
ベータ版: Android 用アクセラレーションサービスは現在ベータ段階にあります。詳細については、このページの注意事項と 利用規約 セクションをご覧ください。
ハードウェアアクセラレーションに GPU、NPU、DSP などの専用プロセッサを使用すると、ML対応 Android アプリケーションの推論パフォーマンス(一部のケースでは最大 10 倍の速度)とユーザーエクスペリエンスが大幅に改善されます。ただし、ユーザーが使用するハードウェアとドライバーは様々であるため、ユーザーのデバイスに最適なハードウェアアクセラレーション構成を選択するのは困難です。また、デバイスで誤った構成を有効にしてしまうと、ハードウェアの相性により、高い遅延や、一部のケースではランタイムエラーまたは精度に関わる問題が発生し、ユーザーエクスペリエンスが損なわれてしまう可能性もあります。
Android 用アクセラレーションサービスは、ランタイムエラーや精度問題のリスクを最小限に抑えながら、特定のユーザーデバイスと .tflite モデルに最適なハードウェアアクセラレーション構成を選択できるようにする API です。
アクセラレーションサービスは、TensorFlow Lite モデルで内部推論ベンチマークを実行して、ユーザーデバイス上で様々なアクセラレーション構成を評価します。これらのテストの実行は、モデルにもよりますが、通常数秒で完了します。ベンチマーク各ユーザーのデバイス上で推論時間の前に実行し、キャッシュすれば、推論中に使用できます。これらのベンチマークはプロセス外で実行されるため、アプリがクラッシュするリスクが最小限に抑えられます。
モデル、データサンプル、および期待される結果(「ゴールデン」入力と出力)を提供すれば、アクセラレーションサービスが内部の TFLite 推論ベンチマークを実行し、ハードウェアの推奨を提示します。
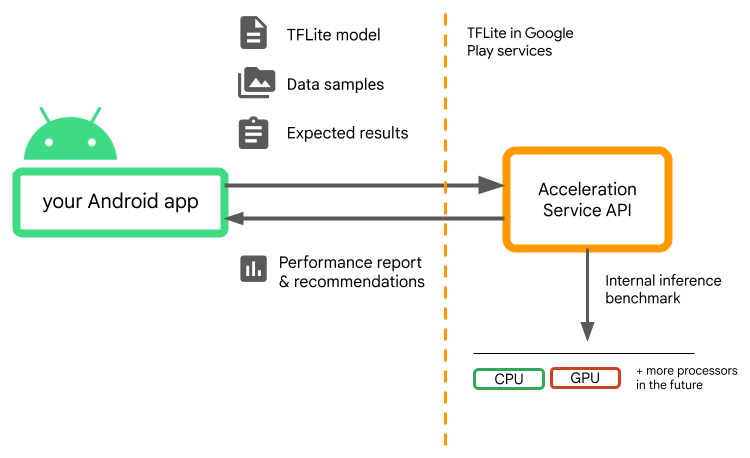
アクセラレーションサービスは Android のカスタム ML スタックの一部であり、Google Play Services の TensorFlow Lite と連携します。
プロジェクトに依存関係を追加する
アプリケーションの build.gradle ファイルに、以下の依存関係を追加します。
implementation "com.google.android.gms:play-services-tflite-
acceleration-service:16.0.0-beta01"
Acceleration Service API は Google Play Services で TensorFlow Lite と連携します。Play Services 経由で提供される TensorFlow Lite をまだ使用していない場合は、依存関係を更新する必要があります。
Acceleration Service API の使用方法
アクセラレーションサービスを使用するには、モデルに対して評価したいアクセラレーション構成(OpenGL による GPU など)を作成することから始めます。次に、モデル、サンプルデータ、および期待されるモデルの出力によって、検証構成を作成します。最後に、validateConfig() を呼び出して、アクセラレーション構成と検証構成を渡します。

アクセラレーション構成を作成する
アクセラレーション構成は、実行時にデリゲートに変換されるハードウェア構成の表現です。アクセラレーションサービスは、これらの構成を内部的に使用して、テスト推論を実行します。
現時点では、アクセラレーションサービスでは、GPU 構成(実行時に GPU デリゲートに変換される)を GpuAccelerationConfig と CPU 推論(CpuAccelerationConfig を使用)によって評価することができます。今後、他のハードウェアにもアクセスできるようにより多くのデリゲートのサポートに取り組んでいます。
GPU アクセラレーション構成
以下のように、GPU アクセラレーション構成を作成します。
AccelerationConfig accelerationConfig = new GpuAccelerationConfig.Builder()
.setEnableQuantizedInference(false)
.build();
setEnableQuantizedInference() で、モデルが量子化を使用しているかどうかを指定する必要があります。
CPU アクセラレーション構成
以下のように、CPU アクセラレーションを作成します。
AccelerationConfig accelerationConfig = new CpuAccelerationConfig.Builder()
.setNumThreads(2)
.build();
setNumThreads() メソッドを使って、CPU 推論の評価に使用するスレッド数を定義します。
検証構成を作成する
検証構成によって、アクセラレーションサービスが推論を評価する方法を定義できます。この構成によって、以下の情報を渡します。
- 入力サンプル
- 期待される出力
- 精度の検証ロジック
モデルの最適なパフォーマンスを期待できる入力サンプルを必ず提供してください(「ゴールデン」サンプルとしても知られています)。
以下のように、CustomValidationConfig.Builder で ValidationConfig を作成します。
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenOutputs(outputBuffer)
.setAccuracyValidator(new MyCustomAccuracyValidator())
.build();
setBatchSize() でゴールデンサンプルの数を指定します。ゴールデンサンプルの入力は、setGoldenInputs() で渡します。入力に期待される出力は、setGoldenOutputs() で指定します。
最大推論時間を setInferenceTimeoutMillis() で定義できます(デフォルトは 5000 ms)。推量が定義した時間よりも長く掛かる場合、この構成は拒否されます。
オプションとして、以下のようにカスタムの AccuracyValidator を作成することもできます。
class MyCustomAccuracyValidator implements AccuracyValidator {
boolean validate(
BenchmarkResult benchmarkResult,
ByteBuffer[] goldenOutput) {
for (int i = 0; i < benchmarkResult.actualOutput().size(); i++) {
if (!goldenOutputs[i]
.equals(benchmarkResult.actualOutput().get(i).getValue())) {
return false;
}
}
return true;
}
}
必ずユースケースに合った検証ロジックを検証するようにしてください。
検証データがすでにモデルに埋め込まれている場合は、EmbeddedValidationConfig を使用できることに注意してください。
検証出力を生成する
ゴールデン出力はオプションであり、ゴールデン入力を指定する限り、アクセラレーションサービスはゴールデン出力を内部で生成できます。また setGoldenConfig() を呼び出すと、これらのゴールデン出力の生成に使用されるアクセラレーション構成を定義することもできます。
ValidationConfig validationConfig = new CustomValidationConfig.Builder()
.setBatchSize(5)
.setGoldenInputs(inputs)
.setGoldenConfig(customCpuAccelerationConfig)
[...]
.build();
アクセラレーション構成を検証する
アクセラレーション構成と検証構成を作成したら、モデルでそれらを検証できます。
以下を実行して、Play Services ランタイムを使用する TensorFlow Lite を適切に初期化し、GPU デリゲートがデバイスで使用できることを確認してください。
TfLiteGpu.isGpuDelegateAvailable(context)
.onSuccessTask(gpuAvailable -> TfLite.initialize(context,
TfLiteInitializationOptions.builder()
.setEnableGpuDelegateSupport(gpuAvailable)
.build()
)
);
AccelerationService.create() を実行して、AccelerationService をインスタンス化します。
次に validateConfig() を呼び出すと、モデルのアクセラレーション構成を検証できます。
InterpreterApi interpreter;
InterpreterOptions interpreterOptions = InterpreterApi.Options();
AccelerationService.create(context)
.validateConfig(model, accelerationConfig, validationConfig)
.addOnSuccessListener(validatedConfig -> {
if (validatedConfig.isValid() && validatedConfig.benchmarkResult().hasPassedAccuracyTest()) {
interpreterOptions.setAccelerationConfig(validatedConfig);
interpreter = InterpreterApi.create(model, interpreterOptions);
});
validateConfigs() を呼び出して、パラメーターとして Iterable<AccelerationConfig> オブジェクトを渡すと、複数の構成を検証することもできます。
validateConfig() は、同期タスクを有効にする Google Play サービスの Task Api から Task<ValidatedAccelerationConfigResult> を返します。
検証呼び出しから結果を取得するには、addOnSuccessListener() コールバックを追加します。
インタープリターで検証済みの構成を使用する
コールバックで返された ValidatedAccelerationConfigResult が有効であることを確認したら、interpreterOptions.setAccelerationConfig() を呼び出して、インタープリターのアクセラレーション構成として検証済みの構成を設定できます。
構成のキャッシュ
モデルに最適化されたアクセラレーション構成がデバイスで変更されることはほとんどありません。したがって、満足のいくアクセラレーション構成を得られたら、以降のセッションで別の検証を実行する代わりに、アプリケーションがその構成取得して InterpreterOptions の作成に使用できるように、デバイスに保存することをお勧めします。保存と取得のプロセスは、ValidatedAccelerationConfigResult の serialize() と deserialize() メソッドを使うとより簡単に行えます。
サンプルアプリケーション
アクセラレーションサービスのその場での統合をレビューするには、サンプルアプリをご覧ください。
制限事項
現在アクセラレーションサービスには以下の制限があります。
- 現時点では、CPU と GPU アクセラレーション構成のみがサポートされています。
- Google Play サービスの TensorFlow Lite のみがサポートされており、バンドル版の TensorFlow Lite を使用している場合は利用できません。
ValidatedAccelerationConfigResultオブジェクトで直接BaseOptionsを初期化できないため、TensorFlow Lite Task ライブラリはサポートされていません。- Acceleration Service SDK は API レベル 22 およびそれ以降のみをサポートしています。
注意事項
特に、この SDK を本番で使用する予定である場合は、以下の注意事項をよく確認してください。
Acceleration Service API のベータ版を終了して安定版がリリースされる前に、新しい SDK を公開します。これは現在のベータ版とは多少異なる可能性があります。アクセラレーションサービスの使用を継続するには、適時にこの新しい SDK に移行し、アプリのアップデートをプッシュする必要があります。安定版がリリースされた後、ベータ版の SDK と Google Play サービスの互換性が無くなる可能性があるため、これを行わない場合にアプリが動作しなくなる可能性があります。
Acceleration Service API 内の特定の機能または全 API が一般に利用できるようになるという保証はありません。無期限にベータ版のままになる可能性や、サービス終了、または他の機能と合わせて特定の開発者オーディエンスを対象としたパッケージに含まれる可能性もあります。Acceleration Service API または API 自体が最終的に一般に提供される可能性はありますが、このスケジュールはまた確定していません。
規約とプライバシー
利用規約
Acceleration Service API の利用は、Google API 利用規約の対象です。
また、Acceleration Service API は現在ベータ版であるため、それを使用することで、上記の「注意事項」セクションに記載された潜在的な課題を理解し、アクセラレーションサービスが必ずしも指定のとおりに動作しない可能性があることに同意するものとします。
プライバシー
Acceleration Service API を使用する際、入力データ(画像、動画、テキストなど)の処理は完全にデバイス上で行われ、アクセラレーションサービスが Google サーバーにデータを送信することはありません。したがって、この API を使用して、デバイスから転送されるべきではない入力データを処理することができます。
Acceleration Service API は、バグ修正、モデルの更新、およびハードウェアアクセラレータの互換性に関する更新情報などを受信するために、Google サーバーに接続することがあります。Acceleration Service API はまた、プライバシーポリシーに詳しく説明されているとおり、あなたのアプリにおける API のパフォーマンスと使用状況に関する指標を Google に送信します。Google はこの指標データを使用してパフォーマンスを測定し、API のデバッグ、保守、および改善を行い、誤使用や不正使用を検出します。
適用法で定められているとおり、あなたには、アプリのユーザーに対し、Google による Acceleration Service 指標の処理について説明する義務があります。
Google が収集するデータには、以下の項目が含まれます。
- デバイス情報(メーカー、モデル、OS バージョン、ビルドなど)と使用可能な ML ハードウェアアクセラレータ(GPU および DSP)。診断および使用状況分析で使用されます。
- アプリ情報(パッケージ名 / バンドル ID、アプリバージョン)。診断および使用状況分析で使用されます。
- API 構成(画像の形式や解像度など)。診断および使用状況分析で使用されます。
- イベントタイプ(初期化、モデルのダウンロード、更新、実行、検出など)。診断および使用状況分析で使用されます。
- エラーコード。診断で使用されます。
- パフォーマンス指標。診断で使用されます。
- ユーザーまたは物理デバイスを一意に識別しない、インストール単位の識別子。リモート構成の操作と使用状況分析で使用されます。
- ネットワークリクエスト送信者 IP アドレス。リモート構成の診断に使用されます。収集された IP アドレスは一時的に保持されます。
サポートとフィードバック
TensorFlow 課題トラッカーを使用すると、フィードバックを提出し、サポートを受けることができます。を使用して、問題の報告とサポートリクエストには、Google Play サービスの TensorFlow Lite 用の課題テンプレートをご利用ください。