Ferramentas de processamento de texto para o TensorFlow
import tensorflow as tf import tensorflow_text as tf_text def preprocess(vocab_table, example_text): # Normalize text tf_text.normalize_utf8(example_text) # Tokenize into words word_tokenizer = tf_text.WhitespaceTokenizer() tokens = word_tokenizer.tokenize(example_text) # Tokenize into subwords subword_tokenizer = tf_text.WordpieceTokenizer( lookup_table, token_out_type=tf.int64) subtokens = subword_tokenizer.tokenize(tokens).merge_dims(1, -1) # Apply padding padded_inputs = tf_text.pad_model_inputs(subtokens, max_seq_length=16) return padded_inputs
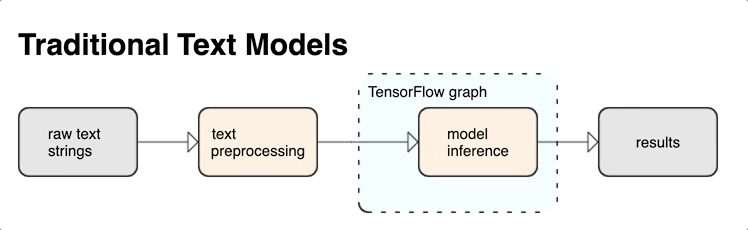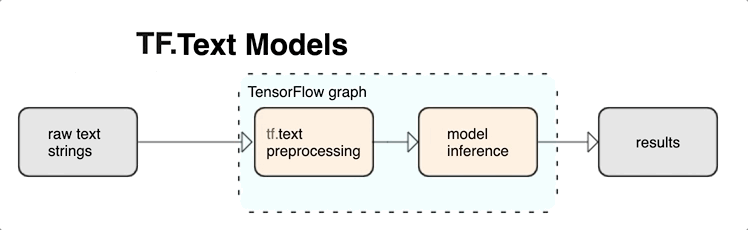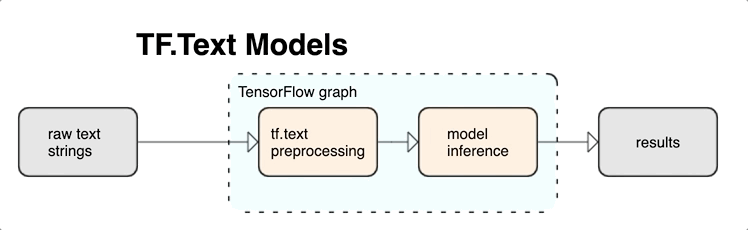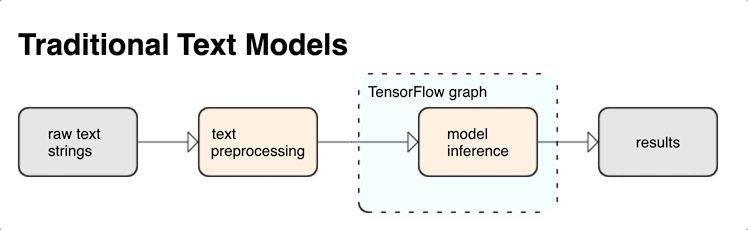
O TensorFlow oferece uma grande coleção de operações e bibliotecas para ajudar você a trabalhar com entradas em forma de texto, como strings ou documentos de texto bruto. Essas bibliotecas podem realizar o pré-processamento regularmente exigido por modelos baseados em texto, e inclui outros recursos úteis para modelagem sequencial.
É possível extrair recursos textuais sintáticos e semânticos avançados de dentro do gráfico do TensorFlow como entrada para sua rede neural.
A integração do pré-processamento com o gráfico do TensorFlow oferece os seguintes benefícios:
- Proporciona várias ferramentas para trabalhar com texto.
- Permite a integração com uma pacote de ferramentas do TensorFlow para oferecer suporte a projetos desde a definição do problema até o treinamento, a avaliação e o lançamento.
- Diminui a complexidade no momento da disponibilização e impede o desvio de treinamento/disponibilização.
Além disso, você não precisa se preocupar com diferenças entre a tokenização no treinamento e na inferência, nem com o gerenciamento de scripts de pré-processamento.