Flexible, controlled and interpretable ML with lattice based models
import numpy as np import tensorflow as tf import tensorflow_lattice as tfl model = tf.keras.models.Sequential() model.add( tfl.layers.ParallelCombination([ # Monotonic piece-wise linear calibration with bounded output tfl.layers.PWLCalibration( monotonicity='increasing', input_keypoints=np.linspace(1., 5., num=20), output_min=0.0, output_max=1.0), # Diminishing returns tfl.layers.PWLCalibration( monotonicity='increasing', convexity='concave', input_keypoints=np.linspace(0., 200., num=20), output_min=0.0, output_max=2.0), # Partially monotonic categorical calibration: calib(0) <= calib(1) tfl.layers.CategoricalCalibration( num_buckets=4, output_min=0.0, output_max=1.0, monotonicities=[(0, 1)]), ])) model.add( tfl.layers.Lattice( lattice_sizes=[2, 3, 2], monotonicities=['increasing', 'increasing', 'increasing'], # Trust: model is more responsive to input 0 if input 1 increases edgeworth_trusts=(0, 1, 'positive'))) model.compile(...)
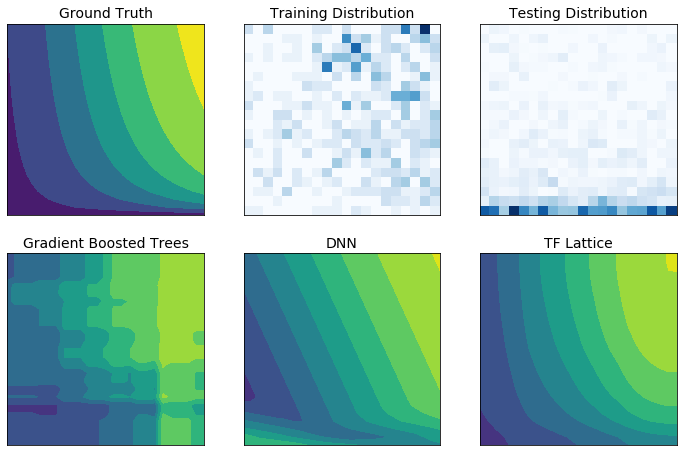
TensorFlow Lattice is a library that implements constrained and interpretable lattice based models. The library enables you to inject domain knowledge into the learning process through common-sense or policy-driven shape constraints. This is done using a collection of Keras layers that can satisfy constraints such as monotonicity, convexity and how features interact. The library also provides easy to setup premade models.
With TF Lattice you can use domain knowledge to better extrapolate to the parts of the input space not covered by the training dataset. This helps avoid unexpected model behaviour when the serving distribution is different from the training distribution.