
エージェントを相手にボードゲームをします。エージェントは、強化学習を使用してトレーニングされ、TensorFlow Lite でデプロイされています。
はじめに
TensorFlow Lite を初めて使用する場合、Android を使用する場合は、以下のサンプルアプリをご覧ください。
Android 以外のプラットフォームを使用する場合、または、すでに TensorFlow Lite API に精通している場合は、トレーニング済みモデルをダウンロードできます。
使い方
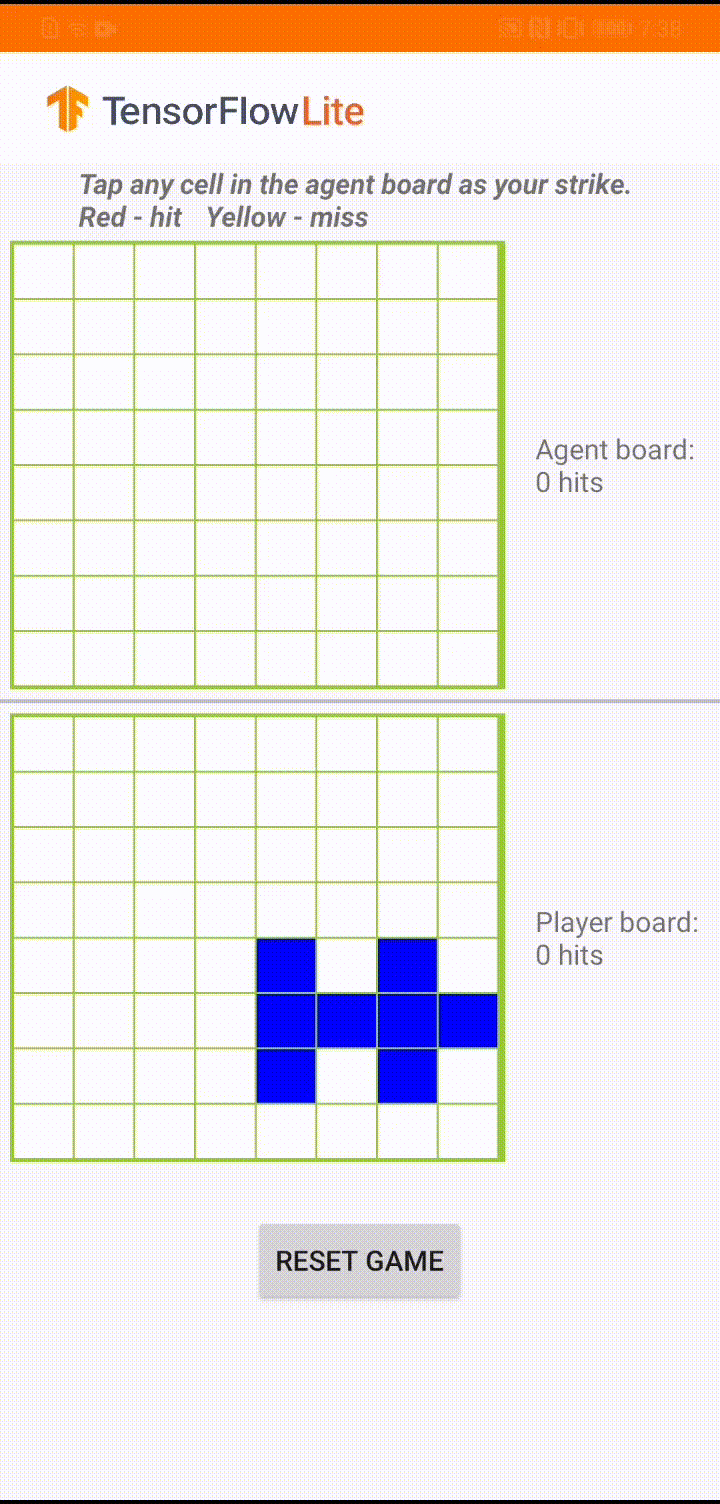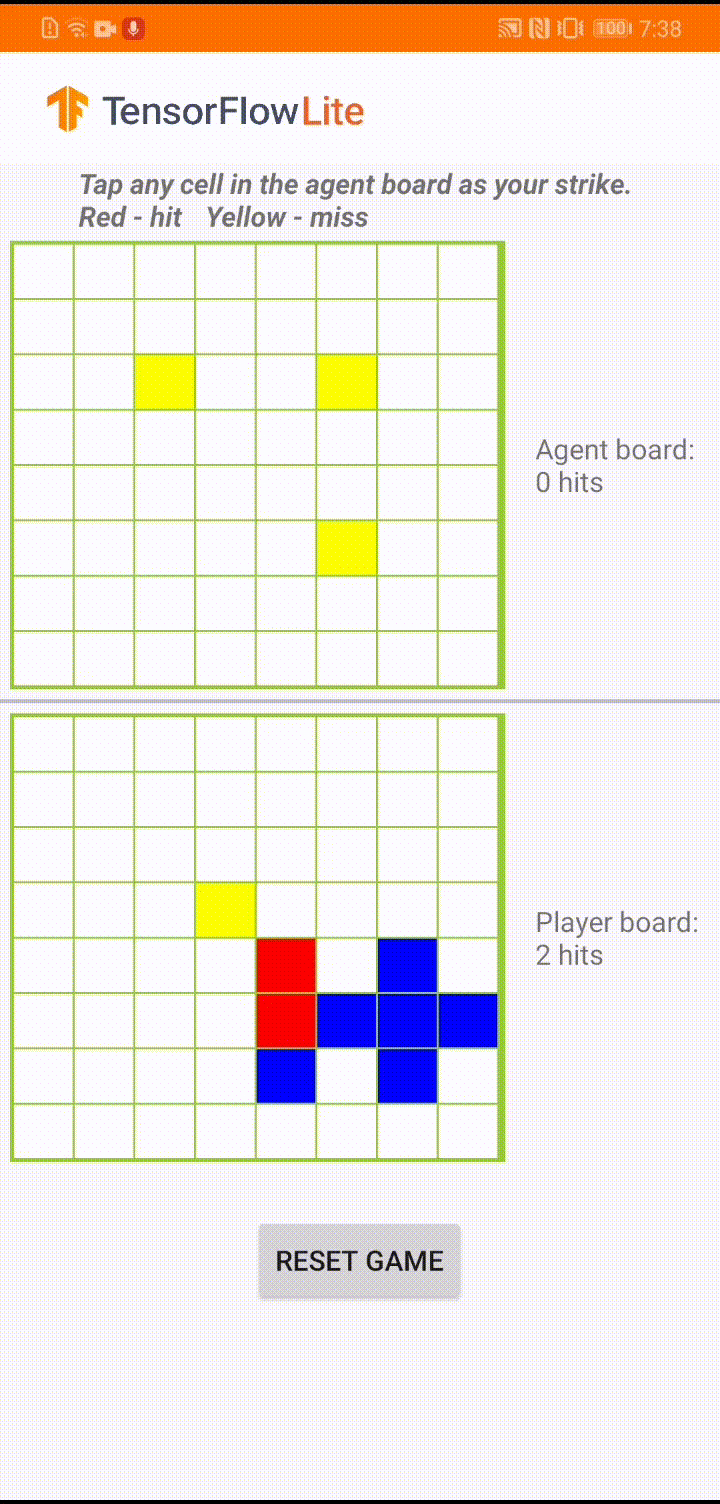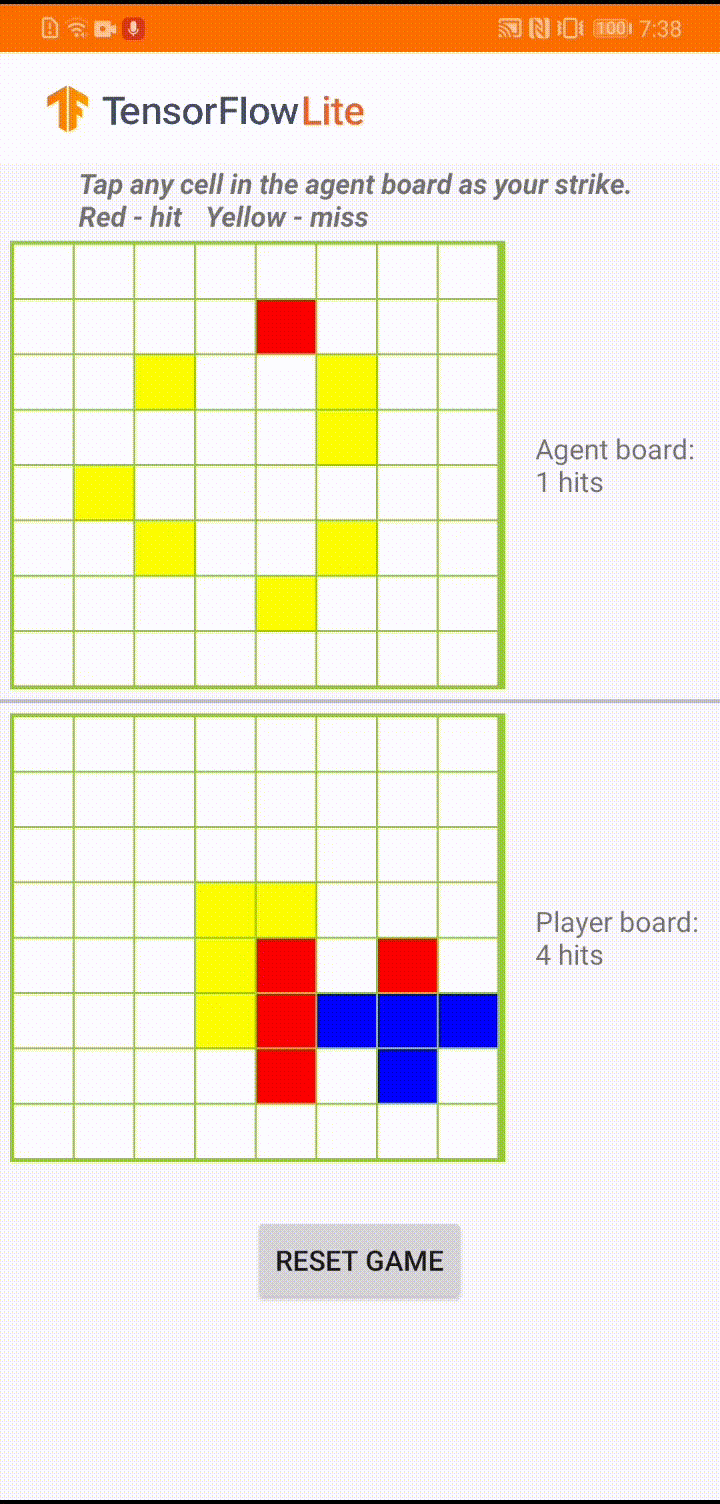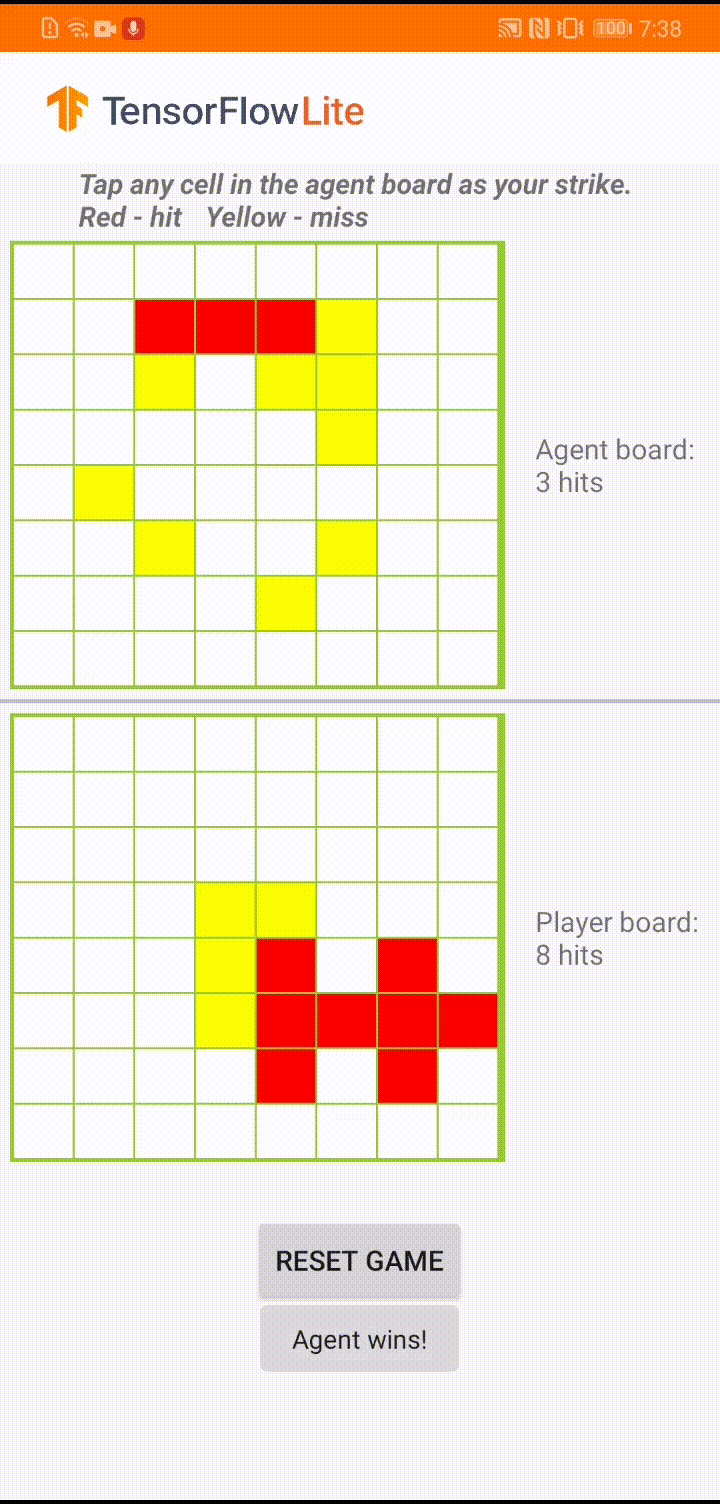
ゲームエージェントが「Plane Strike」という小さいボードゲームをするためのモデルが構築されています。このゲームの簡単な概要とルールについては、README を参照してください。
アプリの UI の基盤には、人間のプレイヤーと対戦するエージェントが構築されています。エージェントは 3 層 MLP であり、ボードの状態を入力値として受け取り、64 のボードのマスのそれぞれに対して予測されたスコアを出力します。モデルは、方策勾配 (REINFORCE) を使用してトレーニングされています。トレーニングコードについては、こちらを参照してください。エージェントをトレーニングした後は、モデルを TFLite に変換し、Android アプリでデプロイします。
Android アプリでの実際のゲーム中、エージェントの番になると、エージェントは人間の対戦相手のボード状態 (下部のボード) を確認します。このボード状態には、以前の成功と失敗 (当たりと外れ) に関する情報が含まれています。そして、トレーニング済みのモデルを使用して、次に狙う場所を予測し、人間の対戦相手よりも早くゲームを終わらせることができるようにします。
パフォーマンスベンチマーク
パフォーマンスベンチマークの数値は、ここで説明するツールで生成されます。
| モデル名 | モデルサイズ | デバイス | CPU |
|---|---|---|---|
| 方策勾配 | 84 Kb | Pixel 3 (Android 10) | 0.01ms* |
| Pixel 4 (Android 10) | 0.01ms* |
- 1 つのスレッドを使用。
入力
モデルでは、(1, 8, 8) の 3-D float32 テンソルをボード状態として入力できます。
出力
モデルは、64 の考えられる候補それぞれに対して、形状 (1,64) の 2-D float32 テンソルを予測スコアとして返します。
モデルのトレーニング
トレーニングコードで BOARD_SIZE パラメータを変更すると、大きい/小さいボードの独自のモデルをトレーニングできます。