध देखें। आप TensorFlow रैंकिंग उदाहरण कोड में इस तकनीक के एक नमूना कार्यान्वयन के साथ शुरुआत कर सकते हैं।
वितरित रैंकिंग समर्थन
TensorFlow रैंकिंग को शुरू से अंत तक बड़े पैमाने पर रैंकिंग सिस्टम बनाने के लिए डिज़ाइन किया गया है: जिसमें डेटा प्रोसेसिंग, मॉडल निर्माण, मूल्यांकन और उत्पादन परिनियोजन शामिल है। यह विषम सघन और विरल सुविधाओं को संभाल सकता है, लाखों डेटा बिंदुओं तक स्केल कर सकता है, और बड़े पैमाने पर रैंकिंग अनुप्रयोगों के लिए वितरित प्रशिक्षण का समर्थन करने के लिए डिज़ाइन किया गया है।
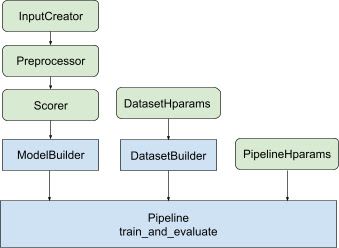
लाइब्रेरी दोहराए जाने वाले, बॉयलरप्लेट कोड से बचने और वितरित समाधान बनाने के लिए एक अनुकूलित रैंकिंग पाइपलाइन आर्किटेक्चर प्रदान करती है जिसे आपके रैंकिंग मॉडल को प्रशिक्षित करने से लेकर इसे परोसने तक लागू किया जा सकता है। रैंकिंग पाइपलाइन TensorFlow की अधिकांश वितरित रणनीतियों का समर्थन करती है, जिसमें मिररडस्ट्रेटी , टीपीयूस्ट्रेटी , मल्टीवर्करमिररडस्ट्रेटी और पैरामीटरसर्वरस्ट्रेटी शामिल हैं। रैंकिंग पाइपलाइन प्रशिक्षित रैंकिंग मॉडल को tf.saved_model प्रारूप में निर्यात कर सकती है, जो कई इनपुट हस्ताक्षरों का समर्थन करती है। इसके अलावा, रैंकिंग पाइपलाइन उपयोगी कॉलबैक प्रदान करती है, जिसमें लंबे समय तक चलने वाली विफलताओं से उबरने में मदद करने के लिए TensorBoard डेटा विज़ुअलाइज़ेशन और BackupAndRestore का समर्थन शामिल है। प्रशिक्षण संचालन.
रैंकिंग लाइब्रेरी tfr.keras.pipeline कक्षाओं का एक सेट प्रदान करके वितरित प्रशिक्षण कार्यान्वयन के निर्माण में सहायता करती है, जो इनपुट के रूप में एक मॉडल बिल्डर, डेटा बिल्डर और हाइपरपैरामीटर लेती है। केरस-आधारित tfr.keras.ModelBuilder वर्ग आपको वितरित प्रसंस्करण के लिए एक मॉडल बनाने में सक्षम बनाता है, और एक्स्टेंसिबल इनपुटक्रिएटर, प्रीप्रोसेसर और स्कोरर वर्गों के साथ काम करता है:
TensorFlow रैंकिंग पाइपलाइन कक्षाएं प्रशिक्षण डेटा सेट करने के लिए डेटासेटबिल्डर के साथ भी काम करती हैं, जिसमें हाइपरपैरामीटर शामिल हो सकते हैं। अंत में, पाइपलाइन में ही PipelineHparams ऑब्जेक्ट के रूप में हाइपरपैरामीटर का एक सेट शामिल हो सकता है।
वितरित रैंकिंग ट्यूटोरियल का उपयोग करके वितरित रैंकिंग मॉडल बनाना शुरू करें।