
Copyright 2023 The TF-Agents Authors.
Get Started
|
|
|
 View source on GitHub
View source on GitHub
|
|
This tutorial is a step-by-step guide on how to use the TF-Agents library for contextual bandits problems where the actions (arms) have their own features, such as a list of movies represented by features (genre, year of release, ...).
Prerequisite
It is assumed that the reader is somewhat familiar with the Bandit library of TF-Agents, in particular, has worked through the tutorial for Bandits in TF-Agents before reading this tutorial.
Multi-Armed Bandits with Arm Features
In the "classic" Contextual Multi-Armed Bandits setting, an agent receives a context vector (aka observation) at every time step and has to choose from a finite set of numbered actions (arms) so as to maximize its cumulative reward.
Now consider the scenario where an agent recommends to a user the next movie to watch. Every time a decision has to be made, the agent receives as context some information about the user (watch history, genre preference, etc...), as well as the list of movies to choose from.
We could try to formulate this problem by having the user information as the context and the arms would be movie_1, movie_2, ..., movie_K, but this approach has multiple shortcomings:
- The number of actions would have to be all the movies in the system and it is cumbersome to add a new movie.
- The agent has to learn a model for every single movie.
- Similarity between movies is not taken into account.
Instead of numbering the movies, we can do something more intuitive: we can represent movies with a set of features including genre, length, cast, rating, year, etc. The advantages of this approach are manifold:
- Generalisation across movies.
- The agent learns just one reward function that models reward with user and movie features.
- Easy to remove from, or introduce new movies to the system.
In this new setting, the number of actions does not even have to be the same in every time step.
Per-Arm Bandits in TF-Agents
The TF-Agents Bandit suite is developed so that one can use it for the per-arm case as well. There are per-arm environments, and also most of the policies and agents can operate in per-arm mode.
Before we dive into coding an example, we need the necessery imports.
Installation
pip install tf-agentspip install tf-keras
import os
# Keep using keras-2 (tf-keras) rather than keras-3 (keras).
os.environ['TF_USE_LEGACY_KERAS'] = '1'
Imports
import functools
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from tf_agents.bandits.agents import lin_ucb_agent
from tf_agents.bandits.environments import stationary_stochastic_per_arm_py_environment as p_a_env
from tf_agents.bandits.metrics import tf_metrics as tf_bandit_metrics
from tf_agents.drivers import dynamic_step_driver
from tf_agents.environments import tf_py_environment
from tf_agents.replay_buffers import tf_uniform_replay_buffer
from tf_agents.specs import tensor_spec
from tf_agents.trajectories import time_step as ts
nest = tf.nest
Parameters -- Feel Free to Play Around
# The dimension of the global features.
GLOBAL_DIM = 40
# The elements of the global feature will be integers in [-GLOBAL_BOUND, GLOBAL_BOUND).
GLOBAL_BOUND = 10
# The dimension of the per-arm features.
PER_ARM_DIM = 50
# The elements of the PER-ARM feature will be integers in [-PER_ARM_BOUND, PER_ARM_BOUND).
PER_ARM_BOUND = 6
# The variance of the Gaussian distribution that generates the rewards.
VARIANCE = 100.0
# The elements of the linear reward parameter will be integers in [-PARAM_BOUND, PARAM_BOUND).
PARAM_BOUND = 10
NUM_ACTIONS = 70
BATCH_SIZE = 20
# Parameter for linear reward function acting on the
# concatenation of global and per-arm features.
reward_param = list(np.random.randint(
-PARAM_BOUND, PARAM_BOUND, [GLOBAL_DIM + PER_ARM_DIM]))
A Simple Per-Arm Environment
The stationary stochastic environment, explained in the other tutorial, has a per-arm counterpart.
To initialize the per-arm environment, one has to define functions that generate
- global and per-arm features: These functions have no input parameters and generate a single (global or per-arm) feature vector when called.
- rewards: This function takes as parameter the concatenation of a global and a per-arm feature vector, and generates a reward. Basically this is the function that the agent will have to "guess". It is worth noting here that in the per-arm case the reward function is identical for every arm. This is a fundamental difference from the classic bandit case, where the agent has to estimate reward functions for each arm independently.
def global_context_sampling_fn():
"""This function generates a single global observation vector."""
return np.random.randint(
-GLOBAL_BOUND, GLOBAL_BOUND, [GLOBAL_DIM]).astype(np.float32)
def per_arm_context_sampling_fn():
""""This function generates a single per-arm observation vector."""
return np.random.randint(
-PER_ARM_BOUND, PER_ARM_BOUND, [PER_ARM_DIM]).astype(np.float32)
def linear_normal_reward_fn(x):
"""This function generates a reward from the concatenated global and per-arm observations."""
mu = np.dot(x, reward_param)
return np.random.normal(mu, VARIANCE)
Now we are equipped to initialize our environment.
per_arm_py_env = p_a_env.StationaryStochasticPerArmPyEnvironment(
global_context_sampling_fn,
per_arm_context_sampling_fn,
NUM_ACTIONS,
linear_normal_reward_fn,
batch_size=BATCH_SIZE
)
per_arm_tf_env = tf_py_environment.TFPyEnvironment(per_arm_py_env)
Below we can check what this environment produces.
print('observation spec: ', per_arm_tf_env.observation_spec())
print('\nAn observation: ', per_arm_tf_env.reset().observation)
action = tf.zeros(BATCH_SIZE, dtype=tf.int32)
time_step = per_arm_tf_env.step(action)
print('\nRewards after taking an action: ', time_step.reward)
observation spec: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None), 'per_arm': TensorSpec(shape=(70, 50), dtype=tf.float32, name=None)}
An observation: {'global': <tf.Tensor: shape=(20, 40), dtype=float32, numpy=
array([[ -4., 8., -5., 7., -3., -7., -1., 8., 4., 2., -8.,
5., 9., 7., 4., -6., -1., 1., -10., 1., 3., 1.,
3., 8., -4., 1., 5., -8., 1., -10., 7., 7., -5.,
8., -4., 7., 4., -3., -5., 9.],
[ 9., 2., 3., 1., -2., 7., 6., 2., -9., -3., -2.,
8., 5., -1., 6., -4., 2., -2., -5., 6., -2., -10.,
-3., 3., -7., 5., -3., 4., -2., 0., 2., -4., -6.,
2., 1., -4., 9., -1., 8., -3.],
[ 3., 9., -3., 8., -1., 0., 9., 9., 6., 8., 2.,
1., -5., -3., -4., 7., -7., -4., 2., 3., 4., -4.,
6., -3., -3., 7., 2., 1., -3., -8., 7., -2., 2.,
5., -5., 4., 6., 7., 9., 2.],
[ -2., 7., 8., -3., 8., -10., -9., -5., 7., 9., 0.,
-3., -1., -10., 2., 8., -8., 4., -2., 6., 3., -4.,
-8., -10., 9., -2., -8., -7., -4., 0., 6., -3., 9.,
-4., 1., -5., 4., 2., -2., 0.],
[ -6., 5., -8., 3., 2., 2., -8., 4., -6., 6., 0.,
3., 4., -4., 2., -10., -7., 3., 6., 9., -9., -2.,
6., 0., -4., 8., 0., -4., 0., 3., -3., 9., 0.,
-5., 0., 5., -7., -2., 0., 3.],
[ 4., 9., -2., -6., -3., -10., -2., 8., 8., 3., 0.,
3., -1., -9., 1., -6., 8., -5., 1., 2., 3., -3.,
4., 7., 8., -8., 0., -3., 1., 0., -4., -7., -2.,
-5., -6., 4., -2., 3., 1., -4.],
[ -3., -2., 7., -5., -7., -3., 0., -1., 8., -6., 1.,
9., -9., -6., 3., 2., -6., 6., -10., 6., -6., 6.,
-5., 3., -7., -4., 6., 4., -7., -4., -5., 1., -10.,
5., -6., -9., -3., -2., -10., -4.],
[ 7., 9., 2., 4., -4., -7., 4., -6., 2., 9., 7.,
8., -10., 7., 6., 7., -4., -1., -4., 8., -4., -9.,
-6., -1., 7., -8., -5., -6., -3., 2., -5., 9., -6.,
-6., 8., -2., -1., -2., -5., -6.],
[ 5., 7., 7., -8., -3., 9., 6., 7., 1., -3., -2.,
7., -5., 5., 0., -7., 2., -1., -1., 6., -8., -2.,
-10., 6., 2., 8., 0., 3., 1., -7., 5., 3., 4.,
8., -2., -2., -8., 8., 5., 0.],
[ 1., 0., -2., -6., 7., 8., -5., -8., -7., -8., -4.,
-9., 3., -9., 8., -4., -1., -10., 2., -1., 1., -4.,
6., -1., 4., 1., -7., -4., -8., -6., 7., 4., -8.,
-3., -7., 5., -1., -4., -10., -4.],
[ -7., 4., 0., -9., -8., -6., -7., 8., 3., 7., -7.,
-1., 7., -3., 5., 6., 1., -5., 3., -10., -7., 0.,
-4., -4., -7., 2., -5., 3., 2., -3., 3., -7., -1.,
-10., 9., 1., -2., 3., 4., -8.],
[ 8., -5., -10., 7., 7., -7., 2., 7., -1., -10., 6.,
-4., -5., -3., -8., -2., -2., 3., 1., 2., 1., -6.,
8., -7., 7., 8., -8., -10., 2., -7., 1., -2., -3.,
-6., 9., 4., 2., -1., -7., -1.],
[ 2., 5., -2., -10., -2., 2., 2., -9., -9., -8., -1.,
-7., -9., -4., -2., -3., -9., -3., 5., 5., -1., 0.,
8., -8., 9., -3., 8., 9., 7., -8., 4., -7., 0.,
1., -1., 1., 0., 8., -1., -10.],
[ -6., -1., 9., 4., -8., -5., 8., 0., -10., -10., -10.,
-3., 8., -7., -2., -2., -10., 2., -3., -9., 0., 7.,
0., 2., -7., -6., -6., 3., 2., 6., 8., 9., -10.,
7., -4., -9., 7., -9., 3., -5.],
[ -2., 4., 1., 7., -5., -7., -1., -8., -9., -1., -7.,
4., -7., -7., 7., -2., -5., 3., -10., 9., 9., -5.,
1., 4., 5., 0., -1., 5., 9., 1., 8., -9., -9.,
6., -6., -9., 6., 7., 5., 9.],
[-10., -3., -5., 7., -9., -4., 7., -9., -2., 3., -1.,
-5., -9., -7., -6., 6., -4., -7., 2., 0., 1., -10.,
-3., -10., -7., -4., -9., 0., 3., -8., -7., 7., -2.,
3., 1., 3., -9., -2., -9., -3.],
[ 8., 3., -4., -2., -7., -9., -10., -1., 1., -5., 0.,
6., 0., 5., 9., -3., -10., 5., 9., 0., -8., -2.,
4., 8., 3., 5., 0., -6., -5., -2., -1., 3., -2.,
-3., -1., 8., -1., 1., -1., 5.],
[ -8., 3., -6., 4., -8., 8., -8., 4., 2., 1., 4.,
-8., -9., 8., -8., 3., 2., 0., -10., -5., 5., -3.,
-7., -3., 1., 1., -7., 9., 1., -3., 8., 8., 1.,
7., -2., -9., -3., -6., -1., -10.],
[-10., -5., 4., 4., -9., -5., -8., 6., 5., -9., -8.,
4., -7., 2., 7., 2., 6., -1., 0., 8., -6., 3.,
2., 7., -2., -7., -7., -3., 5., 1., 9., 8., 2.,
-1., 3., -5., 6., -1., -9., -8.],
[ -6., -8., -7., -2., -10., 7., 3., -2., -8., 7., -8.,
-10., 7., 8., -2., 6., 3., 6., -1., 0., -6., -7.,
7., 2., -4., 7., -9., -5., 2., 1., -1., -9., 7.,
9., -5., -10., 6., 9., 6., -2.]], dtype=float32)>, 'per_arm': <tf.Tensor: shape=(20, 70, 50), dtype=float32, numpy=
array([[[ 0., 5., 3., ..., -2., 0., -4.],
[-5., 5., -5., ..., 3., 3., 4.],
[ 1., -6., 2., ..., 0., -4., -1.],
...,
[ 1., -3., -5., ..., -5., 4., 3.],
[ 3., -4., 0., ..., -5., -4., 2.],
[-3., -4., -6., ..., -1., -5., -2.]],
[[ 3., -3., -6., ..., -2., -4., -1.],
[-5., 5., -4., ..., -1., 3., -1.],
[-4., 4., 5., ..., 3., -3., -3.],
...,
[-4., -4., 5., ..., -2., 0., -4.],
[ 5., -6., 1., ..., -1., -5., -5.],
[ 5., -4., 5., ..., 4., -4., -4.]],
[[-3., 4., 0., ..., 1., 0., 0.],
[ 1., -1., -5., ..., -4., 5., -4.],
[ 2., 4., 1., ..., -6., -4., -4.],
...,
[ 0., 3., 4., ..., -6., -4., 1.],
[ 3., 5., -5., ..., 5., -2., 4.],
[ 3., -5., 4., ..., 2., -3., -5.]],
...,
[[ 1., -5., -3., ..., -1., -1., 1.],
[-5., 2., -4., ..., -3., 4., -6.],
[-3., -3., 1., ..., 0., -3., -1.],
...,
[-1., 2., -2., ..., -4., 3., 1.],
[-4., 1., -3., ..., 2., -5., -5.],
[-4., -4., -2., ..., 4., -6., -4.]],
[[ 3., 4., 5., ..., -5., -2., -1.],
[-6., 4., -4., ..., 3., -5., -3.],
[ 2., -3., 5., ..., -2., 2., 1.],
...,
[ 4., 2., -1., ..., -5., 5., 1.],
[ 1., -6., 2., ..., 3., 3., 0.],
[ 0., 4., -6., ..., 4., 4., -6.]],
[[ 0., 5., -4., ..., 4., 1., -6.],
[ 3., -1., 4., ..., 1., -1., -2.],
[ 0., -4., -1., ..., 5., 0., 3.],
...,
[ 0., 1., -3., ..., 0., 5., 4.],
[-1., 4., -6., ..., 2., -4., -1.],
[ 4., -2., -6., ..., -5., -5., 5.]]], dtype=float32)>}
Rewards after taking an action: tf.Tensor(
[-496.27966 94.56397 47.344288 326.10242 82.47867
-287.3221 -148.02356 184.77959 330.40982 -78.458405
436.3813 -13.64361 251.81743 375.51117 6.9300766
414.30618 434.41226 373.14758 374.16064 229.50754 ], shape=(20,), dtype=float32)
We see that the observation spec is a dictionary with two elements:
- One with key
'global': this is the global context part, with shape matching the parameterGLOBAL_DIM. - One with key
'per_arm': this is the per-arm context, and its shape is[NUM_ACTIONS, PER_ARM_DIM]. This part is the placeholder for the arm features for every arm in a time step.
The LinUCB Agent
The LinUCB agent implements the identically named Bandit algorithm, which estimates the parameter of the linear reward function while also maintains a confidence ellipsoid around the estimate. The agent chooses the arm that has the highest estimated expected reward, assuming that the parameter lies within the confidence ellipsoid.
Creating an agent requires the knowledge of the observation and the action specification. When defining the agent, we set the boolean parameter accepts_per_arm_features set to True.
observation_spec = per_arm_tf_env.observation_spec()
time_step_spec = ts.time_step_spec(observation_spec)
action_spec = tensor_spec.BoundedTensorSpec(
dtype=tf.int32, shape=(), minimum=0, maximum=NUM_ACTIONS - 1)
agent = lin_ucb_agent.LinearUCBAgent(time_step_spec=time_step_spec,
action_spec=action_spec,
accepts_per_arm_features=True)
The Flow of Training Data
This section gives a sneak peek into the mechanics of how per-arm features go from the policy to training. Feel free to jump to the next section (Defining the Regret Metric) and come back here later if interested.
First, let us have a look at the data specification in the agent. The training_data_spec attribute of the agent specifies what elements and structure the training data should have.
print('training data spec: ', agent.training_data_spec)
training data spec: Trajectory(
{'step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'observation': {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)},
'action': BoundedTensorSpec(shape=(), dtype=tf.int32, name=None, minimum=array(0, dtype=int32), maximum=array(69, dtype=int32)),
'policy_info': PerArmPolicyInfo(log_probability=(), predicted_rewards_mean=(), multiobjective_scalarized_predicted_rewards_mean=(), predicted_rewards_optimistic=(), predicted_rewards_sampled=(), bandit_policy_type=(), chosen_arm_features=TensorSpec(shape=(50,), dtype=tf.float32, name=None)),
'next_step_type': TensorSpec(shape=(), dtype=tf.int32, name='step_type'),
'reward': TensorSpec(shape=(), dtype=tf.float32, name='reward'),
'discount': BoundedTensorSpec(shape=(), dtype=tf.float32, name='discount', minimum=array(0., dtype=float32), maximum=array(1., dtype=float32))})
If we have a closer look to the observation part of the spec, we see that it does not contain per-arm features!
print('observation spec in training: ', agent.training_data_spec.observation)
observation spec in training: {'global': TensorSpec(shape=(40,), dtype=tf.float32, name=None)}
What happened to the per-arm features? To answer this question, first we note that when the LinUCB agent trains, it does not need the per-arm features of all arms, it only needs those of the chosen arm. Hence, it makes sense to drop the tensor of shape [BATCH_SIZE, NUM_ACTIONS, PER_ARM_DIM], as it is very wasteful, especially if the number of actions is large.
But still, the per-arm features of the chosen arm must be somewhere! To this end, we make sure that the LinUCB policy stores the features of the chosen arm within the policy_info field of the training data:
print('chosen arm features: ', agent.training_data_spec.policy_info.chosen_arm_features)
chosen arm features: TensorSpec(shape=(50,), dtype=tf.float32, name=None)
We see from the shape that the chosen_arm_features field has only the feature vector of one arm, and that will be the chosen arm. Note that the policy_info, and with it the chosen_arm_features, is part of the training data, as we saw from inspecting the training data spec, and thus it is available at training time.
Defining the Regret Metric
Before starting the training loop, we define some utility functions that help calculate the regret of our agent. These functions help determining the optimal expected reward given the set of actions (given by their arm features) and the linear parameter that is hidden from the agent.
def _all_rewards(observation, hidden_param):
"""Outputs rewards for all actions, given an observation."""
hidden_param = tf.cast(hidden_param, dtype=tf.float32)
global_obs = observation['global']
per_arm_obs = observation['per_arm']
num_actions = tf.shape(per_arm_obs)[1]
tiled_global = tf.tile(
tf.expand_dims(global_obs, axis=1), [1, num_actions, 1])
concatenated = tf.concat([tiled_global, per_arm_obs], axis=-1)
rewards = tf.linalg.matvec(concatenated, hidden_param)
return rewards
def optimal_reward(observation):
"""Outputs the maximum expected reward for every element in the batch."""
return tf.reduce_max(_all_rewards(observation, reward_param), axis=1)
regret_metric = tf_bandit_metrics.RegretMetric(optimal_reward)
Now we are all set for starting our bandit training loop. The driver below takes care of choosing actions using the policy, storing rewards of chosen actions in the replay buffer, calculating the predefined regret metric, and executing the training step of the agent.
num_iterations = 20 # @param
steps_per_loop = 1 # @param
replay_buffer = tf_uniform_replay_buffer.TFUniformReplayBuffer(
data_spec=agent.policy.trajectory_spec,
batch_size=BATCH_SIZE,
max_length=steps_per_loop)
observers = [replay_buffer.add_batch, regret_metric]
driver = dynamic_step_driver.DynamicStepDriver(
env=per_arm_tf_env,
policy=agent.collect_policy,
num_steps=steps_per_loop * BATCH_SIZE,
observers=observers)
regret_values = []
for _ in range(num_iterations):
driver.run()
loss_info = agent.train(replay_buffer.gather_all())
replay_buffer.clear()
regret_values.append(regret_metric.result())
WARNING:tensorflow:From /tmpfs/tmp/ipykernel_24657/1190294793.py:21: ReplayBuffer.gather_all (from tf_agents.replay_buffers.replay_buffer) is deprecated and will be removed in a future version. Instructions for updating: Use `as_dataset(..., single_deterministic_pass=True)` instead.
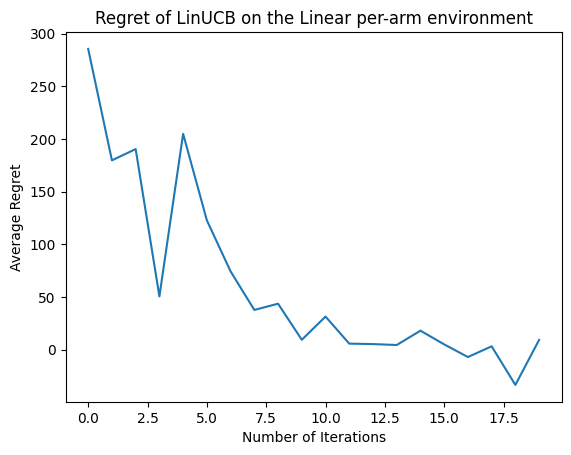
Now let's see the result. If we did everything right, the agent is able to estimate the linear reward function well, and thus the policy can pick actions whose expected reward is close to that of the optimal. This is indicated by our above defined regret metric, which goes down and approaches zero.
plt.plot(regret_values)
plt.title('Regret of LinUCB on the Linear per-arm environment')
plt.xlabel('Number of Iterations')
_ = plt.ylabel('Average Regret')
What's Next?
The above example is implemented in our codebase where you can choose from other agents as well, including the Neural epsilon-Greedy agent.