Narzędzia do przetwarzania tekstu dla TensorFlow
TensorFlow udostępnia dwie biblioteki do przetwarzania tekstu i języka naturalnego: KerasNLP i TensorFlow Text. KerasNLP to biblioteka wysokiego poziomu przetwarzania języka naturalnego (NLP), która obejmuje nowoczesne modele oparte na transformatorach, a także narzędzia tokenizacji niższego poziomu. Jest to zalecane rozwiązanie dla większości przypadków użycia NLP. Zbudowany na TensorFlow Text, KerasNLP wyodrębnia operacje przetwarzania tekstu niskiego poziomu w interfejs API zaprojektowany z myślą o łatwości użytkowania. Ale jeśli wolisz nie pracować z interfejsem API Keras lub potrzebujesz dostępu do operacji przetwarzania tekstu niższego poziomu, możesz bezpośrednio użyć TensorFlow Text.
KerasNLP
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
Najłatwiejszym sposobem rozpoczęcia przetwarzania tekstu w TensorFlow jest użycie KerasNLP. KerasNLP to biblioteka przetwarzania języka naturalnego, która obsługuje przepływy pracy zbudowane z modułowych komponentów, które mają najnowocześniejsze wstępnie ustawione wagi i architektury. Możesz używać komponentów KerasNLP z ich gotową konfiguracją. Jeśli potrzebujesz większej kontroli, możesz łatwo dostosować komponenty. KerasNLP kładzie nacisk na obliczenia w grafie dla wszystkich przepływów pracy, więc możesz oczekiwać łatwej produkcji przy użyciu ekosystemu TensorFlow.
KerasNLP jest rozszerzeniem podstawowego API Keras, a wszystkie moduły wysokiego poziomu KerasNLP to Warstwy lub Modele. Jeśli znasz Keras, rozumiesz już większość KerasNLP.
Aby dowiedzieć się więcej, zobacz KerasNLP .
Tekst TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
KerasNLP zapewnia moduły przetwarzania tekstu wysokiego poziomu, które są dostępne jako warstwy lub modele. Jeśli potrzebujesz dostępu do narzędzi niższego poziomu, możesz użyć TensorFlow Text. TensorFlow Text zapewnia bogatą kolekcję operacji i bibliotek, które pomogą Ci pracować z danymi wejściowymi w formie tekstowej, takiej jak nieprzetworzone ciągi tekstowe lub dokumenty. Biblioteki te mogą regularnie przeprowadzać wstępne przetwarzanie wymagane przez modele tekstowe i zawierać inne funkcje przydatne do modelowania sekwencji.
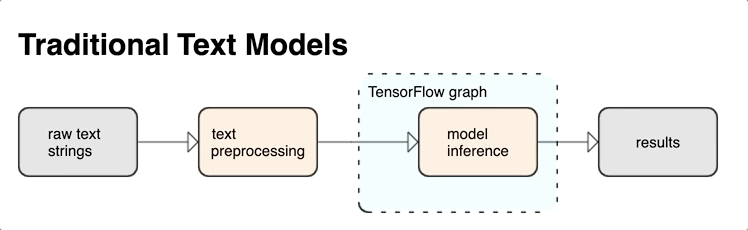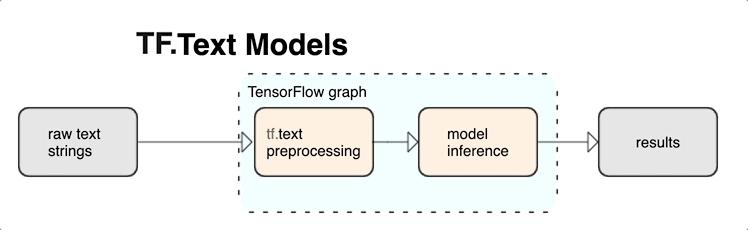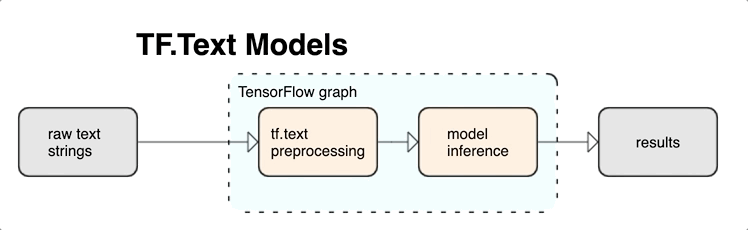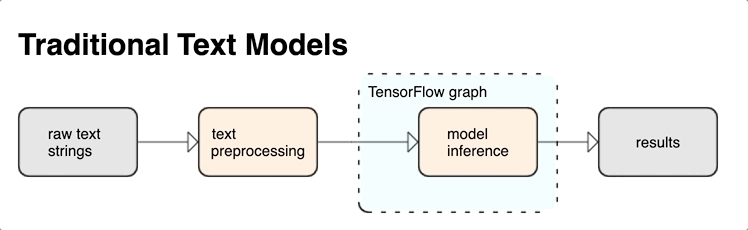
Możesz wyodrębnić potężne składniowe i semantyczne cechy tekstu z wykresu TensorFlow jako dane wejściowe do swojej sieci neuronowej.
Integracja przetwarzania wstępnego z wykresem TensorFlow zapewnia następujące korzyści:
- Ułatwia duży zestaw narzędzi do pracy z tekstem
- Umożliwia integrację z dużym zestawem narzędzi TensorFlow w celu obsługi projektów od zdefiniowania problemu przez szkolenie, ocenę i uruchomienie
- Zmniejsza złożoność w czasie serwowania i zapobiega przekrzywianiu serwowania podczas szkolenia
Oprócz powyższego nie musisz się martwić, że tokenizacja podczas uczenia różni się od tokenizacji przy wnioskowaniu lub zarządzaniu skryptami przetwarzania wstępnego.