

La tâche d'identification de ce que représente un audio est appelée classification audio . Un modèle de classification audio est entraîné pour reconnaître divers événements audio. Par exemple, vous pouvez entraîner un modèle à reconnaître des événements représentant trois événements différents : applaudir, claquer des doigts et taper. TensorFlow Lite fournit des modèles pré-entraînés optimisés que vous pouvez déployer dans vos applications mobiles. Apprenez-en plus sur la classification audio à l'aide de TensorFlow ici .
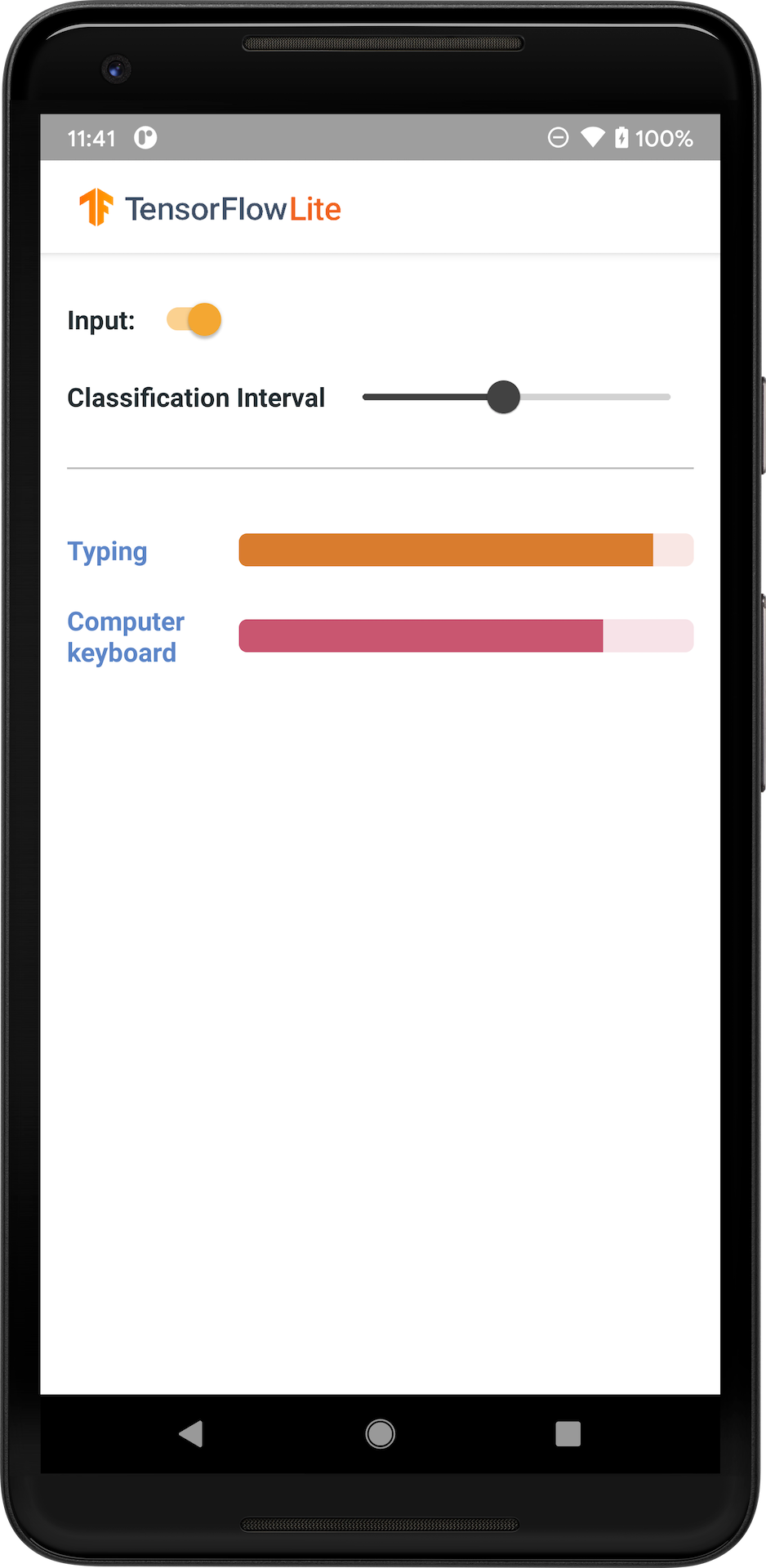
L'image suivante montre la sortie du modèle de classification audio sur Android.
Commencer
Si vous êtes nouveau sur TensorFlow Lite et que vous travaillez avec Android, nous vous recommandons d'explorer les exemples d'applications suivants qui peuvent vous aider à démarrer.
Vous pouvez tirer parti de l'API prête à l'emploi de la bibliothèque de tâches TensorFlow Lite pour intégrer des modèles de classification audio en quelques lignes de code seulement. Vous pouvez également créer votre propre pipeline d'inférence personnalisé à l'aide de la bibliothèque de support TensorFlow Lite .
L'exemple Android ci-dessous montre l'implémentation à l'aide de la bibliothèque de tâches TFLite
Si vous utilisez une plate-forme autre qu'Android/iOS, ou si vous connaissez déjà les API TensorFlow Lite , téléchargez le modèle de démarrage et les fichiers de support (le cas échéant).
Télécharger le modèle de démarrage depuis TensorFlow Hub
Description du modèle
YAMNet est un classificateur d'événements audio qui prend la forme d'onde audio en entrée et effectue des prédictions indépendantes pour chacun des 521 événements audio de l'ontologie AudioSet . Le modèle utilise l'architecture MobileNet v1 et a été formé à l'aide du corpus AudioSet. Ce modèle a été initialement publié dans TensorFlow Model Garden, où se trouvent le code source du modèle, le point de contrôle du modèle d'origine et une documentation plus détaillée.
Comment ça fonctionne
Il existe deux versions du modèle YAMNet converties en TFLite :
YAMNet est le modèle de classification audio original, avec une taille d'entrée dynamique, adapté au déploiement par transfert d'apprentissage, Web et mobile. Il a également un résultat plus complexe.
YAMNet/classification est une version quantifiée avec une entrée de trame de longueur fixe plus simple (15 600 échantillons) et renvoie un seul vecteur de scores pour 521 classes d'événements audio.
Contributions
Le modèle accepte un tableau Tensor ou NumPy 1-D float32 de longueur 15 600 contenant une forme d'onde de 0,975 seconde représentée sous forme d'échantillons mono de 16 kHz dans la plage [-1.0, +1.0] .
Les sorties
Le modèle renvoie un tenseur de forme float32 2D (1 521) contenant les scores prédits pour chacune des 521 classes de l'ontologie AudioSet prises en charge par YAMNet. L'index de colonne (0-520) du tenseur de scores est mappé au nom de classe AudioSet correspondant à l'aide du mappage de classe YAMNet, qui est disponible sous forme de fichier associé yamnet_label_list.txt intégré dans le fichier modèle. Voir ci-dessous pour l'utilisation.
Utilisations appropriées
YAMNet peut être utilisé
- en tant que classificateur d'événements audio autonome qui fournit une base de référence raisonnable pour une grande variété d'événements audio.
- en tant qu'extracteur de fonctionnalités de haut niveau : la sortie d'intégration 1024-D de YAMNet peut être utilisée comme fonctionnalités d'entrée d'un autre modèle qui peut ensuite être entraîné sur une petite quantité de données pour une tâche particulière. Cela permet de créer rapidement des classificateurs audio spécialisés sans nécessiter beaucoup de données étiquetées et sans avoir à former un grand modèle de bout en bout.
- comme début à chaud : les paramètres du modèle YAMNet peuvent être utilisés pour initialiser une partie d'un modèle plus grand, ce qui permet un réglage fin et une exploration du modèle plus rapides.
Limites
- Les sorties du classificateur de YAMNet n'ont pas été étalonnées entre les classes, vous ne pouvez donc pas traiter directement les sorties comme des probabilités. Pour une tâche donnée, vous devrez très probablement effectuer un étalonnage avec des données spécifiques à la tâche qui vous permettront d'attribuer des seuils de score et une mise à l'échelle appropriés par classe.
- YAMNet a été formé sur des millions de vidéos YouTube et, bien que celles-ci soient très diverses, il peut toujours y avoir une inadéquation de domaine entre la vidéo YouTube moyenne et les entrées audio attendues pour une tâche donnée. Vous devez vous attendre à effectuer certains réglages et étalonnages pour rendre YAMNet utilisable dans n'importe quel système que vous construisez.
Personnalisation du modèle
Les modèles pré-entraînés fournis sont formés pour détecter 521 classes audio différentes. Pour une liste complète des classes, consultez le fichier labels dans le référentiel modèle .
Vous pouvez utiliser une technique appelée apprentissage par transfert pour recycler un modèle afin qu'il reconnaisse les classes qui ne figurent pas dans l'ensemble d'origine. Par exemple, vous pouvez réentraîner le modèle pour qu'il détecte plusieurs chants d'oiseaux. Pour ce faire, vous aurez besoin d’un ensemble d’audios de formation pour chacune des nouvelles étiquettes que vous souhaitez former. La méthode recommandée consiste à utiliser la bibliothèque TensorFlow Lite Model Maker qui simplifie le processus de formation d'un modèle TensorFlow Lite à l'aide d'un ensemble de données personnalisé, en quelques lignes de codes. Il utilise l'apprentissage par transfert pour réduire la quantité de données et le temps de formation requis. Vous pouvez également apprendre de l’apprentissage par transfert pour la reconnaissance audio comme exemple d’apprentissage par transfert.
Lectures complémentaires et ressources
Utilisez les ressources suivantes pour en savoir plus sur les concepts liés à la classification audio :