
ไลบรารีการจัดอันดับ TensorFlow ช่วยให้คุณสร้าง การเรียนรู้ที่ปรับขนาดได้เพื่อจัดอันดับ โมเดลการเรียนรู้ของเครื่องโดยใช้แนวทางและเทคนิคที่มีชื่อเสียงจากการวิจัยล่าสุด โมเดลการจัดอันดับจะรับรายการที่คล้ายกัน เช่น หน้าเว็บ และสร้างรายการที่ได้รับการปรับปรุงให้เหมาะสมของรายการเหล่านั้น เช่น เกี่ยวข้องกับหน้าที่มีความเกี่ยวข้องน้อยที่สุด การเรียนรู้ที่จะจัดอันดับแบบจำลองมีแอปพลิเคชันในการค้นหา การตอบคำถาม ระบบผู้แนะนำ และระบบการสนทนา คุณสามารถใช้ไลบรารีนี้เพื่อเร่งการสร้างแบบจำลองการจัดอันดับสำหรับแอปพลิเคชันของคุณโดยใช้ Keras API ไลบรารีการจัดอันดับยังมียูทิลิตี้เวิร์กโฟลว์เพื่อให้ง่ายต่อการขยายขนาดการใช้งานแบบจำลองของคุณเพื่อให้ทำงานอย่างมีประสิทธิภาพกับชุดข้อมูลขนาดใหญ่โดยใช้กลยุทธ์การประมวลผลแบบกระจาย
ภาพรวมนี้ให้ข้อมูลสรุปโดยย่อเกี่ยวกับการพัฒนาการเรียนรู้เพื่อจัดอันดับโมเดลด้วยไลบรารีนี้ แนะนำเทคนิคขั้นสูงบางอย่างที่ไลบรารีสนับสนุน และอภิปรายการยูทิลิตีเวิร์กโฟลว์ที่มีให้เพื่อรองรับการประมวลผลแบบกระจายสำหรับการจัดอันดับแอปพลิเคชัน
พัฒนาการเรียนรู้เพื่อจัดอันดับโมเดล
การสร้างโมเดลด้วยไลบรารี TensorFlow Ranking ทำตามขั้นตอนทั่วไปเหล่านี้:
- ระบุฟังก์ชันการให้คะแนนโดยใช้เลเยอร์ Keras (
tf.keras.layers) - กำหนดเมทริกที่คุณต้องการใช้สำหรับการประเมินผล เช่น
tfr.keras.metrics.NDCGMetric - ระบุฟังก์ชันการสูญเสีย เช่น
tfr.keras.losses.SoftmaxLoss - คอมไพล์โมเดลด้วย
tf.keras.Model.compile()และฝึกฝนกับข้อมูลของคุณ
บทช่วยสอนแนะนำภาพยนตร์ จะแนะนำคุณเกี่ยวกับพื้นฐานของการสร้างการเรียนรู้เพื่อจัดอันดับโมเดลด้วยไลบรารีนี้ ตรวจสอบส่วน การสนับสนุนการจัดอันดับแบบกระจาย สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการสร้างแบบจำลองการจัดอันดับขนาดใหญ่
เทคนิคการจัดอันดับขั้นสูง
ไลบรารี TensorFlow Ranking ให้การสนับสนุนการใช้เทคนิคการจัดอันดับขั้นสูงที่นักวิจัยและวิศวกรของ Google วิจัยและนำไปใช้ ส่วนต่อไปนี้จะให้ภาพรวมของเทคนิคบางอย่างเหล่านี้และวิธีเริ่มต้นใช้งานในแอปพลิเคชันของคุณ
การเรียงลำดับอินพุตรายการ BERT
ไลบรารีการจัดอันดับจัดให้มีการใช้งาน TFR-BERT ซึ่งเป็นสถาปัตยกรรมการให้คะแนนที่จับคู่ BERT กับการสร้างแบบจำลอง LTR เพื่อเพิ่มประสิทธิภาพการเรียงลำดับอินพุตรายการ เพื่อเป็นตัวอย่างของการประยุกต์ใช้แนวทางนี้ ให้พิจารณาแบบสอบถามและรายการเอกสาร n ฉบับที่คุณต้องการจัดอันดับเพื่อตอบสนองต่อแบบสอบถามนี้ แทนที่จะเรียนรู้การเป็นตัวแทน BERT โดยให้คะแนนอย่างเป็นอิสระจากคู่ <query, document> โมเดล LTR ใช้ การสูญเสียการจัดอันดับ เพื่อร่วมกันเรียนรู้การเป็นตัวแทน BERT ที่เพิ่มประโยชน์สูงสุดจากรายการจัดอันดับทั้งหมดโดยคำนึงถึงป้ายกำกับความจริงภาคพื้นดิน รูปต่อไปนี้แสดงให้เห็นถึงเทคนิคนี้:
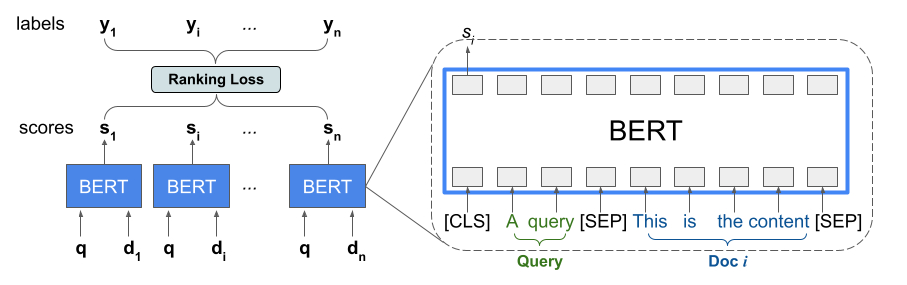
วิธีการนี้จะทำให้รายการเอกสารเรียบขึ้นเพื่อจัดอันดับในการตอบสนองต่อคิวรีในรายการสิ่ง <query, document> สิ่งอันดับเหล่านี้จะถูกป้อนเข้าสู่โมเดลภาษาที่ได้รับการฝึกอบรมล่วงหน้าของ BERT เอาต์พุต BERT ที่รวมกลุ่มสำหรับรายการเอกสารทั้งหมดจะได้รับการปรับแต่งร่วมกับหนึ่งใน การสูญเสียการจัดอันดับ เฉพาะที่มีอยู่ใน TensorFlow Ranking
สถาปัตยกรรมนี้สามารถนำเสนอการปรับปรุงที่สำคัญในประสิทธิภาพของโมเดลภาษาที่ผ่านการฝึกอบรม ทำให้เกิด ประสิทธิภาพที่ล้ำสมัยสำหรับงานจัดอันดับยอดนิยมหลายๆ งาน โดยเฉพาะอย่างยิ่งเมื่อมีการรวมโมเดลภาษาที่ผ่านการฝึกอบรมมาแล้วหลายรายการเข้าด้วยกัน สำหรับข้อมูลเพิ่มเติมเกี่ยวกับเทคนิคนี้ โปรดดู งานวิจัย ที่เกี่ยวข้อง คุณสามารถเริ่มต้นด้วยการใช้งานง่ายๆ ใน โค้ดตัวอย่าง TensorFlow Ranking
แบบจำลองการเติมทั่วไปของการจัดอันดับประสาท (GAM)
สำหรับระบบการจัดอันดับบางระบบ เช่น การประเมินคุณสมบัติสินเชื่อ การกำหนดเป้าหมายการโฆษณา หรือคำแนะนำสำหรับการรักษาพยาบาล ความโปร่งใสและความสามารถในการอธิบายถือเป็นข้อพิจารณาที่สำคัญ การใช้ โมเดลการบวกทั่วไป (GAM) กับปัจจัยการถ่วงน้ำหนักที่เข้าใจกันดีสามารถช่วยให้โมเดลการจัดอันดับของคุณอธิบายและตีความได้ง่ายขึ้น
GAM ได้รับการศึกษาอย่างกว้างขวางเกี่ยวกับงานการถดถอยและการจัดหมวดหมู่ แต่ยังไม่ค่อยชัดเจนนักว่าจะนำไปใช้กับแอปพลิเคชันการจัดอันดับได้อย่างไร ตัวอย่างเช่น แม้ว่า GAM สามารถนำไปใช้ในการสร้างแบบจำลองแต่ละรายการในรายการได้ แต่การสร้างแบบจำลองทั้งการโต้ตอบของรายการและบริบทในการจัดอันดับรายการเหล่านี้ถือเป็นปัญหาที่ท้าทายยิ่งกว่า TensorFlow Ranking นำเสนอการใช้งาน GAM การจัดอันดับแบบนิวรัล ซึ่งเป็นส่วนขยายของโมเดลเสริมทั่วไปที่ออกแบบมาเพื่อปัญหาการจัดอันดับ การใช้งาน TensorFlow Ranking ของ GAM ช่วยให้คุณสามารถเพิ่มการถ่วงน้ำหนักเฉพาะให้กับคุณลักษณะของโมเดลของคุณได้
ภาพประกอบของระบบการจัดอันดับโรงแรมต่อไปนี้ใช้ความเกี่ยวข้อง ราคา และระยะทางเป็นคุณลักษณะการจัดอันดับหลัก โมเดลนี้ใช้เทคนิค GAM เพื่อชั่งน้ำหนักมิติข้อมูลเหล่านี้ให้แตกต่างออกไป โดยขึ้นอยู่กับบริบทของอุปกรณ์ของผู้ใช้ ตัวอย่างเช่น หากข้อความค้นหามาจากโทรศัพท์ ระยะทางจะถูกถ่วงน้ำหนักมากขึ้น โดยสมมติว่าผู้ใช้กำลังมองหาโรงแรมในบริเวณใกล้เคียง
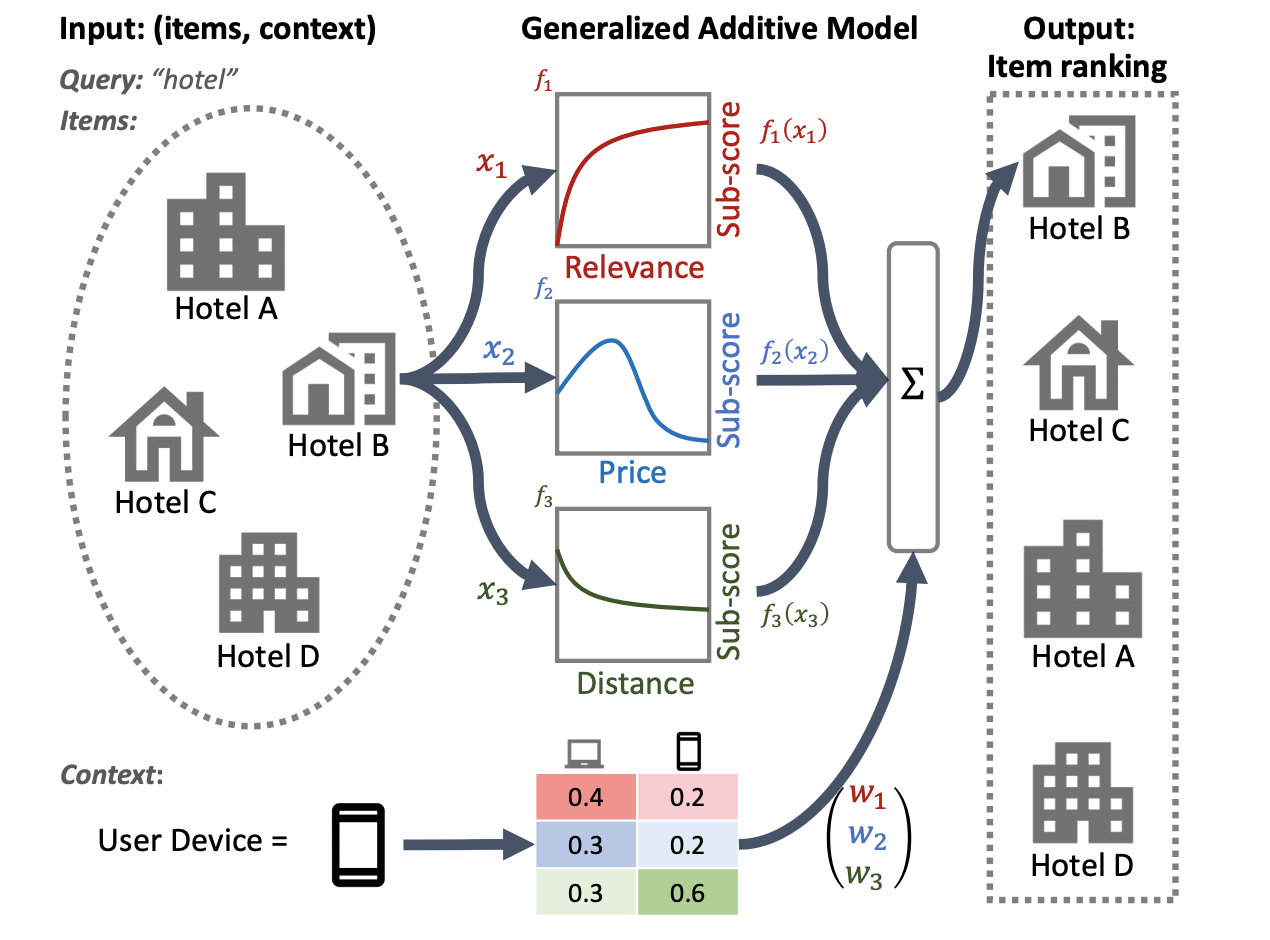
สำหรับข้อมูลเพิ่มเติมเกี่ยวกับการใช้ GAM กับโมเดลการจัดอันดับ โปรดดู การวิจัย ที่เกี่ยวข้อง คุณสามารถเริ่มต้นใช้งานตัวอย่างการใช้เทคนิคนี้ได้ใน โค้ดตัวอย่าง TensorFlow Ranking
การสนับสนุนการจัดอันดับแบบกระจาย
TensorFlow Ranking ได้รับการออกแบบมาเพื่อสร้างระบบการจัดอันดับขนาดใหญ่แบบ end-to-end: รวมถึงการประมวลผลข้อมูล การสร้างแบบจำลอง การประเมินผล และการใช้งานจริง สามารถรองรับฟีเจอร์ที่มีความหนาแน่นและกระจัดกระจายต่างกัน ขยายจุดข้อมูลได้สูงสุดถึงล้านจุด และได้รับการออกแบบมาเพื่อรองรับ การฝึกอบรมแบบกระจาย สำหรับแอปพลิเคชันการจัดอันดับขนาดใหญ่
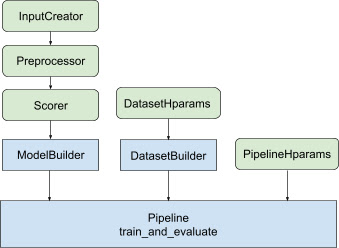
ไลบรารีมีสถาปัตยกรรมไปป์ไลน์การจัดอันดับที่ได้รับการปรับปรุงให้เหมาะสม เพื่อหลีกเลี่ยงการใช้โค้ดสำเร็จรูปซ้ำๆ และสร้างโซลูชันแบบกระจายที่สามารถนำไปใช้ได้ตั้งแต่การฝึกโมเดลการจัดอันดับของคุณไปจนถึงการให้บริการ ไปป์ไลน์การจัดอันดับสนับสนุน กลยุทธ์แบบกระจาย ส่วนใหญ่ของ TensorFlow รวมถึง MirroredStrategy , TPUStrategy , MultiWorkerMirroredStrategy และ ParameterServerStrategy ไปป์ไลน์การจัดอันดับสามารถส่งออกโมเดลการจัดอันดับที่ได้รับการฝึกในรูปแบบ tf.saved_model ซึ่งรองรับ ลายเซ็น อินพุตหลายรายการ .. นอกจากนี้ ไปป์ไลน์การจัดอันดับยังให้การเรียกกลับที่เป็นประโยชน์ รวมถึงการรองรับการแสดงภาพข้อมูล TensorBoard และ BackupAndRestore เพื่อช่วยกู้คืนจากความล้มเหลวในระยะยาว การดำเนินการฝึกอบรม
ไลบรารีการจัดอันดับช่วยในการสร้างการดำเนินการฝึกอบรมแบบกระจายโดยจัดเตรียมชุดคลาส tfr.keras.pipeline ซึ่งใช้ตัวสร้างโมเดล ตัวสร้างข้อมูล และไฮเปอร์พารามิเตอร์เป็นอินพุต คลาส tfr.keras.ModelBuilder ที่ใช้ Keras ช่วยให้คุณสร้างโมเดลสำหรับการประมวลผลแบบกระจาย และทำงานร่วมกับคลาส InputCreator, Preprocessor และ Scorer ที่ขยายได้:
คลาสไปป์ไลน์การจัดอันดับ TensorFlow ยังทำงานร่วมกับ DatasetBuilder เพื่อตั้งค่าข้อมูลการฝึก ซึ่งสามารถรวม ไฮเปอร์พารามิเตอร์ ได้ สุดท้าย ไปป์ไลน์สามารถรวมชุดของไฮเปอร์พารามิเตอร์เป็นออบเจ็ กต์ PipelineHparams ได้
เริ่มต้นสร้างแบบจำลองการจัดอันดับแบบกระจายโดยใช้ บทช่วยสอนการจัดอันดับแบบกระจาย