
Ces dernières années ont vu se développer de nouvelles couches graphiques différentiables pouvant être insérées dans des architectures de réseaux de neurones. Des transformateurs spatiaux aux rendus graphiques différentiables, ces nouvelles couches tirent parti des connaissances acquises au fil des années de vision par ordinateur et de recherche graphique pour créer de nouvelles architectures de réseau plus efficaces. La modélisation explicite des priors géométriques et des contraintes dans les réseaux de neurones ouvre la porte à des architectures qui peuvent être formées de manière robuste, efficace et, plus important encore, de manière auto-supervisée.
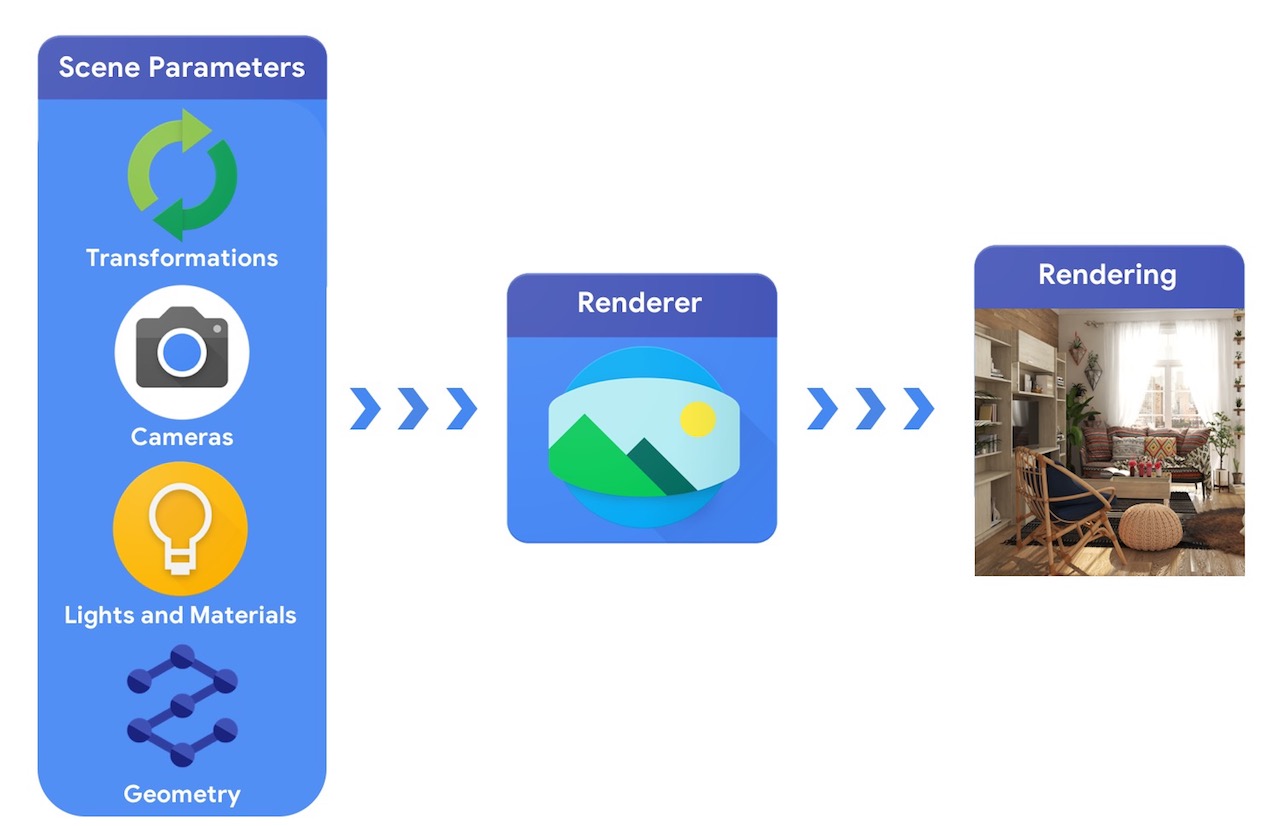
A haut niveau, un pipeline d'infographie nécessite une représentation des objets 3D et leur positionnement absolu dans la scène, une description du matériau qui les compose, des lumières et une caméra. Cette description de scène est ensuite interprétée par un moteur de rendu pour générer un rendu synthétique.
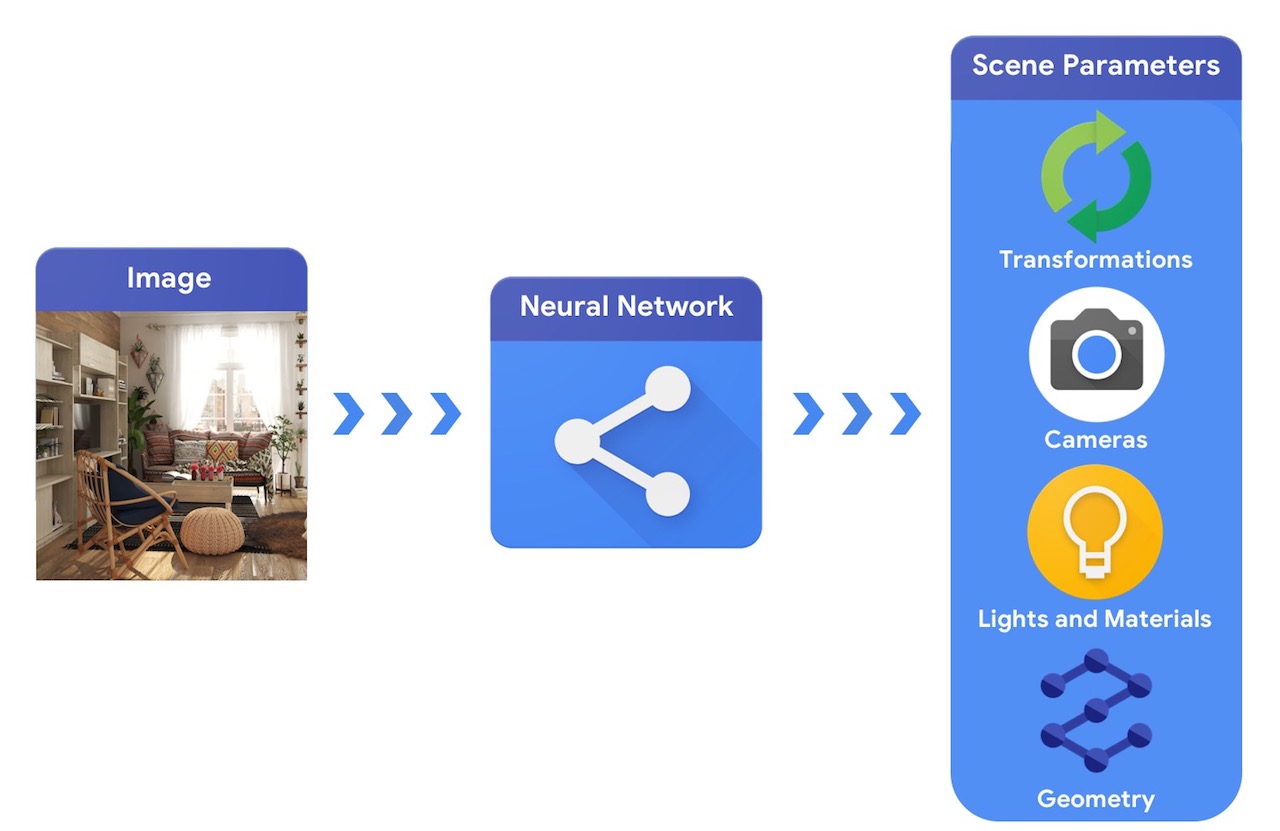
En comparaison, un système de vision par ordinateur partirait d'une image et tenterait d'en déduire les paramètres de la scène. Cela permet de prédire quels objets se trouvent dans la scène, de quels matériaux ils sont faits, ainsi que la position et l'orientation en trois dimensions.
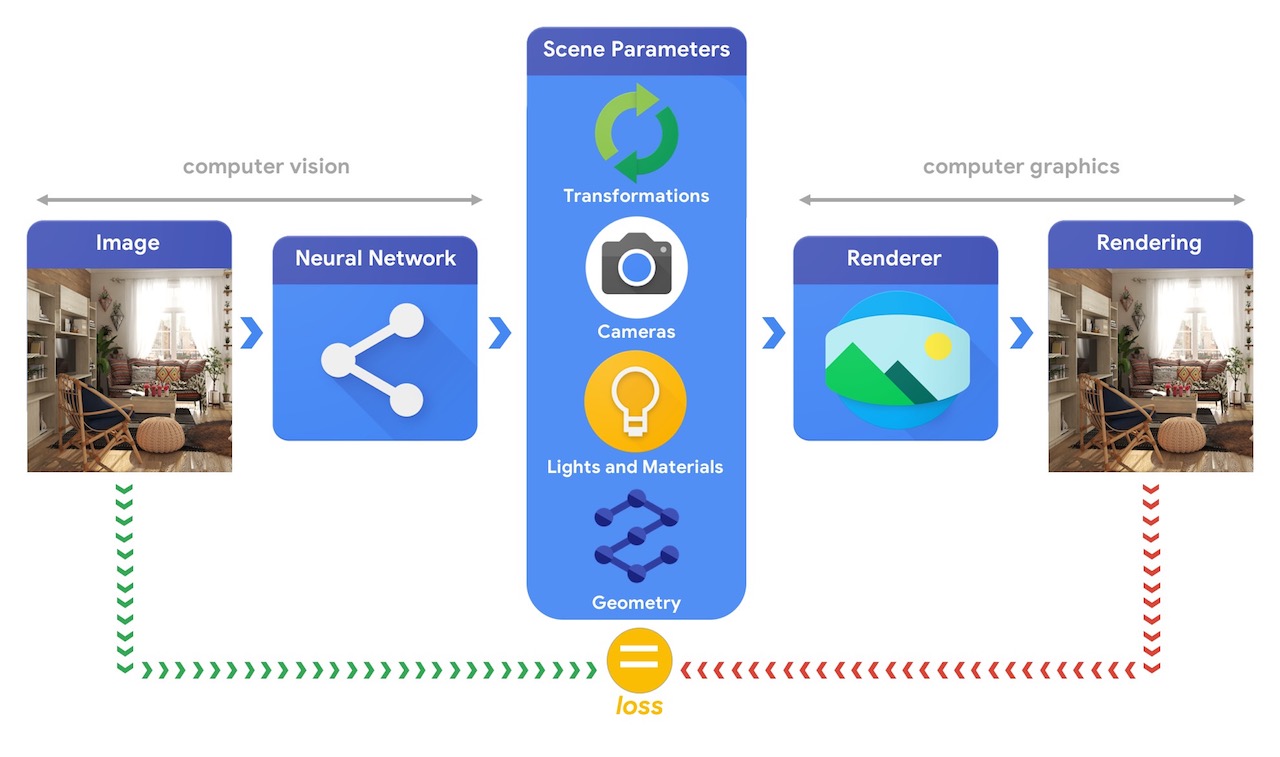
La formation de systèmes d'apprentissage automatique capables de résoudre ces tâches complexes de vision 3D nécessite le plus souvent de grandes quantités de données. Comme l'étiquetage des données est un processus coûteux et complexe, il est important de disposer de mécanismes pour concevoir des modèles d'apprentissage automatique capables de comprendre le monde en trois dimensions tout en étant entraînés sans trop de supervision. La combinaison des techniques de vision par ordinateur et d'infographie offre une occasion unique de tirer parti des vastes quantités de données non étiquetées facilement disponibles. Comme illustré dans l'image ci-dessous, cela peut, par exemple, être réalisé en utilisant une analyse par synthèse où le système de vision extrait les paramètres de la scène et le système graphique restitue une image basée sur eux. Si le rendu correspond à l'image d'origine, le système de vision a extrait avec précision les paramètres de la scène. Dans cette configuration, la vision par ordinateur et l'infographie vont de pair, formant un seul système d'apprentissage automatique similaire à un auto-encodeur, qui peut être formé de manière auto-supervisée.
Tensorflow Graphics est développé pour aider à relever ces types de défis et pour ce faire, il fournit un ensemble de couches graphiques et géométriques différenciables (par exemple, des caméras, des modèles de réflectance, des transformations spatiales, des convolutions de maillage) et des fonctionnalités de visualisation 3D (par exemple, 3D TensorBoard) qui peut être utilisé pour entraîner et déboguer les modèles d'apprentissage automatique de votre choix.