TensorFlow के लिए टेक्स्ट प्रोसेसिंग टूल
TensorFlow टेक्स्ट और नेचुरल लैंग्वेज प्रोसेसिंग के लिए दो लाइब्रेरी प्रदान करता है: KerasNLP और TensorFlow टेक्स्ट। KerasNLP एक उच्च-स्तरीय प्राकृतिक भाषा प्रसंस्करण (NLP) लाइब्रेरी है जिसमें आधुनिक ट्रांसफ़ॉर्मर-आधारित मॉडल और साथ ही निम्न-स्तरीय टोकन उपयोगिताएँ शामिल हैं। अधिकांश एनएलपी उपयोग मामलों के लिए यह अनुशंसित समाधान है। TensorFlow टेक्स्ट पर निर्मित, KerasNLP उपयोग में आसानी के लिए डिज़ाइन किए गए API में निम्न-स्तरीय टेक्स्ट प्रोसेसिंग ऑपरेशंस को सार करता है। लेकिन अगर आप केरस एपीआई के साथ काम नहीं करना पसंद करते हैं, या आपको निचले स्तर के टेक्स्ट प्रोसेसिंग ऑप्स तक पहुंच की आवश्यकता है, तो आप सीधे TensorFlow टेक्स्ट का उपयोग कर सकते हैं।
केरसएनएलपी
import keras_nlp
import tensorflow_datasets as tfds
imdb_train, imdb_test = tfds.load(
"imdb_reviews",
split=["train", "test"],
as_supervised=True,
batch_size=16,
)
# Load a BERT model.
classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased")
# Fine-tune on IMDb movie reviews.
classifier.fit(imdb_train, validation_data=imdb_test)
# Predict two new examples.
classifier.predict(["What an amazing movie!", "A total waste of my time."])
GitHub पर क्विकस्टार्ट देखें।
TensorFlow में टेक्स्ट प्रोसेसिंग शुरू करने का सबसे आसान तरीका KerasNLP का उपयोग करना है। KerasNLP एक नेचुरल लैंग्वेज प्रोसेसिंग लाइब्रेरी है जो अत्याधुनिक प्रीसेट वेट और आर्किटेक्चर वाले मॉड्यूलर घटकों से निर्मित वर्कफ़्लोज़ का समर्थन करती है। आप KerasNLP घटकों का उपयोग उनके आउट-ऑफ़-द-बॉक्स कॉन्फ़िगरेशन के साथ कर सकते हैं। यदि आपको अधिक नियंत्रण की आवश्यकता है, तो आप घटकों को आसानी से अनुकूलित कर सकते हैं। KerasNLP सभी वर्कफ़्लोज़ के लिए इन-ग्राफ़ गणना पर ज़ोर देता है ताकि आप TensorFlow पारिस्थितिकी तंत्र का उपयोग करके आसान उत्पादन की उम्मीद कर सकें।
KerasNLP कोर Keras API का एक विस्तार है, और सभी उच्च-स्तरीय KerasNLP मॉड्यूल परतें या मॉडल हैं। यदि आप केरस से परिचित हैं, तो आप पहले से ही अधिकांश केरसएनएलपी को समझते हैं।
अधिक जानने के लिए, केरसएनएलपी देखें।
टेंसरफ्लो टेक्स्ट
import tensorflow as tf
import tensorflow_text as tf_text
def preprocess(vocab_lookup_table, example_text):
# Normalize text
tf_text.normalize_utf8(example_text)
# Tokenize into words
word_tokenizer = tf_text.WhitespaceTokenizer()
tokens = word_tokenizer.tokenize(example_text)
# Tokenize into subwords
subword_tokenizer = tf_text.WordpieceTokenizer(
vocab_lookup_table, token_out_type=tf.int64)
subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1)
# Apply padding
padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16)
return padded_inputs
नोटबुक में चलाएं7
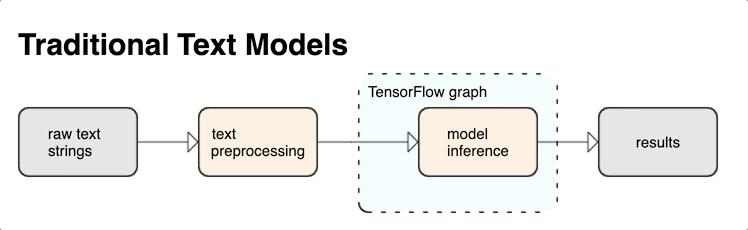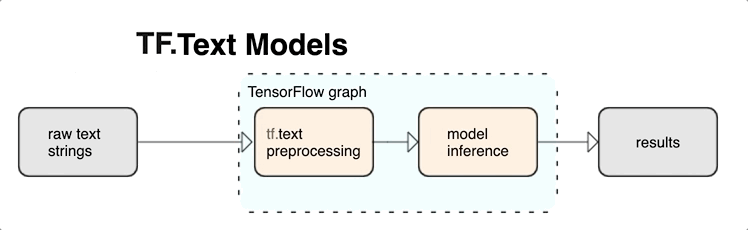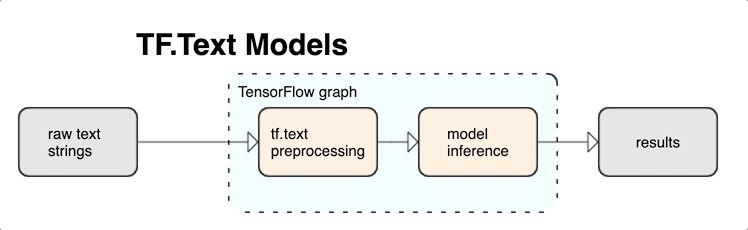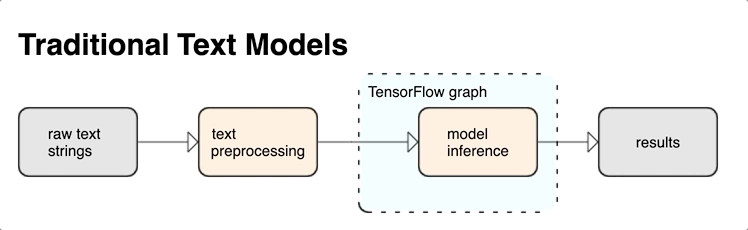
KerasNLP उच्च-स्तरीय टेक्स्ट प्रोसेसिंग मॉड्यूल प्रदान करता है जो परतों या मॉडल के रूप में उपलब्ध हैं। यदि आपको निचले स्तर के टूल तक पहुंच की आवश्यकता है, तो आप TensorFlow Text का उपयोग कर सकते हैं। TensorFlow Text आपको कच्चे टेक्स्ट स्ट्रिंग्स या दस्तावेज़ों जैसे टेक्स्ट फॉर्म में इनपुट के साथ काम करने में मदद करने के लिए ऑप्स और लाइब्रेरीज़ का एक समृद्ध संग्रह प्रदान करता है। ये पुस्तकालय टेक्स्ट-आधारित मॉडलों द्वारा नियमित रूप से आवश्यक प्रीप्रोसेसिंग कर सकते हैं, और अनुक्रम मॉडलिंग के लिए उपयोगी अन्य सुविधाओं को शामिल कर सकते हैं।
आप अपने तंत्रिका जाल के इनपुट के रूप में TensorFlow ग्राफ के अंदर से शक्तिशाली सिंटैक्टिक और सिमेंटिक टेक्स्ट फीचर निकाल सकते हैं।
TensorFlow ग्राफ़ के साथ प्रीप्रोसेसिंग को एकीकृत करने से निम्नलिखित लाभ मिलते हैं:
- टेक्स्ट के साथ काम करने के लिए एक बड़ी टूलकिट की सुविधा प्रदान करता है
- प्रशिक्षण, मूल्यांकन और लॉन्च के माध्यम से समस्या की परिभाषा से परियोजनाओं का समर्थन करने के लिए TensorFlow टूल के एक बड़े सूट के साथ एकीकरण की अनुमति देता है
- सेवारत समय पर जटिलता कम कर देता है और प्रशिक्षण-सेवा तिरछा रोकता है
उपरोक्त के अलावा, आपको प्रशिक्षण में टोकननाइज़ेशन के बारे में चिंता करने की आवश्यकता नहीं है, जो अनुमान पर टोकननाइज़ेशन से अलग है, या प्रीप्रोसेसिंग स्क्रिप्ट्स का प्रबंधन करता है।