
Learn how to integrate Responsible AI practices into your ML workflow using TensorFlow
TensorFlow is committed to helping make progress in the responsible development of AI by sharing a collection of resources and tools with the ML community.

What is Responsible AI?
The development of AI is creating new opportunities to solve challenging, real-world problems. It is also raising new questions about the best way to build AI systems that benefit everyone.

Recommended best practices for AI
Designing AI systems should follow software development best practices while taking a human-centered
approach to ML

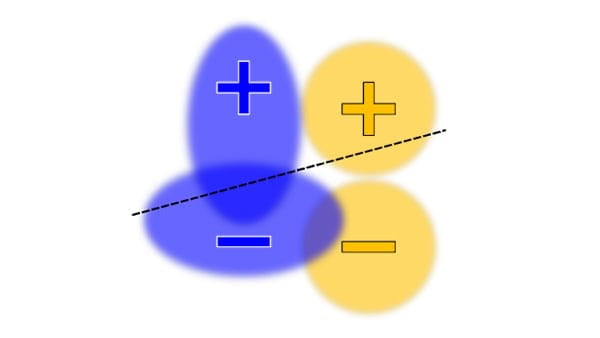
Fairness
As the impact of AI increases across sectors and societies, it is critical to work towards systems that are fair and inclusive to everyone

Interpretability
Understanding and trusting AI systems is important to ensuring they are working as intended

Privacy
Training models off of sensitive data needs privacy preserving safeguards

Security
Identifying potential threats can help keep AI systems safe and secure
Responsible AI in your ML workflow
Responsible AI practices can be incorporated at every step of the ML workflow. Here are some key questions to consider at each stage.
Who is my ML system for?
The way actual users experience your system is essential to assessing the true impact of its predictions, recommendations, and decisions. Make sure to get input from a diverse set of users early on in your development process.
Am I using a representative dataset?
Is your data sampled in a way that represents your users (e.g. will be
used for all ages, but you only have training data from senior citizens)
and the real-world setting (e.g. will be used year-round, but you only
have training data from the summer)?
Is there real-world/human bias in my data?
Underlying biases in data can contribute to complex feedback loops that reinforce existing stereotypes.
What methods should I use to train my model?
Use training methods that build fairness, interpretability, privacy, and
security into the model.
How is my model performing?
Evaluate user experience in real-world scenarios across a broad spectrum of users, use cases, and contexts of use. Test and iterate in dogfood first, followed by continued testing after launch.
Are there complex feedback loops?
Even if everything in the overall system design is carefully crafted, ML-based models rarely operate with 100% perfection when applied to real, live data. When an issue occurs in a live product, consider whether it aligns with any existing societal disadvantages, and how it will be impacted by both short- and long-term solutions.
Responsible AI tools for TensorFlow
The TensorFlow ecosystem has a suite of tools and resources to help tackle some of the questions above.
Define problem
Use the following resources to design models with Responsible AI in mind.

Learn more about the AI development process and key considerations.
Explore, via interactive visualizations, key questions and concepts in the realm of Responsible AI.
Construct and prepare data
Use the following tools to examine data for potential biases.
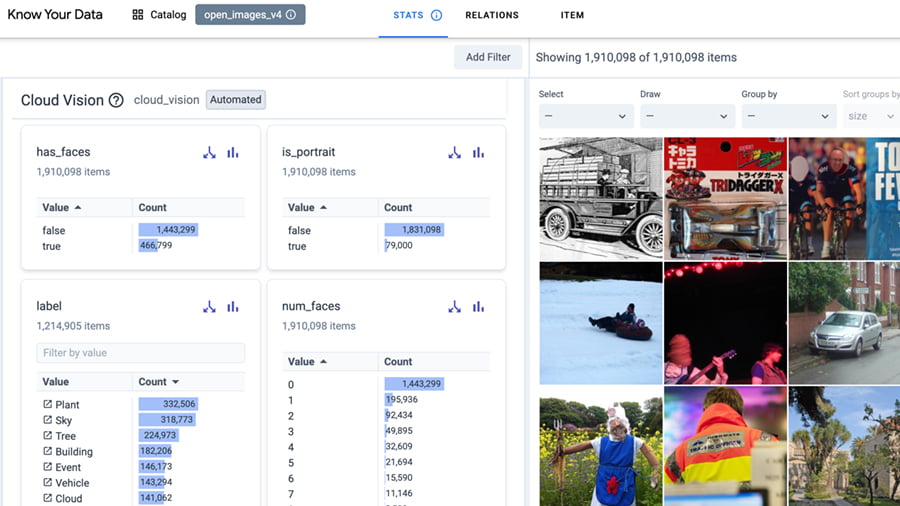
Interactively investigate your dataset to improve data quality and mitigate fairness and bias issues.
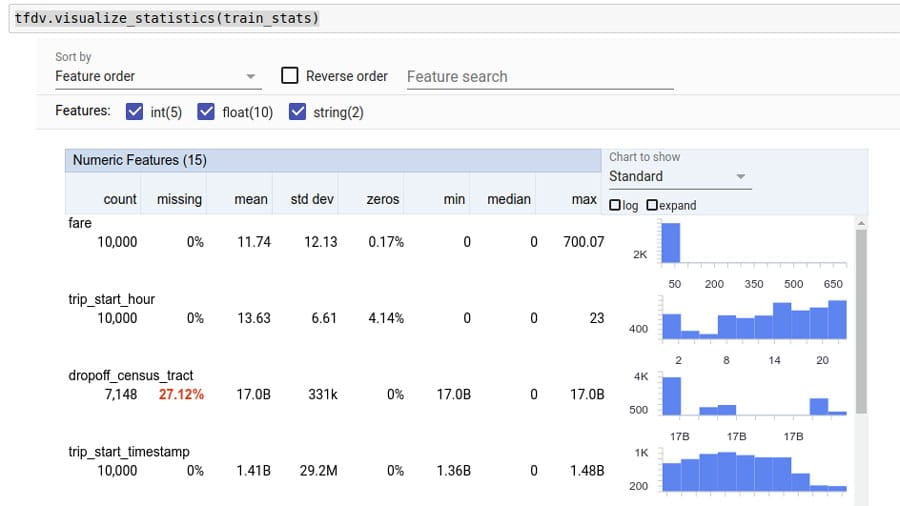
Analyze and transform data to detect problems and engineer more effective feature sets.


A more inclusive skin tone scale, open licensed, to make your data collection and model building needs more robust and inclusive.
Build and train model
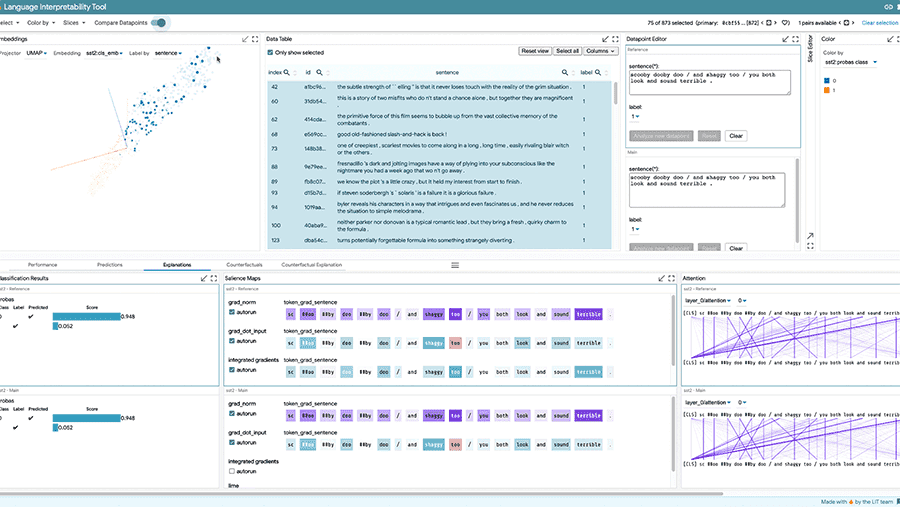
Use the following tools to train models using privacy-preserving, interpretable techniques, and more.

Evaluate model
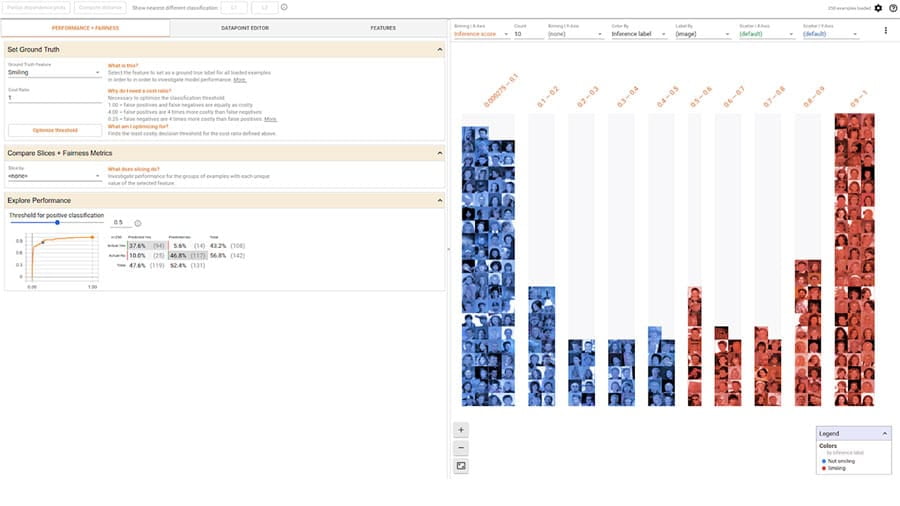
Debug, evaluate, and visualize model performance using the following tools.
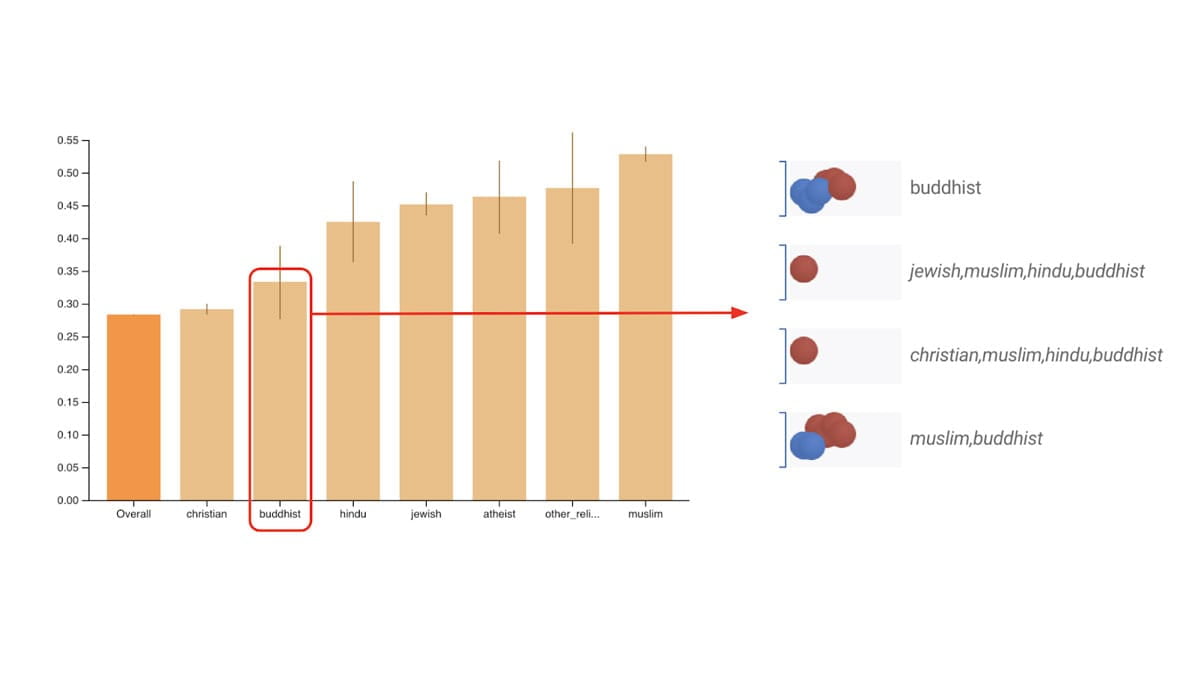
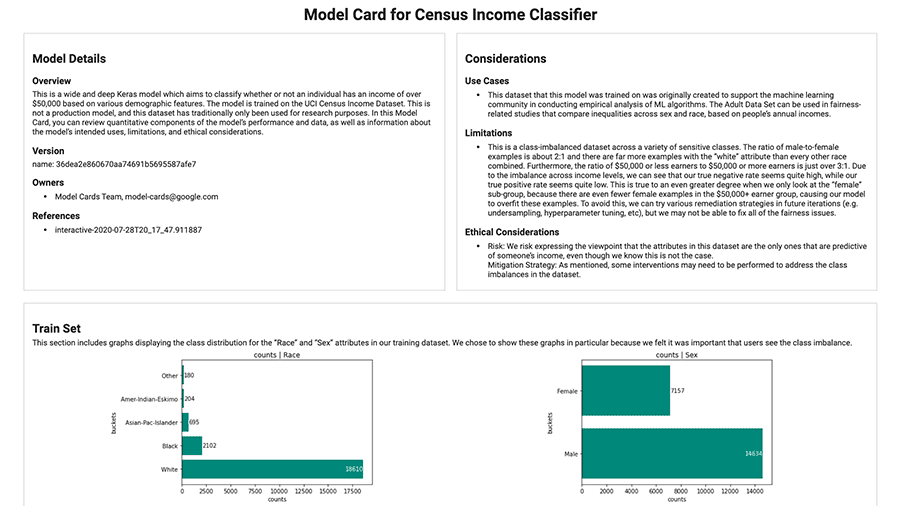
Evaluate commonly-identified fairness metrics for binary and multi-class classifiers.
Evaluate models in a distributed manner and compute over different slices of data.


Deploy and monitor
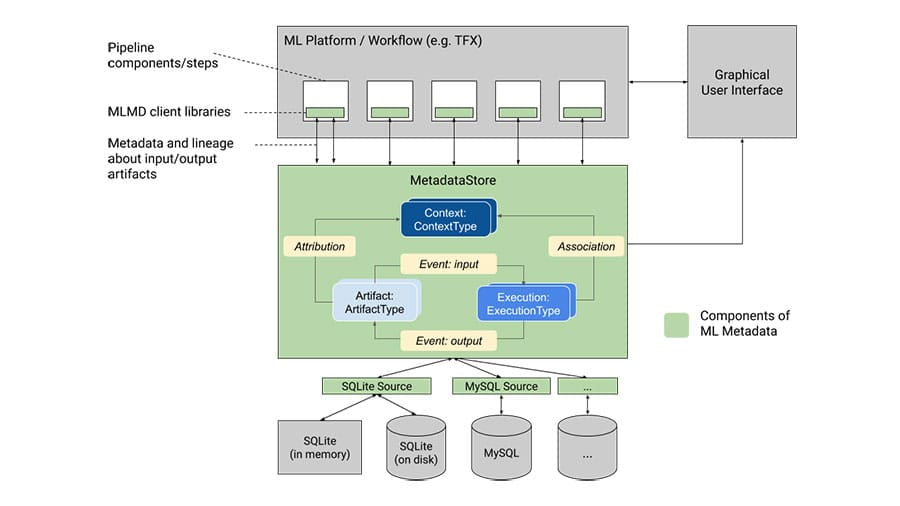
Use the following tools to track and communicate about model context and details.
Community resources
Learn what the community is doing and explore ways to get involved.

Help Google's products become more inclusive and representative of your language, region and culture.

We asked participants to use TensorFlow 2.2 to build a model or application with Responsible AI principles in mind. Check out the gallery to see the winners and other amazing projects.

Introducing a framework to think about ML, fairness and privacy.