
 在 GitHub 中查看源代码 在 GitHub 中查看源代码 |
{img1下载笔记本 |
概述
此笔记本将演示如何使用 TensorFlow Addons 中的 TripletSemiHardLoss 函数。
资源:
TripletLoss
正如 FaceNet 论文中首次介绍的那样,TripletLoss 是一种损失函数,可以训练神经网络紧密嵌入相同类别的特征,同时最大程度地提高不同类别的嵌入向量之间的距离。为此,选择一个锚点以及一个负样本和一个正样本。
损失函数被描述为欧氏距离函数:
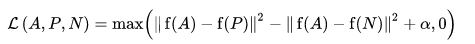
其中,A 是我们的锚点输入,P 是正样本输入,N 是负样本输入,α 是我们用来指定三元组何时变得过于“容易”并且不再需要调整其权重的间隔。
SemiHard 在线学习
如文中所示,最佳结果来自被称为“Semi-Hard”(一般)的三元组。在这些三元组中,负数比正数离锚点更远,但仍会产生正损失。为了高效地找到这些三元组,我们利用在线学习,并且仅从每个批次的 Semi-Hard 样本中进行训练。
设置
pip install -q -U tensorflow-addonsimport io
import numpy as np
import tensorflow as tf
import tensorflow_addons as tfa
import tensorflow_datasets as tfds
准备数据
def _normalize_img(img, label):
img = tf.cast(img, tf.float32) / 255.
return (img, label)
train_dataset, test_dataset = tfds.load(name="mnist", split=['train', 'test'], as_supervised=True)
# Build your input pipelines
train_dataset = train_dataset.shuffle(1024).batch(32)
train_dataset = train_dataset.map(_normalize_img)
test_dataset = test_dataset.batch(32)
test_dataset = test_dataset.map(_normalize_img)
Downloading and preparing dataset mnist/3.0.1 (download: 11.06 MiB, generated: 21.00 MiB, total: 32.06 MiB) to /home/kbuilder/tensorflow_datasets/mnist/3.0.1... WARNING:absl:Dataset mnist is hosted on GCS. It will automatically be downloaded to your local data directory. If you'd instead prefer to read directly from our public GCS bucket (recommended if you're running on GCP), you can instead pass `try_gcs=True` to `tfds.load` or set `data_dir=gs://tfds-data/datasets`. Dataset mnist downloaded and prepared to /home/kbuilder/tensorflow_datasets/mnist/3.0.1. Subsequent calls will reuse this data.
构建模型

model = tf.keras.Sequential([
tf.keras.layers.Conv2D(filters=64, kernel_size=2, padding='same', activation='relu', input_shape=(28,28,1)),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Conv2D(filters=32, kernel_size=2, padding='same', activation='relu'),
tf.keras.layers.MaxPooling2D(pool_size=2),
tf.keras.layers.Dropout(0.3),
tf.keras.layers.Flatten(),
tf.keras.layers.Dense(256, activation=None), # No activation on final dense layer
tf.keras.layers.Lambda(lambda x: tf.math.l2_normalize(x, axis=1)) # L2 normalize embeddings
])
训练和评估
# Compile the model
model.compile(
optimizer=tf.keras.optimizers.Adam(0.001),
loss=tfa.losses.TripletSemiHardLoss())
# Train the network
history = model.fit(
train_dataset,
epochs=5)
Epoch 1/5 1875/1875 [==============================] - 7s 4ms/step - loss: 0.5921 Epoch 2/5 1875/1875 [==============================] - 6s 3ms/step - loss: 0.4548 Epoch 3/5 1875/1875 [==============================] - 6s 3ms/step - loss: 0.4230 Epoch 4/5 1875/1875 [==============================] - 6s 3ms/step - loss: 0.4070 Epoch 5/5 1875/1875 [==============================] - 6s 3ms/step - loss: 0.3930
# Evaluate the network
results = model.predict(test_dataset)
# Save test embeddings for visualization in projector
np.savetxt("vecs.tsv", results, delimiter='\t')
out_m = io.open('meta.tsv', 'w', encoding='utf-8')
for img, labels in tfds.as_numpy(test_dataset):
[out_m.write(str(x) + "\n") for x in labels]
out_m.close()
try:
from google.colab import files
files.download('vecs.tsv')
files.download('meta.tsv')
except:
pass
Embedding Projector
可以在此处加载和可视化向量及元数据文件:https://projector.tensorflow.org/
使用 UMAP 进行可视化时,您可以看到我们嵌入式测试数据的结果: