ابزارهای پردازش متن برای TensorFlow
TensorFlow دو کتابخانه برای پردازش متن و زبان طبیعی فراهم می کند: KerasNLP و TensorFlow Text. KerasNLP یک کتابخانه پردازش زبان طبیعی (NLP) سطح بالا است که شامل مدلهای مبتنی بر ترانسفورماتور مدرن و همچنین ابزارهای توکنسازی سطح پایینتر است. این راه حل توصیه شده برای اکثر موارد استفاده از NLP است. KerasNLP که بر روی متن TensorFlow ساخته شده است، عملیات پردازش متن سطح پایین را در یک API که برای سهولت استفاده طراحی شده است، خلاصه می کند. اما اگر ترجیح می دهید با Keras API کار نکنید یا نیاز به دسترسی به عملیات پردازش متن سطح پایین دارید، می توانید مستقیماً از TensorFlow Text استفاده کنید.
KerasNLP
import keras_nlp
import tensorflow_datasets as tfds
imdb_train, imdb_test = tfds.load(
"imdb_reviews",
split=["train", "test"],
as_supervised=True,
batch_size=16,
)
# Load a BERT model.
classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased")
# Fine-tune on IMDb movie reviews.
classifier.fit(imdb_train, validation_data=imdb_test)
# Predict two new examples.
classifier.predict(["What an amazing movie!", "A total waste of my time."])
شروع سریع را در GitHub ببینید.
ساده ترین راه برای شروع پردازش متن در TensorFlow استفاده از KerasNLP است. KerasNLP یک کتابخانه پردازش زبان طبیعی است که از جریان های کاری ساخته شده از اجزای مدولار که دارای وزن ها و معماری های از پیش تعیین شده پیشرفته هستند پشتیبانی می کند. می توانید از اجزای KerasNLP با پیکربندی خارج از جعبه آنها استفاده کنید. اگر به کنترل بیشتری نیاز دارید، می توانید به راحتی اجزا را سفارشی کنید. KerasNLP بر محاسبات درون گراف برای همه گردشهای کاری تاکید دارد، بنابراین میتوانید انتظار تولید آسان با استفاده از اکوسیستم TensorFlow را داشته باشید.
KerasNLP یک برنامه افزودنی از هسته Keras API است و همه ماژولهای KerasNLP سطح بالا لایهها یا مدلها هستند. اگر با Keras آشنایی دارید، از قبل بیشتر KerasNLP را درک کرده اید.
برای کسب اطلاعات بیشتر، KerasNLP را ببینید.
متن TensorFlow
import tensorflow as tf
import tensorflow_text as tf_text
def preprocess(vocab_lookup_table, example_text):
# Normalize text
tf_text.normalize_utf8(example_text)
# Tokenize into words
word_tokenizer = tf_text.WhitespaceTokenizer()
tokens = word_tokenizer.tokenize(example_text)
# Tokenize into subwords
subword_tokenizer = tf_text.WordpieceTokenizer(
vocab_lookup_table, token_out_type=tf.int64)
subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1)
# Apply padding
padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16)
return padded_inputs
اجرا در یک نوت بوک
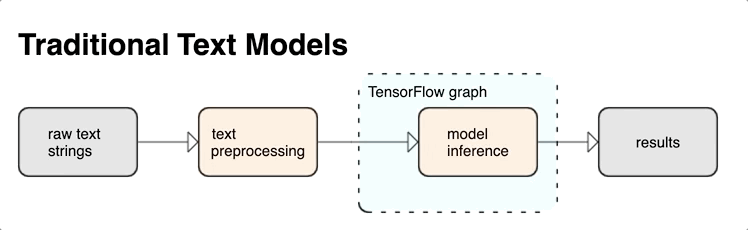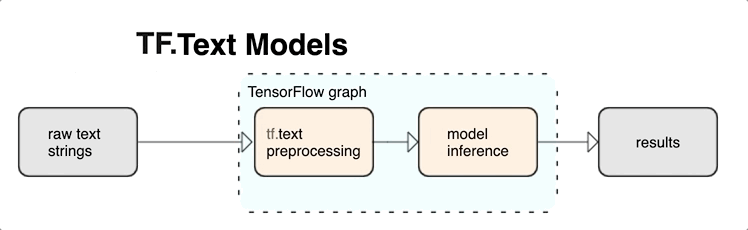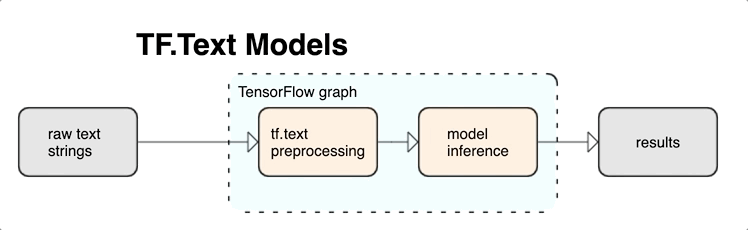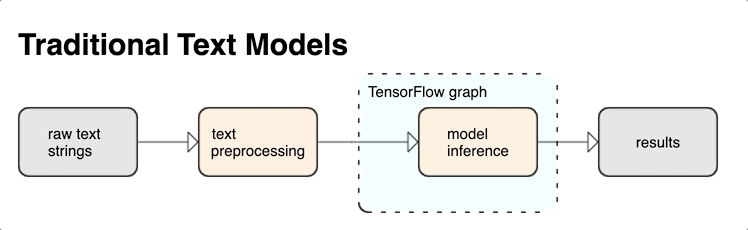
KerasNLP ماژول های پردازش متن سطح بالایی را ارائه می دهد که به صورت لایه یا مدل در دسترس هستند. اگر نیاز به دسترسی به ابزارهای سطح پایین دارید، می توانید از TensorFlow Text استفاده کنید. TensorFlow Text مجموعهای غنی از عملیاتها و کتابخانهها را در اختیار شما قرار میدهد تا به شما کمک کند تا با ورودی به شکل متنی مانند رشتههای متن خام یا اسناد کار کنید. این کتابخانهها میتوانند پیشپردازشهای منظم مورد نیاز مدلهای مبتنی بر متن را انجام دهند و سایر ویژگیهای مفید برای مدلسازی دنبالهای را شامل شوند.
می توانید ویژگی های متنی قدرتمند نحوی و معنایی را از داخل نمودار TensorFlow به عنوان ورودی شبکه عصبی خود استخراج کنید.
ادغام پیش پردازش با نمودار TensorFlow مزایای زیر را به همراه دارد:
- یک جعبه ابزار بزرگ را برای کار با متن تسهیل می کند
- امکان ادغام با مجموعه بزرگی از ابزارهای TensorFlow برای پشتیبانی از پروژه ها از طریق تعریف مشکل از طریق آموزش، ارزیابی و راه اندازی
- پیچیدگی زمان سرو را کاهش می دهد و از انحراف در سرویس آموزشی جلوگیری می کند
علاوه بر موارد فوق، لازم نیست نگران متفاوت بودن توکن سازی در آموزش با توکن سازی در استنتاج یا مدیریت اسکریپت های پیش پردازش باشید.