
La libreria TensorFlow Ranking ti aiuta a creare un apprendimento scalabile per classificare i modelli di machine learning utilizzando approcci e tecniche consolidati derivanti da ricerche recenti. Un modello di ranking prende un elenco di elementi simili, come le pagine web, e genera un elenco ottimizzato di tali elementi, ad esempio quelli più rilevanti per le pagine meno rilevanti. Imparare a classificare i modelli ha applicazioni nella ricerca, nella risposta alle domande, nei sistemi di raccomandazione e nei sistemi di dialogo. Puoi utilizzare questa libreria per accelerare la creazione di un modello di classificazione per la tua applicazione utilizzando l' API Keras . La libreria Ranking fornisce inoltre utilità del flusso di lavoro per facilitare l'ampliamento dell'implementazione del modello per lavorare in modo efficace con set di dati di grandi dimensioni utilizzando strategie di elaborazione distribuita.
Questa panoramica fornisce un breve riepilogo dello sviluppo dell'apprendimento per classificare i modelli con questa libreria, introduce alcune tecniche avanzate supportate dalla libreria e illustra le utilità del flusso di lavoro fornite per supportare l'elaborazione distribuita per la classificazione delle applicazioni.
Sviluppare l’apprendimento per classificare i modelli
Il modello di edificio con la libreria TensorFlow Ranking segue questi passaggi generali:
- Specificare una funzione di punteggio utilizzando i livelli Keras (
tf.keras.layers) - Definisci le metriche che desideri utilizzare per la valutazione, ad esempio
tfr.keras.metrics.NDCGMetric - Specificare una funzione di perdita, ad esempio
tfr.keras.losses.SoftmaxLoss - Compila il modello con
tf.keras.Model.compile()e addestralo con i tuoi dati
Il tutorial Consiglia film ti guida attraverso le nozioni di base per creare un modello di apprendimento per classificare con questa libreria. Consulta la sezione Supporto per il ranking distribuito per ulteriori informazioni sulla creazione di modelli di ranking su larga scala.
Tecniche di ranking avanzate
La libreria TensorFlow Ranking fornisce supporto per l'applicazione di tecniche di ranking avanzate ricercate e implementate dai ricercatori e ingegneri di Google. Le sezioni seguenti forniscono una panoramica di alcune di queste tecniche e come iniziare a utilizzarle nella tua applicazione.
Ordinamento degli input dell'elenco BERT
La libreria Ranking fornisce un'implementazione di TFR-BERT, un'architettura di punteggio che accoppia BERT con la modellazione LTR per ottimizzare l'ordinamento degli input dell'elenco. Come esempio di applicazione di questo approccio, considera una query e un elenco di n documenti che desideri classificare in risposta a questa query. Invece di apprendere una rappresentazione BERT valutata in modo indipendente attraverso le coppie <query, document> , i modelli LTR applicano una perdita di classificazione per apprendere congiuntamente una rappresentazione BERT che massimizza l’utilità dell’intera lista classificata rispetto alle etichette di verità. La figura seguente illustra questa tecnica:
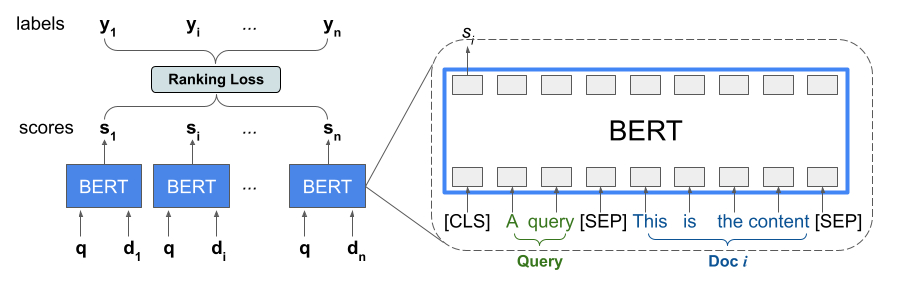
Questo approccio appiattisce un elenco di documenti da classificare in risposta a una query in un elenco di tuple <query, document> . Queste tuple vengono quindi inserite in un modello linguistico pre-addestrato BERT. Gli output BERT raggruppati per l'intero elenco di documenti vengono quindi ottimizzati congiuntamente con una delle perdite di classificazione specializzate disponibili in TensorFlow Ranking.
Questa architettura può fornire miglioramenti significativi nelle prestazioni del modello linguistico preaddestrato, producendo prestazioni all'avanguardia per diverse attività di classificazione popolari, soprattutto quando vengono combinati più modelli linguistici preaddestrati. Per ulteriori informazioni su questa tecnica consultare la ricerca correlata. Puoi iniziare con una semplice implementazione nel codice di esempio TensorFlow Ranking.
Modelli additivi generalizzati di classificazione neurale (GAM)
Per alcuni sistemi di classificazione, come la valutazione dell’ammissibilità del prestito, il targeting degli annunci pubblicitari o la guida per le cure mediche, la trasparenza e la spiegabilità sono considerazioni critiche. L'applicazione di modelli additivi generalizzati (GAM) con fattori di ponderazione ben compresi può aiutare il modello di classificazione a essere più spiegabile e interpretabile.
I GAM sono stati ampiamente studiati con compiti di regressione e classificazione, ma è meno chiaro come applicarli a un'applicazione di classificazione. Ad esempio, mentre i GAM possono essere semplicemente applicati per modellare ogni singolo elemento nell'elenco, modellare sia le interazioni degli elementi che il contesto in cui questi elementi sono classificati è un problema più impegnativo. TensorFlow Ranking fornisce un'implementazione del ranking neurale GAM , un'estensione di modelli additivi generalizzati progettati per problemi di ranking. L' implementazione TensorFlow Ranking dei GAM ti consente di aggiungere una ponderazione specifica alle funzionalità del tuo modello.
La seguente illustrazione di un sistema di classificazione di hotel utilizza pertinenza, prezzo e distanza come caratteristiche principali di classificazione. Questo modello applica una tecnica GAM per valutare queste dimensioni in modo diverso, in base al contesto del dispositivo dell'utente. Ad esempio, se la query proviene da un telefono, la distanza viene ponderata maggiormente, presupponendo che gli utenti stiano cercando un hotel nelle vicinanze.
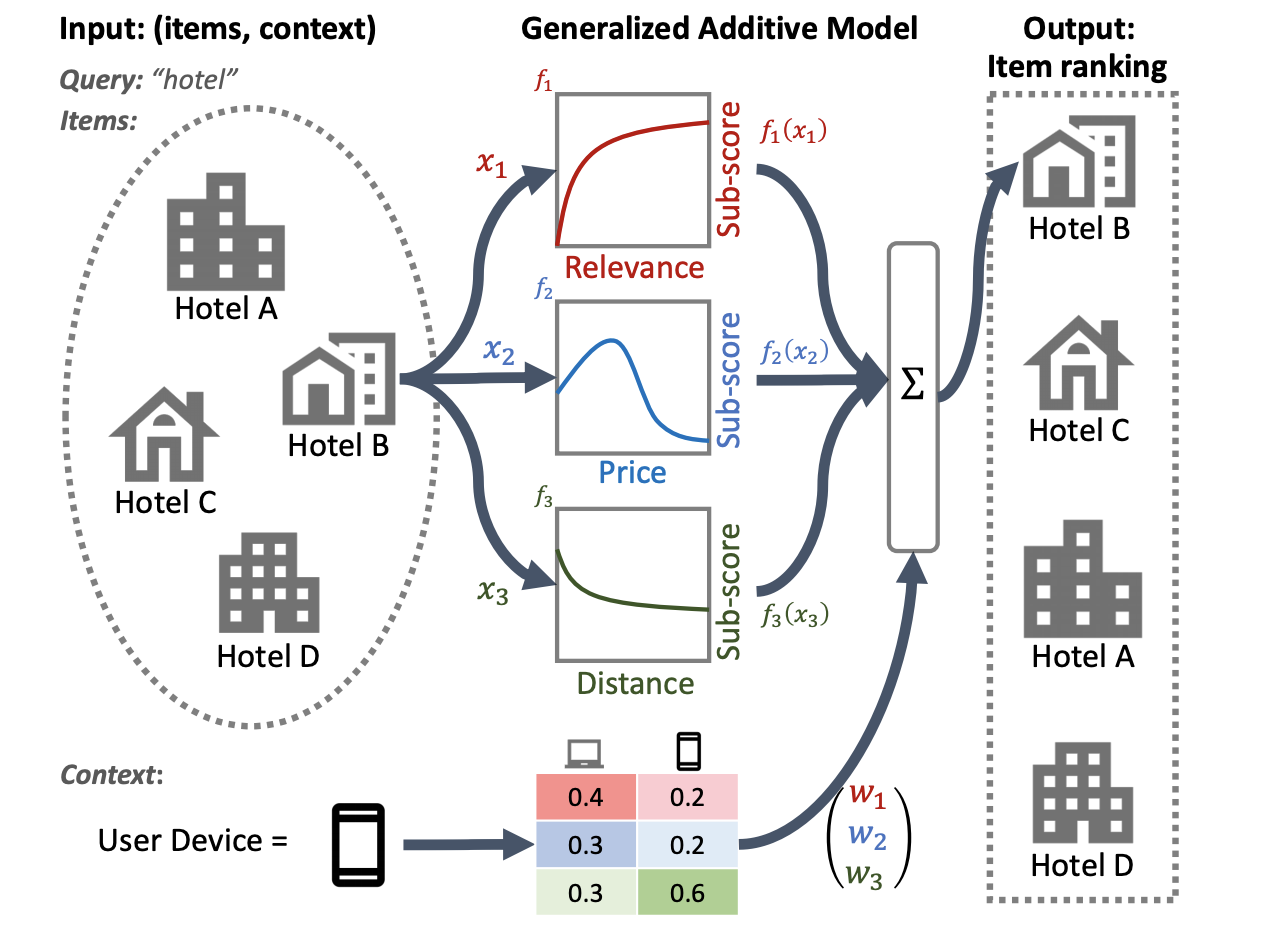
Per ulteriori informazioni sull'utilizzo dei GAM con modelli di classificazione, consultare la ricerca correlata. Puoi iniziare con un'implementazione di esempio di questa tecnica nel codice di esempio TensorFlow Ranking.
Supporto per la classificazione distribuita
TensorFlow Ranking è progettato per la creazione di sistemi di classificazione end-to-end su larga scala: compresa l'elaborazione dei dati, la creazione di modelli, la valutazione e l'implementazione della produzione. Può gestire funzionalità eterogenee, dense e sparse, scalare fino a milioni di punti dati ed è progettato per supportare la formazione distribuita per applicazioni di classificazione su larga scala.
La libreria fornisce un'architettura della pipeline di classificazione ottimizzata, per evitare codice ripetitivo e standard e creare soluzioni distribuite che possono essere applicate dall'addestramento del modello di classificazione al suo servizio. La pipeline di classificazione supporta la maggior parte delle strategie distribuite di TensorFlow, tra cui MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy e ParametroServerStrategy . La pipeline di classificazione può esportare il modello di classificazione addestrato nel formato tf.saved_model , che supporta diverse firme di input. Inoltre, la pipeline di classificazione fornisce callback utili, incluso il supporto per la visualizzazione dei dati TensorBoard e BackupAndRestore per aiutare il ripristino da errori di lunga esecuzione operazioni di formazione.
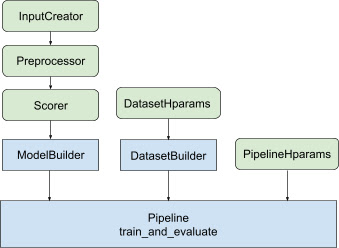
La libreria di classificazione assiste nella creazione di un'implementazione di formazione distribuita fornendo una serie di classi tfr.keras.pipeline , che accettano come input un generatore di modelli, un generatore di dati e iperparametri. La classe tfr.keras.ModelBuilder basata su Keras consente di creare un modello per l'elaborazione distribuita e funziona con le classi InputCreator, Preprocessor e Scorer estensibili:
Le classi della pipeline TensorFlow Ranking funzionano anche con un DatasetBuilder per impostare i dati di training, che possono incorporare iperparametri . Infine, la pipeline stessa può includere un set di iperparametri come oggetto PipelineHparams .
Inizia a creare modelli di classificazione distribuita utilizzando il tutorial sulla classificazione distribuita .