Công cụ xử lý văn bản cho TensorFlow
TensorFlow cung cấp hai thư viện để xử lý văn bản và ngôn ngữ tự nhiên: KerasNLP và TensorFlow Text. KerasNLP là thư viện xử lý ngôn ngữ tự nhiên (NLP) cấp cao bao gồm các mô hình dựa trên máy biến áp hiện đại cũng như các tiện ích mã thông báo cấp thấp hơn. Đó là giải pháp được đề xuất cho hầu hết các trường hợp sử dụng NLP. Được xây dựng trên Văn bản TensorFlow, KerasNLP trừu tượng hóa các hoạt động xử lý văn bản cấp thấp thành một API được thiết kế để dễ sử dụng. Nhưng nếu bạn không muốn làm việc với API Keras hoặc bạn cần quyền truy cập vào các hoạt động xử lý văn bản cấp thấp hơn, bạn có thể sử dụng trực tiếp Văn bản TensorFlow.
KerasNLP
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
Cách dễ nhất để bắt đầu xử lý văn bản trong TensorFlow là sử dụng KerasNLP. KerasNLP là một thư viện xử lý ngôn ngữ tự nhiên hỗ trợ các quy trình công việc được xây dựng từ các thành phần mô-đun có trọng lượng và kiến trúc đặt trước tiên tiến nhất. Bạn có thể sử dụng các thành phần KerasNLP với cấu hình vượt trội của chúng. Nếu bạn cần kiểm soát nhiều hơn, bạn có thể dễ dàng tùy chỉnh các thành phần. KerasNLP nhấn mạnh tính toán trong biểu đồ cho tất cả các quy trình công việc, do đó bạn có thể mong đợi quá trình sản xuất dễ dàng bằng cách sử dụng hệ sinh thái TensorFlow.
KerasNLP là phần mở rộng của API Keras cốt lõi và tất cả các mô-đun KerasNLP cấp cao đều là Lớp hoặc Mô hình. Nếu bạn đã quen thuộc với Keras, thì bạn đã hiểu hầu hết về KerasNLP.
Để tìm hiểu thêm, hãy xem KerasNLP .
Văn bản TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
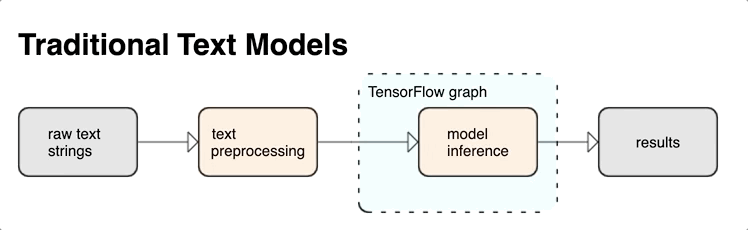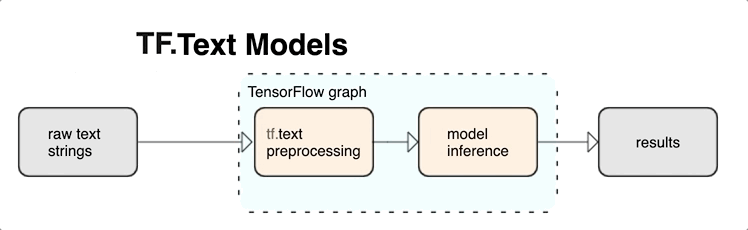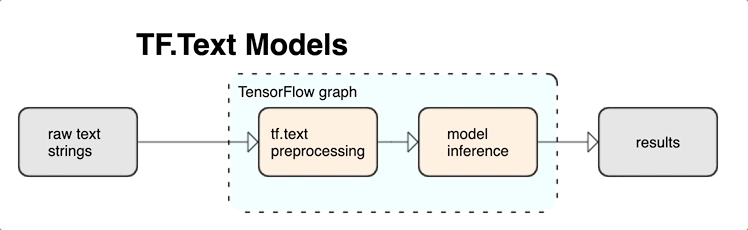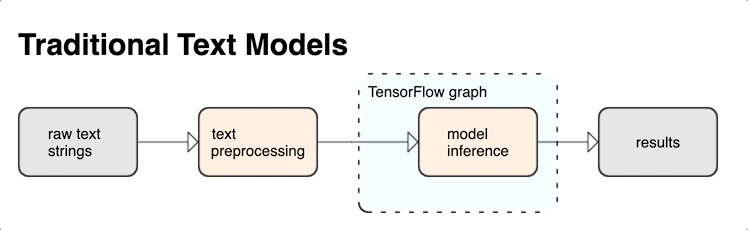
KerasNLP cung cấp các mô-đun xử lý văn bản cấp cao có sẵn dưới dạng lớp hoặc mô hình. Nếu bạn cần quyền truy cập vào các công cụ cấp thấp hơn, bạn có thể sử dụng Văn bản TensorFlow. TensorFlow Text cung cấp cho bạn một bộ sưu tập phong phú các op và thư viện để giúp bạn làm việc với đầu vào ở dạng văn bản, chẳng hạn như chuỗi văn bản thô hoặc tài liệu. Các thư viện này có thể thực hiện tiền xử lý thường xuyên theo yêu cầu của các mô hình dựa trên văn bản và bao gồm các tính năng khác hữu ích cho mô hình trình tự.
Bạn có thể trích xuất các tính năng văn bản ngữ nghĩa và cú pháp mạnh mẽ từ bên trong biểu đồ TensorFlow làm đầu vào cho mạng nơ-ron của mình.
Tích hợp tiền xử lý với biểu đồ TensorFlow mang lại các lợi ích sau:
- Tạo điều kiện cho một bộ công cụ lớn để làm việc với văn bản
- Cho phép tích hợp với bộ công cụ TensorFlow lớn để hỗ trợ các dự án từ xác định vấn đề cho đến đào tạo, đánh giá và khởi chạy
- Giảm độ phức tạp trong thời gian phục vụ và ngăn ngừa sai lệch phục vụ đào tạo
Ngoài những điều trên, bạn không cần phải lo lắng về việc mã thông báo trong quá trình đào tạo khác với mã thông báo khi suy luận hoặc quản lý các tập lệnh tiền xử lý.