
The last few years have seen a rise in novel differentiable graphics layers which can be inserted in neural network architectures. From spatial transformers to differentiable graphics renderers, these new layers leverage the knowledge acquired over years of computer vision and graphics research to build new and more efficient network architectures. Explicitly modeling geometric priors and constraints into neural networks opens up the door to architectures that can be trained robustly, efficiently, and more importantly, in a self-supervised fashion.
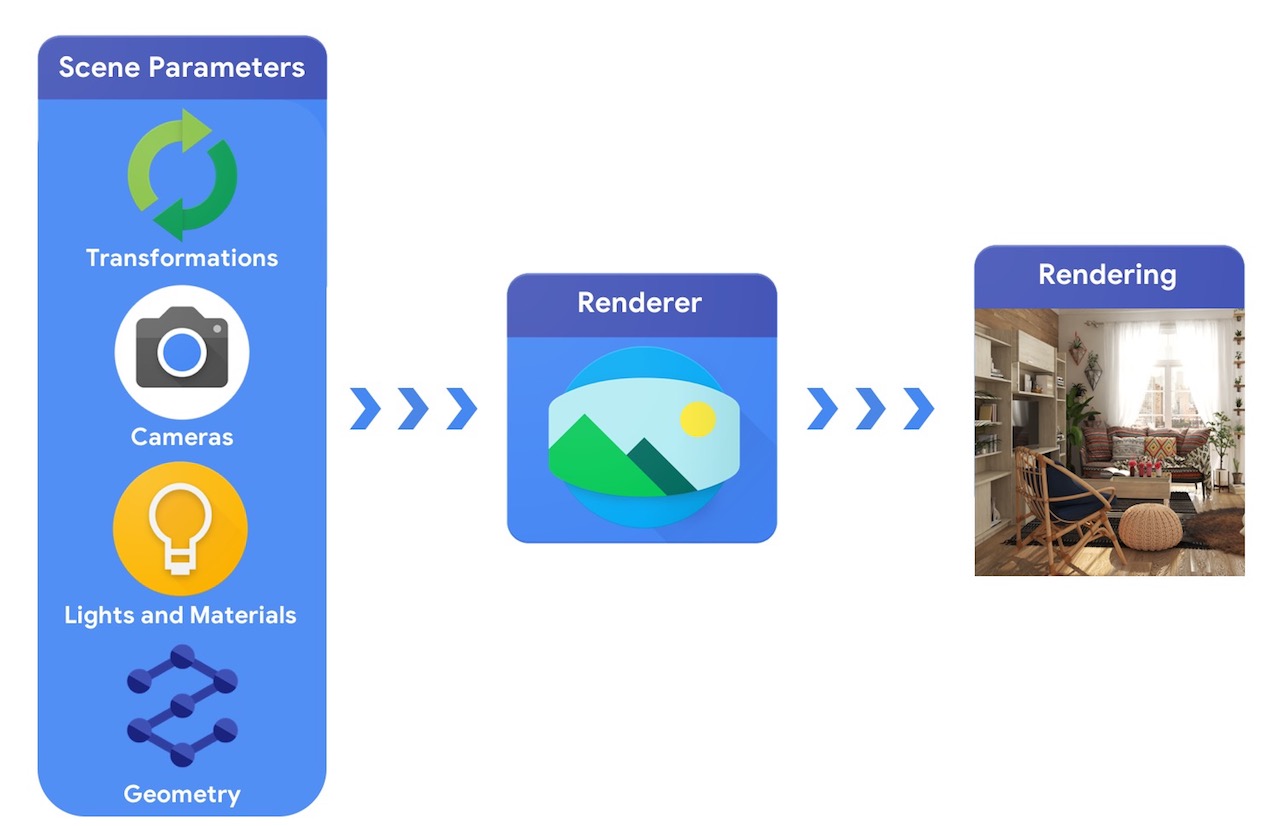
At a high level, a computer graphics pipeline requires a representation of 3D objects and their absolute positioning in the scene, a description of the material they are made of, lights and a camera. This scene description is then interpreted by a renderer to generate a synthetic rendering.
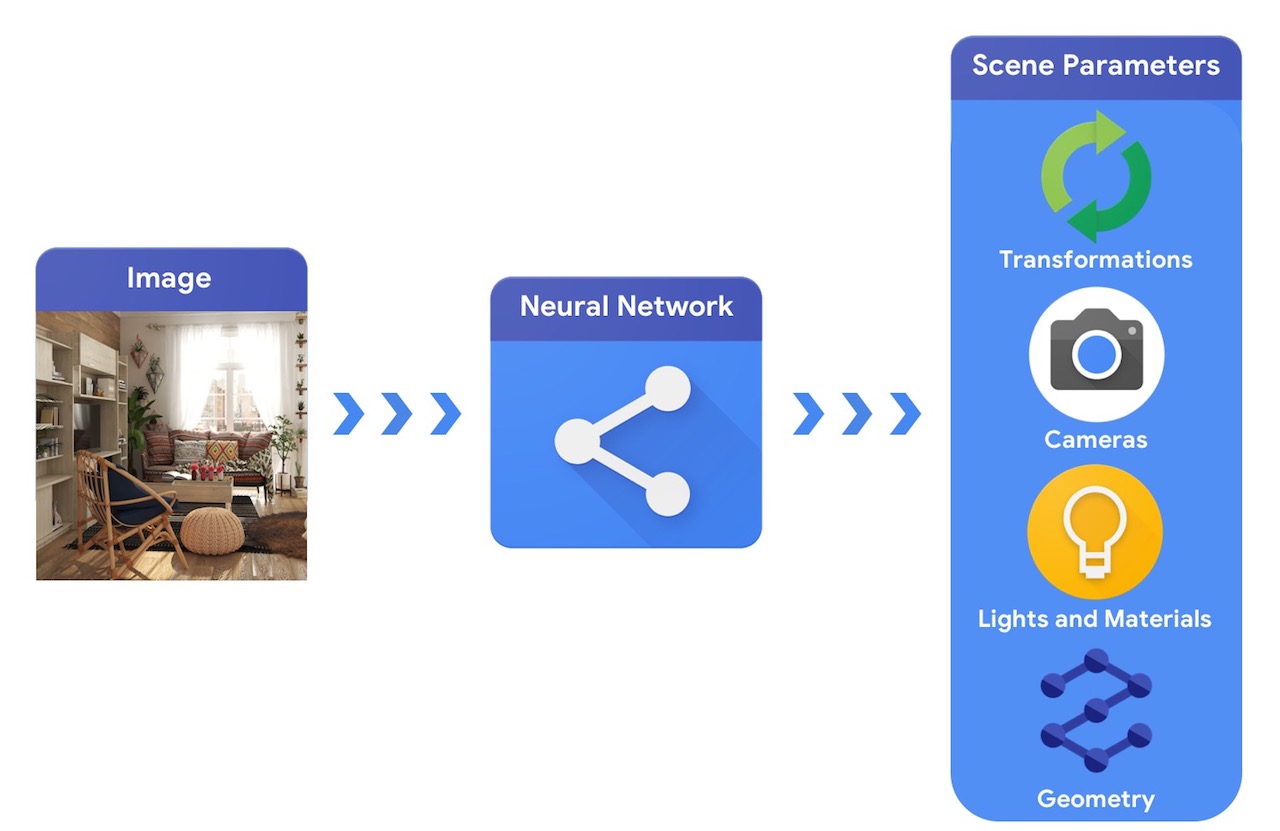
In comparison, a computer vision system would start from an image and try to infer the parameters of the scene. This allows the prediction of which objects are in the scene, what materials they are made of, and the three-dimensional position and orientation.
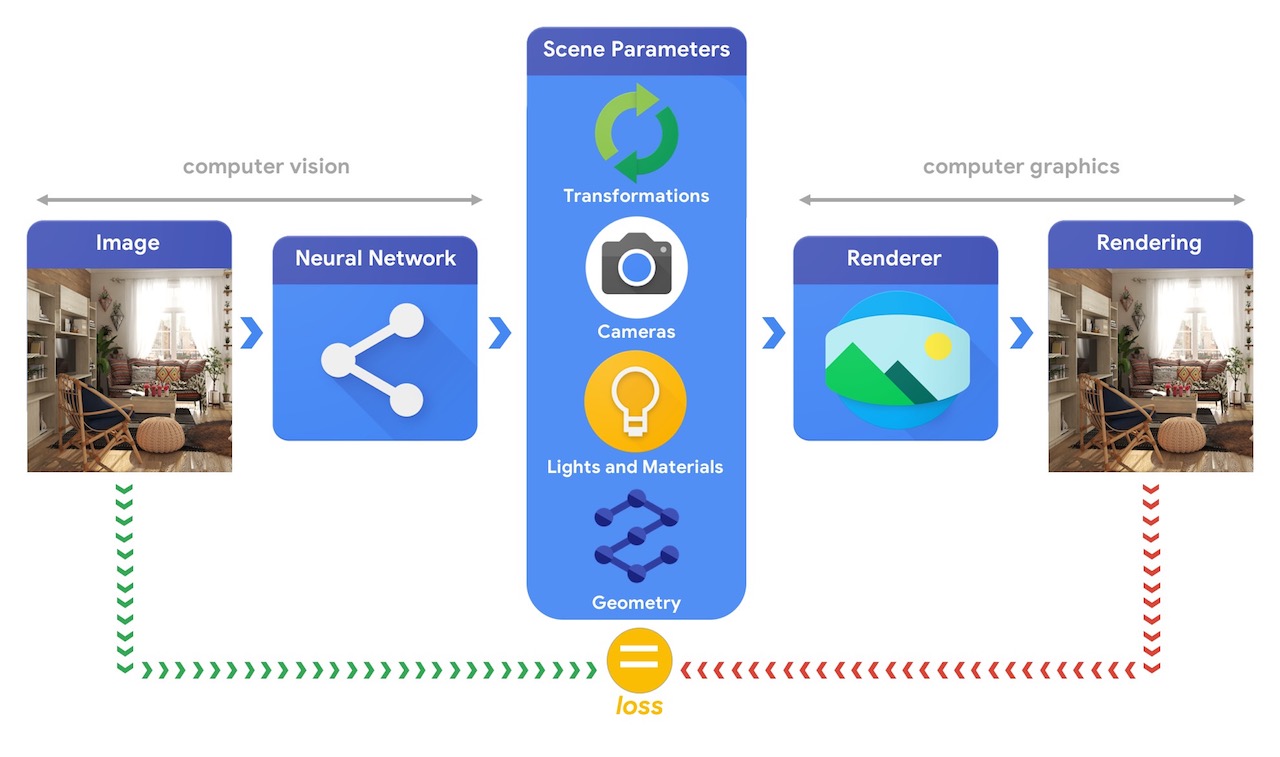
Training machine learning systems capable of solving these complex 3D vision tasks most often requires large quantities of data. As labelling data is a costly and complex process, it is important to have mechanisms to design machine learning models that can comprehend the three dimensional world while being trained without much supervision. Combining computer vision and computer graphics techniques provides a unique opportunity to leverage the vast amounts of readily available unlabelled data. As illustrated in the image below, this can, for instance, be achieved using analysis by synthesis where the vision system extracts the scene parameters and the graphics system renders back an image based on them. If the rendering matches the original image, the vision system has accurately extracted the scene parameters. In this setup, computer vision and computer graphics go hand in hand, forming a single machine learning system similar to an autoencoder, which can be trained in a self-supervised manner.
Tensorflow Graphics is being developed to help tackle these types of challenges and to do so, it provides a set of differentiable graphics and geometry layers (e.g. cameras, reflectance models, spatial transformations, mesh convolutions) and 3D viewer functionalities (e.g. 3D TensorBoard) that can be used to train and debug your machine learning models of choice.