
| | |  عرض المصدر على جيثب عرض المصدر على جيثب | |
يحتوي هذا البرنامج التعليمي على مقدمة لحفلات الزفاف. ستقوم بتدريب حفلات الزفاف الخاصة بك باستخدام نموذج Keras البسيط لمهمة تصنيف المشاعر ، ثم تصورها في جهاز عرض التضمين (كما هو موضح في الصورة أدناه).

تمثيل النص كأرقام
تأخذ نماذج التعلم الآلي المتجهات (مصفوفات الأرقام) كمدخلات. عند العمل مع النص ، فإن أول شيء يجب عليك فعله هو التوصل إلى إستراتيجية لتحويل السلاسل إلى أرقام (أو "تحويل النص") قبل إدخاله في النموذج. في هذا القسم ، سوف تنظر في ثلاث استراتيجيات للقيام بذلك.
ترميزات واحدة ساخنة
كأول فكرة ، قد تقوم بترميز كل كلمة في مفرداتك باستخدام طريقة "واحدة ساخنة". تأمل الجملة "جلست القطة على السجادة". المفردات (أو الكلمات الفريدة) في هذه الجملة هي (قطة ، حصيرة ، على ، جلس ، ال). لتمثيل كل كلمة ، ستقوم بإنشاء متجه صفري بطول يساوي المفردات ، ثم ضع واحدًا في الفهرس يتوافق مع الكلمة. يظهر هذا النهج في الرسم البياني التالي.
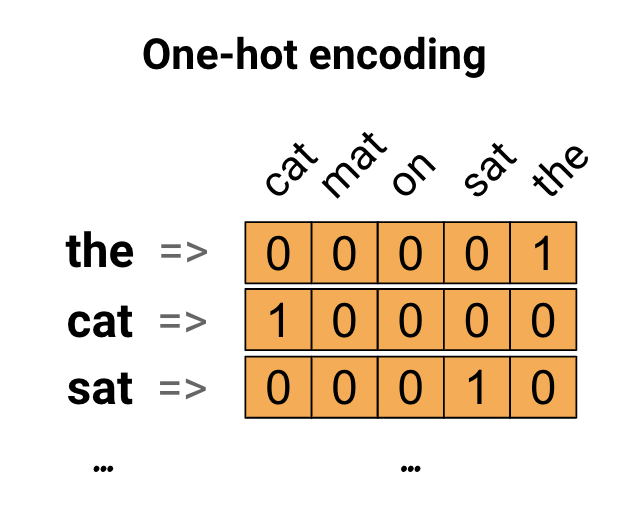
لإنشاء متجه يحتوي على ترميز الجملة ، يمكنك بعد ذلك ربط المتجهات الساخنة الواحدة لكل كلمة.
قم بتشفير كل كلمة برقم فريد
الطريقة الثانية التي يمكنك تجربتها هي تشفير كل كلمة باستخدام رقم فريد. متابعة للمثال أعلاه ، يمكنك تخصيص 1 لكلمة "قطة" و 2 إلى "حصيرة" وهكذا. يمكنك بعد ذلك ترميز الجملة "القط جالس على الحصيرة" كمتجه كثيف مثل [5 ، 1 ، 4 ، 3 ، 5 ، 2]. هذا النهج فعال. بدلاً من ناقل متناثر ، لديك الآن متجه كثيف (حيث تمتلئ جميع العناصر).
ومع ذلك ، هناك جانبان سلبيان لهذا النهج:
يعتبر ترميز الأعداد الصحيحة أمرًا تعسفيًا (لا يلتقط أي علاقة بين الكلمات).
يمكن أن يكون ترميز الأعداد الصحيحة تحديًا لتفسير النموذج. المصنف الخطي ، على سبيل المثال ، يتعلم وزنًا واحدًا لكل ميزة. نظرًا لعدم وجود علاقة بين التشابه بين كلمتين وتشابه ترميزاتهما ، فإن تركيبة وزن الميزة هذه ليست ذات معنى.
كلمة تطريز
تعطينا تضمين الكلمة طريقة لاستخدام تمثيل فعال ومكثف يكون للكلمات المتشابهة ترميز مشابه. الأهم من ذلك ، لا يتعين عليك تحديد هذا الترميز يدويًا. التضمين هو متجه كثيف لقيم الفاصلة العائمة (طول المتجه هو معلمة تحددها). بدلاً من تحديد قيم التضمين يدويًا ، فهي معلمات قابلة للتدريب (أوزان يتعلمها النموذج أثناء التدريب ، بنفس الطريقة التي يتعلم بها النموذج أوزان طبقة كثيفة). من الشائع رؤية تضمين الكلمات ذات الأبعاد الثمانية (لمجموعات البيانات الصغيرة) ، حتى 1024 بُعدًا عند العمل مع مجموعات البيانات الكبيرة. يمكن أن يؤدي التضمين ذو الأبعاد الأعلى إلى التقاط علاقات دقيقة بين الكلمات ، ولكنه يتطلب المزيد من البيانات للتعلم.
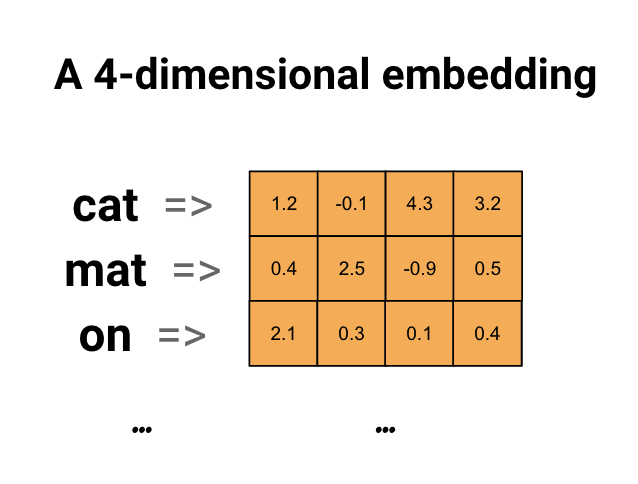
أعلاه هو رسم تخطيطي لتضمين كلمة. يتم تمثيل كل كلمة كمتجه رباعي الأبعاد لقيم الفاصلة العائمة. هناك طريقة أخرى للتفكير في التضمين وهي "جدول البحث". بعد تعلم هذه الأوزان ، يمكنك تشفير كل كلمة من خلال البحث عن المتجه الكثيف الذي يتوافق معه في الجدول.
يثبت
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
قم بتنزيل IMDb Dataset
ستستخدم مجموعة بيانات استعراض الأفلام الكبيرة من خلال البرنامج التعليمي. سوف تقوم بتدريب نموذج مصنف المشاعر على مجموعة البيانات هذه وفي هذه العملية تتعلم حفلات الزفاف من البداية. لقراءة المزيد حول تحميل مجموعة بيانات من البداية ، راجع البرنامج التعليمي تحميل النص .
قم بتنزيل مجموعة البيانات باستخدام أداة ملفات Keras وألق نظرة على الدلائل.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
الق نظرة على train/ الدليل. يحتوي على مجلدات pos و neg مع مراجعات الأفلام التي تم تصنيفها على أنها إيجابية وسلبية على التوالي. ستستخدم المراجعات من مجلدات pos و neg لتدريب نموذج تصنيف ثنائي.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
يحتوي دليل train أيضًا على مجلدات إضافية يجب إزالتها قبل إنشاء مجموعة بيانات التدريب.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
بعد ذلك ، قم بإنشاء tf.data.Dataset باستخدام tf.keras.utils.text_dataset_from_directory . يمكنك قراءة المزيد حول استخدام هذه الأداة المساعدة في هذا البرنامج التعليمي لتصنيف النص .
استخدم دليل train لإنشاء مجموعات بيانات القطار والتحقق من الصحة بتقسيم 20٪ للتحقق من الصحة.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
ألقِ نظرة على بعض تقييمات الأفلام وتسمياتها (1: positive, 0: negative) من مجموعة بيانات القطار.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
تكوين مجموعة البيانات للأداء
هاتان طريقتان مهمتان يجب عليك استخدامهما عند تحميل البيانات للتأكد من أن الإدخال / الإخراج لا يصبح محظورًا.
.cache() يحتفظ بالبيانات في الذاكرة بعد تحميلها خارج القرص. سيضمن ذلك عدم تحول مجموعة البيانات إلى عنق زجاجة أثناء تدريب نموذجك. إذا كانت مجموعة البيانات الخاصة بك كبيرة جدًا بحيث لا يمكن وضعها في الذاكرة ، فيمكنك أيضًا استخدام هذه الطريقة لإنشاء ذاكرة تخزين مؤقت على القرص ذات أداء فعال ، والتي تعد أكثر كفاءة في القراءة من العديد من الملفات الصغيرة.
.prefetch() يتداخل مع المعالجة المسبقة للبيانات وتنفيذ النموذج أثناء التدريب.
يمكنك معرفة المزيد حول كلتا الطريقتين ، بالإضافة إلى كيفية تخزين البيانات مؤقتًا على القرص في دليل أداء البيانات .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
استخدام طبقة التضمين
تسهل Keras استخدام حفلات الزفاف بالكلمات. ألق نظرة على طبقة التضمين .
يمكن فهم طبقة التضمين على أنها جدول بحث يقوم بالتخطيط من فهارس الأعداد الصحيحة (التي تعني كلمات محددة) إلى المتجهات الكثيفة (عناصر التضمينات الخاصة بهم). أبعاد (أو عرض) التضمين هي معلمة يمكنك تجربتها لمعرفة ما يناسب مشكلتك ، بنفس الطريقة التي تجرب بها عدد الخلايا العصبية في طبقة كثيفة.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
عندما تقوم بإنشاء طبقة التضمين ، يتم تهيئة أوزان التضمين عشوائيًا (تمامًا مثل أي طبقة أخرى). أثناء التدريب ، يتم ضبطهم تدريجيًا عن طريق التكاثر العكسي. بمجرد التدريب ، ستعمل كلمة حفلات الزفاف المكتسبة على ترميز أوجه التشابه بين الكلمات تقريبًا (حيث تم تعلمها من أجل المشكلة المحددة التي تدرب عليها نموذجك).
إذا قمت بتمرير عدد صحيح إلى طبقة تضمين ، فإن النتيجة تستبدل كل عدد صحيح بالمتجه من جدول التضمين:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
بالنسبة لمشاكل النص أو التسلسل ، تأخذ طبقة التضمين موترًا ثنائي الأبعاد من الأعداد الصحيحة ، من الشكل (samples, sequence_length) ، حيث يكون كل إدخال عبارة عن سلسلة من الأعداد الصحيحة. يمكنه تضمين تسلسلات ذات أطوال متغيرة. يمكنك تغذية طبقة التضمين فوق الدُفعات بالأشكال (32, 10) (دفعة من 32 سلسلة بطول 10) أو (64, 15) (دفعة من 64 سلسلة بطول 15).
يحتوي الموتر المرتجع على محور واحد أكثر من الإدخال ، ويتم محاذاة متجهات التضمين على طول المحور الأخير الجديد. مررها (2, 3) دفعة إدخال والإخراج (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
عند إعطاء دفعة من التسلسلات كمدخلات ، تقوم طبقة التضمين بإرجاع موتر فاصلة عائمة ثلاثي الأبعاد للشكل (samples, sequence_length, embedding_dimensionality) . للتحويل من هذا التسلسل ذي الطول المتغير إلى تمثيل ثابت ، هناك مجموعة متنوعة من الأساليب القياسية. يمكنك استخدام طبقة RNN أو Attention أو pooling قبل تمريرها إلى طبقة كثيفة. يستخدم هذا البرنامج التعليمي التجميع لأنه الأبسط. يعد تصنيف النص باستخدام البرنامج التعليمي لـ RNN خطوة تالية جيدة.
معالجة النص
بعد ذلك ، حدد خطوات المعالجة المسبقة لمجموعة البيانات المطلوبة لنموذج تصنيف المشاعر الخاص بك. قم بتهيئة طبقة TextVectorization مع المعلمات المطلوبة لتوجيه مراجعات الفيلم. يمكنك معرفة المزيد حول استخدام هذه الطبقة في البرنامج التعليمي Text Classification .
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
قم بإنشاء نموذج تصنيف
استخدم Keras Sequential API لتحديد نموذج تصنيف المشاعر. في هذه الحالة هو نموذج أسلوب "حقيبة الكلمات المستمرة".
- تقوم طبقة
TextVectorizationبتحويل السلاسل إلى فهارس المفردات. لقد قمت بالفعل بتهيئةvectorize_layerكطبقة TextVectorization وقمت ببناء مفرداتها من خلال استدعاءadaptعلىtext_ds. يمكن الآن استخدام vectorize_layer كطبقة أولى من نموذج التصنيف الشامل الخاص بك ، مع تغذية السلاسل المحولة في طبقة التضمين. تأخذ طبقة
Embeddingالمفردات المشفرة بعدد صحيح وتبحث عن متجه التضمين لكل فهرس كلمة. يتم تعلم هذه النواقل باعتبارها نموذج القطارات. تضيف المتجهات بعدًا إلى صفيف الإخراج. الأبعاد الناتجة هي:(batch, sequence, embedding).تقوم طبقة
GlobalAveragePooling1Dبإرجاع متجه إخراج بطول ثابت لكل مثال عن طريق حساب المتوسط على بُعد التسلسل. هذا يسمح للنموذج بالتعامل مع المدخلات ذات الطول المتغير ، بأبسط طريقة ممكنة.يتم توجيه متجه الخرج بطول ثابت من خلال طبقة متصلة بالكامل (
Dense) مع 16 وحدة مخفية.الطبقة الأخيرة متصلة بكثافة مع عقدة خرج واحدة.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
تجميع وتدريب النموذج
ستستخدم TensorBoard لتصور المقاييس بما في ذلك الخسارة والدقة. قم بإنشاء tf.keras.callbacks.TensorBoard .
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
قم بتجميع النموذج وتدريبه باستخدام مُحسِّن Adam وخسارة BinaryCrossentropy .
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
باستخدام هذا النهج ، يصل النموذج إلى دقة التحقق من الصحة بحوالي 78٪ (لاحظ أن النموذج مفرط في التجهيز لأن دقة التدريب أعلى).
يمكنك الاطلاع على ملخص النموذج لمعرفة المزيد حول كل طبقة من النموذج.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
تصور مقاييس النموذج في TensorBoard.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
استرجع كلمة حفلات الزفاف المدربة واحفظها على القرص
بعد ذلك ، استرجع كلمة حفلات الزفاف التي تعلمتها أثناء التدريب. الزخارف هي أوزان طبقة التضمين في النموذج. مصفوفة الأوزان من الشكل (vocab_size, embedding_dimension) .
احصل على الأوزان من النموذج باستخدام get_layer() و get_weights() . توفر وظيفة get_vocabulary() المفردات لبناء ملف بيانات وصفية برمز واحد لكل سطر.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
اكتب الأوزان على القرص. لاستخدام جهاز عرض التضمين ، ستقوم بتحميل ملفين بتنسيق مفصول بعلامات جدولة: ملف متجه (يحتوي على التضمين) ، وملف بيانات التعريف (يحتوي على الكلمات).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
إذا كنت تقوم بتشغيل هذا البرنامج التعليمي في Colaboratory ، فيمكنك استخدام المقتطف التالي لتنزيل هذه الملفات على جهازك المحلي (أو استخدام مستعرض الملفات ، عرض -> جدول المحتويات -> متصفح الملفات ).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
تصور حفلات الزفاف
لتصور حفلات الزفاف ، قم بتحميلها على جهاز عرض التضمين.
افتح جهاز عرض التضمين (يمكن أيضًا تشغيله في مثيل محلي TensorBoard).
انقر فوق "تحميل البيانات".
قم بتحميل الملفين اللذين قمت بإنشائهما أعلاه:
vecs.tsvوmeta.tsv.
سيتم الآن عرض حفلات الزفاف التي قمت بتدريبها. يمكنك البحث عن كلمات للعثور على أقرب جيرانهم. على سبيل المثال ، حاول البحث عن "جميلة". قد ترى الجيران مثل "رائع".
الخطوات التالية
لقد أوضح لك هذا البرنامج التعليمي كيفية تدريب وتصور حفلات الزفاف بالكلمات من البداية على مجموعة بيانات صغيرة.
لتدريب حفلات الزفاف باستخدام خوارزمية Word2Vec ، جرب البرنامج التعليمي Word2Vec .
لمعرفة المزيد حول المعالجة المتقدمة للنصوص ، اقرأ نموذج Transformer لفهم اللغة .