Text processing tools for TensorFlow
TensorFlow provides two libraries for text and natural language processing: KerasNLP and TensorFlow Text. KerasNLP is a high-level natural language processing (NLP) library that includes modern transformer-based models as well as lower-level tokenization utilities. It's the recommended solution for most NLP use cases. Built on TensorFlow Text, KerasNLP abstracts low-level text processing operations into an API that's designed for ease of use. But if you prefer not to work with the Keras API, or you need access to the lower-level text processing ops, you can use TensorFlow Text directly.
KerasNLP
import keras_nlp import tensorflow_datasets as tfds imdb_train, imdb_test = tfds.load( "imdb_reviews", split=["train", "test"], as_supervised=True, batch_size=16, ) # Load a BERT model. classifier = keras_nlp.models.BertClassifier.from_preset("bert_base_en_uncased") # Fine-tune on IMDb movie reviews. classifier.fit(imdb_train, validation_data=imdb_test) # Predict two new examples. classifier.predict(["What an amazing movie!", "A total waste of my time."])
The easiest way to get started processing text in TensorFlow is to use KerasNLP. KerasNLP is a natural language processing library that supports workflows built from modular components that have state-of-the-art preset weights and architectures. You can use KerasNLP components with their out-of-the-box configuration. If you need more control, you can easily customize components. KerasNLP emphasizes in-graph computation for all workflows so you can expect easy productionization using the TensorFlow ecosystem.
KerasNLP is an extension of the core Keras API, and all the high-level KerasNLP modules are Layers or Models. If you're familiar with Keras, you already understand most of KerasNLP.
To learn more, see KerasNLP.
TensorFlow Text
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_lookup_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( vocab_lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
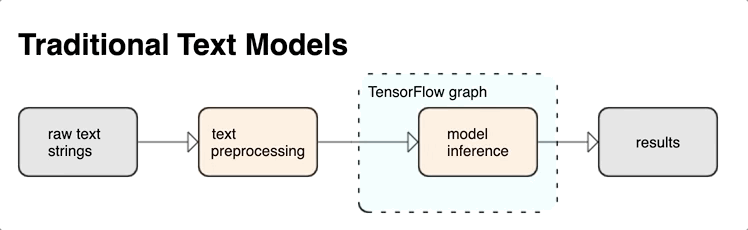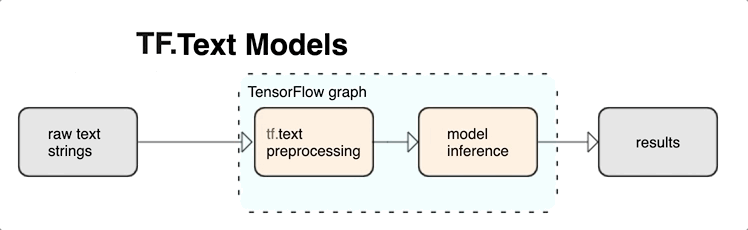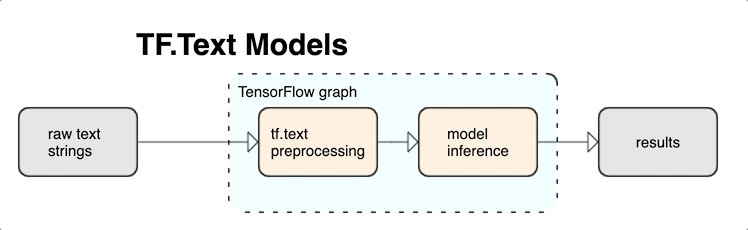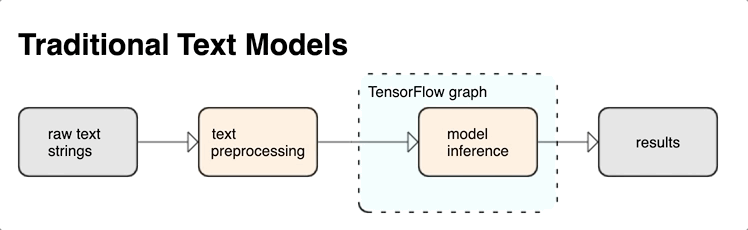
KerasNLP provides high-level text processing modules that are available as layers or models. If you need access to lower-level tools, you can use TensorFlow Text. TensorFlow Text provides you with a rich collection of ops and libraries to help you work with input in text form such as raw text strings or documents. These libraries can perform the preprocessing regularly required by text-based models, and include other features useful for sequence modeling.
You can extract powerful syntactic and semantic text features from inside the TensorFlow graph as input to your neural net.
Integrating preprocessing with the TensorFlow graph provides the following benefits:
- Facilitates a large toolkit for working with text
- Allows integration with a large suite of TensorFlow tools to support projects from problem definition through training, evaluation, and launch
- Reduces complexity at serving time and prevents training-serving skew
In addition to the above, you do not need to worry about tokenization in training being different than the tokenization at inference, or managing preprocessing scripts.