
 在 GitHub 上查看源代码 在 GitHub 上查看源代码 |
概述
此笔记本将演示如何使用 Addons 软件包中的条件梯度优化器。
ConditionalGradient
由于潜在的正则化效果,约束神经网络的参数已被证明对训练有益。通常,参数通过软惩罚(从不保证约束满足)或通过投影运算(计算资源消耗大)进行约束。另一方面,条件梯度 (CG) 优化器可严格执行约束,而无需消耗资源的投影步骤。它通过最大程度减小约束集中目标的线性逼近来工作。在此笔记本中,我们通过 MNIST 数据集上的 CG 优化器演示弗罗宾尼斯范数约束的应用。CG 现在可以作为 Tensorflow API 提供。有关优化器的更多详细信息,请参阅 https://arxiv.org/pdf/1803.06453.pdf
设置
pip install -U tensorflow-addonsimport tensorflow as tf
import tensorflow_addons as tfa
from matplotlib import pyplot as plt
# Hyperparameters
batch_size=64
epochs=10
构建模型
model_1 = tf.keras.Sequential([
tf.keras.layers.Dense(64, input_shape=(784,), activation='relu', name='dense_1'),
tf.keras.layers.Dense(64, activation='relu', name='dense_2'),
tf.keras.layers.Dense(10, activation='softmax', name='predictions'),
])
准备数据
# Load MNIST dataset as NumPy arrays
dataset = {}
num_validation = 10000
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.mnist.load_data()
# Preprocess the data
x_train = x_train.reshape(-1, 784).astype('float32') / 255
x_test = x_test.reshape(-1, 784).astype('float32') / 255
Downloading data from https://storage.googleapis.com/tensorflow/tf-keras-datasets/mnist.npz 11493376/11490434 [==============================] - 0s 0us/step 11501568/11490434 [==============================] - 0s 0us/step
定义自定义回调函数
def frobenius_norm(m):
"""This function is to calculate the frobenius norm of the matrix of all
layer's weight.
Args:
m: is a list of weights param for each layers.
"""
total_reduce_sum = 0
for i in range(len(m)):
total_reduce_sum = total_reduce_sum + tf.math.reduce_sum(m[i]**2)
norm = total_reduce_sum**0.5
return norm
CG_frobenius_norm_of_weight = []
CG_get_weight_norm = tf.keras.callbacks.LambdaCallback(
on_epoch_end=lambda batch, logs: CG_frobenius_norm_of_weight.append(
frobenius_norm(model_1.trainable_weights).numpy()))
训练和评估:使用 CG 作为优化器
只需用新的 TFA 优化器替换典型的 Keras 优化器
# Compile the model
model_1.compile(
optimizer=tfa.optimizers.ConditionalGradient(
learning_rate=0.99949, lambda_=203), # Utilize TFA optimizer
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
history_cg = model_1.fit(
x_train,
y_train,
batch_size=batch_size,
validation_data=(x_test, y_test),
epochs=epochs,
callbacks=[CG_get_weight_norm])
Epoch 1/10 938/938 [==============================] - 3s 3ms/step - loss: 0.3901 - accuracy: 0.8826 - val_loss: 0.2070 - val_accuracy: 0.9375 Epoch 2/10 938/938 [==============================] - 2s 3ms/step - loss: 0.1871 - accuracy: 0.9442 - val_loss: 0.1567 - val_accuracy: 0.9507 Epoch 3/10 938/938 [==============================] - 2s 3ms/step - loss: 0.1471 - accuracy: 0.9561 - val_loss: 0.1253 - val_accuracy: 0.9635 Epoch 4/10 938/938 [==============================] - 2s 3ms/step - loss: 0.1282 - accuracy: 0.9616 - val_loss: 0.1526 - val_accuracy: 0.9493 Epoch 5/10 938/938 [==============================] - 2s 3ms/step - loss: 0.1181 - accuracy: 0.9644 - val_loss: 0.2061 - val_accuracy: 0.9313 Epoch 6/10 938/938 [==============================] - 2s 3ms/step - loss: 0.1147 - accuracy: 0.9659 - val_loss: 0.1480 - val_accuracy: 0.9559 Epoch 7/10 938/938 [==============================] - 2s 3ms/step - loss: 0.1084 - accuracy: 0.9668 - val_loss: 0.1183 - val_accuracy: 0.9663 Epoch 8/10 938/938 [==============================] - 2s 3ms/step - loss: 0.1051 - accuracy: 0.9682 - val_loss: 0.1599 - val_accuracy: 0.9471 Epoch 9/10 938/938 [==============================] - 2s 2ms/step - loss: 0.1023 - accuracy: 0.9689 - val_loss: 0.1100 - val_accuracy: 0.9665 Epoch 10/10 938/938 [==============================] - 2s 3ms/step - loss: 0.1000 - accuracy: 0.9701 - val_loss: 0.1202 - val_accuracy: 0.9644
训练和评估:使用 SGD 作为优化器
model_2 = tf.keras.Sequential([
tf.keras.layers.Dense(64, input_shape=(784,), activation='relu', name='dense_1'),
tf.keras.layers.Dense(64, activation='relu', name='dense_2'),
tf.keras.layers.Dense(10, activation='softmax', name='predictions'),
])
SGD_frobenius_norm_of_weight = []
SGD_get_weight_norm = tf.keras.callbacks.LambdaCallback(
on_epoch_end=lambda batch, logs: SGD_frobenius_norm_of_weight.append(
frobenius_norm(model_2.trainable_weights).numpy()))
# Compile the model
model_2.compile(
optimizer=tf.keras.optimizers.SGD(0.01), # Utilize SGD optimizer
loss=tf.keras.losses.SparseCategoricalCrossentropy(),
metrics=['accuracy'])
history_sgd = model_2.fit(
x_train,
y_train,
batch_size=batch_size,
validation_data=(x_test, y_test),
epochs=epochs,
callbacks=[SGD_get_weight_norm])
Epoch 1/10 938/938 [==============================] - 2s 2ms/step - loss: 0.9734 - accuracy: 0.7435 - val_loss: 0.4342 - val_accuracy: 0.8835 Epoch 2/10 938/938 [==============================] - 2s 2ms/step - loss: 0.3880 - accuracy: 0.8919 - val_loss: 0.3311 - val_accuracy: 0.9070 Epoch 3/10 938/938 [==============================] - 2s 2ms/step - loss: 0.3228 - accuracy: 0.9086 - val_loss: 0.2885 - val_accuracy: 0.9182 Epoch 4/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2890 - accuracy: 0.9166 - val_loss: 0.2661 - val_accuracy: 0.9233 Epoch 5/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2650 - accuracy: 0.9238 - val_loss: 0.2466 - val_accuracy: 0.9301 Epoch 6/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2457 - accuracy: 0.9295 - val_loss: 0.2293 - val_accuracy: 0.9350 Epoch 7/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2295 - accuracy: 0.9334 - val_loss: 0.2153 - val_accuracy: 0.9385 Epoch 8/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2153 - accuracy: 0.9377 - val_loss: 0.2031 - val_accuracy: 0.9405 Epoch 9/10 938/938 [==============================] - 2s 2ms/step - loss: 0.2027 - accuracy: 0.9409 - val_loss: 0.1936 - val_accuracy: 0.9436 Epoch 10/10 938/938 [==============================] - 2s 2ms/step - loss: 0.1918 - accuracy: 0.9443 - val_loss: 0.1853 - val_accuracy: 0.9447
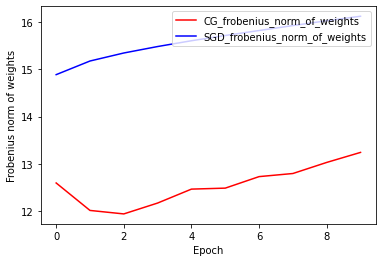
权重的弗罗宾尼斯范数:CG 与 SGD
CG 优化器的当前实现基于弗罗宾尼斯范数,并考虑将弗罗宾尼斯范数作为目标函数中的正则化器。因此,我们将 CG 的正则化效果与尚未采用弗罗宾尼斯范数正则化器的 SGD 优化器进行比较。
plt.plot(
CG_frobenius_norm_of_weight,
color='r',
label='CG_frobenius_norm_of_weights')
plt.plot(
SGD_frobenius_norm_of_weight,
color='b',
label='SGD_frobenius_norm_of_weights')
plt.xlabel('Epoch')
plt.ylabel('Frobenius norm of weights')
plt.legend(loc=1)
<matplotlib.legend.Legend at 0x7efde5ac4c50>
训练和验证准确率:CG 与 SGD
plt.plot(history_cg.history['accuracy'], color='r', label='CG_train')
plt.plot(history_cg.history['val_accuracy'], color='g', label='CG_test')
plt.plot(history_sgd.history['accuracy'], color='pink', label='SGD_train')
plt.plot(history_sgd.history['val_accuracy'], color='b', label='SGD_test')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend(loc=4)
<matplotlib.legend.Legend at 0x7efde514fe10>
