
本教程向您展示如何使用 TensorFlow Lite 构建 Android 应用来对自然语言文本进行分类。此应用是专为实体 Android 设备设计,但也可以在设备模拟器上运行。
示例应用使用 TensorFlow Lite 将文本分类为正面或负面,使用自然语言 (NL) 任务库来执行文本分类机器学习模型。
如果您要更新现有项目,则可以将示例应用用作参考或模板。有关如何向现有应用添加文本分类的说明,请参阅更新和修改应用。
文本分类概述
文本分类是将一组预定义类别分配给开放式文本的机器学习任务。文本分类模型在自然语言文本语料库上进行训练,其中的单词或短语为手动分类。
训练后的模型接收文本作为输入,并尝试根据训练分类的一组已知类对文本进行分类。例如,此示例中的模型接受一段文本,并确定文本的情绪是正面的还是负面的。对于每个文本片段,文本分类模型都会输出一个分数,该分数指示文本被正确分类为正面或负面的置信度。
有关如何生成本教程中的模型的更多信息,请参阅使用 TensorFlow Lite Model Maker 进行文本分类教程。
模型和数据集
本教程采用了使用 SST-2 (Stanford Sentiment Treebank) 数据集训练的模型。SST-2 包含 67,349 条用于训练的电影评论和 872 条用于测试的电影评论,每条评论都被分类为正面或负面。此应用中的模型使用 TensorFlow Lite Model Maker 工具进行训练。
示例应用使用以下预训练模型:
平均词向量 (
NLClassifier) - Task Library 的NLClassifier将输入文本分类为不同的类别,并且可以处理大多数文本分类模型。MobileBERT (
BertNLClassifier) - Task Library 的BertNLClassifier类似于 NLClassifier,但专为需要计算图外 Wordpiece 和 Sentencepiece 词例化的情况而定制。
设置并运行示例应用
要设置文本分类应用,请从 GitHub 下载示例应用并使用 Android Studio 运行。
系统要求
- Android Studio 2021.1.1 (Bumblebee) 或更高版本。
- Android SDK 31 或更高版本
- 最低操作系统版本为 SDK 21 (Android 7.0 - Nougat) 并且已启用开发者模式的 Android 设备,或者 Android 模拟器。
获取示例代码
创建一个示例代码的本地副本。您将使用此代码在 Android Studio 中创建一个项目并运行示例应用。
要克隆和设置示例代码,请执行以下操作:
- 克隆 git 仓库
git clone https://github.com/tensorflow/examples.git - (可选)将您的 git 实例配置为使用稀疏签出,这样您就只有文本分类示例应用的文件:
cd examples git sparse-checkout init --cone git sparse-checkout set lite/examples/text_classification/android
导入并运行项目
从下载的示例代码创建一个项目,构建并运行该项目。
要导入和构建示例代码项目,请执行以下操作:
- 启动 Android Studio。
- 在 Android Studio 中,选择 File > New > Import Project。
- 导航到包含 build.gradle 文件的示例代码目录 (
.../examples/lite/examples/text_classification/android/build.gradle) 并选择该目录。 - 如果 Android Studio 请求 Gradle Sync,请选择 OK。
- 确保您的 Android 设备已连接到计算机并且已启用开发者模式。点击绿色
Run箭头。
如果您选择了正确的目录,Android Studio 会创建并构建一个新项目。这个过程可能需要几分钟,具体取决于您的计算机速度,以及您是否曾将 Android Studio 用于其他项目。构建完成后,Android Studio 会在 Build Output 状态面板中显示 BUILD SUCCESSFUL 消息。
要运行该项目,请执行以下操作:
- 在 Android Studio 中,选择 Run > Run… 来运行项目。
- 选择一台已连接的 Android 设备(或模拟器)来测试应用。
使用应用
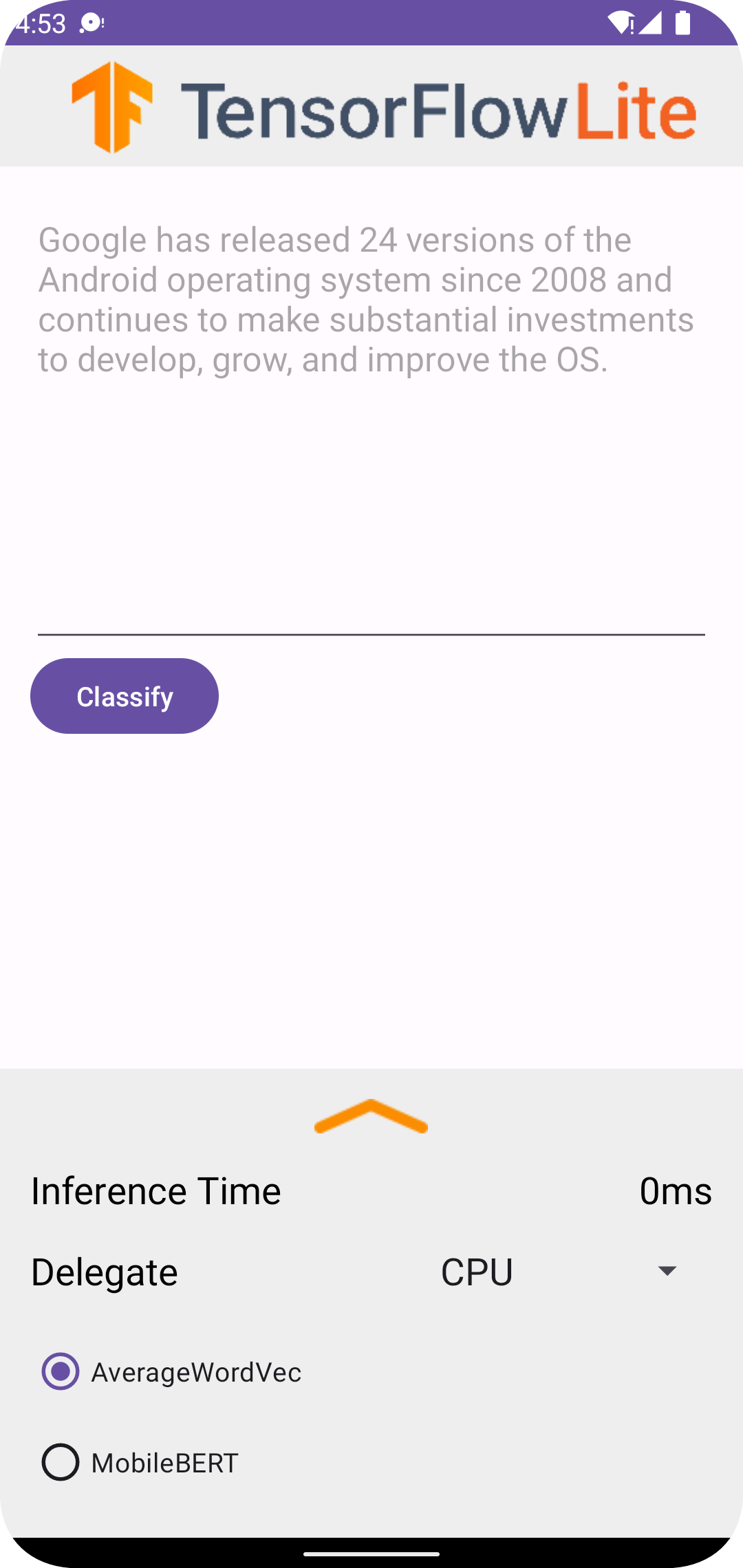
在 Android Studio 中运行项目后,应用将自动在连接的设备或设备模拟器上打开。
要使用文本分类器,请执行以下操作:
- 在文本框中输入一段文本。
- 从 Delegate 下拉列表中,选择
CPU或NNAPI。 - 通过选择
AverageWordVec或MobileBERT指定模型。 - 选择 Classify。
应用输出正分和负分。这两个分数总和为 1,并衡量输入文本的情绪是正面还是负面的可能性。数字越大表示置信度越高。
您现在有一个正常运行的文本分类应用。使用以下部分可以更好地了解示例应用的运作方式,以及如何在您的生产应用中实现文本分类功能:
示例应用的运作方式
该应用使用自然语言 (NL) 的任务库软件包来实现文本分类模型。Average Word Vector 和 MobileBERT 这两个模型使用 TensorFlow Lite Model Maker 进行训练。该应用默认在 CPU 上运行,也可以选择使用 NNAPI 委托进行硬件加速。
以下文件和目录包含此文本分类应用的关键代码:
- TextClassificationHelper.kt - 初始化文本分类器并处理模型和委托选择。
- MainActivity.kt - 实现应用,包括调用
TextClassificationHelper和ResultsAdapter。 - ResultsAdapter.kt - 处理和格式化结果。
修改您的应用
以下部分介绍了修改您自己的 Android 应用以运行示例应用中显示的模型的关键步骤。这些说明使用示例应用作为参考点。您自己的应用所需的具体更改可能与示例应用不同。
打开或创建一个 Android 项目
您需要在 Android Studio 中创建一个 Android 开发项目来遵循这些说明的其余部分。按照以下说明打开现有项目或创建新项目。
打开现有 Android 开发项目:
- 在 Android Studio 中,选择 File > Open 并选择一个现有项目。
创建一个基本的 Android 开发项目:
- 按照 Android Studio 中的说明创建一个基本项目。
有关使用 Android Studio 的更多信息,请参阅 Android Studio 文档。
添加项目依赖项
在您自己的应用中,您必须添加特定的项目依赖项才能运行 TensorFlow Lite 机器学习模型,并访问能够将字符串等数据转换为您所使用的模型可以处理的张量数据格式的效用函数。
以下说明解释了如何将所需的项目和模块依赖项添加到您自己的 Android 应用项目中。
要添加模块依赖项,请执行以下操作:
在使用 TensorFlow Lite 的模块中,更新模块的
build.gradle文件以包含以下依赖项。在示例应用中,依赖项位于 app/build.gradle 中:
dependencies { ... implementation 'org.tensorflow:tensorflow-lite-task-text:0.4.0' }项目必须包含文本任务库 (
tensorflow-lite-task-text)。如果您想修改此应用以在图形处理单元 (GPU) 上运行,GPU 库 (
tensorflow-lite-gpu-delegate-plugin) 提供了在 GPU 上运行应用的基础架构,而委托 (tensorflow-lite-gpu) 提供了兼容性列表。在 GPU 上运行此应用超出了本教程的范围。在 Android Studio 中,选择 File > Sync Project with Gradle Files 来同步项目依赖项。
初始化机器学习模型
在您的 Android 应用中,您必须先使用参数初始化 TensorFlow Lite 机器学习模型,然后才能使用模型运行预测。
TensorFlow Lite 模型存储为 *.tflite 文件。该模型文件包含预测逻辑,并且通常包含有关如何解释预测结果的元数据,例如预测类名称。通常,模型文件应存储在开发项目的 src/main/assets 目录中,如代码示例中所示:
<project>/src/main/assets/mobilebert.tflite<project>/src/main/assets/wordvec.tflite
注:示例应用在构建时使用 [download_model.gradle](https://github.com/tensorflow/examples/blob/master/lite/examples/text_classification/android/app/download_model.gradle) 文件下载 Average Word Vector 和 MobileBERT 模型。对于生产应用,这种方法不是必需的,也不推荐使用。
为方便起见和提升代码可读性,该示例声明了一个为模型定义设置的伴随对象。
要在您的应用中初始化模型,请执行以下操作:
创建一个伴随对象来定义模型的设置。在示例应用中,此对象位于 TextClassificationHelper.kt 中:
companion object { const val DELEGATE_CPU = 0 const val DELEGATE_NNAPI = 1 const val WORD_VEC = "wordvec.tflite" const val MOBILEBERT = "mobilebert.tflite" }通过构建分类器对象为模型创建设置,并使用
BertNLClassifier或NLClassifier构建 TensorFlow Lite 对象。在示例应用中,它位于 TextClassificationHelper.kt 的
initClassifier函数中:fun initClassifier() { ... if( currentModel == MOBILEBERT ) { ... bertClassifier = BertNLClassifier.createFromFileAndOptions( context, MOBILEBERT, options) } else if (currentModel == WORD_VEC) { ... nlClassifier = NLClassifier.createFromFileAndOptions( context, WORD_VEC, options) } }注:大多数使用文本分类的生产应用将使用
BertNLClassifier或NLClassifier之一,而不是两者。
启用硬件加速(可选)
在您的应用中初始化 TensorFlow Lite 模型时,您应该考虑使用硬件加速功能来加速模型的预测计算。TensorFlow Lite 委托是使用移动设备上的专用处理硬件(如图形处理单元 (GPU) 或张量处理单元 (TPU))加速机器学习模型执行的软件模块。
要在您的应用中启用硬件加速,请执行以下操作:
创建一个变量来定义应用将使用的委托。在示例应用中,此变量位于 TextClassificationHelper.kt 中:
var currentDelegate: Int = 0创建一个委托选择器。在示例应用中,委托选择器位于 TextClassificationHelper.kt 的
initClassifier函数中:val baseOptionsBuilder = BaseOptions.builder() when (currentDelegate) { DELEGATE_CPU -> { // Default } DELEGATE_NNAPI -> { baseOptionsBuilder.useNnapi() } }
注:可以修改此应用以使用 GPU 委托,但这需要在使用分类器的同一线程上创建分类器。这超出了本教程的范围。
建议使用委托来运行 TensorFlow Lite 模型,但不是必需的。有关在 TensorFlow Lite 中使用委托的更多信息,请参阅 TensorFlow Lite 委托。
为模型准备数据
在您的 Android 应用中,您的代码通过将现有数据(如原始文本)转换为可以被模型处理的张量数据格式,向模型提供数据进行解释。传递给模型的张量中的数据必须具有与用于训练模型的数据格式相匹配的特定尺寸或形状。
此文本分类应用接受字符串作为输入,并且模型专门在英语语料库上进行训练。推断过程中会忽略特殊字符和非英语单词。
向模型提供文本数据:
使用
init块调用initClassifier函数。在示例应用中,init位于 TextClassificationHelper.kt 中:init { initClassifier() }
运行预测
在您的 Android 应用中,初始化 BertNLClassifier 或 NLClassifier 对象后,就可以开始为模型提供输入文本以将其分类为“正面”或“负面”。
要运行预测,请执行以下操作:
创建一个
classify函数,该函数使用所选分类器 (currentModel) 并测量对输入文本进行分类所花费的时间 (inferenceTime)。在示例应用中,classify函数位于 TextClassificationHelper.kt 中:fun classify(text: String) { executor = ScheduledThreadPoolExecutor(1) executor.execute { val results: List<Category> // inferenceTime is the amount of time, in milliseconds, that it takes to // classify the input text. var inferenceTime = SystemClock.uptimeMillis() // Use the appropriate classifier based on the selected model if(currentModel == MOBILEBERT) { results = bertClassifier.classify(text) } else { results = nlClassifier.classify(text) } inferenceTime = SystemClock.uptimeMillis() - inferenceTime listener.onResult(results, inferenceTime) } }将
classify的结果传递给侦听器对象。fun classify(text: String) { ... listener.onResult(results, inferenceTime) }
处理模型输出
输入一行文本后,模型会为“正面”和“负面”类别生成一个介于 0 和 1 之间、以浮点数表示的预测分数。
要从模型获取预测结果,请执行以下操作:
为侦听器对象创建一个
onResult函数来处理输出。在示例应用中,侦听器对象位于 MainActivity.kt 中private val listener = object : TextClassificationHelper.TextResultsListener { override fun onResult(results: List<Category>, inferenceTime: Long) { runOnUiThread { activityMainBinding.bottomSheetLayout.inferenceTimeVal.text = String.format("%d ms", inferenceTime) adapter.resultsList = results.sortedByDescending { it.score } adapter.notifyDataSetChanged() } } ... }向侦听器对象添加一个
onError函数来处理错误:private val listener = object : TextClassificationHelper.TextResultsListener { ... override fun onError(error: String) { Toast.makeText(this@MainActivity, error, Toast.LENGTH_SHORT).show() } }
一旦模型返回一组预测结果,您的应用就可以根据预测执行操作,将结果呈现给用户或执行其他逻辑。示例应用会在用户界面中列出预测分数。
后续步骤
- 要从头开始训练和实现模型,请参阅使用 TensorFlow Lite Model Maker 进行文本分类教程。
- 探索更多适用于 TensorFlow 的文本处理工具。
- 在 TensorFlow Hub 上下载其他 BERT 模型。
- 在示例中探索 TensorFlow Lite 的各种用法。
- 在模型部分中详细了解如何在 TensorFlow Lite 中使用机器学习模型。
- 在 TensorFlow Lite 开发者指南中详细了解如何在您的移动应用中实现机器学习。