
| | |  در GitHub مشاهده کنید در GitHub مشاهده کنید | | |
این آموزش حاوی کد کامل برای تنظیم دقیق BERT برای انجام تجزیه و تحلیل احساسات بر روی مجموعه داده ای از نقدهای متن ساده فیلم IMDB است. علاوه بر آموزش یک مدل، یاد خواهید گرفت که چگونه متن را در قالبی مناسب پردازش کنید.
در این دفترچه یادداشت خواهید داشت:
- مجموعه داده های IMDB را بارگیری کنید
- یک مدل BERT را از TensorFlow Hub بارگیری کنید
- مدل خود را با ترکیب BERT با یک طبقه بندی بسازید
- مدل خود را آموزش دهید و BERT را به عنوان بخشی از آن تنظیم کنید
- مدل خود را ذخیره کنید و از آن برای طبقه بندی جملات استفاده کنید
اگر شما تازه به کار با مجموعه داده IMDB هستید، لطفا طبقه بندی متن عمومی برای جزئیات بیشتر.
درباره BERT
برت و دیگر معماری ترانسفورماتور رمزگذار در انواع کارهای در NLP (پردازش زبان طبیعی) شدید موفق بوده است. آنها بازنمایی های فضای برداری از زبان طبیعی را محاسبه می کنند که برای استفاده در مدل های یادگیری عمیق مناسب است. خانواده مدلهای BERT از معماری رمزگذار ترانسفورماتور برای پردازش هر نشانه متن ورودی در متن کامل همه نشانهها قبل و بعد استفاده میکنند، از این رو نام: بازنمایی رمزگذار دوطرفه از ترانسفورماتورها.
مدلهای BERT معمولاً روی مجموعه بزرگی از متن از قبل آموزش داده میشوند، سپس برای کارهای خاص تنظیم میشوند.
برپایی
# A dependency of the preprocessing for BERT inputspip install -q -U tensorflow-text
شما خواهید بهینه ساز AdamW از استفاده tensorflow / مدل .
pip install -q tf-models-official
import os
import shutil
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_text as text
from official.nlp import optimization # to create AdamW optimizer
import matplotlib.pyplot as plt
tf.get_logger().setLevel('ERROR')
/tmpfs/src/tf_docs_env/lib/python3.7/site-packages/pkg_resources/__init__.py:119: PkgResourcesDeprecationWarning: 0.18ubuntu0.18.04.1 is an invalid version and will not be supported in a future release PkgResourcesDeprecationWarning,
تحلیل احساسات
این نوت بوک آموزش یک مدل تجزیه و تحلیل احساسات به بررسی فیلم طبقه بندی به عنوان مثبت یا منفی، بر اساس متن نظر.
شما با استفاده از بزرگ فیلم نقد و بررسی مجموعه داده است که شامل متن 50000 بررسی فیلم از بانک اطلاعات اینترنتی فیلمها .
مجموعه داده های IMDB را دانلود کنید
بیایید مجموعه داده را دانلود و استخراج کنیم، سپس ساختار دایرکتوری را بررسی کنیم.
url = 'https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz'
dataset = tf.keras.utils.get_file('aclImdb_v1.tar.gz', url,
untar=True, cache_dir='.',
cache_subdir='')
dataset_dir = os.path.join(os.path.dirname(dataset), 'aclImdb')
train_dir = os.path.join(dataset_dir, 'train')
# remove unused folders to make it easier to load the data
remove_dir = os.path.join(train_dir, 'unsup')
shutil.rmtree(remove_dir)
Downloading data from https://ai.stanford.edu/~amaas/data/sentiment/aclImdb_v1.tar.gz 84131840/84125825 [==============================] - 7s 0us/step 84140032/84125825 [==============================] - 7s 0us/step
بعد، شما را به استفاده از text_dataset_from_directory ابزار برای ایجاد یک برچسب tf.data.Dataset .
مجموعه داده های IMDB قبلاً به دو دسته آموزش و آزمایش تقسیم شده است، اما فاقد مجموعه اعتبارسنجی است. بیایید ایجاد یک مجموعه اعتبار با استفاده از یک 80:20 تقسیم از داده های آموزشی با استفاده از validation_split استدلال زیر کلیک کنید.
AUTOTUNE = tf.data.AUTOTUNE
batch_size = 32
seed = 42
raw_train_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='training',
seed=seed)
class_names = raw_train_ds.class_names
train_ds = raw_train_ds.cache().prefetch(buffer_size=AUTOTUNE)
val_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/train',
batch_size=batch_size,
validation_split=0.2,
subset='validation',
seed=seed)
val_ds = val_ds.cache().prefetch(buffer_size=AUTOTUNE)
test_ds = tf.keras.utils.text_dataset_from_directory(
'aclImdb/test',
batch_size=batch_size)
test_ds = test_ds.cache().prefetch(buffer_size=AUTOTUNE)
Found 25000 files belonging to 2 classes. Using 20000 files for training. Found 25000 files belonging to 2 classes. Using 5000 files for validation. Found 25000 files belonging to 2 classes.
بیایید نگاهی به چند بررسی بیندازیم.
for text_batch, label_batch in train_ds.take(1):
for i in range(3):
print(f'Review: {text_batch.numpy()[i]}')
label = label_batch.numpy()[i]
print(f'Label : {label} ({class_names[label]})')
Review: b'"Pandemonium" is a horror movie spoof that comes off more stupid than funny. Believe me when I tell you, I love comedies. Especially comedy spoofs. "Airplane", "The Naked Gun" trilogy, "Blazing Saddles", "High Anxiety", and "Spaceballs" are some of my favorite comedies that spoof a particular genre. "Pandemonium" is not up there with those films. Most of the scenes in this movie had me sitting there in stunned silence because the movie wasn\'t all that funny. There are a few laughs in the film, but when you watch a comedy, you expect to laugh a lot more than a few times and that\'s all this film has going for it. Geez, "Scream" had more laughs than this film and that was more of a horror film. How bizarre is that?<br /><br />*1/2 (out of four)' Label : 0 (neg) Review: b"David Mamet is a very interesting and a very un-equal director. His first movie 'House of Games' was the one I liked best, and it set a series of films with characters whose perspective of life changes as they get into complicated situations, and so does the perspective of the viewer.<br /><br />So is 'Homicide' which from the title tries to set the mind of the viewer to the usual crime drama. The principal characters are two cops, one Jewish and one Irish who deal with a racially charged area. The murder of an old Jewish shop owner who proves to be an ancient veteran of the Israeli Independence war triggers the Jewish identity in the mind and heart of the Jewish detective.<br /><br />This is were the flaws of the film are the more obvious. The process of awakening is theatrical and hard to believe, the group of Jewish militants is operatic, and the way the detective eventually walks to the final violent confrontation is pathetic. The end of the film itself is Mamet-like smart, but disappoints from a human emotional perspective.<br /><br />Joe Mantegna and William Macy give strong performances, but the flaws of the story are too evident to be easily compensated." Label : 0 (neg) Review: b'Great documentary about the lives of NY firefighters during the worst terrorist attack of all time.. That reason alone is why this should be a must see collectors item.. What shocked me was not only the attacks, but the"High Fat Diet" and physical appearance of some of these firefighters. I think a lot of Doctors would agree with me that,in the physical shape they were in, some of these firefighters would NOT of made it to the 79th floor carrying over 60 lbs of gear. Having said that i now have a greater respect for firefighters and i realize becoming a firefighter is a life altering job. The French have a history of making great documentary\'s and that is what this is, a Great Documentary.....' Label : 1 (pos) 2021-12-01 12:17:32.795514: W tensorflow/core/kernels/data/cache_dataset_ops.cc:768] The calling iterator did not fully read the dataset being cached. In order to avoid unexpected truncation of the dataset, the partially cached contents of the dataset will be discarded. This can happen if you have an input pipeline similar to `dataset.cache().take(k).repeat()`. You should use `dataset.take(k).cache().repeat()` instead.
بارگیری مدل ها از TensorFlow Hub
در اینجا می توانید انتخاب کنید که کدام مدل BERT را از TensorFlow Hub بارگیری کنید و آن را تنظیم کنید. چندین مدل BERT موجود است.
- برت پایه ، Uncased و هفت مدل با وزن آموزش دیده منتشر شده توسط نویسندگان برت اصلی است.
- BERTs کوچک دارند همان معماری کلی اما کمتر و / یا بلوک ترانسفورماتور کوچکتر، که به شما اجازه مبادلات بین سرعت، اندازه و کیفیت اکتشاف.
- آلبرت : چهار اندازه مختلف از "A بازگشت به محتوا | برت" است که باعث کاهش اندازه مدل (اما نه زمان محاسبه) با به اشتراک گذاشتن پارامترهای بین لایه.
- برت کارشناسان : هشت مدل که همه معماری برت پایه اما ارائه یک انتخاب بین حوزه های قبل از آموزش های مختلف، به چین بیشتر از نزدیک با کار مورد نظر.
- الکترا است همان معماری برت (در سه اندازه مختلف)، اما می شود قبل از آموزش دیده به عنوان یک ممیز در یک مجموعه به بالا که شبیه به یک خصمانه شبکه زایشی (GAN).
- برت با صحبت کردن سر توجه و دردار از Gelu [ پایه ، بزرگ ] دو بهبود به هسته از معماری ترانسفورماتور.
مستندات مدل در TensorFlow Hub دارای جزئیات و ارجاعات بیشتری به ادبیات تحقیق است. دنبال لینک بالا، و یا با کلیک بر روی tfhub.dev URL پس از اعدام سلول بعدی چاپ شده است.
پیشنهاد این است که با یک BERT کوچک (با پارامترهای کمتر) شروع کنید زیرا آنها سریعتر تنظیم می شوند. اگر یک مدل کوچک اما با دقت بالاتر دوست دارید، ALBERT ممکن است گزینه بعدی شما باشد. اگر میخواهید دقت بهتری داشته باشید، یکی از اندازههای BERT کلاسیک یا اصلاحات اخیر آنها مانند Electra، Talking Heads یا یک BERT Expert را انتخاب کنید.
گذشته از مدل های موجود در زیر، وجود دارد نسخه های متعدد از مدل های هستند که بزرگتر و می تواند دقت و حتی عملکرد بهتر، اما آنها خیلی بزرگ می شود، خوب تنظیم بر روی یک GPU تک هستند. شما قادر به انجام این کار بر خواهد بود حل مشکلات GLUE با استفاده از برت در COLAB TPU .
در کد زیر خواهید دید که تغییر URL tfhub.dev برای امتحان هر یک از این مدل ها کافی است، زیرا تمام تفاوت های بین آنها در SavedModels از TF Hub محصور شده است.
یک مدل BERT را برای تنظیم دقیق انتخاب کنید
bert_model_name = 'small_bert/bert_en_uncased_L-4_H-512_A-8'
map_name_to_handle = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_L-12_H-768_A-12/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_L-12_H-768_A-12/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_L-12_H-768_A-12/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-128_A-2/1',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-256_A-4/1',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-512_A-8/1',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-2_H-768_A-12/1',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-128_A-2/1',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-256_A-4/1',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-768_A-12/1',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-128_A-2/1',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-256_A-4/1',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-512_A-8/1',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-6_H-768_A-12/1',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-128_A-2/1',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-256_A-4/1',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-512_A-8/1',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-8_H-768_A-12/1',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-128_A-2/1',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-256_A-4/1',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-512_A-8/1',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-10_H-768_A-12/1',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-128_A-2/1',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-256_A-4/1',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-512_A-8/1',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-12_H-768_A-12/1',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_base/2',
'electra_small':
'https://tfhub.dev/google/electra_small/2',
'electra_base':
'https://tfhub.dev/google/electra_base/2',
'experts_pubmed':
'https://tfhub.dev/google/experts/bert/pubmed/2',
'experts_wiki_books':
'https://tfhub.dev/google/experts/bert/wiki_books/2',
'talking-heads_base':
'https://tfhub.dev/tensorflow/talkheads_ggelu_bert_en_base/1',
}
map_model_to_preprocess = {
'bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_en_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_cased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-2_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-4_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-6_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-8_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-10_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-128_A-2':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-256_A-4':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-512_A-8':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'small_bert/bert_en_uncased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'bert_multi_cased_L-12_H-768_A-12':
'https://tfhub.dev/tensorflow/bert_multi_cased_preprocess/3',
'albert_en_base':
'https://tfhub.dev/tensorflow/albert_en_preprocess/3',
'electra_small':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'electra_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_pubmed':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'experts_wiki_books':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
'talking-heads_base':
'https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3',
}
tfhub_handle_encoder = map_name_to_handle[bert_model_name]
tfhub_handle_preprocess = map_model_to_preprocess[bert_model_name]
print(f'BERT model selected : {tfhub_handle_encoder}')
print(f'Preprocess model auto-selected: {tfhub_handle_preprocess}')
BERT model selected : https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Preprocess model auto-selected: https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3
مدل پیش پردازش
ورودیهای متن باید قبل از وارد شدن به BERT به شناسههای نشانه عددی تبدیل شوند و در چندین تنسور مرتب شوند. TensorFlow Hub یک مدل پیش پردازش منطبق برای هر یک از مدل های BERT که در بالا مورد بحث قرار گرفت ارائه می دهد، که این تبدیل را با استفاده از عملیات TF از کتابخانه TF.text پیاده سازی می کند. برای پیش پردازش متن لازم نیست کدهای خالص پایتون را خارج از مدل TensorFlow خود اجرا کنید.
مدل پیش پردازش باید مدلی باشد که در مستندات مدل BERT به آن اشاره شده است، که می توانید آن را در URL چاپ شده در بالا بخوانید. برای مدل های BERT از منوی کشویی بالا، مدل پیش پردازش به طور خودکار انتخاب می شود.
bert_preprocess_model = hub.KerasLayer(tfhub_handle_preprocess)
بیایید مدل پیش پردازش را روی چند متن امتحان کنیم و خروجی را ببینیم:
text_test = ['this is such an amazing movie!']
text_preprocessed = bert_preprocess_model(text_test)
print(f'Keys : {list(text_preprocessed.keys())}')
print(f'Shape : {text_preprocessed["input_word_ids"].shape}')
print(f'Word Ids : {text_preprocessed["input_word_ids"][0, :12]}')
print(f'Input Mask : {text_preprocessed["input_mask"][0, :12]}')
print(f'Type Ids : {text_preprocessed["input_type_ids"][0, :12]}')
Keys : ['input_word_ids', 'input_mask', 'input_type_ids'] Shape : (1, 128) Word Ids : [ 101 2023 2003 2107 2019 6429 3185 999 102 0 0 0] Input Mask : [1 1 1 1 1 1 1 1 1 0 0 0] Type Ids : [0 0 0 0 0 0 0 0 0 0 0 0]
همانطور که می بینید، در حال حاضر شما باید 3 خروجی از پیش پردازش که یک مدل برت می (استفاده از input_words_id ، input_mask و input_type_ids ).
چند نکته مهم دیگر:
- ورودی به 128 توکن کوتاه شده است. تعداد نشانه می تواند سفارشی، و شما می توانید اطلاعات بیشتر در دید حل مشکلات GLUE با استفاده از برت در COLAB TPU .
-
input_type_idsفقط یک مقدار (0) دارند چرا که این یک ورودی حکم واحد است. برای ورودی چند جمله، برای هر ورودی یک عدد خواهد داشت.
از آنجایی که این پیش پردازشگر متن یک مدل TensorFlow است، می تواند مستقیماً در مدل شما گنجانده شود.
با استفاده از مدل BERT
قبل از قرار دادن BERT در مدل خود، اجازه دهید نگاهی به خروجی های آن بیندازیم. شما آن را از TF Hub بارگیری کرده و مقادیر بازگشتی را مشاهده خواهید کرد.
bert_model = hub.KerasLayer(tfhub_handle_encoder)
bert_results = bert_model(text_preprocessed)
print(f'Loaded BERT: {tfhub_handle_encoder}')
print(f'Pooled Outputs Shape:{bert_results["pooled_output"].shape}')
print(f'Pooled Outputs Values:{bert_results["pooled_output"][0, :12]}')
print(f'Sequence Outputs Shape:{bert_results["sequence_output"].shape}')
print(f'Sequence Outputs Values:{bert_results["sequence_output"][0, :12]}')
Loaded BERT: https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Pooled Outputs Shape:(1, 512) Pooled Outputs Values:[ 0.76262873 0.99280983 -0.1861186 0.36673835 0.15233682 0.65504444 0.9681154 -0.9486272 0.00216158 -0.9877732 0.0684272 -0.9763061 ] Sequence Outputs Shape:(1, 128, 512) Sequence Outputs Values:[[-0.28946388 0.3432126 0.33231565 ... 0.21300787 0.7102078 -0.05771166] [-0.28742015 0.31981024 -0.2301858 ... 0.58455074 -0.21329722 0.7269209 ] [-0.66157013 0.6887685 -0.87432927 ... 0.10877253 -0.26173282 0.47855264] ... [-0.2256118 -0.28925604 -0.07064401 ... 0.4756601 0.8327715 0.40025353] [-0.29824278 -0.27473143 -0.05450511 ... 0.48849759 1.0955356 0.18163344] [-0.44378197 0.00930723 0.07223766 ... 0.1729009 1.1833246 0.07897988]]
مدل های برت بازگشت یک نقشه با 3 کلید مهم: pooled_output ، sequence_output ، encoder_outputs :
-
pooled_outputنشان دهنده هر توالی ورودی به عنوان یک کل. شکل است[batch_size, H]. شما می توانید این را به عنوان یک جاسازی برای کل نقد فیلم در نظر بگیرید. -
sequence_outputنشان دهنده هر ورودی نشانه در زمینه. شکل است[batch_size, seq_length, H]. شما می توانید این را به عنوان یک جاسازی متنی برای هر نشانه در نقد فیلم در نظر بگیرید. -
encoder_outputsفعال سازی میانی هستندLبلوک ترانسفورماتور.outputs["encoder_outputs"][i]یک تانسور شکل است[batch_size, seq_length, 1024]با خروجی از i ام بلوک ترانسفورماتور، برای0 <= i < L. آخرین مقدار از لیست برابر استsequence_output.
برای تنظیم خوب می خواهید به استفاده از pooled_output آرایه.
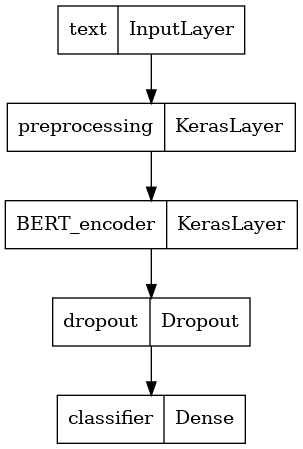
مدل خود را تعریف کنید
شما یک مدل بسیار ساده با تنظیم دقیق، با مدل پیش پردازش، مدل BERT انتخاب شده، یک لایه متراکم و یک لایه Dropout ایجاد خواهید کرد.
def build_classifier_model():
text_input = tf.keras.layers.Input(shape=(), dtype=tf.string, name='text')
preprocessing_layer = hub.KerasLayer(tfhub_handle_preprocess, name='preprocessing')
encoder_inputs = preprocessing_layer(text_input)
encoder = hub.KerasLayer(tfhub_handle_encoder, trainable=True, name='BERT_encoder')
outputs = encoder(encoder_inputs)
net = outputs['pooled_output']
net = tf.keras.layers.Dropout(0.1)(net)
net = tf.keras.layers.Dense(1, activation=None, name='classifier')(net)
return tf.keras.Model(text_input, net)
بیایید بررسی کنیم که مدل با خروجی مدل پیش پردازش اجرا می شود.
classifier_model = build_classifier_model()
bert_raw_result = classifier_model(tf.constant(text_test))
print(tf.sigmoid(bert_raw_result))
tf.Tensor([[0.6749899]], shape=(1, 1), dtype=float32)
البته خروجی بی معنی است، زیرا مدل هنوز آموزش ندیده است.
بیایید نگاهی به ساختار مدل بیندازیم.
tf.keras.utils.plot_model(classifier_model)
آموزش مدل
شما اکنون تمام قطعات را برای آموزش یک مدل دارید، از جمله ماژول پیش پردازش، رمزگذار BERT، داده و طبقهبندی کننده.
عملکرد از دست دادن
از آنجایی که این مشکل طبقه بندی باینری است و مدل خروجی احتمال (یک لایه تک واحدی)، شما با استفاده از losses.BinaryCrossentropy تابع از دست دادن.
loss = tf.keras.losses.BinaryCrossentropy(from_logits=True)
metrics = tf.metrics.BinaryAccuracy()
بهینه ساز
برای تنظیم دقیق، بیایید از همان بهینهسازی استفاده کنیم که BERT در ابتدا با آن آموزش دیده بود: «لحظههای تطبیقی» (آدام). این بهینه ساز به حداقل می رساند از دست دادن پیش بینی می کند و تنظیم از تجزیه وزن (با استفاده از لحظه)، که همچنین به عنوان شناخته شده AdamW .
برای نرخ یادگیری ( init_lr پوسیدگی خطی از یک نرخ یادگیری اولیه پیمان با فاز گرم کردن خطی بیش از 10٪ از آموزش مرحله (پیشوند:)، شما را به همان برنامه به عنوان برت آموزش قبل استفاده num_warmup_steps ). مطابق با مقاله BERT، نرخ یادگیری اولیه برای تنظیم دقیق کمتر است (بهترین 5e-5، 3e-5، 2e-5).
epochs = 5
steps_per_epoch = tf.data.experimental.cardinality(train_ds).numpy()
num_train_steps = steps_per_epoch * epochs
num_warmup_steps = int(0.1*num_train_steps)
init_lr = 3e-5
optimizer = optimization.create_optimizer(init_lr=init_lr,
num_train_steps=num_train_steps,
num_warmup_steps=num_warmup_steps,
optimizer_type='adamw')
بارگذاری مدل BERT و آموزش
با استفاده از classifier_model که قبلا ایجاد شده، شما می توانید این مدل را با از دست دادن، متریک و بهینه ساز کامپایل.
classifier_model.compile(optimizer=optimizer,
loss=loss,
metrics=metrics)
print(f'Training model with {tfhub_handle_encoder}')
history = classifier_model.fit(x=train_ds,
validation_data=val_ds,
epochs=epochs)
Training model with https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1 Epoch 1/5 625/625 [==============================] - 91s 138ms/step - loss: 0.4776 - binary_accuracy: 0.7513 - val_loss: 0.3791 - val_binary_accuracy: 0.8380 Epoch 2/5 625/625 [==============================] - 85s 136ms/step - loss: 0.3266 - binary_accuracy: 0.8547 - val_loss: 0.3659 - val_binary_accuracy: 0.8486 Epoch 3/5 625/625 [==============================] - 86s 138ms/step - loss: 0.2521 - binary_accuracy: 0.8928 - val_loss: 0.3975 - val_binary_accuracy: 0.8518 Epoch 4/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1910 - binary_accuracy: 0.9269 - val_loss: 0.4180 - val_binary_accuracy: 0.8522 Epoch 5/5 625/625 [==============================] - 86s 137ms/step - loss: 0.1509 - binary_accuracy: 0.9433 - val_loss: 0.4641 - val_binary_accuracy: 0.8522
مدل را ارزیابی کنید
بیایید ببینیم که مدل چگونه عمل می کند. دو مقدار برگردانده خواهد شد. از دست دادن (عددی که نشان دهنده خطا است، مقادیر کمتر بهتر است) و دقت.
loss, accuracy = classifier_model.evaluate(test_ds)
print(f'Loss: {loss}')
print(f'Accuracy: {accuracy}')
782/782 [==============================] - 61s 78ms/step - loss: 0.4495 - binary_accuracy: 0.8554 Loss: 0.4494614601135254 Accuracy: 0.8553599715232849
دقت و ضرر را در طول زمان ترسیم کنید
بر اساس History شی بازگردانده شده توسط model.fit() . میتوانید از دست دادن آموزش و اعتبارسنجی را برای مقایسه، و همچنین دقت آموزش و اعتبارسنجی را ترسیم کنید:
history_dict = history.history
print(history_dict.keys())
acc = history_dict['binary_accuracy']
val_acc = history_dict['val_binary_accuracy']
loss = history_dict['loss']
val_loss = history_dict['val_loss']
epochs = range(1, len(acc) + 1)
fig = plt.figure(figsize=(10, 6))
fig.tight_layout()
plt.subplot(2, 1, 1)
# r is for "solid red line"
plt.plot(epochs, loss, 'r', label='Training loss')
# b is for "solid blue line"
plt.plot(epochs, val_loss, 'b', label='Validation loss')
plt.title('Training and validation loss')
# plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.subplot(2, 1, 2)
plt.plot(epochs, acc, 'r', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend(loc='lower right')
dict_keys(['loss', 'binary_accuracy', 'val_loss', 'val_binary_accuracy']) <matplotlib.legend.Legend at 0x7fee7cdb4450>
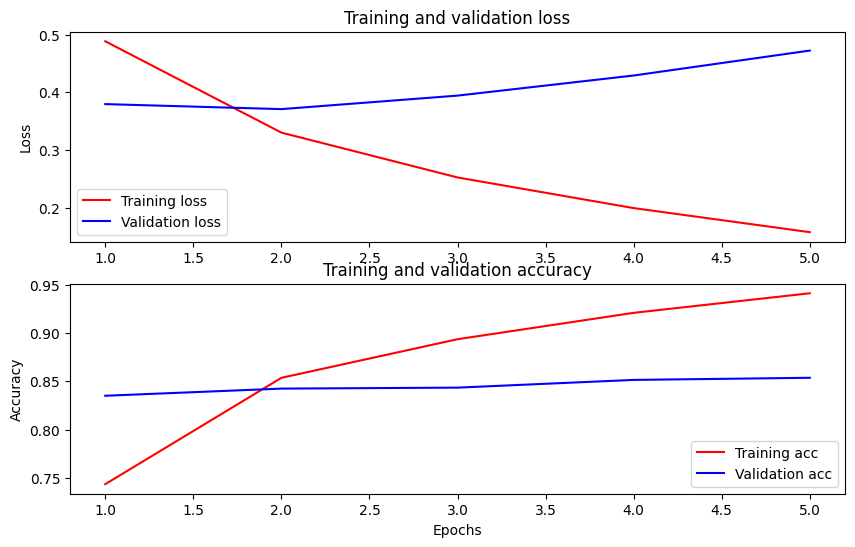
در این نمودار، خطوط قرمز نشان دهنده از دست دادن و دقت تمرین و خطوط آبی نشان دهنده فقدان اعتبار و دقت هستند.
صادرات برای استنتاج
اکنون فقط مدل تنظیم شده خود را برای استفاده بعدی ذخیره کنید.
dataset_name = 'imdb'
saved_model_path = './{}_bert'.format(dataset_name.replace('/', '_'))
classifier_model.save(saved_model_path, include_optimizer=False)
2021-12-01 12:26:06.207608: W tensorflow/python/util/util.cc:368] Sets are not currently considered sequences, but this may change in the future, so consider avoiding using them. WARNING:absl:Found untraced functions such as restored_function_body, restored_function_body, restored_function_body, restored_function_body, restored_function_body while saving (showing 5 of 310). These functions will not be directly callable after loading.
بیایید مدل را دوباره بارگذاری کنیم تا بتوانید آن را در کنار مدلی که هنوز در حافظه است امتحان کنید.
reloaded_model = tf.saved_model.load(saved_model_path)
در اینجا می توانید مدل خود را روی هر جمله ای که می خواهید آزمایش کنید، فقط کافی است به متغیر مثال های زیر اضافه کنید.
def print_my_examples(inputs, results):
result_for_printing = \
[f'input: {inputs[i]:<30} : score: {results[i][0]:.6f}'
for i in range(len(inputs))]
print(*result_for_printing, sep='\n')
print()
examples = [
'this is such an amazing movie!', # this is the same sentence tried earlier
'The movie was great!',
'The movie was meh.',
'The movie was okish.',
'The movie was terrible...'
]
reloaded_results = tf.sigmoid(reloaded_model(tf.constant(examples)))
original_results = tf.sigmoid(classifier_model(tf.constant(examples)))
print('Results from the saved model:')
print_my_examples(examples, reloaded_results)
print('Results from the model in memory:')
print_my_examples(examples, original_results)
Results from the saved model: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622 Results from the model in memory: input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
اگر شما می خواهید به استفاده از مدل خود را در تعمیر و نگهداری TF ، به یاد داشته باشید که آن را SavedModel خود را از طریق یکی از امضا به نام آن است. در پایتون می توانید آنها را به صورت زیر تست کنید:
serving_results = reloaded_model \
.signatures['serving_default'](tf.constant(examples))
serving_results = tf.sigmoid(serving_results['classifier'])
print_my_examples(examples, serving_results)
input: this is such an amazing movie! : score: 0.999521 input: The movie was great! : score: 0.997015 input: The movie was meh. : score: 0.988535 input: The movie was okish. : score: 0.079138 input: The movie was terrible... : score: 0.001622
مراحل بعدی
به عنوان گام بعدی، شما می توانید سعی کنید حل مشکلات GLUE با استفاده از برت در آموزش TPU ، اجرا می شود که در TPU و نشان می دهد شما را چگونه به کار با چند ورودی.