
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub |
Máy tính xách tay này huấn luyện một chuỗi đến chuỗi mô hình (seq2seq) cho Tây Ban Nha để dịch tiếng Anh dựa trên hiệu quả Phương pháp tiếp cận để ý dựa trên thần kinh Machine Translation . Đây là một ví dụ nâng cao giả định một số kiến thức về:
- Trình tự đến mô hình trình tự
- Các nguyên tắc cơ bản của TensorFlow bên dưới lớp keras:
- Làm việc trực tiếp với tensors
- Viết tùy chỉnh
keras.Models vàkeras.layers
Trong khi kiến trúc này có phần lỗi thời nó vẫn là một dự án rất hữu ích cho công việc thông qua để có được một sự hiểu biết sâu sắc hơn về cơ chế chú ý (trước khi đi vào Transformers ).
Sau khi đào tạo mô hình trong máy tính xách tay này, bạn sẽ có thể nhập vào một câu tiếng Tây Ban Nha, chẳng hạn như, và gửi lại bản dịch tiếng Anh "¿todavia estan en casa?": "Là bạn vẫn còn ở nhà"
Mô hình kết quả là xuất khẩu như một tf.saved_model , vì vậy nó có thể được sử dụng trong các môi trường TensorFlow khác.
Chất lượng bản dịch là hợp lý đối với một ví dụ về đồ chơi, nhưng cốt truyện gây chú ý được tạo ra có lẽ thú vị hơn. Điều này cho thấy phần nào của câu đầu vào được mô hình chú ý trong khi dịch:
Thành lập
pip install tensorflow_text
import numpy as np
import typing
from typing import Any, Tuple
import tensorflow as tf
import tensorflow_text as tf_text
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
Hướng dẫn này xây dựng một vài lớp từ đầu, hãy sử dụng biến này nếu bạn muốn chuyển đổi giữa triển khai tùy chỉnh và nội trang.
use_builtins = True
Hướng dẫn này sử dụng rất nhiều API cấp thấp, nơi rất dễ làm sai hình dạng. Lớp này được sử dụng để kiểm tra các hình dạng trong suốt hướng dẫn.
Kiểm tra hình dạng
class ShapeChecker():
def __init__(self):
# Keep a cache of every axis-name seen
self.shapes = {}
def __call__(self, tensor, names, broadcast=False):
if not tf.executing_eagerly():
return
if isinstance(names, str):
names = (names,)
shape = tf.shape(tensor)
rank = tf.rank(tensor)
if rank != len(names):
raise ValueError(f'Rank mismatch:\n'
f' found {rank}: {shape.numpy()}\n'
f' expected {len(names)}: {names}\n')
for i, name in enumerate(names):
if isinstance(name, int):
old_dim = name
else:
old_dim = self.shapes.get(name, None)
new_dim = shape[i]
if (broadcast and new_dim == 1):
continue
if old_dim is None:
# If the axis name is new, add its length to the cache.
self.shapes[name] = new_dim
continue
if new_dim != old_dim:
raise ValueError(f"Shape mismatch for dimension: '{name}'\n"
f" found: {new_dim}\n"
f" expected: {old_dim}\n")
Dữ liệu
Chúng tôi sẽ sử dụng một tập dữ liệu ngôn ngữ được cung cấp bởi http://www.manythings.org/anki/ bộ dữ liệu này chứa cặp dịch ngôn ngữ trong các định dạng:
May I borrow this book? ¿Puedo tomar prestado este libro?
Họ có nhiều ngôn ngữ khác nhau, nhưng chúng tôi sẽ sử dụng tập dữ liệu tiếng Anh-Tây Ban Nha.
Tải xuống và chuẩn bị tập dữ liệu
Để thuận tiện, chúng tôi đã lưu trữ bản sao của tập dữ liệu này trên Google Cloud, nhưng bạn cũng có thể tải xuống bản sao của riêng mình. Sau khi tải xuống tập dữ liệu, đây là các bước chúng tôi sẽ thực hiện để chuẩn bị dữ liệu:
- Thêm một sự khởi đầu và kết thúc thẻ cho mỗi câu.
- Làm sạch các câu bằng cách loại bỏ các ký tự đặc biệt.
- Tạo chỉ mục từ và chỉ mục từ đảo ngược (ánh xạ từ điển từ từ → id và id → từ).
- Chèn mỗi câu đến độ dài tối đa.
# Download the file
import pathlib
path_to_zip = tf.keras.utils.get_file(
'spa-eng.zip', origin='http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip',
extract=True)
path_to_file = pathlib.Path(path_to_zip).parent/'spa-eng/spa.txt'
Downloading data from http://storage.googleapis.com/download.tensorflow.org/data/spa-eng.zip 2646016/2638744 [==============================] - 0s 0us/step 2654208/2638744 [==============================] - 0s 0us/step
def load_data(path):
text = path.read_text(encoding='utf-8')
lines = text.splitlines()
pairs = [line.split('\t') for line in lines]
inp = [inp for targ, inp in pairs]
targ = [targ for targ, inp in pairs]
return targ, inp
targ, inp = load_data(path_to_file)
print(inp[-1])
Si quieres sonar como un hablante nativo, debes estar dispuesto a practicar diciendo la misma frase una y otra vez de la misma manera en que un músico de banjo practica el mismo fraseo una y otra vez hasta que lo puedan tocar correctamente y en el tiempo esperado.
print(targ[-1])
If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
Tạo tập dữ liệu tf.data
Từ những mảng của chuỗi bạn có thể tạo một tf.data.Dataset các chuỗi shuffle và lô chúng một cách hiệu quả:
BUFFER_SIZE = len(inp)
BATCH_SIZE = 64
dataset = tf.data.Dataset.from_tensor_slices((inp, targ)).shuffle(BUFFER_SIZE)
dataset = dataset.batch(BATCH_SIZE)
for example_input_batch, example_target_batch in dataset.take(1):
print(example_input_batch[:5])
print()
print(example_target_batch[:5])
break
tf.Tensor( [b'No s\xc3\xa9 lo que quiero.' b'\xc2\xbfDeber\xc3\xada repetirlo?' b'Tard\xc3\xa9 m\xc3\xa1s de 2 horas en traducir unas p\xc3\xa1ginas en ingl\xc3\xa9s.' b'A Tom comenz\xc3\xb3 a temerle a Mary.' b'Mi pasatiempo es la lectura.'], shape=(5,), dtype=string) tf.Tensor( [b"I don't know what I want." b'Should I repeat it?' b'It took me more than two hours to translate a few pages of English.' b'Tom became afraid of Mary.' b'My hobby is reading.'], shape=(5,), dtype=string)
Xử lý trước văn bản
Một trong những mục tiêu của hướng dẫn này là xây dựng một mô hình có thể được xuất ra dưới dạng một tf.saved_model . Để thực hiện mô hình xuất khẩu hữu ích nó nên tf.string đầu vào, và trở tf.string kết quả đầu ra: Tất cả quá trình xử lý văn bản xảy ra bên trong mô hình.
Tiêu chuẩn hóa
Mô hình đang xử lý văn bản đa ngôn ngữ với vốn từ vựng hạn chế. Vì vậy, việc chuẩn hóa văn bản đầu vào sẽ rất quan trọng.
Bước đầu tiên là chuẩn hóa Unicode để tách các ký tự có dấu và thay thế các ký tự tương thích bằng các ký tự tương đương ASCII của chúng.
Các tensorflow_text gói chứa một hoạt động bình thường hóa unicode:
example_text = tf.constant('¿Todavía está en casa?')
print(example_text.numpy())
print(tf_text.normalize_utf8(example_text, 'NFKD').numpy())
b'\xc2\xbfTodav\xc3\xada est\xc3\xa1 en casa?' b'\xc2\xbfTodavi\xcc\x81a esta\xcc\x81 en casa?'
Chuẩn hóa Unicode sẽ là bước đầu tiên trong chức năng chuẩn hóa văn bản:
def tf_lower_and_split_punct(text):
# Split accecented characters.
text = tf_text.normalize_utf8(text, 'NFKD')
text = tf.strings.lower(text)
# Keep space, a to z, and select punctuation.
text = tf.strings.regex_replace(text, '[^ a-z.?!,¿]', '')
# Add spaces around punctuation.
text = tf.strings.regex_replace(text, '[.?!,¿]', r' \0 ')
# Strip whitespace.
text = tf.strings.strip(text)
text = tf.strings.join(['[START]', text, '[END]'], separator=' ')
return text
print(example_text.numpy().decode())
print(tf_lower_and_split_punct(example_text).numpy().decode())
¿Todavía está en casa? [START] ¿ todavia esta en casa ? [END]
Vectơ hóa văn bản
Chức năng tiêu chuẩn này sẽ được bọc trong một tf.keras.layers.TextVectorization lớp mà sẽ xử lý việc khai thác vốn từ vựng và chuyển đổi văn bản đầu vào trình tự của thẻ.
max_vocab_size = 5000
input_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
Các TextVectorization lớp và nhiều lớp tiền xử lý khác có một adapt phương pháp. Phương pháp này lần đọc một kỷ nguyên của dữ liệu huấn luyện, và các công trình rất giống Model.fix . Đây adapt phương pháp khởi tạo các lớp dựa trên dữ liệu. Ở đây nó xác định từ vựng:
input_text_processor.adapt(inp)
# Here are the first 10 words from the vocabulary:
input_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'que', 'de', 'el', 'a', 'no']
Đó là tiếng Tây Ban Nha TextVectorization lớp, bây giờ xây dựng và .adapt() tiếng Anh một:
output_text_processor = tf.keras.layers.TextVectorization(
standardize=tf_lower_and_split_punct,
max_tokens=max_vocab_size)
output_text_processor.adapt(targ)
output_text_processor.get_vocabulary()[:10]
['', '[UNK]', '[START]', '[END]', '.', 'the', 'i', 'to', 'you', 'tom']
Giờ đây, các lớp này có thể chuyển đổi một loạt chuỗi thành một loạt ID mã thông báo:
example_tokens = input_text_processor(example_input_batch)
example_tokens[:3, :10]
<tf.Tensor: shape=(3, 10), dtype=int64, numpy=
array([[ 2, 9, 17, 22, 5, 48, 4, 3, 0, 0],
[ 2, 13, 177, 1, 12, 3, 0, 0, 0, 0],
[ 2, 120, 35, 6, 290, 14, 2134, 506, 2637, 14]])>
Các get_vocabulary phương pháp có thể được sử dụng để chuyển đổi ID thẻ trở lại văn bản:
input_vocab = np.array(input_text_processor.get_vocabulary())
tokens = input_vocab[example_tokens[0].numpy()]
' '.join(tokens)
'[START] no se lo que quiero . [END] '
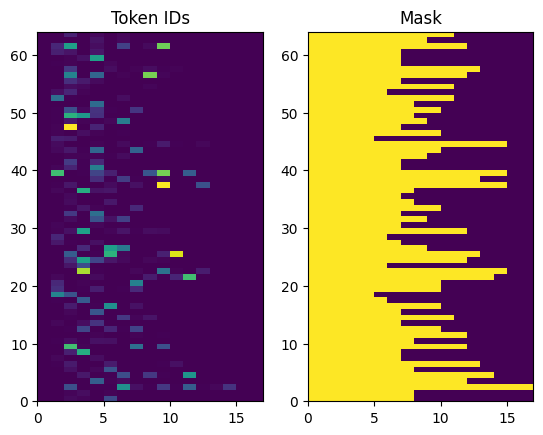
Các ID mã thông báo được trả lại không có đệm. Điều này có thể dễ dàng được biến thành một chiếc mặt nạ:
plt.subplot(1, 2, 1)
plt.pcolormesh(example_tokens)
plt.title('Token IDs')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')
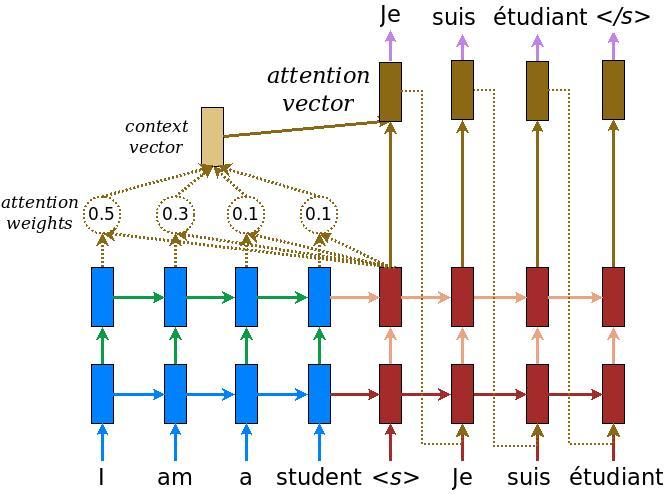
Mô hình bộ mã hóa / giải mã
Sơ đồ sau đây cho thấy tổng quan về mô hình. Tại mỗi bước thời gian, đầu ra của bộ giải mã được kết hợp với tổng trọng số trên đầu vào được mã hóa, để dự đoán từ tiếp theo. Sơ đồ và công thức là từ giấy Lương .
Trước khi đi sâu vào nó, hãy xác định một vài hằng số cho mô hình:
embedding_dim = 256
units = 1024
Bộ mã hóa
Bắt đầu bằng cách xây dựng bộ mã hóa, phần màu xanh lam của sơ đồ ở trên.
Bộ mã hóa:
- Mất một danh sách các ID token (từ
input_text_processor). - Vẻ lên một vector nhúng cho mỗi token (Sử dụng một
layers.Embedding). - Xử lý embeddings thành một chuỗi mới (Sử dụng một
layers.GRU). - Lợi nhuận:
- Trình tự đã xử lý. Điều này sẽ được chuyển đến đầu chú ý.
- Trạng thái bên trong. Điều này sẽ được sử dụng để khởi tạo bộ giải mã
class Encoder(tf.keras.layers.Layer):
def __init__(self, input_vocab_size, embedding_dim, enc_units):
super(Encoder, self).__init__()
self.enc_units = enc_units
self.input_vocab_size = input_vocab_size
# The embedding layer converts tokens to vectors
self.embedding = tf.keras.layers.Embedding(self.input_vocab_size,
embedding_dim)
# The GRU RNN layer processes those vectors sequentially.
self.gru = tf.keras.layers.GRU(self.enc_units,
# Return the sequence and state
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
def call(self, tokens, state=None):
shape_checker = ShapeChecker()
shape_checker(tokens, ('batch', 's'))
# 2. The embedding layer looks up the embedding for each token.
vectors = self.embedding(tokens)
shape_checker(vectors, ('batch', 's', 'embed_dim'))
# 3. The GRU processes the embedding sequence.
# output shape: (batch, s, enc_units)
# state shape: (batch, enc_units)
output, state = self.gru(vectors, initial_state=state)
shape_checker(output, ('batch', 's', 'enc_units'))
shape_checker(state, ('batch', 'enc_units'))
# 4. Returns the new sequence and its state.
return output, state
Đây là cách nó phù hợp với nhau cho đến nay:
# Convert the input text to tokens.
example_tokens = input_text_processor(example_input_batch)
# Encode the input sequence.
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
example_enc_output, example_enc_state = encoder(example_tokens)
print(f'Input batch, shape (batch): {example_input_batch.shape}')
print(f'Input batch tokens, shape (batch, s): {example_tokens.shape}')
print(f'Encoder output, shape (batch, s, units): {example_enc_output.shape}')
print(f'Encoder state, shape (batch, units): {example_enc_state.shape}')
Input batch, shape (batch): (64,) Input batch tokens, shape (batch, s): (64, 14) Encoder output, shape (batch, s, units): (64, 14, 1024) Encoder state, shape (batch, units): (64, 1024)
Bộ mã hóa trả về trạng thái bên trong của nó để trạng thái của nó có thể được sử dụng để khởi tạo bộ giải mã.
RNN cũng thường trả về trạng thái của nó để nó có thể xử lý một chuỗi qua nhiều cuộc gọi. Bạn sẽ thấy nhiều hơn về việc xây dựng bộ giải mã.
Đầu chú ý
Bộ giải mã sử dụng sự chú ý để tập trung có chọn lọc vào các phần của chuỗi đầu vào. Sự chú ý lấy một chuỗi các vectơ làm đầu vào cho mỗi ví dụ và trả về một vectơ "chú ý" cho mỗi ví dụ. Lớp chú ý này cũng tương tự như một layers.GlobalAveragePoling1D nhưng lớp chú ý thực hiện một bình quân gia quyền.
Hãy xem cách này hoạt động như thế nào:


Ở đâu:
- \(s\) là chỉ số encoder.
- \(t\) là chỉ số bộ giải mã.
- \(\alpha_{ts}\) là trọng tâm.
- \(h_s\) là trình tự của các kết quả đầu ra bộ mã hóa được tham dự đến (sự chú ý "chìa khóa" và "giá trị" trong thuật ngữ biến áp).
- \(h_t\) là trạng thái các bộ giải mã tham dự vào chuỗi (sự chú ý "truy vấn" trong thuật ngữ biến áp).
- \(c_t\) là kết quả vector ngữ cảnh.
- \(a_t\) là đầu ra cuối cùng kết hợp "hoàn cảnh" và "truy vấn".
Các phương trình:
- Tính trọng sự chú ý, \(\alpha_{ts}\), như một softmax qua chuỗi đầu ra của encoder.
- Tính toán vectơ ngữ cảnh dưới dạng tổng trọng số của các đầu ra bộ mã hóa.
Cuối cùng là \(score\) chức năng. Công việc của nó là tính toán điểm logit vô hướng cho mỗi cặp khóa-truy vấn. Có hai cách tiếp cận phổ biến:
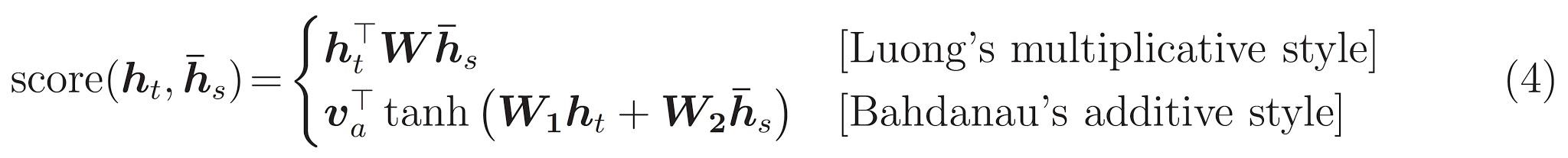
Hướng dẫn này sử dụng sự chú ý của phụ Bahdanau của . TensorFlow bao gồm việc triển khai của cả hai như layers.Attention và layers.AdditiveAttention . Lớp bên dưới xử lý các ma trận trọng lượng trong một cặp layers.Dense lớp, và kêu gọi thực hiện dựng sẵn.
class BahdanauAttention(tf.keras.layers.Layer):
def __init__(self, units):
super().__init__()
# For Eqn. (4), the Bahdanau attention
self.W1 = tf.keras.layers.Dense(units, use_bias=False)
self.W2 = tf.keras.layers.Dense(units, use_bias=False)
self.attention = tf.keras.layers.AdditiveAttention()
def call(self, query, value, mask):
shape_checker = ShapeChecker()
shape_checker(query, ('batch', 't', 'query_units'))
shape_checker(value, ('batch', 's', 'value_units'))
shape_checker(mask, ('batch', 's'))
# From Eqn. (4), `W1@ht`.
w1_query = self.W1(query)
shape_checker(w1_query, ('batch', 't', 'attn_units'))
# From Eqn. (4), `W2@hs`.
w2_key = self.W2(value)
shape_checker(w2_key, ('batch', 's', 'attn_units'))
query_mask = tf.ones(tf.shape(query)[:-1], dtype=bool)
value_mask = mask
context_vector, attention_weights = self.attention(
inputs = [w1_query, value, w2_key],
mask=[query_mask, value_mask],
return_attention_scores = True,
)
shape_checker(context_vector, ('batch', 't', 'value_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
return context_vector, attention_weights
Kiểm tra lớp Chú ý
Tạo một BahdanauAttention lớp:
attention_layer = BahdanauAttention(units)
Lớp này có 3 đầu vào:
- Các
query: Điều này sẽ được tạo ra bởi các bộ giải mã, sau đó. - Các
value: Đây sẽ là đầu ra của encoder. - Các
mask: Để loại trừ đệm,example_tokens != 0
(example_tokens != 0).shape
TensorShape([64, 14])
Việc triển khai vectơ hóa của lớp chú ý cho phép bạn chuyển một loạt chuỗi các vectơ truy vấn và một loạt chuỗi các vectơ giá trị. Kết quả là:
- Một loạt chuỗi các vectơ kết quả có kích thước bằng kích thước của các truy vấn.
- Một chú ý hàng loạt bản đồ, với kích thước
(query_length, value_length).
# Later, the decoder will generate this attention query
example_attention_query = tf.random.normal(shape=[len(example_tokens), 2, 10])
# Attend to the encoded tokens
context_vector, attention_weights = attention_layer(
query=example_attention_query,
value=example_enc_output,
mask=(example_tokens != 0))
print(f'Attention result shape: (batch_size, query_seq_length, units): {context_vector.shape}')
print(f'Attention weights shape: (batch_size, query_seq_length, value_seq_length): {attention_weights.shape}')
Attention result shape: (batch_size, query_seq_length, units): (64, 2, 1024) Attention weights shape: (batch_size, query_seq_length, value_seq_length): (64, 2, 14)
Các trọng cần lưu ý tổng hợp để 1.0 cho mỗi chuỗi.
Dưới đây là các trọng tâm trên chuỗi tại t=0 :
plt.subplot(1, 2, 1)
plt.pcolormesh(attention_weights[:, 0, :])
plt.title('Attention weights')
plt.subplot(1, 2, 2)
plt.pcolormesh(example_tokens != 0)
plt.title('Mask')
Text(0.5, 1.0, 'Mask')

Bởi vì sự khởi nhỏ ngẫu nhiên các trọng tâm là tất cả gần 1/(sequence_length) . Nếu bạn phóng to trên trọng lượng cho một chuỗi duy nhất, bạn có thể thấy rằng có một số sự thay đổi nhỏ rằng mô hình có thể học hỏi để mở rộng và khai thác.
attention_weights.shape
TensorShape([64, 2, 14])
attention_slice = attention_weights[0, 0].numpy()
attention_slice = attention_slice[attention_slice != 0]
plt.suptitle('Attention weights for one sequence')
plt.figure(figsize=(12, 6))
a1 = plt.subplot(1, 2, 1)
plt.bar(range(len(attention_slice)), attention_slice)
# freeze the xlim
plt.xlim(plt.xlim())
plt.xlabel('Attention weights')
a2 = plt.subplot(1, 2, 2)
plt.bar(range(len(attention_slice)), attention_slice)
plt.xlabel('Attention weights, zoomed')
# zoom in
top = max(a1.get_ylim())
zoom = 0.85*top
a2.set_ylim([0.90*top, top])
a1.plot(a1.get_xlim(), [zoom, zoom], color='k')
[<matplotlib.lines.Line2D at 0x7fb42c5b1090>] <Figure size 432x288 with 0 Axes>

Người giải mã
Công việc của bộ giải mã là tạo ra các dự đoán cho mã thông báo đầu ra tiếp theo.
- Bộ giải mã nhận được đầu ra bộ mã hóa hoàn chỉnh.
- Nó sử dụng RNN để theo dõi những gì nó đã tạo ra cho đến nay.
- Nó sử dụng đầu ra RNN của nó làm truy vấn để thu hút sự chú ý qua đầu ra của bộ mã hóa, tạo ra vectơ ngữ cảnh.
- Nó kết hợp đầu ra RNN và vectơ ngữ cảnh bằng cách sử dụng Công thức 3 (bên dưới) để tạo ra "vectơ chú ý".
- Nó tạo ra các dự đoán logit cho mã thông báo tiếp theo dựa trên "vectơ chú ý".

Đây là Decoder lớp và khởi tạo của nó. Trình khởi tạo tạo tất cả các lớp cần thiết.
class Decoder(tf.keras.layers.Layer):
def __init__(self, output_vocab_size, embedding_dim, dec_units):
super(Decoder, self).__init__()
self.dec_units = dec_units
self.output_vocab_size = output_vocab_size
self.embedding_dim = embedding_dim
# For Step 1. The embedding layer convets token IDs to vectors
self.embedding = tf.keras.layers.Embedding(self.output_vocab_size,
embedding_dim)
# For Step 2. The RNN keeps track of what's been generated so far.
self.gru = tf.keras.layers.GRU(self.dec_units,
return_sequences=True,
return_state=True,
recurrent_initializer='glorot_uniform')
# For step 3. The RNN output will be the query for the attention layer.
self.attention = BahdanauAttention(self.dec_units)
# For step 4. Eqn. (3): converting `ct` to `at`
self.Wc = tf.keras.layers.Dense(dec_units, activation=tf.math.tanh,
use_bias=False)
# For step 5. This fully connected layer produces the logits for each
# output token.
self.fc = tf.keras.layers.Dense(self.output_vocab_size)
Các call phương pháp cho lớp này mất và trả về nhiều tensors. Tổ chức chúng thành các lớp vùng chứa đơn giản:
class DecoderInput(typing.NamedTuple):
new_tokens: Any
enc_output: Any
mask: Any
class DecoderOutput(typing.NamedTuple):
logits: Any
attention_weights: Any
Đây là việc thực hiện các call phương pháp:
def call(self,
inputs: DecoderInput,
state=None) -> Tuple[DecoderOutput, tf.Tensor]:
shape_checker = ShapeChecker()
shape_checker(inputs.new_tokens, ('batch', 't'))
shape_checker(inputs.enc_output, ('batch', 's', 'enc_units'))
shape_checker(inputs.mask, ('batch', 's'))
if state is not None:
shape_checker(state, ('batch', 'dec_units'))
# Step 1. Lookup the embeddings
vectors = self.embedding(inputs.new_tokens)
shape_checker(vectors, ('batch', 't', 'embedding_dim'))
# Step 2. Process one step with the RNN
rnn_output, state = self.gru(vectors, initial_state=state)
shape_checker(rnn_output, ('batch', 't', 'dec_units'))
shape_checker(state, ('batch', 'dec_units'))
# Step 3. Use the RNN output as the query for the attention over the
# encoder output.
context_vector, attention_weights = self.attention(
query=rnn_output, value=inputs.enc_output, mask=inputs.mask)
shape_checker(context_vector, ('batch', 't', 'dec_units'))
shape_checker(attention_weights, ('batch', 't', 's'))
# Step 4. Eqn. (3): Join the context_vector and rnn_output
# [ct; ht] shape: (batch t, value_units + query_units)
context_and_rnn_output = tf.concat([context_vector, rnn_output], axis=-1)
# Step 4. Eqn. (3): `at = tanh(Wc@[ct; ht])`
attention_vector = self.Wc(context_and_rnn_output)
shape_checker(attention_vector, ('batch', 't', 'dec_units'))
# Step 5. Generate logit predictions:
logits = self.fc(attention_vector)
shape_checker(logits, ('batch', 't', 'output_vocab_size'))
return DecoderOutput(logits, attention_weights), state
Decoder.call = call
Các bộ mã hóa xử lý chuỗi đầu vào đầy đủ của nó với một cuộc gọi duy nhất để RNN của nó. Điều này thực hiện của các bộ giải mã có thể làm điều đó cũng cho hiệu quả đào tạo. Nhưng hướng dẫn này sẽ chạy bộ giải mã trong một vòng lặp vì một số lý do:
- Tính linh hoạt: Viết vòng lặp cho phép bạn kiểm soát trực tiếp quy trình đào tạo.
- Độ tinh khiết: Có thể làm mặt nạ thủ thuật và sử dụng
layers.RNN, hoặctfa.seq2seqAPI để đóng gói tất cả điều này thành một cuộc gọi duy nhất. Nhưng viết nó ra như một vòng lặp có thể rõ ràng hơn.- Vòng đào tạo miễn phí được thể hiện trong hệ chữ tutiorial.
Bây giờ hãy thử sử dụng bộ giải mã này.
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
Bộ giải mã có 4 đầu vào.
-
new_tokens- Các dấu hiệu cuối cùng được tạo. Khởi tạo các bộ giải mã với"[START]"token. -
enc_output- được tạo ra bởiEncoder. -
mask- Một tensor boolean chỉ ra nơitokens != 0 -
state- Các trướcstateđầu ra từ các bộ giải mã (trạng thái nội bộ của RNN của bộ giải mã). Vượt quaNoneđể zero-khởi tạo nó. Giấy gốc khởi tạo nó từ trạng thái RNN cuối cùng của bộ mã hóa.
# Convert the target sequence, and collect the "[START]" tokens
example_output_tokens = output_text_processor(example_target_batch)
start_index = output_text_processor.get_vocabulary().index('[START]')
first_token = tf.constant([[start_index]] * example_output_tokens.shape[0])
# Run the decoder
dec_result, dec_state = decoder(
inputs = DecoderInput(new_tokens=first_token,
enc_output=example_enc_output,
mask=(example_tokens != 0)),
state = example_enc_state
)
print(f'logits shape: (batch_size, t, output_vocab_size) {dec_result.logits.shape}')
print(f'state shape: (batch_size, dec_units) {dec_state.shape}')
logits shape: (batch_size, t, output_vocab_size) (64, 1, 5000) state shape: (batch_size, dec_units) (64, 1024)
Lấy mẫu mã thông báo theo nhật ký:
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
Giải mã mã thông báo dưới dạng từ đầu tiên của đầu ra:
vocab = np.array(output_text_processor.get_vocabulary())
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['already'],
['plants'],
['pretended'],
['convince'],
['square']], dtype='<U16')
Bây giờ, hãy sử dụng bộ giải mã để tạo bộ log thứ hai.
- Vượt qua cùng
enc_outputvàmask, những điều này đã không thay đổi. - Vượt qua mẫu mã thông báo như
new_tokens. - Vượt qua
decoder_statebộ giải mã trở lại lần cuối cùng, vì vậy RNN tiếp tục với một ký ức về nơi nó rời đi thời gian qua.
dec_result, dec_state = decoder(
DecoderInput(sampled_token,
example_enc_output,
mask=(example_tokens != 0)),
state=dec_state)
sampled_token = tf.random.categorical(dec_result.logits[:, 0, :], num_samples=1)
first_word = vocab[sampled_token.numpy()]
first_word[:5]
array([['nap'],
['mean'],
['worker'],
['passage'],
['baked']], dtype='<U16')
Tập huấn
Bây giờ bạn đã có tất cả các thành phần của mô hình, đã đến lúc bắt đầu đào tạo mô hình. Có thể bạn sẽ cần:
- Một chức năng mất mát và trình tối ưu hóa để thực hiện việc tối ưu hóa.
- Chức năng bước đào tạo xác định cách cập nhật mô hình cho từng lô đầu vào / mục tiêu.
- Một vòng lặp đào tạo để thúc đẩy quá trình đào tạo và lưu các điểm kiểm tra.
Xác định hàm mất mát
class MaskedLoss(tf.keras.losses.Loss):
def __init__(self):
self.name = 'masked_loss'
self.loss = tf.keras.losses.SparseCategoricalCrossentropy(
from_logits=True, reduction='none')
def __call__(self, y_true, y_pred):
shape_checker = ShapeChecker()
shape_checker(y_true, ('batch', 't'))
shape_checker(y_pred, ('batch', 't', 'logits'))
# Calculate the loss for each item in the batch.
loss = self.loss(y_true, y_pred)
shape_checker(loss, ('batch', 't'))
# Mask off the losses on padding.
mask = tf.cast(y_true != 0, tf.float32)
shape_checker(mask, ('batch', 't'))
loss *= mask
# Return the total.
return tf.reduce_sum(loss)
Thực hiện bước đào tạo
Bắt đầu với một lớp mô hình, quá trình đào tạo sẽ được triển khai như train_step phương pháp trên mô hình này. Xem Tuỳ chỉnh phù hợp để biết chi tiết.
Ở đây train_step phương pháp là một wrapper quanh _train_step thực hiện mà sẽ đến sau. Wrapper này bao gồm một công tắc để bật và tắt tf.function biên soạn, để làm cho gỡ lỗi dễ dàng hơn.
class TrainTranslator(tf.keras.Model):
def __init__(self, embedding_dim, units,
input_text_processor,
output_text_processor,
use_tf_function=True):
super().__init__()
# Build the encoder and decoder
encoder = Encoder(input_text_processor.vocabulary_size(),
embedding_dim, units)
decoder = Decoder(output_text_processor.vocabulary_size(),
embedding_dim, units)
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.use_tf_function = use_tf_function
self.shape_checker = ShapeChecker()
def train_step(self, inputs):
self.shape_checker = ShapeChecker()
if self.use_tf_function:
return self._tf_train_step(inputs)
else:
return self._train_step(inputs)
Nhìn chung việc thực hiện cho Model.train_step phương pháp là như sau:
- Nhận một loạt
input_text, target_texttừtf.data.Dataset. - Chuyển đổi các đầu vào văn bản thô đó thành nhúng mã thông báo và mặt nạ.
- Chạy bộ mã hóa trên
input_tokensđể có được nhữngencoder_outputvàencoder_state. - Khởi tạo trạng thái bộ giải mã và mất mát.
- Vòng qua
target_tokens:- Chạy bộ giải mã từng bước một.
- Tính toán sự mất mát cho mỗi bước.
- Tích lũy lỗ trung bình.
- Tính gradient của sự mất mát và sử dụng tối ưu hóa để áp dụng bản cập nhật trên của mô hình
trainable_variables.
Các _preprocess phương pháp, bổ sung dưới đây, dụng cụ bước # 1 và # 2:
def _preprocess(self, input_text, target_text):
self.shape_checker(input_text, ('batch',))
self.shape_checker(target_text, ('batch',))
# Convert the text to token IDs
input_tokens = self.input_text_processor(input_text)
target_tokens = self.output_text_processor(target_text)
self.shape_checker(input_tokens, ('batch', 's'))
self.shape_checker(target_tokens, ('batch', 't'))
# Convert IDs to masks.
input_mask = input_tokens != 0
self.shape_checker(input_mask, ('batch', 's'))
target_mask = target_tokens != 0
self.shape_checker(target_mask, ('batch', 't'))
return input_tokens, input_mask, target_tokens, target_mask
TrainTranslator._preprocess = _preprocess
Các _train_step phương pháp, thêm vào bên dưới, xử lý các bước còn lại trừ thực sự chạy bộ giải mã:
def _train_step(self, inputs):
input_text, target_text = inputs
(input_tokens, input_mask,
target_tokens, target_mask) = self._preprocess(input_text, target_text)
max_target_length = tf.shape(target_tokens)[1]
with tf.GradientTape() as tape:
# Encode the input
enc_output, enc_state = self.encoder(input_tokens)
self.shape_checker(enc_output, ('batch', 's', 'enc_units'))
self.shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder's state to the encoder's final state.
# This only works if the encoder and decoder have the same number of
# units.
dec_state = enc_state
loss = tf.constant(0.0)
for t in tf.range(max_target_length-1):
# Pass in two tokens from the target sequence:
# 1. The current input to the decoder.
# 2. The target for the decoder's next prediction.
new_tokens = target_tokens[:, t:t+2]
step_loss, dec_state = self._loop_step(new_tokens, input_mask,
enc_output, dec_state)
loss = loss + step_loss
# Average the loss over all non padding tokens.
average_loss = loss / tf.reduce_sum(tf.cast(target_mask, tf.float32))
# Apply an optimization step
variables = self.trainable_variables
gradients = tape.gradient(average_loss, variables)
self.optimizer.apply_gradients(zip(gradients, variables))
# Return a dict mapping metric names to current value
return {'batch_loss': average_loss}
TrainTranslator._train_step = _train_step
Các _loop_step phương pháp, bổ sung dưới đây, thực hiện các bộ giải mã và tính toán sự mất mát gia tăng và tình trạng giải mã mới ( dec_state ).
def _loop_step(self, new_tokens, input_mask, enc_output, dec_state):
input_token, target_token = new_tokens[:, 0:1], new_tokens[:, 1:2]
# Run the decoder one step.
decoder_input = DecoderInput(new_tokens=input_token,
enc_output=enc_output,
mask=input_mask)
dec_result, dec_state = self.decoder(decoder_input, state=dec_state)
self.shape_checker(dec_result.logits, ('batch', 't1', 'logits'))
self.shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
self.shape_checker(dec_state, ('batch', 'dec_units'))
# `self.loss` returns the total for non-padded tokens
y = target_token
y_pred = dec_result.logits
step_loss = self.loss(y, y_pred)
return step_loss, dec_state
TrainTranslator._loop_step = _loop_step
Kiểm tra bước đào tạo
Xây dựng một TrainTranslator , và cấu hình nó cho đào tạo bằng cách sử dụng Model.compile phương pháp:
translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
use_tf_function=False)
# Configure the loss and optimizer
translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
Kiểm tra các train_step . Đối với một mô hình văn bản như thế này, sự mất mát sẽ bắt đầu gần:
np.log(output_text_processor.vocabulary_size())
8.517193191416236
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.5849695>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.55271>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.4929113>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=7.3296022>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=6.80437>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.000246>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=5.8740363>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.794589>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.3175836>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.108163>}
CPU times: user 5.49 s, sys: 0 ns, total: 5.49 s
Wall time: 5.45 s
Trong khi nó dễ dàng hơn để gỡ lỗi mà không có một tf.function nó cung cấp cho một tăng hiệu suất. Vì vậy, bây giờ mà các _train_step phương pháp đang làm việc, hãy thử các tf.function -wrapped _tf_train_step , để tối đa hóa hiệu suất trong khi đào tạo:
@tf.function(input_signature=[[tf.TensorSpec(dtype=tf.string, shape=[None]),
tf.TensorSpec(dtype=tf.string, shape=[None])]])
def _tf_train_step(self, inputs):
return self._train_step(inputs)
TrainTranslator._tf_train_step = _tf_train_step
translator.use_tf_function = True
Cuộc gọi đầu tiên sẽ chậm, vì nó theo dõi chức năng.
translator.train_step([example_input_batch, example_target_batch])
2021-12-04 12:09:48.074769: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.180156: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:09:48.285846: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:09:48.307794: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/PartitionedCall was passed variant from gradient_tape/while/while_grad/body/_531/gradient_tape/while/gradients/while/decoder_1/gru_3/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:09:48.425447: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node while/body/_1/while/TensorListPushBack_56 was passed float from while/body/_1/while/decoder_1/gru_3/PartitionedCall:6 incompatible with expected variant.
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.045638>}
Nhưng sau đó nó thường là 2-3x nhanh hơn so với háo hức train_step phương pháp:
%%time
for n in range(10):
print(translator.train_step([example_input_batch, example_target_batch]))
print()
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.1098256>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.169871>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.139249>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=4.0410743>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.9664454>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.895707>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.8154407>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.7583396>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.6986444>}
{'batch_loss': <tf.Tensor: shape=(), dtype=float32, numpy=3.640298>}
CPU times: user 4.4 s, sys: 960 ms, total: 5.36 s
Wall time: 1.67 s
Một thử nghiệm tốt đối với một mô hình mới là để thấy rằng nó có thể quá phù hợp với một lô đầu vào duy nhất. Hãy thử nó, khoản lỗ sẽ nhanh chóng về 0:
losses = []
for n in range(100):
print('.', end='')
logs = translator.train_step([example_input_batch, example_target_batch])
losses.append(logs['batch_loss'].numpy())
print()
plt.plot(losses)
.................................................................................................... [<matplotlib.lines.Line2D at 0x7fb427edf210>]

Bây giờ bạn đã tự tin rằng bước đào tạo đang hoạt động, hãy tạo một bản sao mới của mô hình để đào tạo từ đầu:
train_translator = TrainTranslator(
embedding_dim, units,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor)
# Configure the loss and optimizer
train_translator.compile(
optimizer=tf.optimizers.Adam(),
loss=MaskedLoss(),
)
Đào tạo mô hình
Trong khi không có gì sai trái với văn bản lặp đào tạo tùy chỉnh riêng của bạn, thực hiện Model.train_step phương pháp, như trong phần trước, cho phép bạn chạy Model.fit và tránh viết lại tất cả những mã nồi hơi-tấm.
Hướng dẫn này chỉ xe lửa cho một vài kỷ nguyên, vì vậy sử dụng một callbacks.Callback để thu thập lịch sử của lỗ hàng loạt, vì âm mưu:
class BatchLogs(tf.keras.callbacks.Callback):
def __init__(self, key):
self.key = key
self.logs = []
def on_train_batch_end(self, n, logs):
self.logs.append(logs[self.key])
batch_loss = BatchLogs('batch_loss')
train_translator.fit(dataset, epochs=3,
callbacks=[batch_loss])
Epoch 1/3
2021-12-04 12:10:11.617839: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:11.737105: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] layout failed: OUT_OF_RANGE: src_output = 25, but num_outputs is only 25
2021-12-04 12:10:11.855054: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] tfg_optimizer{} failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
when importing GraphDef to MLIR module in GrapplerHook
2021-12-04 12:10:11.878896: E tensorflow/core/grappler/optimizers/meta_optimizer.cc:812] function_optimizer failed: INVALID_ARGUMENT: Input 6 of node StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/PartitionedCall was passed variant from StatefulPartitionedCall/gradient_tape/while/while_grad/body/_589/gradient_tape/while/gradients/while/decoder_2/gru_5/PartitionedCall_grad/TensorListPopBack_2:1 incompatible with expected float.
2021-12-04 12:10:12.004755: W tensorflow/core/common_runtime/process_function_library_runtime.cc:866] Ignoring multi-device function optimization failure: INVALID_ARGUMENT: Input 1 of node StatefulPartitionedCall/while/body/_59/while/TensorListPushBack_56 was passed float from StatefulPartitionedCall/while/body/_59/while/decoder_2/gru_5/PartitionedCall:6 incompatible with expected variant.
1859/1859 [==============================] - 349s 185ms/step - batch_loss: 2.0443
Epoch 2/3
1859/1859 [==============================] - 350s 188ms/step - batch_loss: 1.0382
Epoch 3/3
1859/1859 [==============================] - 343s 184ms/step - batch_loss: 0.8085
<keras.callbacks.History at 0x7fb42c3eda10>
plt.plot(batch_loss.logs)
plt.ylim([0, 3])
plt.xlabel('Batch #')
plt.ylabel('CE/token')
Text(0, 0.5, 'CE/token')
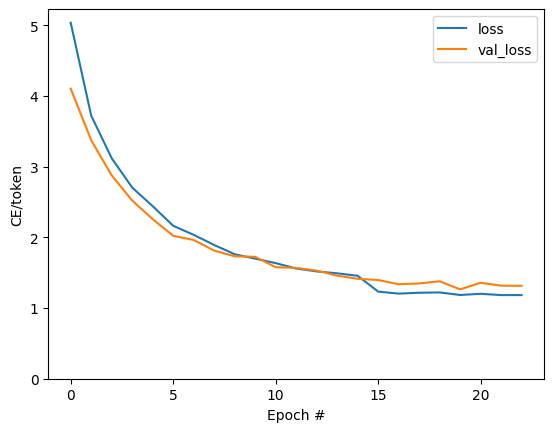
Các bước nhảy có thể nhìn thấy trong cốt truyện nằm ở ranh giới kỷ nguyên.
Phiên dịch
Bây giờ mà các mô hình được đào tạo, thực hiện một chức năng để thực hiện đầy đủ text => text dịch.
Đối với điều này nhu cầu mô hình để đảo ngược text => token IDs bản đồ được cung cấp bởi các output_text_processor . Nó cũng cần biết ID cho các mã thông báo đặc biệt. Tất cả điều này được thực hiện trong phương thức khởi tạo cho lớp mới. Việc triển khai phương pháp dịch thực tế sẽ tuân theo.
Nhìn chung, điều này tương tự như vòng lặp đào tạo, ngoại trừ đầu vào cho bộ giải mã ở mỗi bước thời gian là một mẫu từ dự đoán cuối cùng của bộ giải mã.
class Translator(tf.Module):
def __init__(self, encoder, decoder, input_text_processor,
output_text_processor):
self.encoder = encoder
self.decoder = decoder
self.input_text_processor = input_text_processor
self.output_text_processor = output_text_processor
self.output_token_string_from_index = (
tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(),
mask_token='',
invert=True))
# The output should never generate padding, unknown, or start.
index_from_string = tf.keras.layers.StringLookup(
vocabulary=output_text_processor.get_vocabulary(), mask_token='')
token_mask_ids = index_from_string(['', '[UNK]', '[START]']).numpy()
token_mask = np.zeros([index_from_string.vocabulary_size()], dtype=np.bool)
token_mask[np.array(token_mask_ids)] = True
self.token_mask = token_mask
self.start_token = index_from_string(tf.constant('[START]'))
self.end_token = index_from_string(tf.constant('[END]'))
translator = Translator(
encoder=train_translator.encoder,
decoder=train_translator.decoder,
input_text_processor=input_text_processor,
output_text_processor=output_text_processor,
)
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:21: DeprecationWarning: `np.bool` is a deprecated alias for the builtin `bool`. To silence this warning, use `bool` by itself. Doing this will not modify any behavior and is safe. If you specifically wanted the numpy scalar type, use `np.bool_` here. Deprecated in NumPy 1.20; for more details and guidance: https://numpy.org/devdocs/release/1.20.0-notes.html#deprecations
Chuyển đổi ID mã thông báo thành văn bản
Phương pháp đầu tiên để thực hiện là tokens_to_text mà cải đạo từ ID thẻ để có thể đọc được văn bản của con người.
def tokens_to_text(self, result_tokens):
shape_checker = ShapeChecker()
shape_checker(result_tokens, ('batch', 't'))
result_text_tokens = self.output_token_string_from_index(result_tokens)
shape_checker(result_text_tokens, ('batch', 't'))
result_text = tf.strings.reduce_join(result_text_tokens,
axis=1, separator=' ')
shape_checker(result_text, ('batch'))
result_text = tf.strings.strip(result_text)
shape_checker(result_text, ('batch',))
return result_text
Translator.tokens_to_text = tokens_to_text
Nhập một số ID mã thông báo ngẫu nhiên và xem những gì nó tạo ra:
example_output_tokens = tf.random.uniform(
shape=[5, 2], minval=0, dtype=tf.int64,
maxval=output_text_processor.vocabulary_size())
translator.tokens_to_text(example_output_tokens).numpy()
array([b'vain mysteries', b'funny ham', b'drivers responding',
b'mysterious ignoring', b'fashion votes'], dtype=object)
Mẫu từ dự đoán của người giải mã
Hàm này nhận đầu ra logit của trình giải mã và lấy mẫu mã thông báo ID từ bản phân phối đó:
def sample(self, logits, temperature):
shape_checker = ShapeChecker()
# 't' is usually 1 here.
shape_checker(logits, ('batch', 't', 'vocab'))
shape_checker(self.token_mask, ('vocab',))
token_mask = self.token_mask[tf.newaxis, tf.newaxis, :]
shape_checker(token_mask, ('batch', 't', 'vocab'), broadcast=True)
# Set the logits for all masked tokens to -inf, so they are never chosen.
logits = tf.where(self.token_mask, -np.inf, logits)
if temperature == 0.0:
new_tokens = tf.argmax(logits, axis=-1)
else:
logits = tf.squeeze(logits, axis=1)
new_tokens = tf.random.categorical(logits/temperature,
num_samples=1)
shape_checker(new_tokens, ('batch', 't'))
return new_tokens
Translator.sample = sample
Chạy thử chức năng này trên một số đầu vào ngẫu nhiên:
example_logits = tf.random.normal([5, 1, output_text_processor.vocabulary_size()])
example_output_tokens = translator.sample(example_logits, temperature=1.0)
example_output_tokens
<tf.Tensor: shape=(5, 1), dtype=int64, numpy=
array([[4506],
[3577],
[2961],
[4586],
[ 944]])>
Triển khai vòng lặp dịch
Đây là một triển khai hoàn chỉnh của vòng lặp dịch văn bản sang văn bản.
Điều này thực hiện thu thập các kết quả vào danh sách python, trước khi sử dụng tf.concat tham gia cùng họ vào tensors.
Điều này thực hiện tĩnh unrolls đồ thị ra max_length lặp. Điều này không sao với việc thực thi háo hức trong python.
def translate_unrolled(self,
input_text, *,
max_length=50,
return_attention=True,
temperature=1.0):
batch_size = tf.shape(input_text)[0]
input_tokens = self.input_text_processor(input_text)
enc_output, enc_state = self.encoder(input_tokens)
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
result_tokens = []
attention = []
done = tf.zeros([batch_size, 1], dtype=tf.bool)
for _ in range(max_length):
dec_input = DecoderInput(new_tokens=new_tokens,
enc_output=enc_output,
mask=(input_tokens!=0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
attention.append(dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens.append(new_tokens)
if tf.executing_eagerly() and tf.reduce_all(done):
break
# Convert the list of generates token ids to a list of strings.
result_tokens = tf.concat(result_tokens, axis=-1)
result_text = self.tokens_to_text(result_tokens)
if return_attention:
attention_stack = tf.concat(attention, axis=1)
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_unrolled
Chạy nó trên một đầu vào đơn giản:
%%time
input_text = tf.constant([
'hace mucho frio aqui.', # "It's really cold here."
'Esta es mi vida.', # "This is my life.""
])
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its a long cold here . this is my life . CPU times: user 165 ms, sys: 4.37 ms, total: 169 ms Wall time: 164 ms
Nếu bạn muốn xuất mô hình này, bạn sẽ cần phải quấn phương pháp này trong một tf.function . Việc triển khai cơ bản này có một số vấn đề nếu bạn cố gắng thực hiện điều đó:
- Các biểu đồ kết quả rất lớn và mất vài giây để tạo, lưu hoặc tải.
- Bạn không thể phá vỡ từ một vòng tĩnh unrolled, vì vậy nó sẽ luôn luôn chạy
max_lengthlặp lại, ngay cả khi tất cả các kết quả đầu ra được thực hiện. Nhưng thậm chí sau đó nó nhanh hơn một chút so với việc thực thi háo hức.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
Chạy tf.function một lần để biên dịch nó:
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 18.8 s, sys: 0 ns, total: 18.8 s Wall time: 18.7 s
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 88 ms
[Tùy chọn] Sử dụng vòng lặp tượng trưng
def translate_symbolic(self,
input_text,
*,
max_length=50,
return_attention=True,
temperature=1.0):
shape_checker = ShapeChecker()
shape_checker(input_text, ('batch',))
batch_size = tf.shape(input_text)[0]
# Encode the input
input_tokens = self.input_text_processor(input_text)
shape_checker(input_tokens, ('batch', 's'))
enc_output, enc_state = self.encoder(input_tokens)
shape_checker(enc_output, ('batch', 's', 'enc_units'))
shape_checker(enc_state, ('batch', 'enc_units'))
# Initialize the decoder
dec_state = enc_state
new_tokens = tf.fill([batch_size, 1], self.start_token)
shape_checker(new_tokens, ('batch', 't1'))
# Initialize the accumulators
result_tokens = tf.TensorArray(tf.int64, size=1, dynamic_size=True)
attention = tf.TensorArray(tf.float32, size=1, dynamic_size=True)
done = tf.zeros([batch_size, 1], dtype=tf.bool)
shape_checker(done, ('batch', 't1'))
for t in tf.range(max_length):
dec_input = DecoderInput(
new_tokens=new_tokens, enc_output=enc_output, mask=(input_tokens != 0))
dec_result, dec_state = self.decoder(dec_input, state=dec_state)
shape_checker(dec_result.attention_weights, ('batch', 't1', 's'))
attention = attention.write(t, dec_result.attention_weights)
new_tokens = self.sample(dec_result.logits, temperature)
shape_checker(dec_result.logits, ('batch', 't1', 'vocab'))
shape_checker(new_tokens, ('batch', 't1'))
# If a sequence produces an `end_token`, set it `done`
done = done | (new_tokens == self.end_token)
# Once a sequence is done it only produces 0-padding.
new_tokens = tf.where(done, tf.constant(0, dtype=tf.int64), new_tokens)
# Collect the generated tokens
result_tokens = result_tokens.write(t, new_tokens)
if tf.reduce_all(done):
break
# Convert the list of generated token ids to a list of strings.
result_tokens = result_tokens.stack()
shape_checker(result_tokens, ('t', 'batch', 't0'))
result_tokens = tf.squeeze(result_tokens, -1)
result_tokens = tf.transpose(result_tokens, [1, 0])
shape_checker(result_tokens, ('batch', 't'))
result_text = self.tokens_to_text(result_tokens)
shape_checker(result_text, ('batch',))
if return_attention:
attention_stack = attention.stack()
shape_checker(attention_stack, ('t', 'batch', 't1', 's'))
attention_stack = tf.squeeze(attention_stack, 2)
shape_checker(attention_stack, ('t', 'batch', 's'))
attention_stack = tf.transpose(attention_stack, [1, 0, 2])
shape_checker(attention_stack, ('batch', 't', 's'))
return {'text': result_text, 'attention': attention_stack}
else:
return {'text': result_text}
Translator.translate = translate_symbolic
Việc triển khai ban đầu đã sử dụng danh sách python để thu thập kết quả đầu ra. Sử dụng này tf.range như iterator vòng lặp, cho phép tf.autograph để chuyển đổi các vòng lặp. Sự thay đổi lớn nhất trong việc thực hiện này là việc sử dụng tf.TensorArray thay vì python list để tensors tích lũy. tf.TensorArray là cần thiết để thu thập một số biến của tensors trong chế độ đồ thị.
Với việc thực thi hăng hái, bản triển khai này hoạt động ngang bằng với bản gốc:
%%time
result = translator.translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 175 ms, sys: 0 ns, total: 175 ms Wall time: 170 ms
Nhưng khi bạn bọc nó trong một tf.function bạn sẽ nhận thấy hai sự khác biệt.
@tf.function(input_signature=[tf.TensorSpec(dtype=tf.string, shape=[None])])
def tf_translate(self, input_text):
return self.translate(input_text)
Translator.tf_translate = tf_translate
Đầu tiên: Biểu đồ sáng tạo là nhanh hơn nhiều (~ 10x), vì nó không tạo max_iterations bản của mô hình.
%%time
result = translator.tf_translate(
input_text = input_text)
CPU times: user 1.79 s, sys: 0 ns, total: 1.79 s Wall time: 1.77 s
Thứ hai: Hàm đã biên dịch nhanh hơn nhiều trên các đầu vào nhỏ (5 lần trong ví dụ này), vì nó có thể thoát ra khỏi vòng lặp.
%%time
result = translator.tf_translate(
input_text = input_text)
print(result['text'][0].numpy().decode())
print(result['text'][1].numpy().decode())
print()
its very cold here . this is my life . CPU times: user 40.1 ms, sys: 0 ns, total: 40.1 ms Wall time: 17.1 ms
Hình dung quá trình
Các trọng tâm được trả về bởi các translate phương pháp cho thấy nơi mô hình là "tìm kiếm" khi nó được tạo ra mỗi thẻ đầu ra.
Vì vậy, tổng sự chú ý trên đầu vào sẽ trả về tất cả những thứ:
a = result['attention'][0]
print(np.sum(a, axis=-1))
[1.0000001 0.99999994 1. 0.99999994 1. 0.99999994]
Đây là sự phân bố sự chú ý cho bước đầu ra đầu tiên của ví dụ đầu tiên. Lưu ý rằng sự chú ý bây giờ tập trung hơn nhiều so với mô hình chưa được đào tạo:
_ = plt.bar(range(len(a[0, :])), a[0, :])

Vì có một số căn chỉnh sơ bộ giữa các từ đầu vào và đầu ra, bạn mong đợi sự chú ý sẽ được tập trung gần đường chéo:
plt.imshow(np.array(a), vmin=0.0)
<matplotlib.image.AxesImage at 0x7faf2886ced0>

Dưới đây là một số mã để tạo ra một âm mưu gây chú ý tốt hơn:
Các âm mưu chú ý được gắn nhãn
def plot_attention(attention, sentence, predicted_sentence):
sentence = tf_lower_and_split_punct(sentence).numpy().decode().split()
predicted_sentence = predicted_sentence.numpy().decode().split() + ['[END]']
fig = plt.figure(figsize=(10, 10))
ax = fig.add_subplot(1, 1, 1)
attention = attention[:len(predicted_sentence), :len(sentence)]
ax.matshow(attention, cmap='viridis', vmin=0.0)
fontdict = {'fontsize': 14}
ax.set_xticklabels([''] + sentence, fontdict=fontdict, rotation=90)
ax.set_yticklabels([''] + predicted_sentence, fontdict=fontdict)
ax.xaxis.set_major_locator(ticker.MultipleLocator(1))
ax.yaxis.set_major_locator(ticker.MultipleLocator(1))
ax.set_xlabel('Input text')
ax.set_ylabel('Output text')
plt.suptitle('Attention weights')
i=0
plot_attention(result['attention'][i], input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
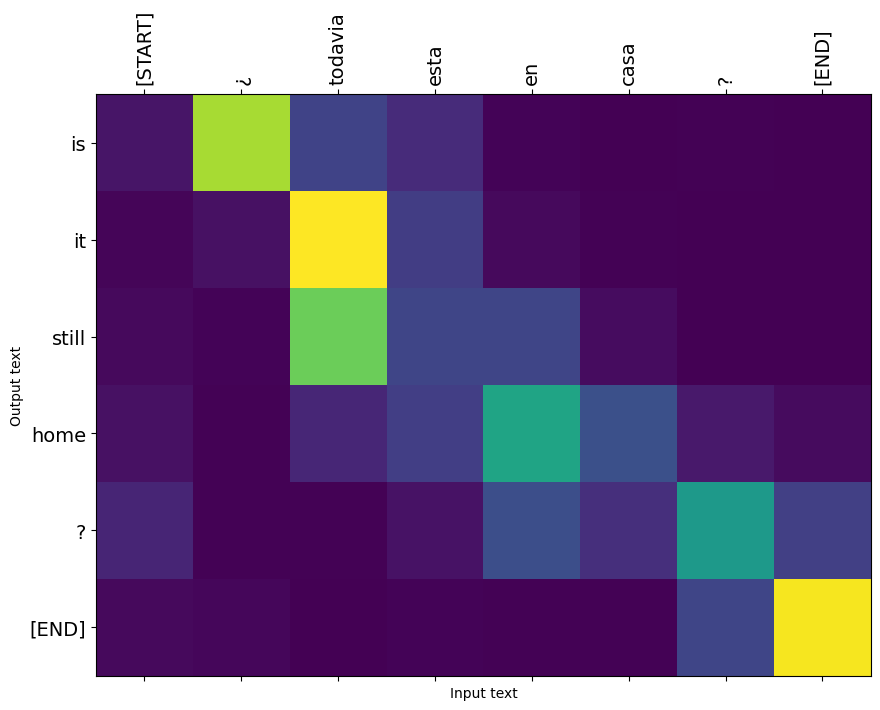
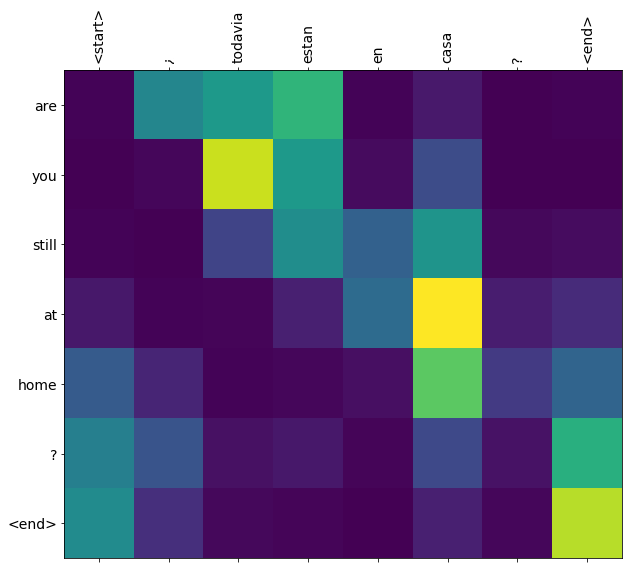
Dịch thêm một vài câu và vẽ sơ đồ:
%%time
three_input_text = tf.constant([
# This is my life.
'Esta es mi vida.',
# Are they still home?
'¿Todavía están en casa?',
# Try to find out.'
'Tratar de descubrir.',
])
result = translator.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? all about killed . CPU times: user 78 ms, sys: 23 ms, total: 101 ms Wall time: 23.1 ms
result['text']
<tf.Tensor: shape=(3,), dtype=string, numpy=
array([b'this is my life .', b'are you still at home ?',
b'all about killed .'], dtype=object)>
i = 0
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 1
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

i = 2
plot_attention(result['attention'][i], three_input_text[i], result['text'][i])
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app

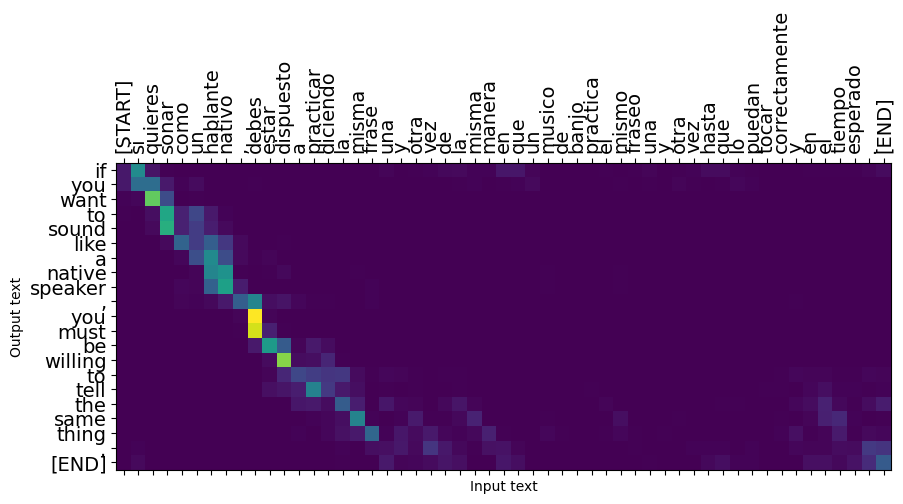
Các câu ngắn thường hoạt động tốt, nhưng nếu đầu vào quá dài, mô hình sẽ mất tập trung theo đúng nghĩa đen và ngừng cung cấp các dự đoán hợp lý. Có hai lý do chính cho việc này:
- Mô hình đã được đào tạo với việc giáo viên buộc phải cung cấp đúng mã thông báo ở mỗi bước, bất kể dự đoán của mô hình. Mô hình có thể được thực hiện mạnh mẽ hơn nếu đôi khi nó được cung cấp các dự đoán của chính nó.
- Mô hình chỉ có quyền truy cập vào đầu ra trước đó của nó thông qua trạng thái RNN. Nếu trạng thái RNN bị hỏng, không có cách nào để mô hình phục hồi. Transformers giải quyết điều này bằng cách sử dụng tự sự chú ý trong bộ mã hóa và giải mã.
long_input_text = tf.constant([inp[-1]])
import textwrap
print('Expected output:\n', '\n'.join(textwrap.wrap(targ[-1])))
Expected output: If you want to sound like a native speaker, you must be willing to practice saying the same sentence over and over in the same way that banjo players practice the same phrase over and over until they can play it correctly and at the desired tempo.
result = translator.tf_translate(long_input_text)
i = 0
plot_attention(result['attention'][i], long_input_text[i], result['text'][i])
_ = plt.suptitle('This never works')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:14: UserWarning: FixedFormatter should only be used together with FixedLocator /tmpfs/src/tf_docs_env/lib/python3.7/site-packages/ipykernel_launcher.py:15: UserWarning: FixedFormatter should only be used together with FixedLocator from ipykernel import kernelapp as app
Xuất khẩu
Một khi bạn có một mô hình bạn đang hài lòng với bạn có thể muốn xuất nó như là một tf.saved_model để sử dụng bên ngoài của chương trình python này đã tạo ra nó.
Từ mô hình này là một lớp con của tf.Module (thông qua keras.Model ), và tất cả các chức năng phục vụ xuất khẩu được biên dịch trong một tf.function mô hình nên xuất khẩu sạch với tf.saved_model.save :
Bây giờ mà các chức năng đã được bắt nguồn từ nó có thể được xuất khẩu sử dụng saved_model.save :
tf.saved_model.save(translator, 'translator',
signatures={'serving_default': translator.tf_translate})
2021-12-04 12:27:54.310890: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as encoder_2_layer_call_fn, encoder_2_layer_call_and_return_conditional_losses, decoder_2_layer_call_fn, decoder_2_layer_call_and_return_conditional_losses, embedding_4_layer_call_fn while saving (showing 5 of 60). These functions will not be directly callable after loading. INFO:tensorflow:Assets written to: translator/assets INFO:tensorflow:Assets written to: translator/assets
reloaded = tf.saved_model.load('translator')
result = reloaded.tf_translate(three_input_text)
%%time
result = reloaded.tf_translate(three_input_text)
for tr in result['text']:
print(tr.numpy().decode())
print()
this is my life . are you still at home ? find out about to find out . CPU times: user 42.8 ms, sys: 7.69 ms, total: 50.5 ms Wall time: 20 ms
Bước tiếp theo
- Tải về một tập dữ liệu khác nhau để thử nghiệm với bản dịch, ví dụ, tiếng Anh sang tiếng Đức, tiếng Anh hoặc tiếng Pháp.
- Thử nghiệm với việc đào tạo trên một tập dữ liệu lớn hơn hoặc sử dụng nhiều kỷ nguyên hơn.
- Hãy thử biến hướng dẫn mà thực hiện một nhiệm vụ dịch tương tự nhưng sử dụng một lớp biến thay vì RNNs. Phiên bản này cũng sử dụng một
text.BertTokenizerđể thực hiện wordpiece tokenization. - Có một cái nhìn tại tensorflow_addons.seq2seq để thực hiện điều này loại tự để mô hình chuỗi. Các
tfa.seq2seqgói bao gồm chức năng cấp cao hơn nhưseq2seq.BeamSearchDecoder.