
| | |  Xem nguồn trên GitHub Xem nguồn trên GitHub | |
Hướng dẫn này có phần giới thiệu về cách nhúng từ. Bạn sẽ đào tạo cách nhúng từ của riêng mình bằng cách sử dụng mô hình Keras đơn giản cho nhiệm vụ phân loại tình cảm, và sau đó trực quan hóa chúng trong Máy chiếu nhúng (được hiển thị trong hình ảnh bên dưới).

Biểu diễn văn bản dưới dạng số
Mô hình học máy lấy vectơ (mảng số) làm đầu vào. Khi làm việc với văn bản, điều đầu tiên bạn phải làm là nghĩ ra một chiến lược để chuyển đổi chuỗi thành số (hoặc để "vectơ hóa" văn bản) trước khi đưa nó vào mô hình. Trong phần này, bạn sẽ xem xét ba chiến lược để làm như vậy.
Mã hóa một lần
Ý tưởng đầu tiên là bạn có thể mã hóa từng từ trong vốn từ vựng của mình. Hãy xem xét câu "The cat sat on the mat". Từ vựng (hoặc các từ duy nhất) trong câu này là (cat, mat, on, sat, the). Để đại diện cho mỗi từ, bạn sẽ tạo một vectơ 0 có độ dài bằng từ vựng, sau đó đặt một vectơ trong chỉ mục tương ứng với từ đó. Cách tiếp cận này được thể hiện trong sơ đồ sau.
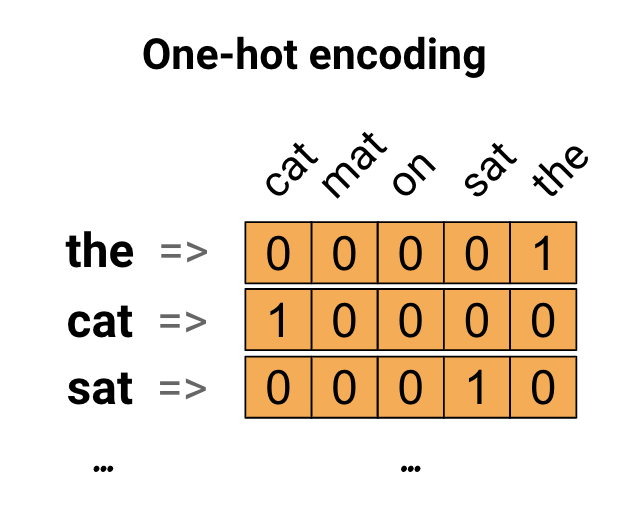
Để tạo một vectơ có chứa mã hóa của câu, sau đó bạn có thể nối các vectơ duy nhất cho mỗi từ.
Mã hóa mỗi từ bằng một số duy nhất
Cách tiếp cận thứ hai mà bạn có thể thử là mã hóa mỗi từ bằng một số duy nhất. Tiếp tục ví dụ trên, bạn có thể gán 1 cho "cat", 2 cho "mat", v.v. Sau đó, bạn có thể mã hóa câu "Con mèo ngồi trên chiếu" dưới dạng vectơ dày đặc như [5, 1, 4, 3, 5, 2]. Cách tiếp cận này là hiệu quả. Thay vì một vectơ thưa thớt, bây giờ bạn có một vectơ dày đặc (nơi tất cả các phần tử đều đầy đủ).
Tuy nhiên, có hai nhược điểm của phương pháp này:
Mã hóa số nguyên là tùy ý (nó không nắm bắt bất kỳ mối quan hệ nào giữa các từ).
Mã hóa số nguyên có thể là một thách thức đối với một mô hình để diễn giải. Ví dụ, một bộ phân loại tuyến tính học một trọng số duy nhất cho mỗi đối tượng địa lý. Bởi vì không có mối quan hệ giữa sự giống nhau của hai từ bất kỳ và sự giống nhau của các mã hóa của chúng, sự kết hợp trọng số đặc trưng này không có ý nghĩa.
Nhúng từ
Nhúng từ cung cấp cho chúng ta một cách để sử dụng một cách biểu diễn hiệu quả, dày đặc, trong đó các từ tương tự có mã hóa tương tự. Quan trọng là bạn không phải chỉ định mã hóa này bằng tay. Phép nhúng là một vectơ dày đặc các giá trị dấu chấm động (độ dài của vectơ là một tham số bạn chỉ định). Thay vì chỉ định các giá trị cho việc nhúng theo cách thủ công, chúng là các tham số có thể đào tạo (trọng số được mô hình học trong quá trình đào tạo, giống như cách một mô hình học trọng số cho một lớp dày đặc). Người ta thường thấy các nhúng từ có 8 chiều (đối với tập dữ liệu nhỏ), lên đến 1024 chiều khi làm việc với tập dữ liệu lớn. Nhúng theo chiều cao hơn có thể nắm bắt các mối quan hệ chi tiết giữa các từ, nhưng cần nhiều dữ liệu hơn để tìm hiểu.
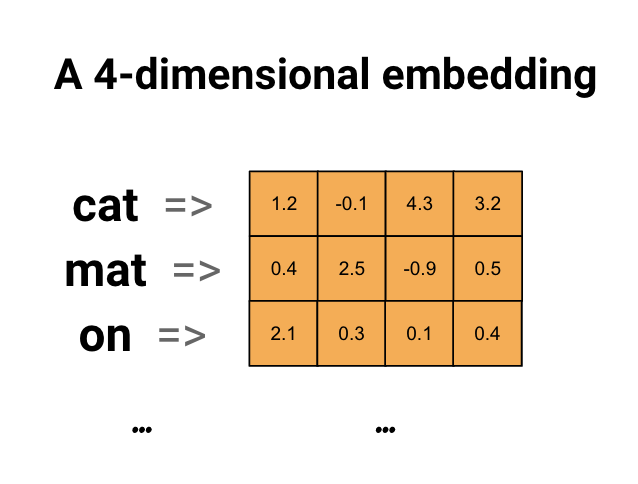
Trên đây là sơ đồ cho một từ nhúng. Mỗi từ được biểu diễn dưới dạng véc tơ 4 chiều của các giá trị dấu phẩy động. Một cách khác để nghĩ về một nhúng là "bảng tra cứu". Sau khi đã học xong các trọng số này, bạn có thể mã hóa từng từ bằng cách tra cứu vectơ dày đặc mà nó tương ứng trong bảng.
Thành lập
import io
import os
import re
import shutil
import string
import tensorflow as tf
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Dense, Embedding, GlobalAveragePooling1D
from tensorflow.keras.layers import TextVectorization
Tải xuống Tập dữ liệu IMDb
Bạn sẽ sử dụng Tập dữ liệu đánh giá phim lớn thông qua hướng dẫn. Bạn sẽ đào tạo một mô hình phân loại tình cảm trên tập dữ liệu này và trong quá trình này, bạn sẽ học cách nhúng từ đầu. Để đọc thêm về cách tải tập dữ liệu từ đầu, hãy xem hướng dẫn Tải văn bản .
Tải xuống tập dữ liệu bằng tiện ích tệp Keras và xem các thư mục.
url = "https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz"
dataset = tf.keras.utils.get_file("aclImdb_v1.tar.gz", url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
os.listdir(dataset_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step ['test', 'imdb.vocab', 'imdbEr.txt', 'train', 'README']
Hãy xem thư mục train/ . Nó có các thư mục pos và neg với các đánh giá phim được gắn nhãn tương ứng là tích cực và tiêu cực. Bạn sẽ sử dụng các đánh giá từ các thư mục pos và neg để đào tạo một mô hình phân loại nhị phân.
train_dir = os.path.join(dataset_dir, 'train')
os.listdir(train_dir)
['urls_pos.txt', 'urls_unsup.txt', 'urls_neg.txt', 'pos', 'unsup', 'unsupBow.feat', 'neg', 'labeledBow.feat']
Thư mục train cũng có các thư mục bổ sung cần được xóa trước khi tạo tập dữ liệu đào tạo.
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Tiếp theo, tạo tf.data.Dataset bằng tf.keras.utils.text_dataset_from_directory . Bạn có thể đọc thêm về cách sử dụng tiện ích này trong hướng dẫn phân loại văn bản này.
Sử dụng thư mục train để tạo cả tập dữ liệu huấn luyện và xác thực với phần chia 20% để xác thực.
batch_size = 1024
seed = 123
train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='training', seed=seed)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train', batch_size=batch_size, validation_split=0.2,
subset='validation', seed=seed)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation.
Hãy xem một vài bài đánh giá phim và nhãn của chúng (1: positive, 0: negative) từ tập dữ liệu về xe lửa.
for text_batch, label_batch in train_ds.take(1):
for i in range(5):
print(label_batch[i].numpy(), text_batch.numpy()[i])
0 b"Oh My God! Please, for the love of all that is holy, Do Not Watch This Movie! It it 82 minutes of my life I will never get back. Sure, I could have stopped watching half way through. But I thought it might get better. It Didn't. Anyone who actually enjoyed this movie is one seriously sick and twisted individual. No wonder us Australians/New Zealanders have a terrible reputation when it comes to making movies. Everything about this movie is horrible, from the acting to the editing. I don't even normally write reviews on here, but in this case I'll make an exception. I only wish someone had of warned me before I hired this catastrophe" 1 b'This movie is SOOOO funny!!! The acting is WONDERFUL, the Ramones are sexy, the jokes are subtle, and the plot is just what every high schooler dreams of doing to his/her school. I absolutely loved the soundtrack as well as the carefully placed cynicism. If you like monty python, You will love this film. This movie is a tad bit "grease"esk (without all the annoying songs). The songs that are sung are likable; you might even find yourself singing these songs once the movie is through. This musical ranks number two in musicals to me (second next to the blues brothers). But please, do not think of it as a musical per say; seeing as how the songs are so likable, it is hard to tell a carefully choreographed scene is taking place. I think of this movie as more of a comedy with undertones of romance. You will be reminded of what it was like to be a rebellious teenager; needless to say, you will be reminiscing of your old high school days after seeing this film. Highly recommended for both the family (since it is a very youthful but also for adults since there are many jokes that are funnier with age and experience.' 0 b"Alex D. Linz replaces Macaulay Culkin as the central figure in the third movie in the Home Alone empire. Four industrial spies acquire a missile guidance system computer chip and smuggle it through an airport inside a remote controlled toy car. Because of baggage confusion, grouchy Mrs. Hess (Marian Seldes) gets the car. She gives it to her neighbor, Alex (Linz), just before the spies turn up. The spies rent a house in order to burglarize each house in the neighborhood until they locate the car. Home alone with the chicken pox, Alex calls 911 each time he spots a theft in progress, but the spies always manage to elude the police while Alex is accused of making prank calls. The spies finally turn their attentions toward Alex, unaware that he has rigged devices to cleverly booby-trap his entire house. Home Alone 3 wasn't horrible, but probably shouldn't have been made, you can't just replace Macauley Culkin, Joe Pesci, or Daniel Stern. Home Alone 3 had some funny parts, but I don't like when characters are changed in a movie series, view at own risk." 0 b"There's a good movie lurking here, but this isn't it. The basic idea is good: to explore the moral issues that would face a group of young survivors of the apocalypse. But the logic is so muddled that it's impossible to get involved.<br /><br />For example, our four heroes are (understandably) paranoid about catching the mysterious airborne contagion that's wiped out virtually all of mankind. Yet they wear surgical masks some times, not others. Some times they're fanatical about wiping down with bleach any area touched by an infected person. Other times, they seem completely unconcerned.<br /><br />Worse, after apparently surviving some weeks or months in this new kill-or-be-killed world, these people constantly behave like total newbs. They don't bother accumulating proper equipment, or food. They're forever running out of fuel in the middle of nowhere. They don't take elementary precautions when meeting strangers. And after wading through the rotting corpses of the entire human race, they're as squeamish as sheltered debutantes. You have to constantly wonder how they could have survived this long... and even if they did, why anyone would want to make a movie about them.<br /><br />So when these dweebs stop to agonize over the moral dimensions of their actions, it's impossible to take their soul-searching seriously. Their actions would first have to make some kind of minimal sense.<br /><br />On top of all this, we must contend with the dubious acting abilities of Chris Pine. His portrayal of an arrogant young James T Kirk might have seemed shrewd, when viewed in isolation. But in Carriers he plays on exactly that same note: arrogant and boneheaded. It's impossible not to suspect that this constitutes his entire dramatic range.<br /><br />On the positive side, the film *looks* excellent. It's got an over-sharp, saturated look that really suits the southwestern US locale. But that can't save the truly feeble writing nor the paper-thin (and annoying) characters. Even if you're a fan of the end-of-the-world genre, you should save yourself the agony of watching Carriers." 0 b'I saw this movie at an actual movie theater (probably the \\(2.00 one) with my cousin and uncle. We were around 11 and 12, I guess, and really into scary movies. I remember being so excited to see it because my cool uncle let us pick the movie (and we probably never got to do that again!) and sooo disappointed afterwards!! Just boring and not scary. The only redeeming thing I can remember was Corky Pigeon from Silver Spoons, and that wasn\'t all that great, just someone I recognized. I\'ve seen bad movies before and this one has always stuck out in my mind as the worst. This was from what I can recall, one of the most boring, non-scary, waste of our collective \\)6, and a waste of film. I have read some of the reviews that say it is worth a watch and I say, "Too each his own", but I wouldn\'t even bother. Not even so bad it\'s good.'
Định cấu hình tập dữ liệu cho hiệu suất
Đây là hai phương pháp quan trọng bạn nên sử dụng khi tải dữ liệu để đảm bảo rằng I / O không bị chặn.
.cache() giữ dữ liệu trong bộ nhớ sau khi nó được tải ra khỏi đĩa. Điều này sẽ đảm bảo tập dữ liệu không trở thành nút cổ chai trong khi đào tạo mô hình của bạn. Nếu tập dữ liệu của bạn quá lớn để vừa với bộ nhớ, bạn cũng có thể sử dụng phương pháp này để tạo bộ đệm ẩn trên đĩa hiệu quả, hiệu quả hơn để đọc so với nhiều tệp nhỏ.
.prefetch() chồng lên quá trình tiền xử lý dữ liệu và thực thi mô hình trong khi đào tạo.
Bạn có thể tìm hiểu thêm về cả hai phương pháp cũng như cách lưu trữ dữ liệu vào đĩa trong hướng dẫn về hiệu suất dữ liệu .
AUTOTUNE = tf.data.AUTOTUNE
train_ds = train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
Sử dụng lớp Nhúng
Keras giúp bạn dễ dàng sử dụng tính năng nhúng từ. Hãy xem lớp Nhúng .
Lớp Nhúng có thể được hiểu là một bảng tra cứu ánh xạ từ các chỉ số nguyên (viết tắt của các từ cụ thể) đến các vectơ dày đặc (các nhúng của chúng). Kích thước (hoặc chiều rộng) của nhúng là một tham số bạn có thể thử nghiệm để xem điều gì hoạt động tốt cho vấn đề của bạn, giống như cách bạn thử nghiệm với số lượng tế bào thần kinh trong một lớp dày đặc.
# Embed a 1,000 word vocabulary into 5 dimensions.
embedding_layer = tf.keras.layers.Embedding(1000, 5)
Khi bạn tạo một lớp Nhúng, trọng số cho việc nhúng sẽ được khởi tạo ngẫu nhiên (giống như bất kỳ lớp nào khác). Trong quá trình đào tạo, chúng dần dần được điều chỉnh thông qua nhân giống ngược. Sau khi được đào tạo, các phép nhúng từ đã học sẽ mã hóa gần như tương đồng giữa các từ (vì chúng đã được học cho vấn đề cụ thể mà mô hình của bạn được đào tạo).
Nếu bạn chuyển một số nguyên vào một lớp nhúng, kết quả sẽ thay thế mỗi số nguyên bằng vectơ từ bảng nhúng:
result = embedding_layer(tf.constant([1, 2, 3]))
result.numpy()
array([[ 0.01318491, -0.02219239, 0.024673 , -0.03208025, 0.02297195],
[-0.00726584, 0.03731754, -0.01209557, -0.03887399, -0.02407478],
[ 0.04477594, 0.04504738, -0.02220147, -0.03642888, -0.04688282]],
dtype=float32)
Đối với các vấn đề về văn bản hoặc trình tự, lớp Nhúng lấy hàng chục số nguyên, có hình dạng (samples, sequence_length) , trong đó mỗi mục nhập là một chuỗi các số nguyên. Nó có thể nhúng các chuỗi có độ dài thay đổi. Bạn có thể đưa vào lớp nhúng ở trên các lô có hình dạng (32, 10) (lô 32 dãy có độ dài 10) hoặc (64, 15) (đợt 64 dãy có độ dài 15).
Hàng chục được trả về có nhiều trục hơn đầu vào, các vectơ nhúng được căn chỉnh dọc theo trục cuối cùng mới. Chuyển cho nó một (2, 3) lô đầu vào và đầu ra là (2, 3, N)
result = embedding_layer(tf.constant([[0, 1, 2], [3, 4, 5]]))
result.shape
TensorShape([2, 3, 5])
Khi được cung cấp một loạt các trình tự làm đầu vào, một lớp nhúng sẽ trả về một tensor dấu chấm động 3D, có hình dạng (samples, sequence_length, embedding_dimensionality) . Để chuyển đổi từ chuỗi có độ dài thay đổi này thành một biểu diễn cố định, có nhiều cách tiếp cận tiêu chuẩn khác nhau. Bạn có thể sử dụng lớp RNN, Attention hoặc gộp trước khi chuyển nó sang lớp dày đặc. Hướng dẫn này sử dụng tính năng gộp vì nó đơn giản nhất. Phân loại văn bản với hướng dẫn RNN là một bước tiếp theo tốt.
Xử lý trước văn bản
Tiếp theo, xác định các bước xử lý trước tập dữ liệu cần thiết cho mô hình phân loại tình cảm của bạn. Khởi tạo lớp TextVectorization với các thông số mong muốn để vector hóa các bài đánh giá phim. Bạn có thể tìm hiểu thêm về cách sử dụng lớp này trong hướng dẫn Phân loại Văn bản .
# Create a custom standardization function to strip HTML break tags '<br />'.
def custom_standardization(input_data):
lowercase = tf.strings.lower(input_data)
stripped_html = tf.strings.regex_replace(lowercase, '<br />', ' ')
return tf.strings.regex_replace(stripped_html,
'[%s]' % re.escape(string.punctuation), '')
# Vocabulary size and number of words in a sequence.
vocab_size = 10000
sequence_length = 100
# Use the text vectorization layer to normalize, split, and map strings to
# integers. Note that the layer uses the custom standardization defined above.
# Set maximum_sequence length as all samples are not of the same length.
vectorize_layer = TextVectorization(
standardize=custom_standardization,
max_tokens=vocab_size,
output_mode='int',
output_sequence_length=sequence_length)
# Make a text-only dataset (no labels) and call adapt to build the vocabulary.
text_ds = train_ds.map(lambda x, y: x)
vectorize_layer.adapt(text_ds)
Tạo mô hình phân loại
Sử dụng API tuần tự Keras để xác định mô hình phân loại tình cảm. Trong trường hợp này, đó là mô hình kiểu "Túi lời liên tục".
- Lớp
TextVectorizationchuyển đổi các chuỗi thành các chỉ mục từ vựng. Bạn đã khởi tạovectorize_layerdưới dạng lớp TextVectorization và xây dựng vốn từ vựng của nó bằng cách gọiadapttrêntext_ds. Giờ đây, vectorize_layer có thể được sử dụng làm lớp đầu tiên của mô hình phân loại end-to-end của bạn, cung cấp các chuỗi đã chuyển đổi vào lớp Nhúng. Lớp
Embeddinglấy từ vựng được mã hóa số nguyên và tra cứu vectơ nhúng cho mỗi từ-chỉ mục. Các vectơ này được học khi mô hình đào tạo. Các vectơ thêm một thứ nguyên vào mảng đầu ra. Các kích thước kết quả là:(batch, sequence, embedding).Lớp
GlobalAveragePooling1Dtrả về một vectơ đầu ra có độ dài cố định cho mỗi ví dụ bằng cách lấy trung bình trên thứ nguyên trình tự. Điều này cho phép mô hình xử lý đầu vào có độ dài thay đổi, theo cách đơn giản nhất có thể.Vectơ đầu ra có độ dài cố định được chuyển qua một lớp được kết nối đầy đủ (
Dense) với 16 đơn vị ẩn.Lớp cuối cùng được kết nối dày đặc với một nút đầu ra duy nhất.
embedding_dim=16
model = Sequential([
vectorize_layer,
Embedding(vocab_size, embedding_dim, name="embedding"),
GlobalAveragePooling1D(),
Dense(16, activation='relu'),
Dense(1)
])
Biên dịch và đào tạo mô hình
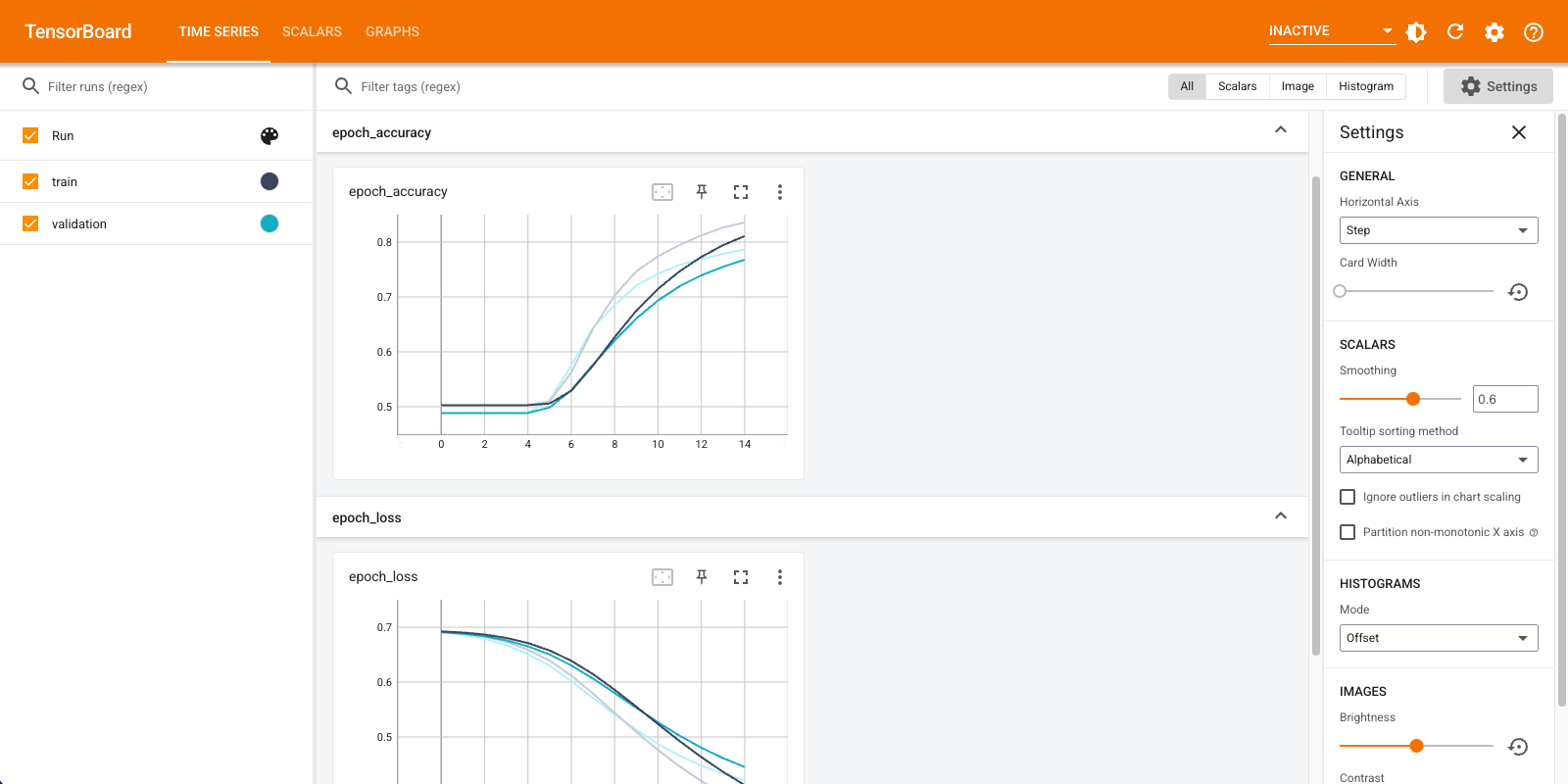
Bạn sẽ sử dụng TensorBoard để trực quan hóa các số liệu bao gồm mất mát và độ chính xác. Tạo tf.keras.callbacks.TensorBoard .
tensorboard_callback = tf.keras.callbacks.TensorBoard(log_dir="logs")
Biên dịch và đào tạo mô hình bằng cách sử dụng trình tối ưu hóa Adam và mất BinaryCrossentropy .
model.compile(optimizer='adam',
loss=tf.keras.losses.BinaryCrossentropy(from_logits=True),
metrics=['accuracy'])
model.fit(
train_ds,
validation_data=val_ds,
epochs=15,
callbacks=[tensorboard_callback])
Epoch 1/15 20/20 [==============================] - 2s 71ms/step - loss: 0.6910 - accuracy: 0.5028 - val_loss: 0.6878 - val_accuracy: 0.4886 Epoch 2/15 20/20 [==============================] - 1s 57ms/step - loss: 0.6838 - accuracy: 0.5028 - val_loss: 0.6791 - val_accuracy: 0.4886 Epoch 3/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6726 - accuracy: 0.5028 - val_loss: 0.6661 - val_accuracy: 0.4886 Epoch 4/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6563 - accuracy: 0.5028 - val_loss: 0.6481 - val_accuracy: 0.4886 Epoch 5/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6343 - accuracy: 0.5061 - val_loss: 0.6251 - val_accuracy: 0.5066 Epoch 6/15 20/20 [==============================] - 1s 58ms/step - loss: 0.6068 - accuracy: 0.5634 - val_loss: 0.5982 - val_accuracy: 0.5762 Epoch 7/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5752 - accuracy: 0.6405 - val_loss: 0.5690 - val_accuracy: 0.6386 Epoch 8/15 20/20 [==============================] - 1s 58ms/step - loss: 0.5412 - accuracy: 0.7036 - val_loss: 0.5390 - val_accuracy: 0.6850 Epoch 9/15 20/20 [==============================] - 1s 59ms/step - loss: 0.5064 - accuracy: 0.7479 - val_loss: 0.5106 - val_accuracy: 0.7222 Epoch 10/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4734 - accuracy: 0.7774 - val_loss: 0.4855 - val_accuracy: 0.7430 Epoch 11/15 20/20 [==============================] - 1s 59ms/step - loss: 0.4432 - accuracy: 0.7971 - val_loss: 0.4636 - val_accuracy: 0.7570 Epoch 12/15 20/20 [==============================] - 1s 58ms/step - loss: 0.4161 - accuracy: 0.8155 - val_loss: 0.4453 - val_accuracy: 0.7674 Epoch 13/15 20/20 [==============================] - 1s 59ms/step - loss: 0.3921 - accuracy: 0.8304 - val_loss: 0.4303 - val_accuracy: 0.7780 Epoch 14/15 20/20 [==============================] - 1s 61ms/step - loss: 0.3711 - accuracy: 0.8398 - val_loss: 0.4181 - val_accuracy: 0.7884 Epoch 15/15 20/20 [==============================] - 1s 58ms/step - loss: 0.3524 - accuracy: 0.8493 - val_loss: 0.4082 - val_accuracy: 0.7948 <keras.callbacks.History at 0x7fca579745d0>
Với cách tiếp cận này, mô hình đạt độ chính xác xác thực khoảng 78% (lưu ý rằng mô hình được trang bị quá mức vì độ chính xác đào tạo cao hơn).
Bạn có thể xem phần tóm tắt mô hình để tìm hiểu thêm về từng lớp của mô hình.
model.summary()
Model: "sequential"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
text_vectorization (TextVec (None, 100) 0
torization)
embedding (Embedding) (None, 100, 16) 160000
global_average_pooling1d (G (None, 16) 0
lobalAveragePooling1D)
dense (Dense) (None, 16) 272
dense_1 (Dense) (None, 1) 17
=================================================================
Total params: 160,289
Trainable params: 160,289
Non-trainable params: 0
_________________________________________________________________
Hình dung các chỉ số của mô hình trong TensorBoard.
#docs_infra: no_execute
%load_ext tensorboard
%tensorboard --logdir logs
Truy xuất các nhúng từ đã đào tạo và lưu chúng vào đĩa
Tiếp theo, truy xuất các từ nhúng đã học trong quá trình đào tạo. Các phần nhúng là trọng số của lớp Nhúng trong mô hình. Ma trận trọng số có dạng (vocab_size, embedding_dimension) .
Lấy các trọng số từ mô hình bằng cách sử dụng get_layer() và get_weights() . Hàm get_vocabulary() cung cấp từ vựng để tạo tệp siêu dữ liệu với một mã thông báo trên mỗi dòng.
weights = model.get_layer('embedding').get_weights()[0]
vocab = vectorize_layer.get_vocabulary()
Ghi các trọng lượng vào đĩa. Để sử dụng Máy chiếu nhúng , bạn sẽ tải lên hai tệp ở định dạng được phân tách bằng tab: tệp vectơ (chứa tệp nhúng) và tệp dữ liệu meta (chứa các từ).
out_v = io.open('vectors.tsv', 'w', encoding='utf-8')
out_m = io.open('metadata.tsv', 'w', encoding='utf-8')
for index, word in enumerate(vocab):
if index == 0:
continue # skip 0, it's padding.
vec = weights[index]
out_v.write('\t'.join([str(x) for x in vec]) + "\n")
out_m.write(word + "\n")
out_v.close()
out_m.close()
Nếu bạn đang chạy hướng dẫn này trong Colaboratory , bạn có thể sử dụng đoạn mã sau để tải các tệp này xuống máy cục bộ của mình (hoặc sử dụng trình duyệt tệp, Xem -> Mục lục -> Trình duyệt tệp ).
try:
from google.colab import files
files.download('vectors.tsv')
files.download('metadata.tsv')
except Exception:
pass
Hình dung các nhúng
Để hình dung các nhúng, hãy tải chúng lên máy chiếu nhúng.
Mở Máy chiếu nhúng (điều này cũng có thể chạy trong phiên bản TensorBoard cục bộ).
Nhấp vào "Nạp dữ liệu".
Tải lên hai tệp bạn đã tạo ở trên:
vecs.tsvvàmeta.tsv.
Các phương pháp nhúng bạn đã đào tạo bây giờ sẽ được hiển thị. Bạn có thể tìm kiếm các từ để tìm những người hàng xóm gần nhất của họ. Ví dụ, hãy thử tìm kiếm "đẹp". Bạn có thể thấy những người hàng xóm như "tuyệt vời".
Bước tiếp theo
Hướng dẫn này đã chỉ cho bạn cách đào tạo và trực quan hóa việc nhúng từ từ đầu trên một tập dữ liệu nhỏ.
Để đào tạo cách nhúng từ bằng thuật toán Word2Vec, hãy thử hướng dẫn Word2Vec .
Để tìm hiểu thêm về xử lý văn bản nâng cao, hãy đọc Mô hình máy biến áp để hiểu ngôn ngữ .