
Introduction
Ce didacticiel est conçu pour présenter TensorFlow Extended (TFX) et AIPlatform Pipelines et vous aider à apprendre à créer vos propres pipelines de machine learning sur Google Cloud. Il montre l'intégration avec TFX, AI Platform Pipelines et Kubeflow, ainsi que l'interaction avec TFX dans les notebooks Jupyter.
À la fin de ce didacticiel, vous aurez créé et exécuté un pipeline ML, hébergé sur Google Cloud. Vous pourrez visualiser les résultats de chaque exécution et visualiser la lignée des artefacts créés.
Vous suivrez un processus de développement ML typique, en commençant par l'examen de l'ensemble de données et en terminant par un pipeline fonctionnel complet. En cours de route, vous découvrirez des moyens de déboguer et de mettre à jour votre pipeline, ainsi que de mesurer les performances.
Ensemble de données sur les taxis de Chicago


Vous utilisez l' ensemble de données Taxi Trips publié par la ville de Chicago.
Vous pouvez en savoir plus sur l'ensemble de données dans Google BigQuery . Explorez l'ensemble de données complet dans l' interface utilisateur BigQuery .
Objectif du modèle - Classification binaire
Le client donnera-t-il un pourboire supérieur ou inférieur à 20 % ?
1. Configurer un projet Google Cloud
1.a Configurez votre environnement sur Google Cloud
Pour commencer, vous avez besoin d'un compte Google Cloud. Si vous en avez déjà un, passez directement à Créer un nouveau projet .
Accédez à la console Google Cloud .
Accepter les conditions générales de Google Cloud
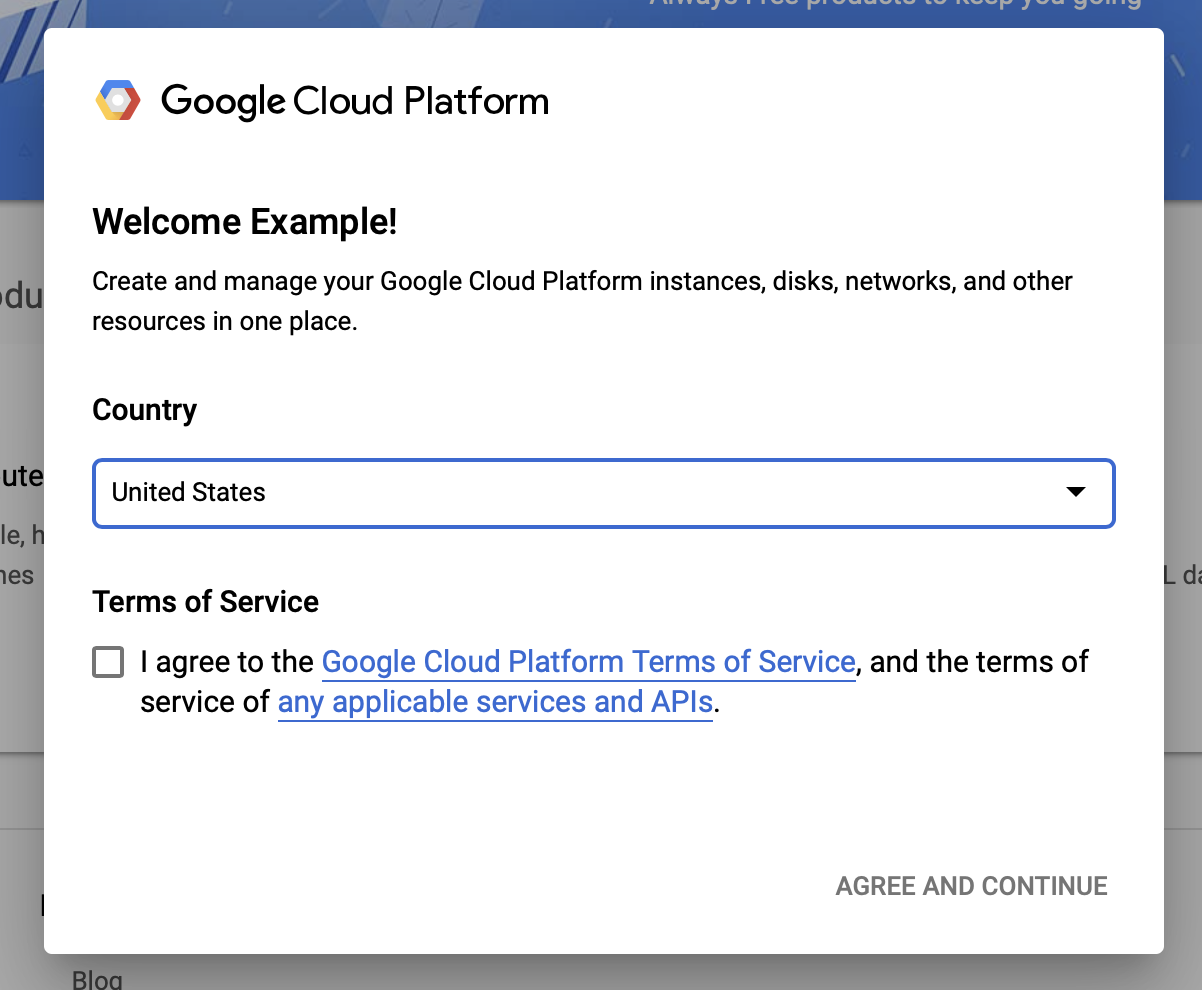
Si vous souhaitez démarrer avec un compte d'essai gratuit, cliquez sur Essayez gratuitement (ou Commencez gratuitement ).
Sélectionnez votre pays.
Acceptez les conditions de service.
Saisissez les détails de facturation.
Vous ne serez pas facturé à ce stade. Si vous n'avez aucun autre projet Google Cloud, vous pouvez suivre ce didacticiel sans dépasser les limites de l'offre gratuite de Google Cloud , qui incluent un maximum de 8 cœurs exécutés en même temps.
1.b Créez un nouveau projet.
- Dans le tableau de bord principal de Google Cloud , cliquez sur la liste déroulante du projet à côté de l'en-tête de Google Cloud Platform , puis sélectionnez Nouveau projet .
- Donnez un nom à votre projet et entrez d'autres détails du projet
- Une fois que vous avez créé un projet, assurez-vous de le sélectionner dans la liste déroulante des projets.
2. Configurer et déployer un pipeline AI Platform sur un nouveau cluster Kubernetes
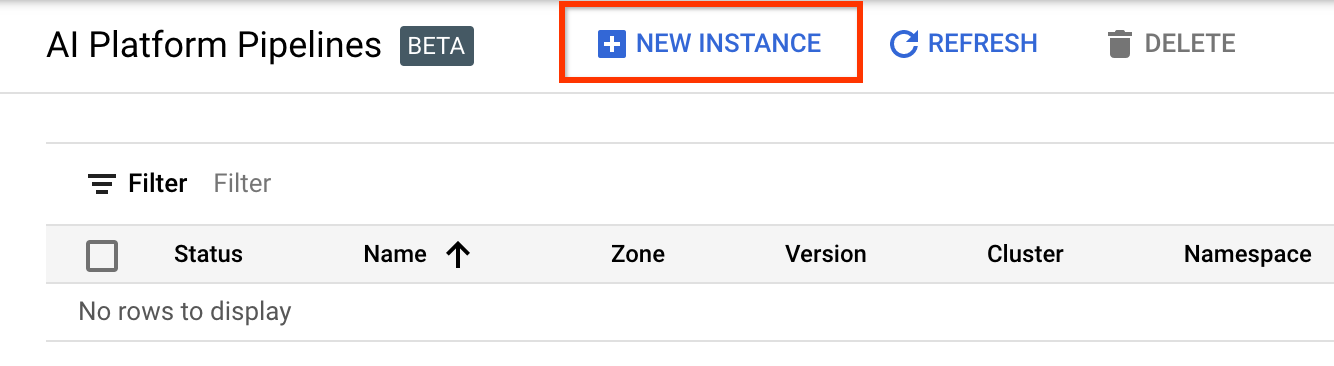
Accédez à la page des clusters de pipelines AI Platform .
Dans le menu de navigation principal : ≡ > AI Platform > Pipelines
Cliquez sur + Nouvelle instance pour créer un nouveau cluster.
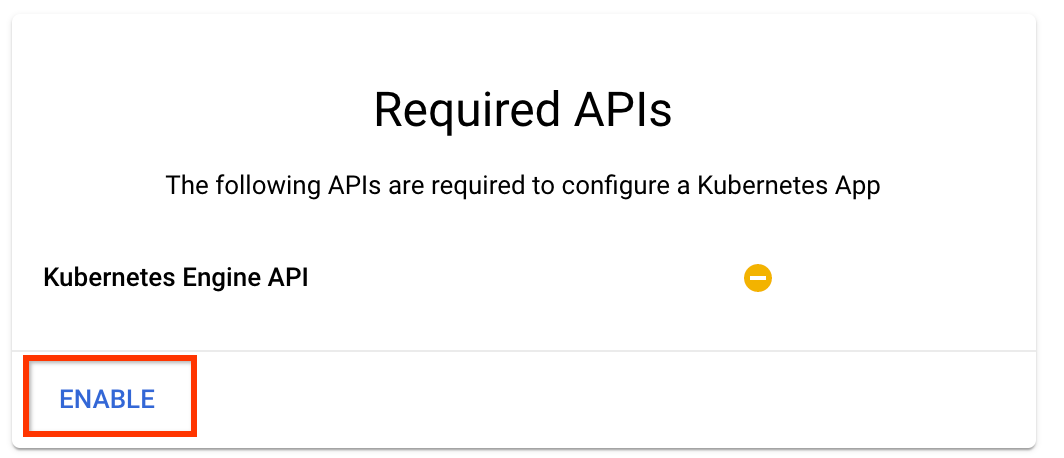
Sur la page de présentation de Kubeflow Pipelines , cliquez sur Configurer .

Cliquez sur "Activer" pour activer l'API Kubernetes Engine
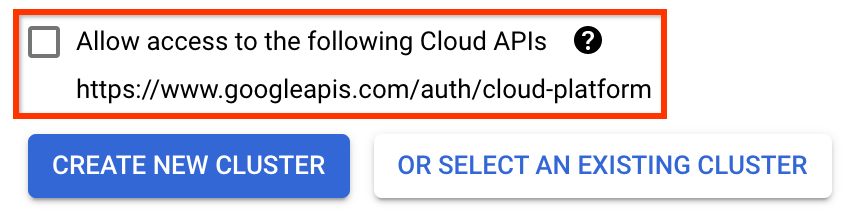
Sur la page Déployer les pipelines Kubeflow :
Sélectionnez une zone (ou « région ») pour votre cluster. Le réseau et le sous-réseau peuvent être définis, mais pour les besoins de ce didacticiel, nous les laisserons par défaut.
IMPORTANT Cochez la case intitulée Autoriser l'accès aux API cloud suivantes . (Cela est nécessaire pour que ce cluster puisse accéder aux autres éléments de votre projet. Si vous manquez cette étape, la corriger plus tard est un peu délicate.)
Cliquez sur Créer un nouveau cluster et attendez plusieurs minutes jusqu'à ce que le cluster soit créé. Cela prendra quelques minutes. Une fois l'opération terminée, vous verrez un message du type :
Cluster "cluster-1" créé avec succès dans la zone "us-central1-a".
Sélectionnez un espace de noms et un nom d'instance (l'utilisation des valeurs par défaut convient). Pour les besoins de ce didacticiel, ne cochez pas executor.emissary ou Managedstorage.enabled .
Cliquez sur Déployer et attendez quelques instants jusqu'à ce que le pipeline soit déployé. En déployant Kubeflow Pipelines, vous acceptez les conditions d'utilisation.
3. Configurez l'instance Cloud AI Platform Notebook.
Accédez à la page Vertex AI Workbench . La première fois que vous exécuterez Workbench, vous devrez activer l'API Notebooks.
Dans le menu de navigation principal : ≡ -> Vertex AI -> Workbench
Si vous y êtes invité, activez l'API Compute Engine.
Créez un nouveau bloc-notes avec TensorFlow Enterprise 2.7 (ou supérieur) installé.
Nouveau bloc-notes -> TensorFlow Enterprise 2.7 -> Sans GPU
Sélectionnez une région et une zone, puis attribuez un nom à l'instance de notebook.
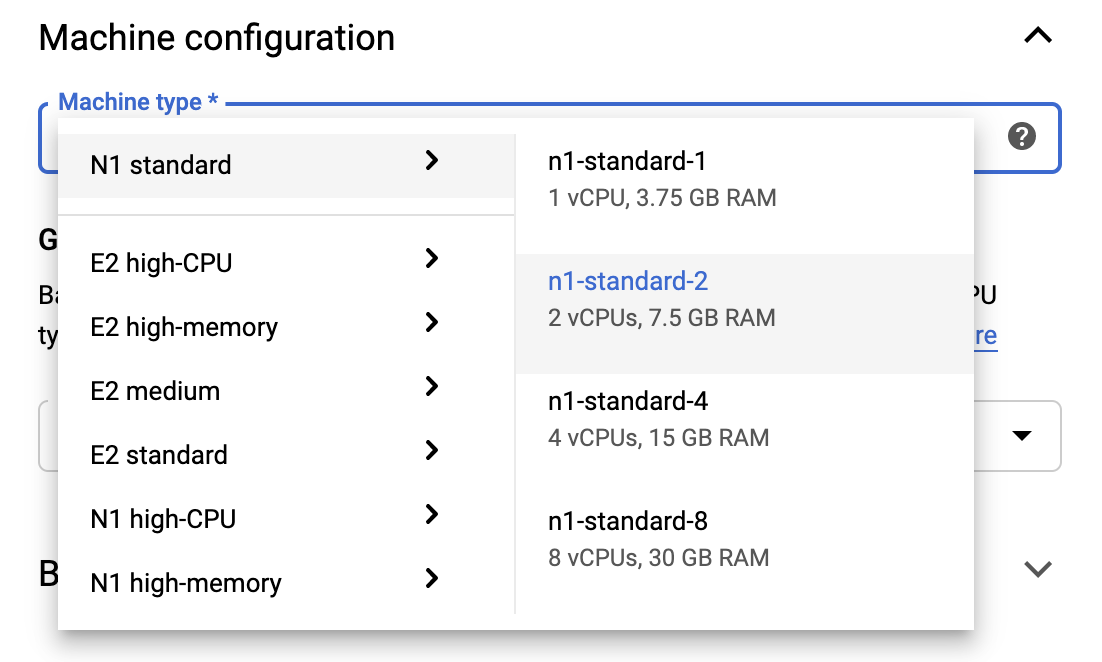
Pour rester dans les limites de l'offre gratuite, vous devrez peut-être modifier les paramètres par défaut ici pour réduire le nombre de processeurs virtuels disponibles pour cette instance de 4 à 2 :
- Sélectionnez Options avancées au bas du formulaire Nouveau bloc-notes .
Sous Configuration de la machine, vous souhaiterez peut-être sélectionner une configuration avec 1 ou 2 processeurs virtuels si vous devez rester dans le niveau gratuit.
Attendez que le nouveau notebook soit créé, puis cliquez sur Activer l'API Notebooks.
4. Lancez le bloc-notes de démarrage
Accédez à la page des clusters de pipelines AI Platform .
Dans le menu de navigation principal : ≡ -> AI Platform -> Pipelines
Sur la ligne du cluster que vous utilisez dans ce didacticiel, cliquez sur Open Pipelines Dashboard .

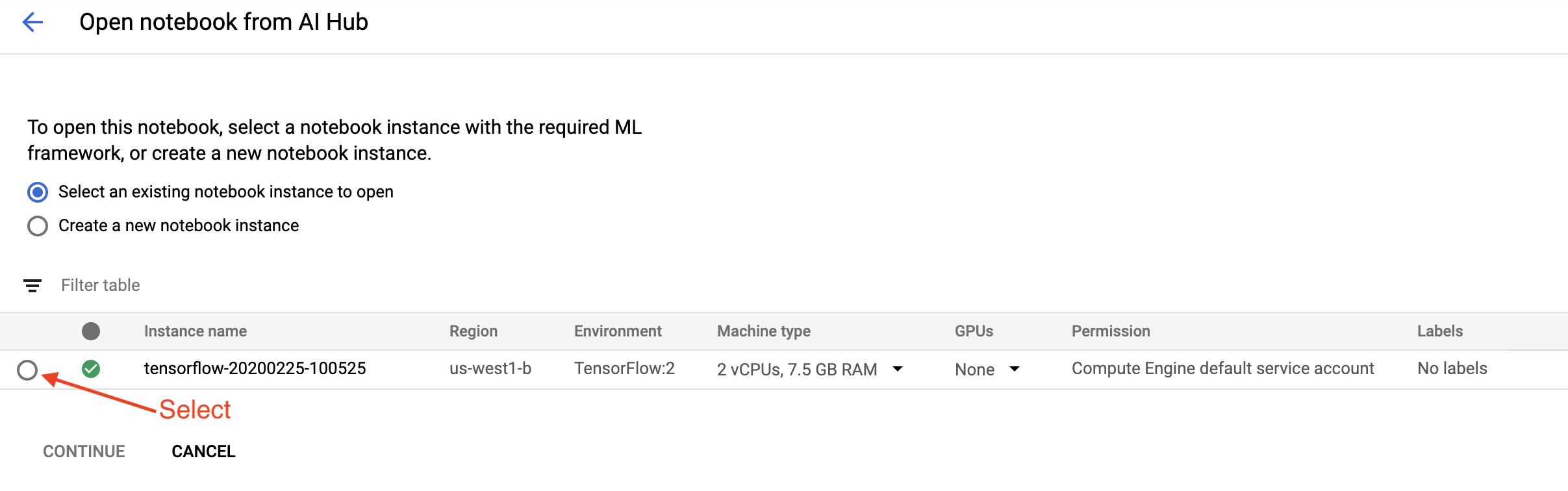
Sur la page Mise en route , cliquez sur Ouvrir un bloc-notes Cloud AI Platform sur Google Cloud .

Sélectionnez l'instance de Notebook que vous utilisez pour ce didacticiel et continuez , puis confirmez .
5. Continuez à travailler dans le bloc-notes
Installer
Le bloc-notes de démarrage commence par installer TFX et Kubeflow Pipelines (KFP) dans la machine virtuelle sur laquelle Jupyter Lab s'exécute.
Il vérifie ensuite quelle version de TFX est installée, effectue une importation, puis définit et imprime l'ID du projet :

Connectez-vous à vos services Google Cloud
La configuration du pipeline nécessite votre ID de projet, que vous pouvez obtenir via le notebook et définir comme variable d'environnement.
# Read GCP project id from env.
shell_output=!gcloud config list --format 'value(core.project)' 2>/dev/null
GCP_PROJECT_ID=shell_output[0]
print("GCP project ID:" + GCP_PROJECT_ID)
Définissez maintenant le point de terminaison de votre cluster KFP.
Celui-ci peut être trouvé à partir de l'URL du tableau de bord Pipelines. Accédez au tableau de bord Kubeflow Pipeline et regardez l'URL. Le point de terminaison correspond à tout ce qui se trouve dans l'URL commençant par https:// , jusqu'à googleusercontent.com inclus.
ENDPOINT='' # Enter YOUR ENDPOINT here.
Le notebook définit ensuite un nom unique pour l'image Docker personnalisée :
# Docker image name for the pipeline image
CUSTOM_TFX_IMAGE='gcr.io/' + GCP_PROJECT_ID + '/tfx-pipeline'
6. Copiez un modèle dans le répertoire de votre projet
Modifiez la cellule suivante du bloc-notes pour définir un nom pour votre pipeline. Dans ce tutoriel, nous utiliserons my_pipeline .
PIPELINE_NAME="my_pipeline"
PROJECT_DIR=os.path.join(os.path.expanduser("~"),"imported",PIPELINE_NAME)
Le notebook utilise ensuite la CLI tfx pour copier le modèle de pipeline. Ce didacticiel utilise l'ensemble de données Chicago Taxi pour effectuer une classification binaire. Le modèle définit donc le modèle sur taxi :
!tfx template copy \
--pipeline-name={PIPELINE_NAME} \
--destination-path={PROJECT_DIR} \
--model=taxi
Le notebook modifie ensuite son contexte CWD vers le répertoire du projet :
%cd {PROJECT_DIR}
Parcourez les fichiers du pipeline
Sur le côté gauche de Cloud AI Platform Notebook, vous devriez voir un navigateur de fichiers. Il devrait y avoir un répertoire avec le nom de votre pipeline ( my_pipeline ). Ouvrez-le et affichez les fichiers. (Vous pourrez également les ouvrir et les modifier à partir de l'environnement du bloc-notes.)
# You can also list the files from the shellls
La commande tfx template copy ci-dessus a créé un échafaudage de base de fichiers qui construisent un pipeline. Ceux-ci incluent les codes sources Python, les exemples de données et les notebooks Jupyter. Ceux-ci sont destinés à cet exemple particulier. Pour vos propres pipelines, il s'agira des fichiers de support dont votre pipeline a besoin.
Voici une brève description des fichiers Python.
-
pipeline- Ce répertoire contient la définition du pipeline-
configs.py- définit des constantes communes pour les exécuteurs de pipeline -
pipeline.py- définit les composants TFX et un pipeline
-
-
models- Ce répertoire contient les définitions de modèles ML.-
features.pyfeatures_test.py— définit les fonctionnalités du modèle -
preprocessing.py/preprocessing_test.py— définit les tâches de prétraitement à l'aide detf::Transform -
estimator- Ce répertoire contient un modèle basé sur un estimateur.-
constants.py— définit les constantes du modèle -
model.py/model_test.py- définit le modèle DNN à l'aide de l'estimateur TF
-
-
keras- Ce répertoire contient un modèle basé sur Keras.-
constants.py— définit les constantes du modèle -
model.py/model_test.py- définit le modèle DNN à l'aide de Keras
-
-
-
beam_runner.py/kubeflow_runner.py— définit des exécuteurs pour chaque moteur d'orchestration
7. Exécutez votre premier pipeline TFX sur Kubeflow
Le notebook exécutera le pipeline à l’aide de la commande CLI tfx run .
Connectez-vous au stockage
Les pipelines en cours d'exécution créent des artefacts qui doivent être stockés dans ML-Metadata . Les artefacts font référence aux charges utiles, qui sont des fichiers qui doivent être stockés dans un système de fichiers ou dans un stockage par blocs. Pour ce didacticiel, nous utiliserons GCS pour stocker nos charges utiles de métadonnées, en utilisant le compartiment créé automatiquement lors de la configuration. Son nom sera <your-project-id>-kubeflowpipelines-default .
Créer le pipeline
Le notebook téléchargera nos exemples de données dans le compartiment GCS afin que nous puissions les utiliser ultérieurement dans notre pipeline.
gsutil cp data/data.csv gs://{GOOGLE_CLOUD_PROJECT}-kubeflowpipelines-default/tfx-template/data/taxi/data.csv
Le notebook utilise ensuite la commande tfx pipeline create pour créer le pipeline.
!tfx pipeline create \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT} \
--build-image
Lors de la création d'un pipeline, Dockerfile sera généré pour créer une image Docker. N'oubliez pas d'ajouter ces fichiers à votre système de contrôle de code source (par exemple, git) avec d'autres fichiers source.
Exécuter le pipeline
Le notebook utilise ensuite la commande tfx run create pour démarrer une exécution de votre pipeline. Vous verrez également cette exécution répertoriée sous Expériences dans le tableau de bord Kubeflow Pipelines.
tfx run create --pipeline-name={PIPELINE_NAME} --endpoint={ENDPOINT}
Vous pouvez afficher votre pipeline à partir du tableau de bord Kubeflow Pipelines.
8. Validez vos données
La première tâche de tout projet de science des données ou de ML est de comprendre et de nettoyer les données.
- Comprendre les types de données pour chaque fonctionnalité
- Rechercher des anomalies et des valeurs manquantes
- Comprendre les distributions pour chaque fonctionnalité
Composants


- ExempleGen ingère et divise l'ensemble de données d'entrée.
- StatisticsGen calcule les statistiques pour l'ensemble de données.
- SchemaGen SchemaGen examine les statistiques et crée un schéma de données.
- SampleValidator recherche les anomalies et les valeurs manquantes dans l'ensemble de données.
Dans l'éditeur de fichiers de laboratoire Jupyter :
Dans pipeline / pipeline.py , décommentez les lignes qui ajoutent ces composants à votre pipeline :
# components.append(statistics_gen)
# components.append(schema_gen)
# components.append(example_validator)
( ExampleGen était déjà activé lorsque les fichiers modèles ont été copiés.)
Mettez à jour le pipeline et réexécutez-le
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Vérifiez le pipeline
Pour Kubeflow Orchestrator, visitez le tableau de bord KFP et recherchez les sorties du pipeline dans la page correspondant à l'exécution de votre pipeline. Cliquez sur l'onglet "Expériences" sur la gauche et sur "Toutes les exécutions" dans la page Expériences. Vous devriez pouvoir trouver l'exécution portant le nom de votre pipeline.
Exemple plus avancé
L'exemple présenté ici est en réalité uniquement destiné à vous aider à démarrer. Pour un exemple plus avancé, consultez le TensorFlow Data Validation Colab .
Pour plus d'informations sur l'utilisation de TFDV pour explorer et valider un ensemble de données, consultez les exemples sur tensorflow.org .
9. Ingénierie des fonctionnalités
Vous pouvez augmenter la qualité prédictive de vos données et/ou réduire la dimensionnalité grâce à l'ingénierie des fonctionnalités.
- Croix de fonctionnalités
- Vocabulaires
- Intégrations
- APC
- Encodage catégoriel
L'un des avantages de l'utilisation de TFX est que vous écrirez votre code de transformation une seule fois et que les transformations résultantes seront cohérentes entre la formation et la diffusion.
Composants

- Transform effectue l'ingénierie des fonctionnalités sur l'ensemble de données.
Dans l'éditeur de fichiers de laboratoire Jupyter :
Dans pipeline / pipeline.py , recherchez et décommentez la ligne qui ajoute Transform au pipeline.
# components.append(transform)
Mettez à jour le pipeline et réexécutez-le
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Vérifier les sorties du pipeline
Pour Kubeflow Orchestrator, visitez le tableau de bord KFP et recherchez les sorties du pipeline dans la page correspondant à l'exécution de votre pipeline. Cliquez sur l'onglet "Expériences" sur la gauche et sur "Toutes les exécutions" dans la page Expériences. Vous devriez pouvoir trouver l'exécution portant le nom de votre pipeline.
Exemple plus avancé
L'exemple présenté ici est en réalité uniquement destiné à vous aider à démarrer. Pour un exemple plus avancé, consultez TensorFlow Transform Colab .
10. Formation
Entraînez un modèle TensorFlow avec vos données agréables, propres et transformées.
- Incluez les transformations de l'étape précédente afin qu'elles soient appliquées de manière cohérente
- Enregistrez les résultats en tant que SavedModel pour la production
- Visualisez et explorez le processus de formation à l'aide de TensorBoard
- Enregistrez également un EvalSavedModel pour l'analyse des performances du modèle
Composants
- Le formateur entraîne un modèle TensorFlow.
Dans l'éditeur de fichiers de laboratoire Jupyter :
Dans pipeline / pipeline.py , recherchez et décommentez le qui ajoute Trainer au pipeline :
# components.append(trainer)
Mettez à jour le pipeline et réexécutez-le
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Vérifier les sorties du pipeline
Pour Kubeflow Orchestrator, visitez le tableau de bord KFP et recherchez les sorties du pipeline dans la page correspondant à l'exécution de votre pipeline. Cliquez sur l'onglet "Expériences" sur la gauche et sur "Toutes les exécutions" dans la page Expériences. Vous devriez pouvoir trouver l'exécution portant le nom de votre pipeline.
Exemple plus avancé
L'exemple présenté ici est en réalité uniquement destiné à vous aider à démarrer. Pour un exemple plus avancé, consultez le didacticiel TensorBoard .
11. Analyse des performances du modèle
Comprendre bien plus que les indicateurs de haut niveau.
- Les utilisateurs bénéficient des performances du modèle uniquement pour leurs requêtes
- De mauvaises performances sur des tranches de données peuvent être masquées par des métriques de niveau supérieur
- L’équité du modèle est importante
- Souvent, des sous-ensembles clés d'utilisateurs ou de données sont très importants et peuvent être petits
- Performance dans des conditions critiques mais inhabituelles
- Performance pour les publics clés tels que les influenceurs
- Si vous remplacez un modèle actuellement en production, assurez-vous d'abord que le nouveau est meilleur
Composants
- L'évaluateur effectue une analyse approfondie des résultats de la formation.
Dans l'éditeur de fichiers de laboratoire Jupyter :
Dans pipeline / pipeline.py , recherchez et décommentez la ligne qui ajoute Evaluator au pipeline :
components.append(evaluator)
Mettez à jour le pipeline et réexécutez-le
# Update the pipeline
! tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
! tfx run create --pipeline-name "{PIPELINE_NAME}"
Vérifier les sorties du pipeline
Pour Kubeflow Orchestrator, visitez le tableau de bord KFP et recherchez les sorties du pipeline dans la page correspondant à l'exécution de votre pipeline. Cliquez sur l'onglet "Expériences" sur la gauche et sur "Toutes les exécutions" dans la page Expériences. Vous devriez pouvoir trouver l'exécution portant le nom de votre pipeline.
12. Servir le modèle
Si le nouveau modèle est prêt, faites-le.
- Pusher déploie SavedModels dans des emplacements bien connus
Les cibles de déploiement reçoivent de nouveaux modèles provenant d'emplacements bien connus
- Service TensorFlow
- TensorFlow Lite
- TensorFlow JS
- TensorFlow Hub
Composants
- Pusher déploie le modèle sur une infrastructure de service.
Dans l'éditeur de fichiers de laboratoire Jupyter :
Dans pipeline / pipeline.py , recherchez et décommentez la ligne qui ajoute Pusher au pipeline :
# components.append(pusher)
Vérifier les sorties du pipeline
Pour Kubeflow Orchestrator, visitez le tableau de bord KFP et recherchez les sorties du pipeline dans la page correspondant à l'exécution de votre pipeline. Cliquez sur l'onglet "Expériences" sur la gauche et sur "Toutes les exécutions" dans la page Expériences. Vous devriez pouvoir trouver l'exécution portant le nom de votre pipeline.
Cibles de déploiement disponibles
Vous avez maintenant formé et validé votre modèle, et votre modèle est maintenant prêt pour la production. Vous pouvez désormais déployer votre modèle sur n'importe quelle cible de déploiement TensorFlow, notamment :
- TensorFlow Serving , pour diffuser votre modèle sur un serveur ou une batterie de serveurs et traiter les requêtes d'inférence REST et/ou gRPC.
- TensorFlow Lite , pour inclure votre modèle dans une application mobile native Android ou iOS, ou dans une application Raspberry Pi, IoT ou microcontrôleur.
- TensorFlow.js , pour exécuter votre modèle dans un navigateur Web ou une application Node.JS.
Exemples plus avancés
L’exemple présenté ci-dessus est en réalité uniquement destiné à vous aider à démarrer. Vous trouverez ci-dessous quelques exemples d'intégration avec d'autres services Cloud.
Considérations sur les ressources de Kubeflow Pipelines
En fonction des exigences de votre charge de travail, la configuration par défaut de votre déploiement Kubeflow Pipelines peut ou non répondre à vos besoins. Vous pouvez personnaliser vos configurations de ressources à l'aide pipeline_operator_funcs dans votre appel à KubeflowDagRunnerConfig .
pipeline_operator_funcs est une liste d'éléments OpFunc , qui transforme toutes les instances ContainerOp générées dans la spécification de pipeline KFP compilée à partir de KubeflowDagRunner .
Par exemple, pour configurer la mémoire, nous pouvons utiliser set_memory_request pour déclarer la quantité de mémoire nécessaire. Une façon typique de procéder consiste à créer un wrapper pour set_memory_request et à l'utiliser pour l'ajouter à la liste des OpFunc du pipeline :
def request_more_memory():
def _set_memory_spec(container_op):
container_op.set_memory_request('32G')
return _set_memory_spec
# Then use this opfunc in KubeflowDagRunner
pipeline_op_funcs = kubeflow_dag_runner.get_default_pipeline_operator_funcs()
pipeline_op_funcs.append(request_more_memory())
config = KubeflowDagRunnerConfig(
pipeline_operator_funcs=pipeline_op_funcs,
...
)
kubeflow_dag_runner.KubeflowDagRunner(config=config).run(pipeline)
Les fonctions de configuration de ressources similaires incluent :
-
set_memory_limit -
set_cpu_request -
set_cpu_limit -
set_gpu_limit
Essayez BigQueryExampleGen
BigQuery est un entrepôt de données cloud sans serveur, hautement évolutif et rentable. BigQuery peut être utilisé comme source d'exemples de formation dans TFX. Dans cette étape, nous ajouterons BigQueryExampleGen au pipeline.
Dans l'éditeur de fichiers de laboratoire Jupyter :
Double-cliquez pour ouvrir pipeline.py . Commentez CsvExampleGen et décommentez la ligne qui crée une instance de BigQueryExampleGen . Vous devez également décommenter l'argument query de la fonction create_pipeline .
Nous devons spécifier quel projet GCP utiliser pour BigQuery, et cela se fait en définissant --project dans beam_pipeline_args lors de la création d'un pipeline.
Double-cliquez pour ouvrir configs.py . Décommentez la définition de BIG_QUERY_WITH_DIRECT_RUNNER_BEAM_PIPELINE_ARGS et BIG_QUERY_QUERY . Vous devez remplacer l'ID du projet et la valeur de la région dans ce fichier par les valeurs correctes pour votre projet GCP.
Changez de répertoire d’un niveau au-dessus. Cliquez sur le nom du répertoire au-dessus de la liste des fichiers. Le nom du répertoire est le nom du pipeline qui est my_pipeline si vous n'avez pas modifié le nom du pipeline.
Double-cliquez pour ouvrir kubeflow_runner.py . Décommentez deux arguments, query et beam_pipeline_args , pour la fonction create_pipeline .
Le pipeline est désormais prêt à utiliser BigQuery comme exemple de source. Mettez à jour le pipeline comme avant et créez une nouvelle exécution comme nous l'avons fait aux étapes 5 et 6.
Mettez à jour le pipeline et réexécutez-le
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Essayez Dataflow
Plusieurs composants TFX utilisent Apache Beam pour implémenter des pipelines de données parallèles, ce qui signifie que vous pouvez distribuer les charges de travail de traitement des données à l'aide de Google Cloud Dataflow . Dans cette étape, nous allons configurer l'orchestrateur Kubeflow pour qu'il utilise Dataflow comme back-end de traitement des données pour Apache Beam.
# Select your project:
gcloud config set project YOUR_PROJECT_ID
# Get a list of services that you can enable in your project:
gcloud services list --available | grep Dataflow
# If you don't see dataflow.googleapis.com listed, that means you haven't been
# granted access to enable the Dataflow API. See your account adminstrator.
# Enable the Dataflow service:
gcloud services enable dataflow.googleapis.com
Double-cliquez sur pipeline pour changer de répertoire et double-cliquez pour ouvrir configs.py . Décommentez la définition de GOOGLE_CLOUD_REGION et DATAFLOW_BEAM_PIPELINE_ARGS .
Changez de répertoire d’un niveau au-dessus. Cliquez sur le nom du répertoire au-dessus de la liste des fichiers. Le nom du répertoire est le nom du pipeline qui est my_pipeline si vous ne l'avez pas modifié.
Double-cliquez pour ouvrir kubeflow_runner.py . Décommentez beam_pipeline_args . (Assurez-vous également de commenter beam_pipeline_args actuels que vous avez ajoutés à l'étape 7.)
Mettez à jour le pipeline et réexécutez-le
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Vous pouvez trouver vos tâches Dataflow dans Dataflow dans Cloud Console .
Essayez la formation et la prédiction Cloud AI Platform avec KFP
TFX interagit avec plusieurs services GCP gérés, tels que Cloud AI Platform for Training and Prediction . Vous pouvez configurer votre composant Trainer pour qu'il utilise Cloud AI Platform Training, un service géré pour la formation des modèles ML. De plus, lorsque votre modèle est créé et prêt à être servi, vous pouvez le transférer vers Cloud AI Platform Prediction pour le servir. Dans cette étape, nous allons configurer nos composants Trainer et Pusher pour qu'ils utilisent les services Cloud AI Platform.
Avant de modifier des fichiers, vous devrez peut-être d'abord activer l'API AI Platform Training & Prediction .
Double-cliquez sur pipeline pour changer de répertoire et double-cliquez pour ouvrir configs.py . Décommentez la définition de GOOGLE_CLOUD_REGION , GCP_AI_PLATFORM_TRAINING_ARGS et GCP_AI_PLATFORM_SERVING_ARGS . Nous utiliserons notre image de conteneur personnalisée pour entraîner un modèle dans Cloud AI Platform Training. Nous devons donc définir masterConfig.imageUri dans GCP_AI_PLATFORM_TRAINING_ARGS sur la même valeur que CUSTOM_TFX_IMAGE ci-dessus.
Changez de répertoire d'un niveau plus haut et double-cliquez pour ouvrir kubeflow_runner.py . Décommentez ai_platform_training_args et ai_platform_serving_args .
Mettez à jour le pipeline et réexécutez-le
# Update the pipeline
!tfx pipeline update \
--pipeline-path=kubeflow_runner.py \
--endpoint={ENDPOINT}
!tfx run create --pipeline-name {PIPELINE_NAME} --endpoint={ENDPOINT}
Vous pouvez trouver vos offres de formation dans Cloud AI Platform Jobs . Si votre pipeline s'est terminé avec succès, vous pouvez trouver votre modèle dans Modèles Cloud AI Platform .
14. Utilisez vos propres données
Dans ce didacticiel, vous avez créé un pipeline pour un modèle à l'aide de l'ensemble de données Chicago Taxi. Essayez maintenant de mettre vos propres données dans le pipeline. Vos données peuvent être stockées partout où le pipeline peut y accéder, y compris les fichiers Google Cloud Storage, BigQuery ou CSV.
Vous devez modifier la définition du pipeline pour s'adapter à vos données.
Si vos données sont stockées dans des fichiers
- Modifiez
DATA_PATHdanskubeflow_runner.py, en indiquant l'emplacement.
Si vos données sont stockées dans BigQuery
- Modifiez
BIG_QUERY_QUERYdans configs.py en votre instruction de requête. - Ajoutez des fonctionnalités dans
modelsfeatures.py. - Modifiez
models/preprocessing.pypour transformer les données d'entrée pour la formation . - Modifiez
models/keras/model.pyetmodels/keras/constants.pypour décrire votre modèle ML .
En savoir plus sur le formateur
Consultez le guide des composants du formateur pour plus de détails sur les pipelines de formation.
Nettoyer
Pour nettoyer toutes les ressources Google Cloud utilisées dans ce projet, vous pouvez supprimer le projet Google Cloud que vous avez utilisé pour le didacticiel.
Vous pouvez également nettoyer des ressources individuelles en visitant chaque console : - Google Cloud Storage - Google Container Registry - Google Kubernetes Engine