
Visão geral
Visão geral
Este tutorial foi desenvolvido para ajudá-lo a aprender a criar seus próprios pipelines de aprendizado de máquina usando o TensorFlow Extended (TFX) e o Apache Airflow como orquestrador. Ele é executado no Vertex AI Workbench e mostra integração com TFX e TensorBoard, bem como interação com TFX em um ambiente Jupyter Lab.
O que você vai fazer?
Você aprenderá como criar um pipeline de ML usando TFX
- Um pipeline TFX é um gráfico acíclico direcionado, ou "DAG". Frequentemente nos referiremos a pipelines como DAGs.
- Os pipelines TFX são apropriados quando você implanta um aplicativo de ML de produção
- Os pipelines TFX são apropriados quando os conjuntos de dados são grandes ou podem se tornar grandes
- Os pipelines TFX são apropriados quando a consistência de treinamento/serviço é importante
- Os pipelines TFX são apropriados quando o gerenciamento de versão para inferência é importante
- O Google usa pipelines TFX para ML de produção
Consulte o Guia do usuário do TFX para saber mais.
Você seguirá um processo típico de desenvolvimento de ML:
- Ingerindo, compreendendo e limpando nossos dados
- Engenharia de recursos
- Treinamento
- Analisando o desempenho do modelo
- Ensaboar, enxaguar, repetir
- Pronto para produção
Apache Airflow para orquestração de pipeline
Os orquestradores TFX são responsáveis por agendar componentes do pipeline TFX com base nas dependências definidas pelo pipeline. O TFX foi projetado para ser portátil para vários ambientes e estruturas de orquestração. Um dos orquestradores padrão suportados pelo TFX é o Apache Airflow . Este laboratório ilustra o uso do Apache Airflow para orquestração de pipeline TFX. O Apache Airflow é uma plataforma para criar, programar e monitorar fluxos de trabalho de forma programática. O TFX usa o Airflow para criar fluxos de trabalho como gráficos acíclicos direcionados (DAGs) de tarefas. A interface de usuário avançada facilita a visualização de pipelines em execução na produção, monitora o progresso e soluciona problemas quando necessário. Os fluxos de trabalho do Apache Airflow são definidos como código. Isso os torna mais fáceis de manter, versáveis, testáveis e colaborativos. O Apache Airflow é adequado para pipelines de processamento em lote. É leve e fácil de aprender.
Neste exemplo, vamos executar um pipeline TFX em uma instância configurando manualmente o Airflow.
Os outros orquestradores padrão suportados pelo TFX são Apache Beam e Kubeflow. O Apache Beam pode ser executado em vários back-ends de processamento de dados (Beam Ruunners). O Cloud Dataflow é um desses executores de feixe que pode ser usado para executar pipelines TFX. O Apache Beam pode ser usado para streaming e pipelines de processamento em lote.
O Kubeflow é uma plataforma de ML de código aberto dedicada a tornar as implantações de fluxos de trabalho de aprendizado de máquina (ML) no Kubernetes simples, portáteis e escaláveis. O Kubeflow pode ser usado como um orquestrador para pipelines TFFX quando eles precisam ser implantados em clusters Kubernetes. Além disso, você também pode usar seu próprio orquestrador personalizado para executar um pipeline TFX.
Leia mais sobre o Airflow aqui .
Conjunto de dados de táxi de Chicago


Você usará o conjunto de dados Taxi Trips divulgado pela cidade de Chicago.
Objetivo do modelo - classificação binária
O cliente dará uma gorjeta maior ou menor que 20%?
Configurar o projeto do Google Cloud
Antes de clicar no botão Iniciar laboratório Leia estas instruções. Os laboratórios são cronometrados e você não pode pausá-los. O cronômetro, que começa quando você clica em Iniciar laboratório , mostra por quanto tempo os recursos do Google Cloud serão disponibilizados para você.
Este laboratório prático permite que você mesmo faça as atividades de laboratório em um ambiente de nuvem real, não em um ambiente de simulação ou demonstração. Ele faz isso fornecendo credenciais novas e temporárias que você usa para fazer login e acessar o Google Cloud durante o laboratório.
Do que você precisa Para concluir este laboratório, você precisa de:
- Acesso a um navegador de internet padrão (recomenda-se o navegador Chrome).
- Hora de concluir o laboratório.
Como iniciar seu laboratório e fazer login no Console do Google Cloud 1. Clique no botão Iniciar laboratório . Se você precisar pagar pelo laboratório, um pop-up será aberto para você selecionar a forma de pagamento. À esquerda está um painel preenchido com as credenciais temporárias que você deve usar para este laboratório.
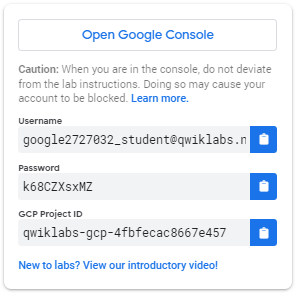
- Copie o nome de usuário e clique em Abrir console do Google . O laboratório aumenta os recursos e, em seguida, abre outra guia que mostra a página Entrar .
Dica: abra as guias em janelas separadas, lado a lado.
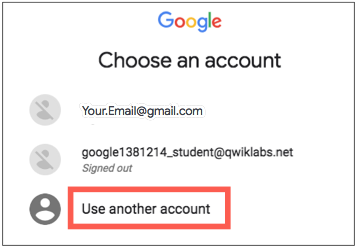
- Na página de login , cole o nome de usuário que você copiou do painel esquerdo. Em seguida, copie e cole a senha.
- Clique nas páginas seguintes:
- Aceite os termos e condições.
Não adicione opções de recuperação ou autenticação de dois fatores (porque esta é uma conta temporária).
Não se inscreva para testes gratuitos.
Após alguns instantes, o Cloud Console é aberto nesta guia.
Ative o Cloud Shell
O Cloud Shell é uma máquina virtual carregada com ferramentas de desenvolvimento. Ele oferece um diretório inicial persistente de 5 GB e é executado no Google Cloud. O Cloud Shell fornece acesso de linha de comando aos seus recursos do Google Cloud.
No Cloud Console, na barra de ferramentas superior direita, clique no botão Ativar Cloud Shell .
Clique em Continuar .
Demora alguns momentos para provisionar e se conectar ao ambiente. Quando você está conectado, você já está autenticado e o projeto está definido para seu _PROJECT ID . Por exemplo:

gcloud é a ferramenta de linha de comando do Google Cloud. Ele vem pré-instalado no Cloud Shell e oferece suporte ao preenchimento de guias.
Você pode listar o nome da conta ativa com este comando:
gcloud auth list
(Resultado)
ATIVO: * CONTA: aluno-01-xxxxxxxxxxxx@qwiklabs.net Para definir a conta ativa, execute: $ gcloud config set account
ACCOUNT
Você pode listar o ID do projeto com este comando: gcloud config list project (Output)
[núcleo] projeto =
(saída de exemplo)
[core] projeto = qwiklabs-gcp-44776a13dea667a6
Para obter a documentação completa do gcloud, consulte a visão geral da ferramenta de linha de comando gcloud .
Ativar os serviços do Google Cloud
- No Cloud Shell, use gcloud para habilitar os serviços usados no laboratório.
gcloud services enable notebooks.googleapis.com
Implantar instância do Vertex Notebook
- Clique no menu de navegação e navegue até Vertex AI e, em seguida, até Workbench .
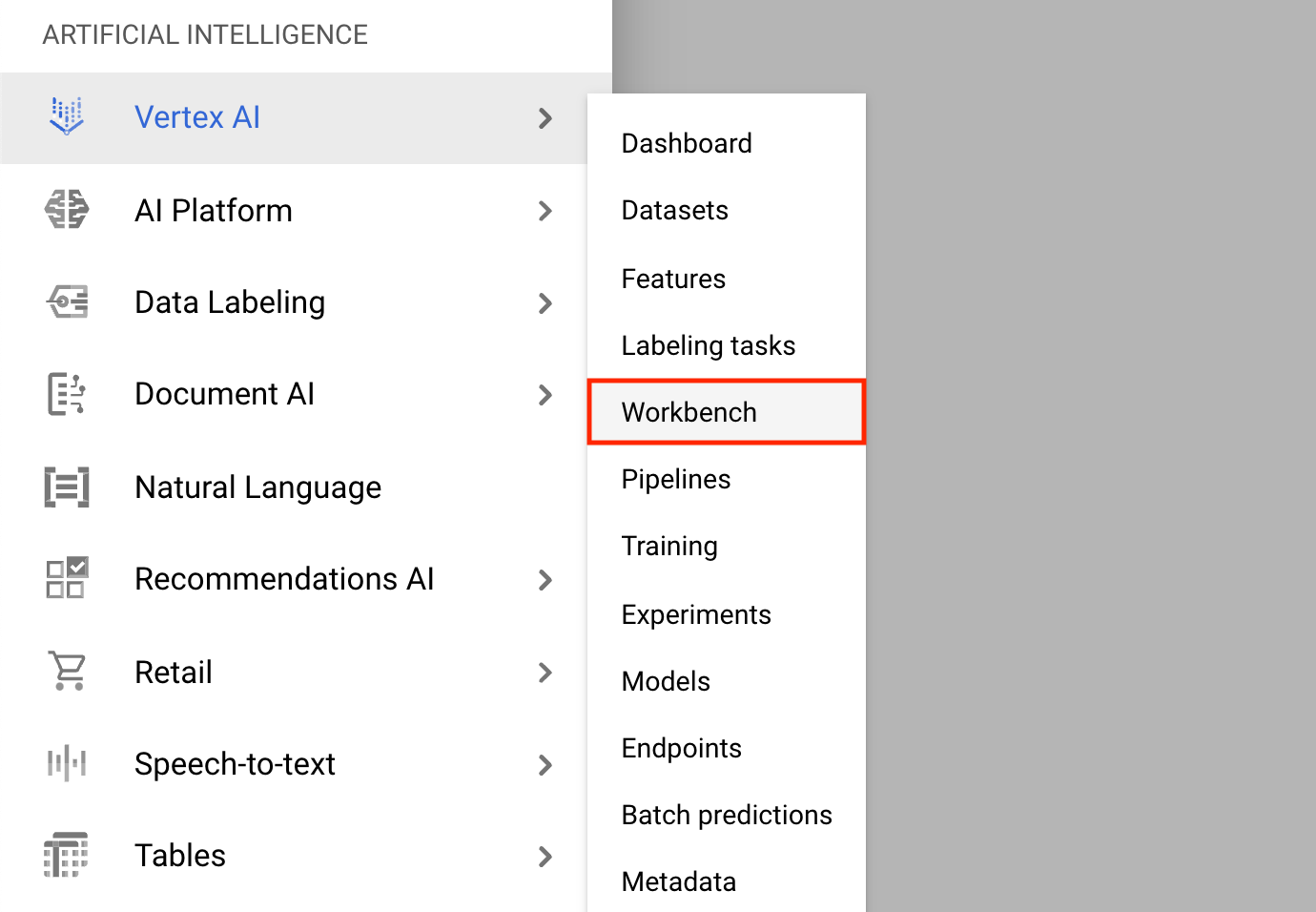
Na página Instâncias de notebook, clique em Novo notebook .
No menu Personalizar instância, selecione TensorFlow Enterprise e escolha a versão do TensorFlow Enterprise 2.x (com LTS) > Sem GPUs .
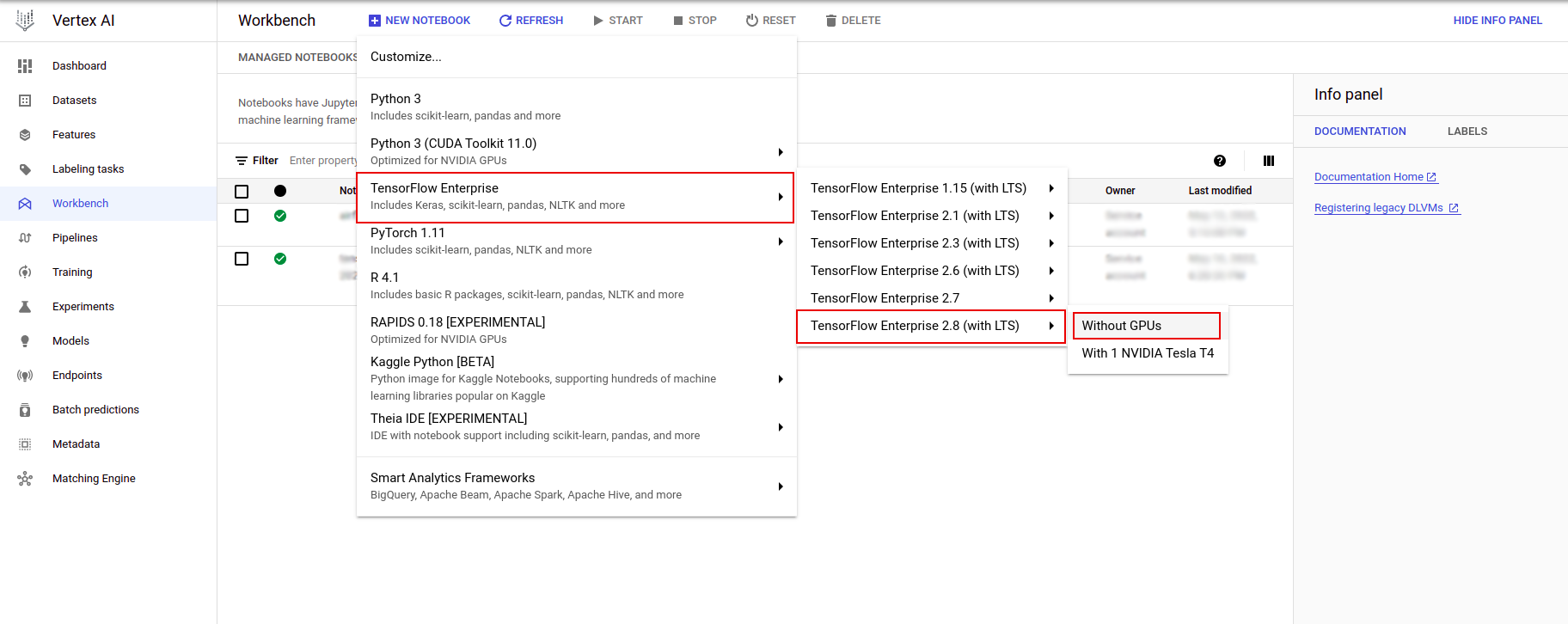
Na caixa de diálogo Nova instância de notebook , clique no ícone de lápis para Editar as propriedades da instância.
Em Instance name , insira um nome para sua instância.
Para Region , selecione
us-east1e para Zone , selecione uma zona dentro da região selecionada.Role para baixo até Machine configuration e selecione e2-standard-2 para Machine type.
Deixe os campos restantes com seus padrões e clique em Criar .
Após alguns minutos, o console do Vertex AI exibirá o nome da sua instância, seguido por Open Jupyterlab .
- Clique em Abrir JupyterLab . Uma janela do JupyterLab será aberta em uma nova guia.
Configure o ambiente
Clonar o repositório do laboratório
Em seguida, você tfx o repositório tfx em sua instância do JupyterLab. 1. No JupyterLab, clique no ícone Terminal para abrir um novo terminal.
Cancel para Build Recomendado.
- Para clonar o repositório
tfxGithub, digite o seguinte comando e pressione Enter .
git clone https://github.com/tensorflow/tfx.git
- Para confirmar que você clonou o repositório, clique duas vezes no diretório
tfxe confirme que você pode ver seu conteúdo.
Instalar dependências do laboratório
- Execute o seguinte para acessar a
tfx/tfx/examples/airflow_workshop/taxi/setup/e execute./setup_demo.shpara instalar as dependências do laboratório:
cd ~/tfx/tfx/examples/airflow_workshop/taxi/setup/
./setup_demo.sh
O código acima irá
- Instale os pacotes necessários.
- Crie uma pasta de
airflowde ar na pasta inicial. - Copie a pasta
dagsda pastatfx/tfx/examples/airflow_workshop/taxi/setup/para~/airflow/pasta. - Copie o arquivo csv de
tfx/tfx/examples/airflow_workshop/taxi/setup/datapara~/airflow/data.
Configurando o servidor Airflow
Crie uma regra de firewall para acessar o servidor airflow no navegador
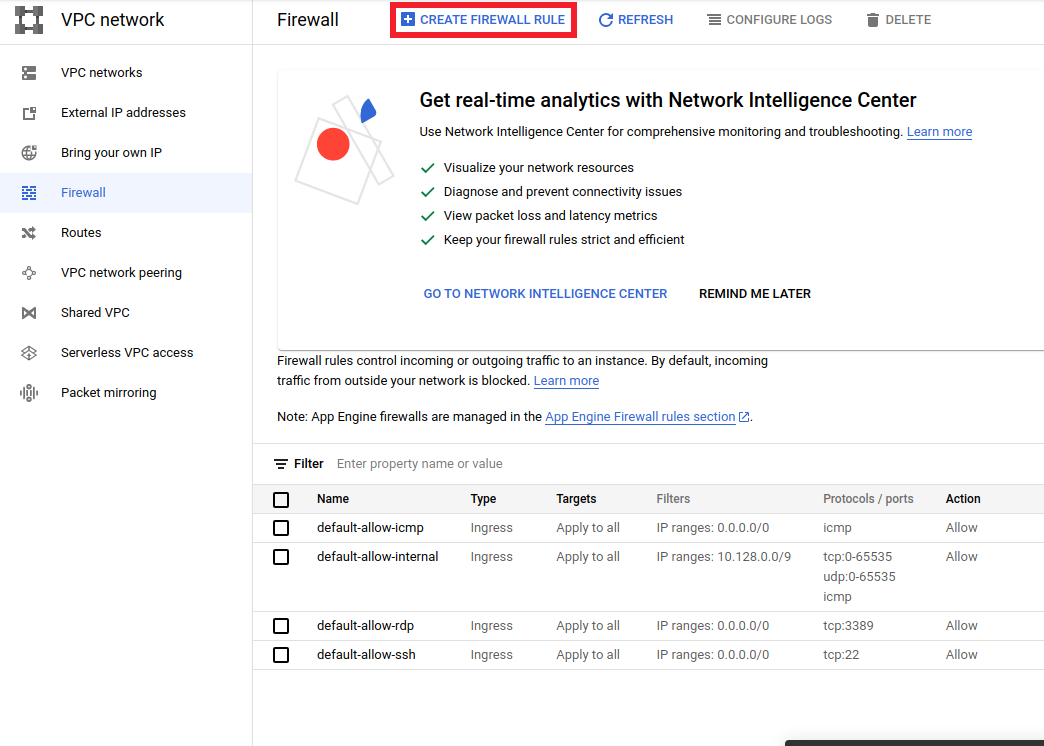
- Vá para
<a href="https://console.cloud.google.com/networking/firewalls/list">https://console.cloud.google.com/networking/firewalls/list</a>e certifique-se o nome do projeto é selecionado apropriadamente - Clique na opção
CREATE FIREWALL RULEna parte superior
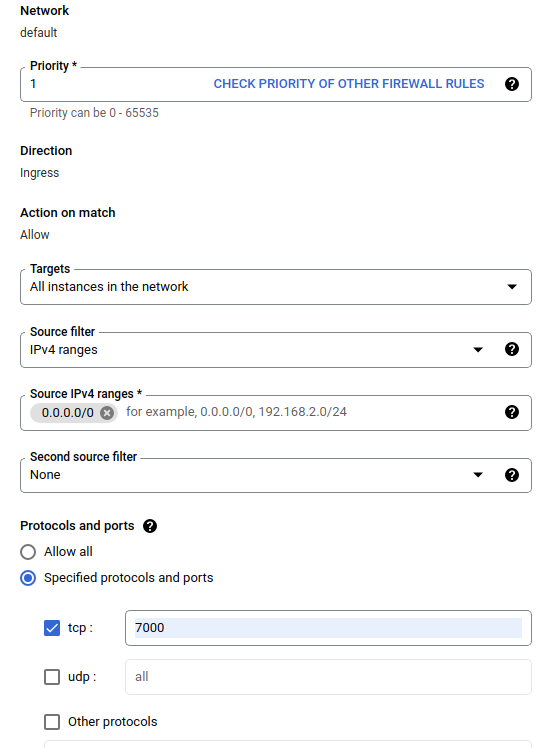
Na caixa de diálogo Criar um firewall , siga as etapas listadas abaixo.
- Para Name , coloque
airflow-tfx. - Para Prioridade , selecione
1. - Para Destinos , selecione
All instances in the network. - Para intervalos IPv4 de origem , selecione
0.0.0.0/0 - Para Protocolos e portas , clique em
tcpe digite7000na caixa ao lado detcp - Clique
Create.
Execute o servidor airflow a partir do seu shell
Na janela Jupyter Lab Terminal, mude para o diretório inicial, execute o comando airflow users create para criar um usuário administrador para o Airflow:
cd
airflow users create --role Admin --username admin --email admin --firstname admin --lastname admin --password admin
Em seguida, execute o comando airflow webserver e airflow scheduler para executar o servidor. Escolha a porta 7000 , pois ela é permitida pelo firewall.
nohup airflow webserver -p 7000 &> webserver.out &
nohup airflow scheduler &> scheduler.out &
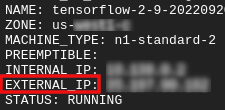
Obtenha seu ip externo
- No Cloud Shell, use
gcloudpara obter o IP externo.
gcloud compute instances list
Como executar um DAG/pipeline
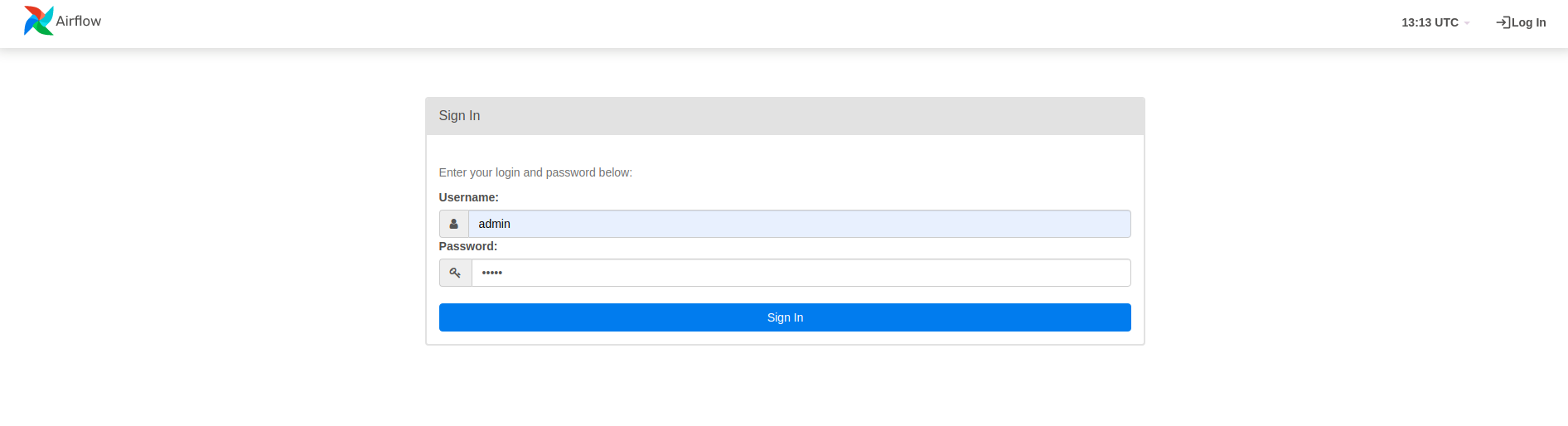
Em um navegador
Abra um navegador e acesse http://
- Na página de login, digite o nome de usuário (
admin) e a senha (admin) que você escolheu ao executar o comandoairflow users create.
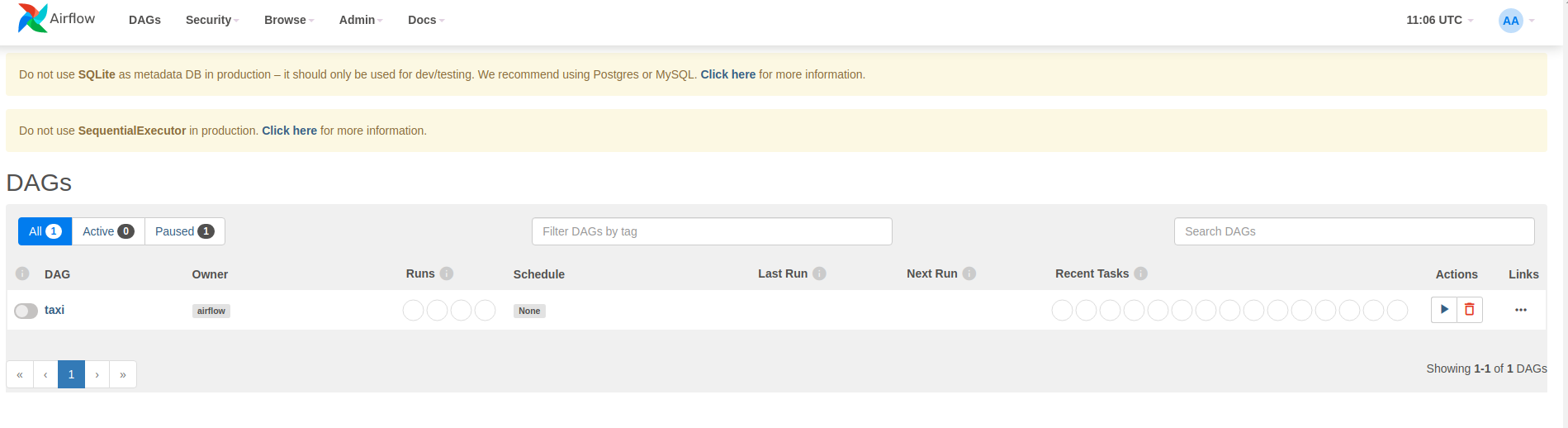
O Airflow carrega DAGs de arquivos de origem do Python. Ele pega cada arquivo e o executa. Em seguida, ele carrega todos os objetos DAG desse arquivo. Todos os arquivos .py que definem objetos DAG serão listados como pipelines na página inicial do airflow.
Neste tutorial, o Airflow verifica a pasta ~/airflow/dags/ em busca de objetos DAG.
Se você abrir ~/airflow/dags/taxi_pipeline.py e rolar até o final, verá que ele cria e armazena um objeto DAG em uma variável chamada DAG . Portanto, ele será listado como um pipeline na página inicial do fluxo de ar, conforme mostrado abaixo:
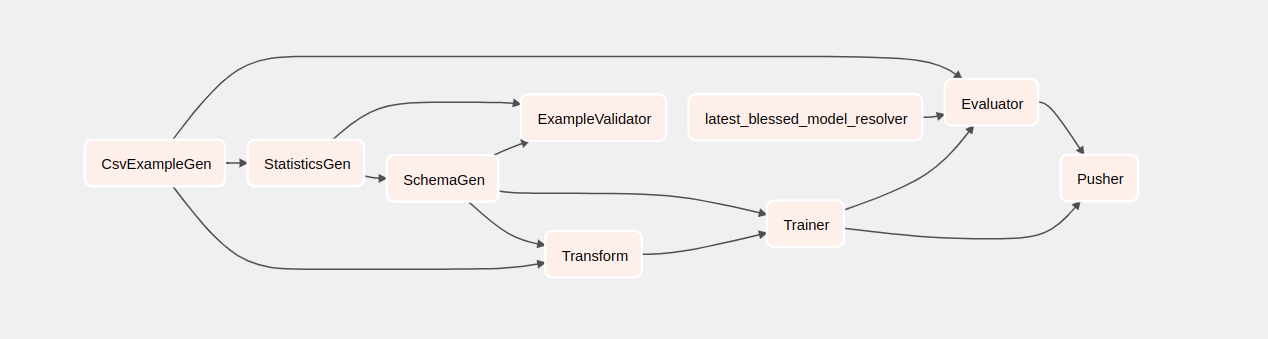
Se você clicar em táxi, será redirecionado para a visualização em grade do DAG. Você pode clicar na opção Graph na parte superior para obter a visualização do gráfico do DAG.
Acionar o pipeline de táxi
Na página inicial você pode ver os botões que podem ser usados para interagir com o DAG.
Sob o cabeçalho de ações , clique no botão de acionamento para acionar o pipeline.
Na página taxi DAG , use o botão à direita para atualizar o estado da exibição do gráfico do DAG conforme o pipeline é executado. Além disso, você pode habilitar a atualização automática para instruir o Airflow a atualizar automaticamente a exibição do gráfico quando o estado mudar.
Você também pode usar a CLI do Airflow no terminal para habilitar e acionar seus DAGs:
# enable/disable
airflow pause <your DAG name>
airflow unpause <your DAG name>
# trigger
airflow trigger_dag <your DAG name>
Aguardando a conclusão do pipeline
Depois de acionar seu pipeline, na exibição DAGs, você pode observar o progresso de seu pipeline enquanto ele está em execução. À medida que cada componente é executado, a cor do contorno do componente no gráfico DAG muda para mostrar seu estado. Quando um componente terminar de processar, o contorno ficará verde escuro para mostrar que está pronto.
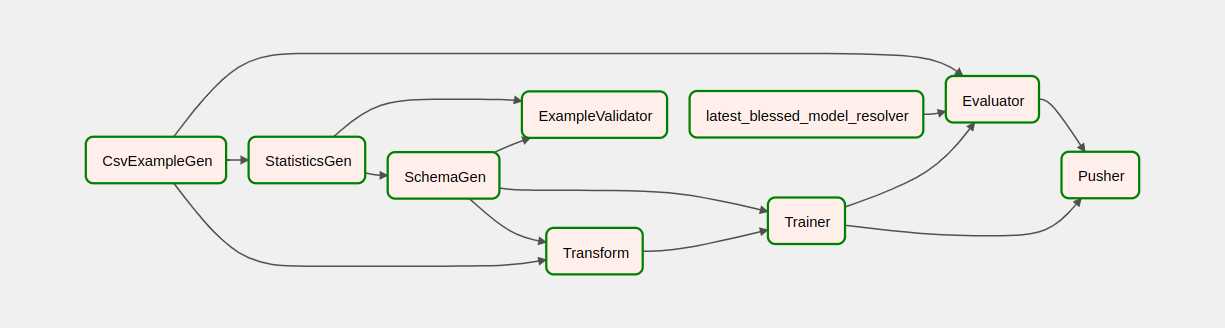
Entendendo os componentes
Agora veremos os componentes desse pipeline em detalhes e veremos individualmente as saídas produzidas por cada etapa do pipeline.
No JupyterLab, vá para
~/tfx/tfx/examples/airflow_workshop/taxi/notebooks/Abra notebook.ipynb.

Continue o laboratório no bloco de anotações e execute cada célula clicando no botão Executar (
 ) ícone na parte superior da tela. Como alternativa, você pode executar o código em uma célula com SHIFT + ENTER .
) ícone na parte superior da tela. Como alternativa, você pode executar o código em uma célula com SHIFT + ENTER .
Leia a narrativa e certifique-se de entender o que está acontecendo em cada célula.