
近几年,一种可以插入神经网络架构的新型可微分图形层开始兴起。从空间变换器到可微分图形渲染器,这些新型图形层利用多年的计算机视觉和图形学研究知识来构建更高效的新网络架构。将几何先验和约束显式建模到神经网络中,为能够以自监督的方式进行稳健、高效训练的架构打开了大门。
从高级层面来说,计算机图形流水线需要 3D 物体的表示以及它们在场景中的绝对位置、其材质的描述、灯光和相机。随后,渲染器利用此场景描述生成合成渲染。
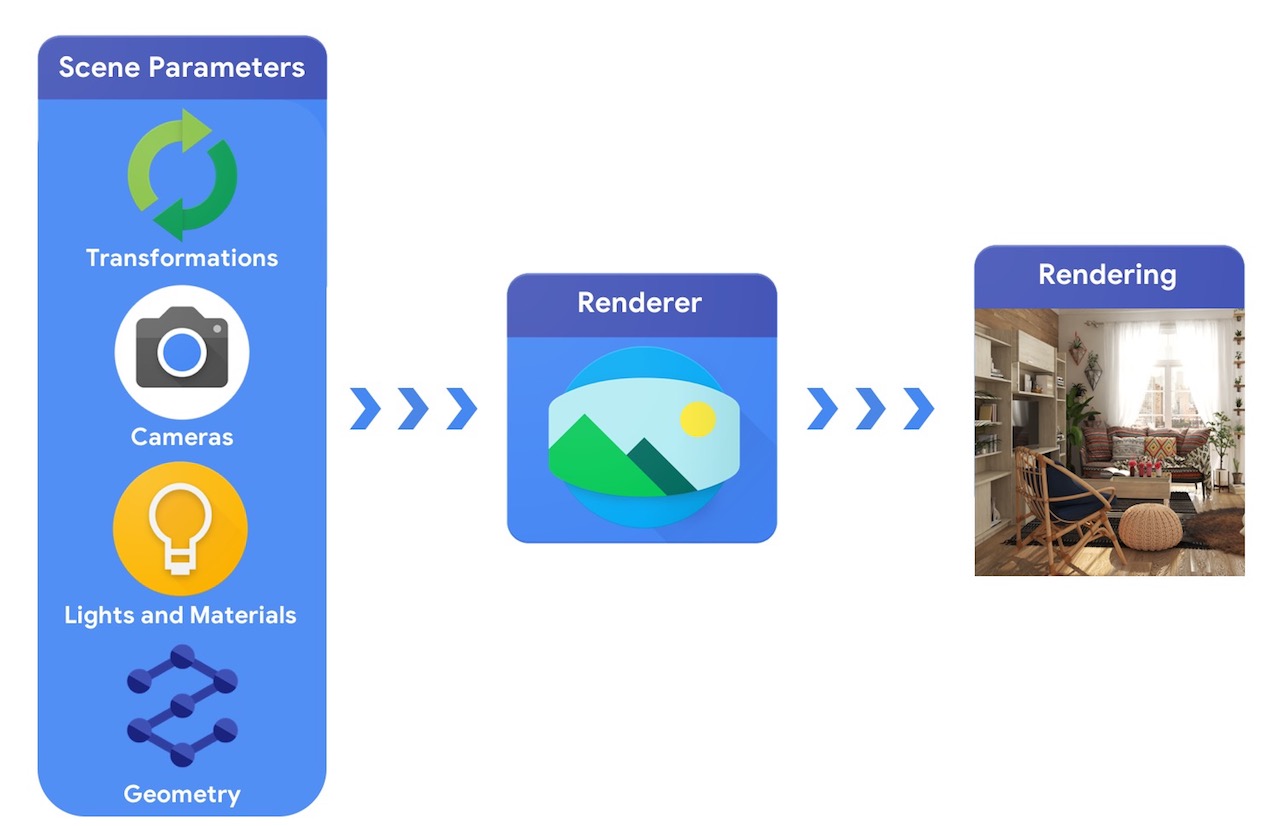
相比之下,计算机视觉系统从图像开始,尝试推断场景的参数。这样就可以预测场景中有哪些物体、它们的材质以及三维位置和方向。
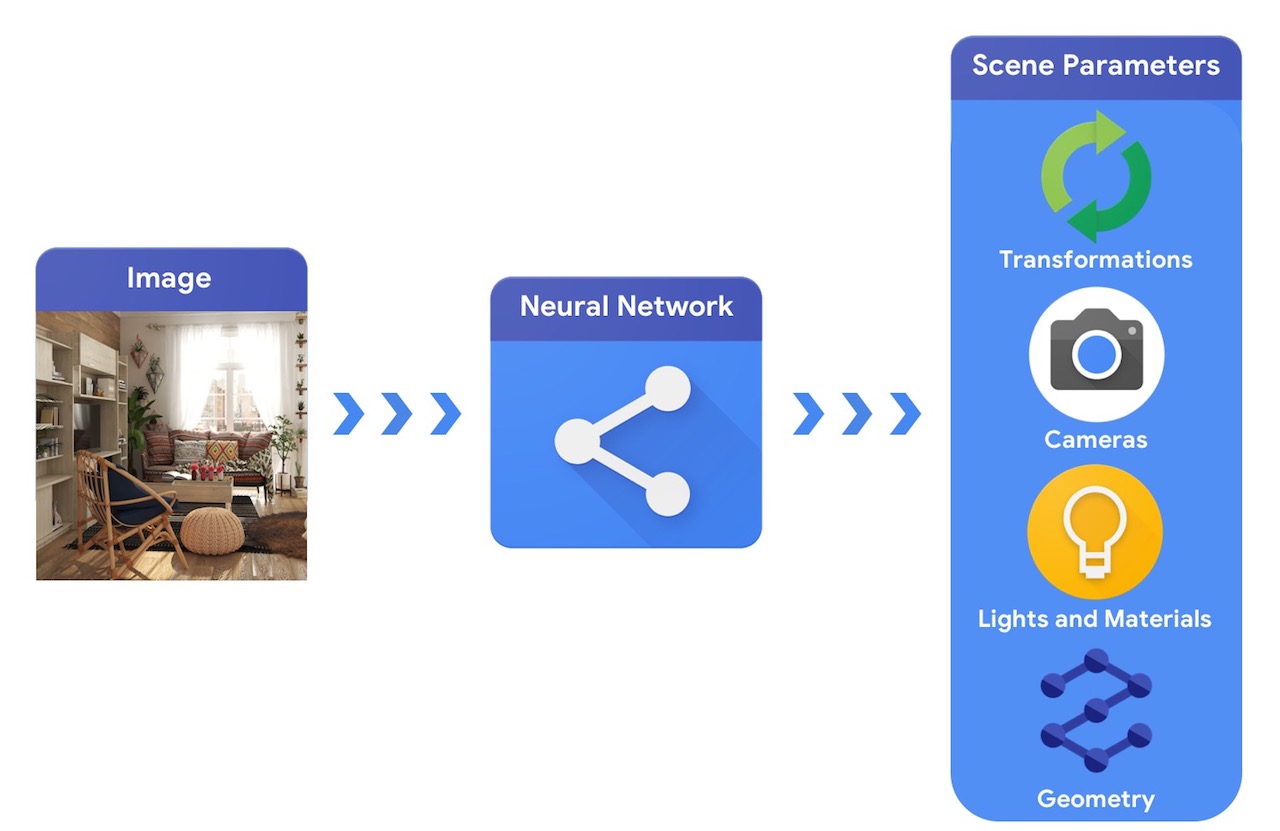
训练能够解决这些复杂 3D 视觉任务的机器学习系统通常需要大量数据。由于标注数据的过程既昂贵又复杂,因此设计能够理解三维世界且训练时无需太多监督的机器学习模型至关重要。结合计算机视觉和计算机图形学技术后,我们得以利用大量可用的未标注数据。如下图所示,这可以通过合成分析来实现:视觉系统提取场景参数,图形系统基于这些参数渲染图像。如果渲染结果与原始图像匹配,则说明视觉系统准确地提取了场景参数。在这种设置中,计算机视觉和计算机图形学相结合,形成了一个类似于自编码器的机器学习系统,这种系统能够以自监督的方式进行训练。
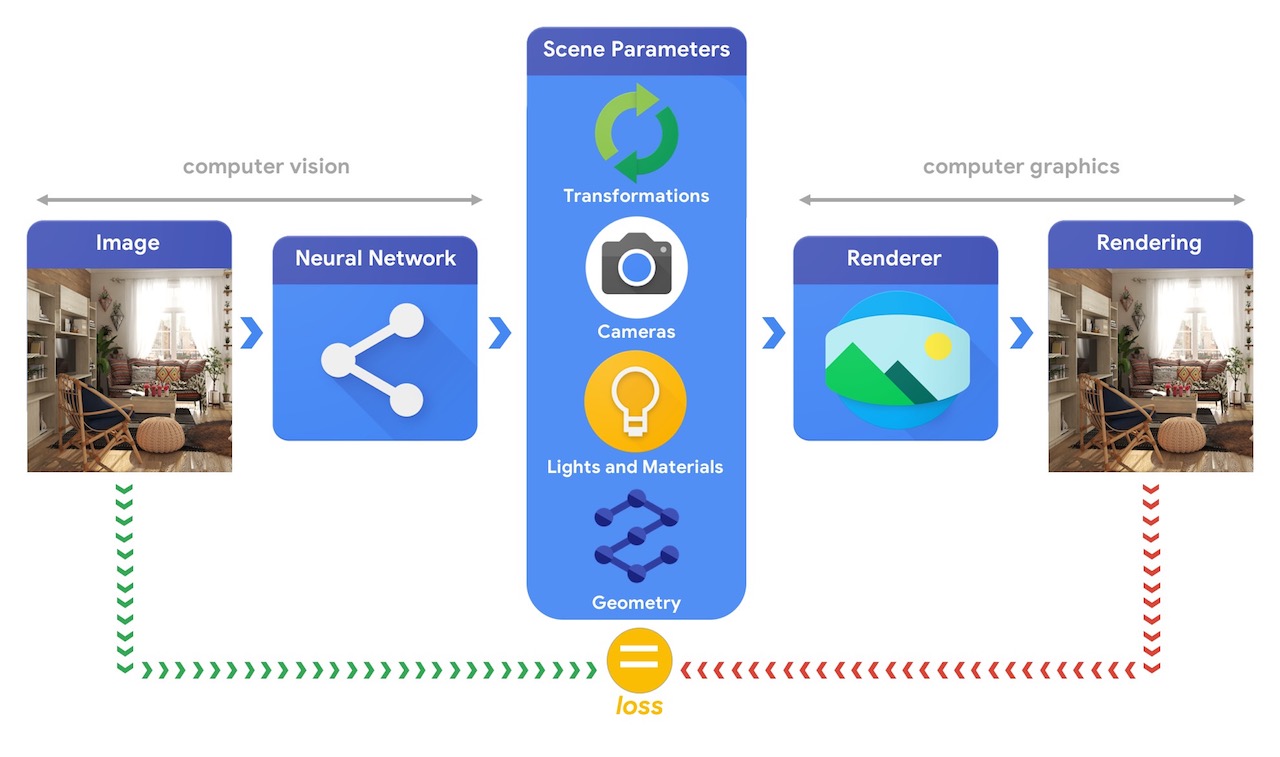
开发 Tensorflow Graphics 的目的是帮助解决这类挑战,为此,它提供了一组可微分图形和几何层(例如相机、反射模型、空间变换、网格卷积)以及 3D 查看器功能(例如 3D TensorBoard),可用于训练和调试您选择的机器学习模型。