
Copyright 2023 The TF-Agents Authors.
|
|
|
 View source on GitHub
View source on GitHub
|
|
Introduction
This example shows how to train a Soft Actor Critic agent on the Minitaur environment.
If you've worked through the DQN Colab this should feel very familiar. Notable changes include:
- Changing the agent from DQN to SAC.
- Training on Minitaur which is a much more complex environment than CartPole. The Minitaur environment aims to train a quadruped robot to move forward.
- Using the TF-Agents Actor-Learner API for distributed Reinforcement Learning.
The API supports both distributed data collection using an experience replay buffer and variable container (parameter server) and distributed training across multiple devices. The API is designed to be very simple and modular. We utilize Reverb for both replay buffer and variable container and TF DistributionStrategy API for distributed training on GPUs and TPUs.
If you haven't installed the following dependencies, run:
sudo apt-get updatesudo apt-get install -y xvfb ffmpegpip install 'imageio==2.4.0'pip install matplotlibpip install tf-agents[reverb]pip install pybulletpip install tf-keras
import os
# Keep using keras-2 (tf-keras) rather than keras-3 (keras).
os.environ['TF_USE_LEGACY_KERAS'] = '1'
Setup
First we will import the different tools that we need.
import base64
import imageio
import IPython
import matplotlib.pyplot as plt
import os
import reverb
import tempfile
import PIL.Image
import tensorflow as tf
from tf_agents.agents.ddpg import critic_network
from tf_agents.agents.sac import sac_agent
from tf_agents.agents.sac import tanh_normal_projection_network
from tf_agents.environments import suite_pybullet
from tf_agents.metrics import py_metrics
from tf_agents.networks import actor_distribution_network
from tf_agents.policies import greedy_policy
from tf_agents.policies import py_tf_eager_policy
from tf_agents.policies import random_py_policy
from tf_agents.replay_buffers import reverb_replay_buffer
from tf_agents.replay_buffers import reverb_utils
from tf_agents.train import actor
from tf_agents.train import learner
from tf_agents.train import triggers
from tf_agents.train.utils import spec_utils
from tf_agents.train.utils import strategy_utils
from tf_agents.train.utils import train_utils
tempdir = tempfile.gettempdir()
2023-12-22 12:28:38.504926: E external/local_xla/xla/stream_executor/cuda/cuda_dnn.cc:9261] Unable to register cuDNN factory: Attempting to register factory for plugin cuDNN when one has already been registered 2023-12-22 12:28:38.504976: E external/local_xla/xla/stream_executor/cuda/cuda_fft.cc:607] Unable to register cuFFT factory: Attempting to register factory for plugin cuFFT when one has already been registered 2023-12-22 12:28:38.506679: E external/local_xla/xla/stream_executor/cuda/cuda_blas.cc:1515] Unable to register cuBLAS factory: Attempting to register factory for plugin cuBLAS when one has already been registered
Hyperparameters
env_name = "MinitaurBulletEnv-v0" # @param {type:"string"}
# Use "num_iterations = 1e6" for better results (2 hrs)
# 1e5 is just so this doesn't take too long (1 hr)
num_iterations = 100000 # @param {type:"integer"}
initial_collect_steps = 10000 # @param {type:"integer"}
collect_steps_per_iteration = 1 # @param {type:"integer"}
replay_buffer_capacity = 10000 # @param {type:"integer"}
batch_size = 256 # @param {type:"integer"}
critic_learning_rate = 3e-4 # @param {type:"number"}
actor_learning_rate = 3e-4 # @param {type:"number"}
alpha_learning_rate = 3e-4 # @param {type:"number"}
target_update_tau = 0.005 # @param {type:"number"}
target_update_period = 1 # @param {type:"number"}
gamma = 0.99 # @param {type:"number"}
reward_scale_factor = 1.0 # @param {type:"number"}
actor_fc_layer_params = (256, 256)
critic_joint_fc_layer_params = (256, 256)
log_interval = 5000 # @param {type:"integer"}
num_eval_episodes = 20 # @param {type:"integer"}
eval_interval = 10000 # @param {type:"integer"}
policy_save_interval = 5000 # @param {type:"integer"}
Environment
Environments in RL represent the task or problem that we are trying to solve. Standard environments can be easily created in TF-Agents using suites. We have different suites for loading environments from sources such as the OpenAI Gym, Atari, DM Control, etc., given a string environment name.
Now let's load the Minitaur environment from the Pybullet suite.
env = suite_pybullet.load(env_name)
env.reset()
PIL.Image.fromarray(env.render())
pybullet build time: Nov 28 2023 23:52:03
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/gym/spaces/box.py:84: UserWarning: WARN: Box bound precision lowered by casting to float32
logger.warn(f"Box bound precision lowered by casting to {self.dtype}")
current_dir=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_envs/bullet
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_data

In this environment the goal is for the agent to train a policy that will control the Minitaur robot and have it move forward as fast as possible. Episodes last 1000 steps and the return will be the sum of rewards throughout the episode.
Let's look at the information the environment provides as an observation which the policy will use to generate actions.
print('Observation Spec:')
print(env.time_step_spec().observation)
print('Action Spec:')
print(env.action_spec())
Observation Spec:
BoundedArraySpec(shape=(28,), dtype=dtype('float32'), name='observation', minimum=[ -3.1515927 -3.1515927 -3.1515927 -3.1515927 -3.1515927
-3.1515927 -3.1515927 -3.1515927 -167.72488 -167.72488
-167.72488 -167.72488 -167.72488 -167.72488 -167.72488
-167.72488 -5.71 -5.71 -5.71 -5.71
-5.71 -5.71 -5.71 -5.71 -1.01
-1.01 -1.01 -1.01 ], maximum=[ 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927 3.1515927
3.1515927 3.1515927 167.72488 167.72488 167.72488 167.72488
167.72488 167.72488 167.72488 167.72488 5.71 5.71
5.71 5.71 5.71 5.71 5.71 5.71
1.01 1.01 1.01 1.01 ])
Action Spec:
BoundedArraySpec(shape=(8,), dtype=dtype('float32'), name='action', minimum=-1.0, maximum=1.0)
The observation is fairly complex. We receive 28 values representing the angles, velocities, and torques for all the motors. In return the environment expects 8 values for the actions between [-1, 1]. These are the desired motor angles.
Usually we create two environments: one for collecting data during training and one for evaluation. The environments are written in pure python and use numpy arrays, which the Actor Learner API directly consumes.
collect_env = suite_pybullet.load(env_name)
eval_env = suite_pybullet.load(env_name)
urdf_root=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_data urdf_root=/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/pybullet_data
Distribution Strategy
We use the DistributionStrategy API to enable running the train step computation across multiple devices such as multiple GPUs or TPUs using data parallelism. The train step:
- Receives a batch of training data
- Splits it across the devices
- Computes the forward step
- Aggregates and computes the MEAN of the loss
- Computes the backward step and performs a gradient variable update
With TF-Agents Learner API and DistributionStrategy API it is quite easy to switch between running the train step on GPUs (using MirroredStrategy) to TPUs (using TPUStrategy) without changing any of the training logic below.
Enabling the GPU
If you want to try running on a GPU, you'll first need to enable GPUs for the notebook:
- Navigate to Edit→Notebook Settings
- Select GPU from the Hardware Accelerator drop-down
Picking a strategy
Use strategy_utils to generate a strategy. Under the hood, passing the parameter:
use_gpu = Falsereturnstf.distribute.get_strategy(), which uses CPUuse_gpu = Truereturnstf.distribute.MirroredStrategy(), which uses all GPUs that are visible to TensorFlow on one machine
use_gpu = True
strategy = strategy_utils.get_strategy(tpu=False, use_gpu=use_gpu)
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0', '/job:localhost/replica:0/task:0/device:GPU:1', '/job:localhost/replica:0/task:0/device:GPU:2', '/job:localhost/replica:0/task:0/device:GPU:3')
INFO:tensorflow:Using MirroredStrategy with devices ('/job:localhost/replica:0/task:0/device:GPU:0', '/job:localhost/replica:0/task:0/device:GPU:1', '/job:localhost/replica:0/task:0/device:GPU:2', '/job:localhost/replica:0/task:0/device:GPU:3')
All variables and Agents need to be created under strategy.scope(), as you'll see below.
Agent
To create an SAC Agent, we first need to create the networks that it will train. SAC is an actor-critic agent, so we will need two networks.
The critic will give us value estimates for Q(s,a). That is, it will recieve as input an observation and an action, and it will give us an estimate of how good that action was for the given state.
observation_spec, action_spec, time_step_spec = (
spec_utils.get_tensor_specs(collect_env))
with strategy.scope():
critic_net = critic_network.CriticNetwork(
(observation_spec, action_spec),
observation_fc_layer_params=None,
action_fc_layer_params=None,
joint_fc_layer_params=critic_joint_fc_layer_params,
kernel_initializer='glorot_uniform',
last_kernel_initializer='glorot_uniform')
We will use this critic to train an actor network which will allow us to generate actions given an observation.
The ActorNetwork will predict parameters for a tanh-squashed MultivariateNormalDiag distribution. This distribution will then be sampled, conditioned on the current observation, whenever we need to generate actions.
with strategy.scope():
actor_net = actor_distribution_network.ActorDistributionNetwork(
observation_spec,
action_spec,
fc_layer_params=actor_fc_layer_params,
continuous_projection_net=(
tanh_normal_projection_network.TanhNormalProjectionNetwork))
With these networks at hand we can now instantiate the agent.
with strategy.scope():
train_step = train_utils.create_train_step()
tf_agent = sac_agent.SacAgent(
time_step_spec,
action_spec,
actor_network=actor_net,
critic_network=critic_net,
actor_optimizer=tf.keras.optimizers.Adam(
learning_rate=actor_learning_rate),
critic_optimizer=tf.keras.optimizers.Adam(
learning_rate=critic_learning_rate),
alpha_optimizer=tf.keras.optimizers.Adam(
learning_rate=alpha_learning_rate),
target_update_tau=target_update_tau,
target_update_period=target_update_period,
td_errors_loss_fn=tf.math.squared_difference,
gamma=gamma,
reward_scale_factor=reward_scale_factor,
train_step_counter=train_step)
tf_agent.initialize()
Replay Buffer
In order to keep track of the data collected from the environment, we will use Reverb, an efficient, extensible, and easy-to-use replay system by Deepmind. It stores experience data collected by the Actors and consumed by the Learner during training.
In this tutorial, this is less important than max_size -- but in a distributed setting with async collection and training, you will probably want to experiment with rate_limiters.SampleToInsertRatio, using a samples_per_insert somewhere between 2 and 1000. For example:
rate_limiter=reverb.rate_limiters.SampleToInsertRatio(samples_per_insert=3.0, min_size_to_sample=3, error_buffer=3.0)
table_name = 'uniform_table'
table = reverb.Table(
table_name,
max_size=replay_buffer_capacity,
sampler=reverb.selectors.Uniform(),
remover=reverb.selectors.Fifo(),
rate_limiter=reverb.rate_limiters.MinSize(1))
reverb_server = reverb.Server([table])
[reverb/cc/platform/tfrecord_checkpointer.cc:162] Initializing TFRecordCheckpointer in /tmpfs/tmp/tmp277hgu8l. [reverb/cc/platform/tfrecord_checkpointer.cc:565] Loading latest checkpoint from /tmpfs/tmp/tmp277hgu8l [reverb/cc/platform/default/server.cc:71] Started replay server on port 43327
The replay buffer is constructed using specs describing the tensors that are to be stored, which can be obtained from the agent using tf_agent.collect_data_spec.
Since the SAC Agent needs both the current and next observation to compute the loss, we set sequence_length=2.
reverb_replay = reverb_replay_buffer.ReverbReplayBuffer(
tf_agent.collect_data_spec,
sequence_length=2,
table_name=table_name,
local_server=reverb_server)
Now we generate a TensorFlow dataset from the Reverb replay buffer. We will pass this to the Learner to sample experiences for training.
dataset = reverb_replay.as_dataset(
sample_batch_size=batch_size, num_steps=2).prefetch(50)
experience_dataset_fn = lambda: dataset
Policies
In TF-Agents, policies represent the standard notion of policies in RL: given a time_step produce an action or a distribution over actions. The main method is policy_step = policy.step(time_step) where policy_step is a named tuple PolicyStep(action, state, info). The policy_step.action is the action to be applied to the environment, state represents the state for stateful (RNN) policies and info may contain auxiliary information such as log probabilities of the actions.
Agents contain two policies:
agent.policy— The main policy that is used for evaluation and deployment.agent.collect_policy— A second policy that is used for data collection.
tf_eval_policy = tf_agent.policy
eval_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_eval_policy, use_tf_function=True)
tf_collect_policy = tf_agent.collect_policy
collect_policy = py_tf_eager_policy.PyTFEagerPolicy(
tf_collect_policy, use_tf_function=True)
Policies can be created independently of agents. For example, use tf_agents.policies.random_py_policy to create a policy which will randomly select an action for each time_step.
random_policy = random_py_policy.RandomPyPolicy(
collect_env.time_step_spec(), collect_env.action_spec())
Actors
The actor manages interactions between a policy and an environment.
- The Actor components contain an instance of the environment (as
py_environment) and a copy of the policy variables. - Each Actor worker runs a sequence of data collection steps given the local values of the policy variables.
- Variable updates are done explicitly using the variable container client instance in the training script before calling
actor.run(). - The observed experience is written into the replay buffer in each data collection step.
As the Actors run data collection steps, they pass trajectories of (state, action, reward) to the observer, which caches and writes them to the Reverb replay system.
We're storing trajectories for frames [(t0,t1) (t1,t2) (t2,t3), ...] because stride_length=1.
rb_observer = reverb_utils.ReverbAddTrajectoryObserver(
reverb_replay.py_client,
table_name,
sequence_length=2,
stride_length=1)
We create an Actor with the random policy and collect experiences to seed the replay buffer with.
initial_collect_actor = actor.Actor(
collect_env,
random_policy,
train_step,
steps_per_run=initial_collect_steps,
observers=[rb_observer])
initial_collect_actor.run()
Instantiate an Actor with the collect policy to gather more experiences during training.
env_step_metric = py_metrics.EnvironmentSteps()
collect_actor = actor.Actor(
collect_env,
collect_policy,
train_step,
steps_per_run=1,
metrics=actor.collect_metrics(10),
summary_dir=os.path.join(tempdir, learner.TRAIN_DIR),
observers=[rb_observer, env_step_metric])
Create an Actor which will be used to evaluate the policy during training. We pass in actor.eval_metrics(num_eval_episodes) to log metrics later.
eval_actor = actor.Actor(
eval_env,
eval_policy,
train_step,
episodes_per_run=num_eval_episodes,
metrics=actor.eval_metrics(num_eval_episodes),
summary_dir=os.path.join(tempdir, 'eval'),
)
Learners
The Learner component contains the agent and performs gradient step updates to the policy variables using experience data from the replay buffer. After one or more training steps, the Learner can push a new set of variable values to the variable container.
saved_model_dir = os.path.join(tempdir, learner.POLICY_SAVED_MODEL_DIR)
# Triggers to save the agent's policy checkpoints.
learning_triggers = [
triggers.PolicySavedModelTrigger(
saved_model_dir,
tf_agent,
train_step,
interval=policy_save_interval),
triggers.StepPerSecondLogTrigger(train_step, interval=1000),
]
agent_learner = learner.Learner(
tempdir,
train_step,
tf_agent,
experience_dataset_fn,
triggers=learning_triggers,
strategy=strategy)
WARNING:absl:`0/step_type` is not a valid tf.function parameter name. Sanitizing to `arg_0_step_type`.
WARNING:absl:`0/reward` is not a valid tf.function parameter name. Sanitizing to `arg_0_reward`.
WARNING:absl:`0/discount` is not a valid tf.function parameter name. Sanitizing to `arg_0_discount`.
WARNING:absl:`0/observation` is not a valid tf.function parameter name. Sanitizing to `arg_0_observation`.
WARNING:absl:`0/step_type` is not a valid tf.function parameter name. Sanitizing to `arg_0_step_type`.
argv[0]=
argv[0]=
argv[0]=
argv[0]=
argv[0]=
argv[0]=
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/policy/assets
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tf_agents.distributions.utils.SquashToSpecNormal_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tfp.distributions.MultivariateNormalDiag_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/policy/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/collect_policy/assets
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tf_agents.distributions.utils.SquashToSpecNormal_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tfp.distributions.MultivariateNormalDiag_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/collect_policy/assets
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/greedy_policy/assets
/tmpfs/src/tf_docs_env/lib/python3.9/site-packages/tensorflow/python/saved_model/nested_structure_coder.py:458: UserWarning: Encoding a StructuredValue with type tfp.distributions.Deterministic_ACTTypeSpec; loading this StructuredValue will require that this type be imported and registered.
warnings.warn("Encoding a StructuredValue with type %s; loading this "
INFO:tensorflow:Assets written to: /tmpfs/tmp/policies/greedy_policy/assets
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
Metrics and Evaluation
We instantiated the eval Actor with actor.eval_metrics above, which creates most commonly used metrics during policy evaluation:
- Average return. The return is the sum of rewards obtained while running a policy in an environment for an episode, and we usually average this over a few episodes.
- Average episode length.
We run the Actor to generate these metrics.
def get_eval_metrics():
eval_actor.run()
results = {}
for metric in eval_actor.metrics:
results[metric.name] = metric.result()
return results
metrics = get_eval_metrics()
def log_eval_metrics(step, metrics):
eval_results = (', ').join(
'{} = {:.6f}'.format(name, result) for name, result in metrics.items())
print('step = {0}: {1}'.format(step, eval_results))
log_eval_metrics(0, metrics)
step = 0: AverageReturn = -0.796275, AverageEpisodeLength = 131.550003
Check out the metrics module for other standard implementations of different metrics.
Training the agent
The training loop involves both collecting data from the environment and optimizing the agent's networks. Along the way, we will occasionally evaluate the agent's policy to see how we are doing.
try:
%%time
except:
pass
# Reset the train step
tf_agent.train_step_counter.assign(0)
# Evaluate the agent's policy once before training.
avg_return = get_eval_metrics()["AverageReturn"]
returns = [avg_return]
for _ in range(num_iterations):
# Training.
collect_actor.run()
loss_info = agent_learner.run(iterations=1)
# Evaluating.
step = agent_learner.train_step_numpy
if eval_interval and step % eval_interval == 0:
metrics = get_eval_metrics()
log_eval_metrics(step, metrics)
returns.append(metrics["AverageReturn"])
if log_interval and step % log_interval == 0:
print('step = {0}: loss = {1}'.format(step, loss_info.loss.numpy()))
rb_observer.close()
reverb_server.stop()
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 12 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 6 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Collective all_reduce tensors: 1 all_reduces, num_devices = 4, group_size = 4, implementation = CommunicationImplementation.NCCL, num_packs = 1
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
INFO:tensorflow:Reduce to /job:localhost/replica:0/task:0/device:CPU:0 then broadcast to ('/job:localhost/replica:0/task:0/device:CPU:0',).
2023-12-22 12:31:02.824292: W tensorflow/core/grappler/optimizers/loop_optimizer.cc:933] Skipping loop optimization for Merge node with control input: while/body/_121/while/replica_1/Losses/alpha_loss/write_summary/summary_cond/branch_executed/_1946
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
[reverb/cc/client.cc:165] Sampler and server are owned by the same process (26631) so Table uniform_table is accessed directly without gRPC.
step = 5000: loss = -54.42484664916992
step = 10000: AverageReturn = -0.739843, AverageEpisodeLength = 292.600006
step = 10000: loss = -54.64984130859375
step = 15000: loss = -35.02790451049805
step = 20000: AverageReturn = -1.259167, AverageEpisodeLength = 441.850006
step = 20000: loss = -26.131771087646484
step = 25000: loss = -19.544872283935547
step = 30000: AverageReturn = -0.818176, AverageEpisodeLength = 466.200012
step = 30000: loss = -13.54043197631836
step = 35000: loss = -10.158345222473145
step = 40000: AverageReturn = -1.347950, AverageEpisodeLength = 601.700012
step = 40000: loss = -6.913794040679932
step = 45000: loss = -5.61244010925293
step = 50000: AverageReturn = -1.182192, AverageEpisodeLength = 483.950012
step = 50000: loss = -4.762404441833496
step = 55000: loss = -3.82161545753479
step = 60000: AverageReturn = -1.674075, AverageEpisodeLength = 623.400024
step = 60000: loss = -4.256121635437012
step = 65000: loss = -3.6529903411865234
step = 70000: AverageReturn = -1.215892, AverageEpisodeLength = 728.500000
step = 70000: loss = -4.215447902679443
step = 75000: loss = -4.645144462585449
step = 80000: AverageReturn = -1.224958, AverageEpisodeLength = 615.099976
step = 80000: loss = -4.062835693359375
step = 85000: loss = -2.9989473819732666
step = 90000: AverageReturn = -0.896713, AverageEpisodeLength = 508.149994
step = 90000: loss = -3.086637020111084
step = 95000: loss = -3.242603302001953
step = 100000: AverageReturn = -0.280301, AverageEpisodeLength = 354.649994
step = 100000: loss = -3.288505792617798
[reverb/cc/platform/default/server.cc:84] Shutting down replay server
Visualization
Plots
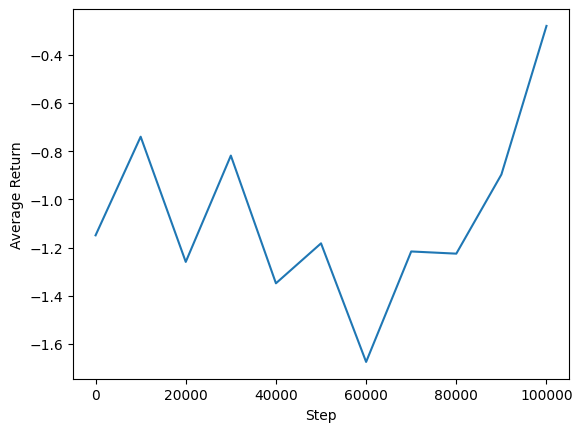
We can plot average return vs global steps to see the performance of our agent. In Minitaur, the reward function is based on how far the minitaur walks in 1000 steps and penalizes the energy expenditure.
steps = range(0, num_iterations + 1, eval_interval)
plt.plot(steps, returns)
plt.ylabel('Average Return')
plt.xlabel('Step')
plt.ylim()
(-1.743763194978237, -0.210612578690052)
Videos
It is helpful to visualize the performance of an agent by rendering the environment at each step. Before we do that, let us first create a function to embed videos in this colab.
def embed_mp4(filename):
"""Embeds an mp4 file in the notebook."""
video = open(filename,'rb').read()
b64 = base64.b64encode(video)
tag = '''
<video width="640" height="480" controls>
<source src="data:video/mp4;base64,{0}" type="video/mp4">
Your browser does not support the video tag.
</video>'''.format(b64.decode())
return IPython.display.HTML(tag)
The following code visualizes the agent's policy for a few episodes:
num_episodes = 3
video_filename = 'sac_minitaur.mp4'
with imageio.get_writer(video_filename, fps=60) as video:
for _ in range(num_episodes):
time_step = eval_env.reset()
video.append_data(eval_env.render())
while not time_step.is_last():
action_step = eval_actor.policy.action(time_step)
time_step = eval_env.step(action_step.action)
video.append_data(eval_env.render())
embed_mp4(video_filename)