

งานในการระบุสิ่งที่เสียงเป็นตัวแทนเรียกว่า การจำแนกเสียง โมเดลการจัดหมวดหมู่เสียงได้รับการฝึกอบรมให้จดจำเหตุการณ์เสียงต่างๆ ตัวอย่างเช่น คุณอาจฝึกโมเดลให้จดจำเหตุการณ์ที่แสดงถึงเหตุการณ์ที่แตกต่างกันสามเหตุการณ์: การปรบมือ การดีดนิ้ว และการพิมพ์ TensorFlow Lite นำเสนอโมเดลที่ได้รับการฝึกล่วงหน้าที่ได้รับการปรับปรุงซึ่งคุณสามารถปรับใช้ในแอปพลิเคชันมือถือของคุณได้ เรียนรู้เพิ่มเติมเกี่ยวกับการจัดหมวดหมู่เสียงโดยใช้ TensorFlow ที่นี่
รูปภาพต่อไปนี้แสดงเอาต์พุตของโมเดลการจัดหมวดหมู่เสียงบน Android
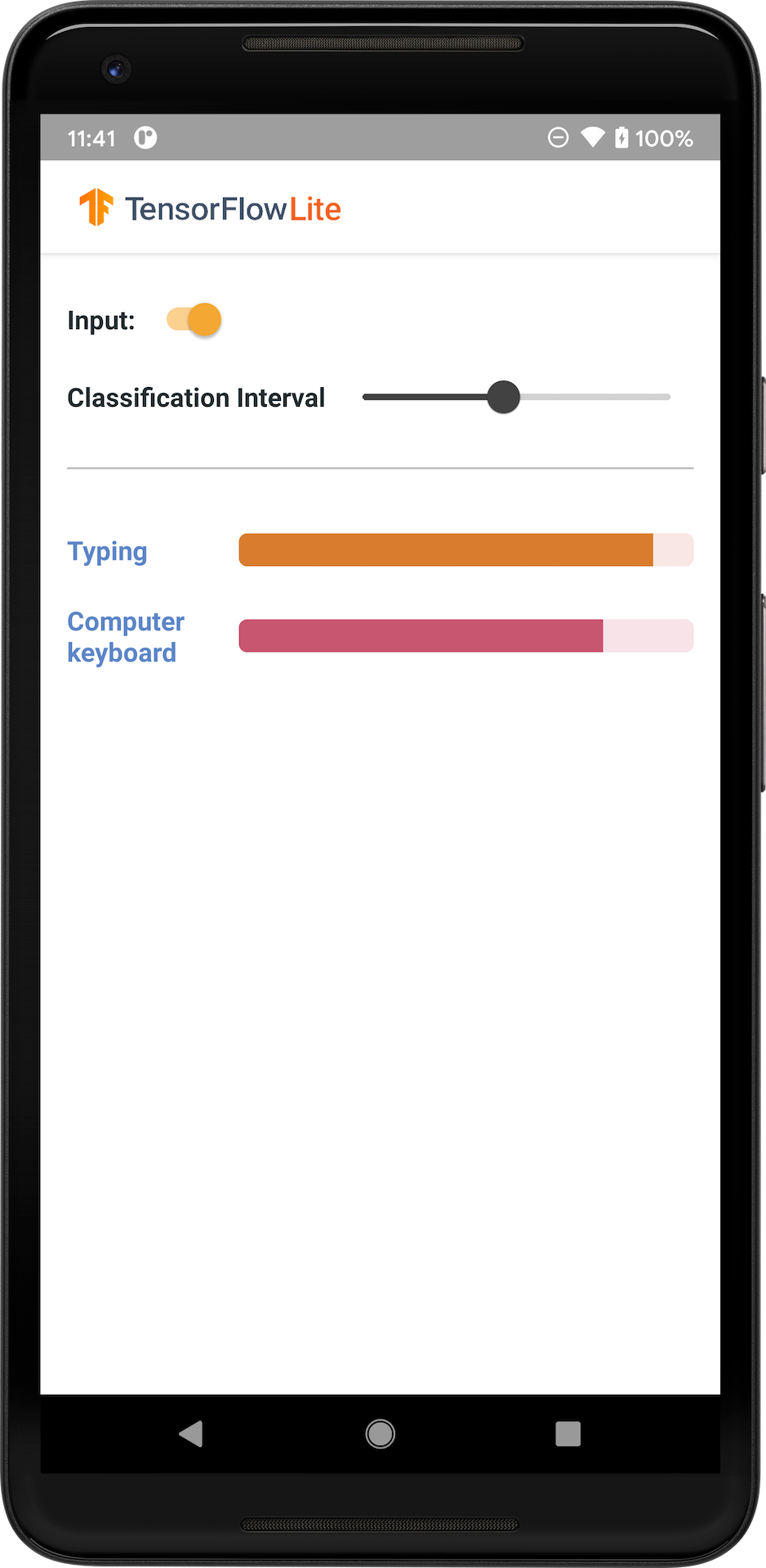
เริ่ม
หากคุณยังใหม่กับ TensorFlow Lite และกำลังใช้งาน Android เราขอแนะนำให้สำรวจแอปพลิเคชันตัวอย่างต่อไปนี้ที่สามารถช่วยคุณเริ่มต้นได้
คุณสามารถใช้ประโยชน์จาก API แบบสำเร็จรูปจาก TensorFlow Lite Task Library เพื่อผสานรวมโมเดลการจัดหมวดหมู่เสียงด้วยโค้ดเพียงไม่กี่บรรทัด คุณยังสามารถสร้างไปป์ไลน์การอนุมานที่คุณกำหนดเองได้โดยใช้ TensorFlow Lite Support Library
ตัวอย่าง Android ด้านล่างสาธิตการใช้งานโดยใช้ TFLite Task Library
หากคุณใช้แพลตฟอร์มอื่นที่ไม่ใช่ Android/iOS หรือหากคุณคุ้นเคยกับ TensorFlow Lite API อยู่แล้ว ให้ดาวน์โหลดโมเดลเริ่มต้นและไฟล์ที่รองรับ (ถ้ามี)
ดาวน์โหลดโมเดลเริ่มต้นจาก TensorFlow Hub
คำอธิบายโมเดล
YAMNet คือตัวแยกประเภทเหตุการณ์เสียงที่ใช้รูปคลื่นเสียงเป็นอินพุต และทำการคาดการณ์อย่างเป็นอิสระสำหรับเหตุการณ์เสียง 521 รายการจาก AudioSet Ontology โมเดลนี้ใช้สถาปัตยกรรม MobileNet v1 และได้รับการฝึกโดยใช้คลังข้อมูล AudioSet โมเดลนี้เดิมเปิดตัวใน TensorFlow Model Garden ซึ่งเป็นซอร์สโค้ดของโมเดล จุดตรวจสอบโมเดลดั้งเดิม และเอกสารประกอบโดยละเอียดเพิ่มเติม
มันทำงานอย่างไร
โมเดล YAMNet ที่แปลงเป็น TFLite มีสองเวอร์ชัน:
YAMNet เป็นโมเดลการจัดหมวดหมู่เสียงดั้งเดิมที่มีขนาดอินพุตแบบไดนามิก เหมาะสำหรับการถ่ายโอนการเรียนรู้ การใช้งานเว็บและมือถือ นอกจากนี้ยังมีผลลัพธ์ที่ซับซ้อนมากขึ้นอีกด้วย
YAMNet/การจัดหมวดหมู่ เป็นเวอร์ชันเชิงปริมาณที่มีอินพุตเฟรมความยาวคงที่ที่ง่ายกว่า (15600 ตัวอย่าง) และส่งคืนเวกเตอร์เดี่ยวของคะแนนสำหรับคลาสเหตุการณ์เสียง 521 รายการ
อินพุต
โมเดลยอมรับ 1-D float32 Tensor หรืออาร์เรย์ NumPy ที่มีความยาว 15600 ซึ่งมีรูปคลื่น 0.975 วินาทีที่แสดงเป็นตัวอย่างโมโน 16 kHz ในช่วง [-1.0, +1.0]
เอาท์พุต
โมเดลส่งคืน Tensor 2-D float32 Tensor ของรูปร่าง (1, 521) ซึ่งมีคะแนนที่คาดการณ์ไว้สำหรับแต่ละคลาส 521 ใน Ontology AudioSet ที่ YAMNet รองรับ ดัชนีคอลัมน์ (0-520) ของเทนเซอร์คะแนนจะถูกแมปกับชื่อคลาส AudioSet ที่เกี่ยวข้องโดยใช้ YAMNet Class Map ซึ่งพร้อมใช้งานในรูปแบบไฟล์ที่เกี่ยวข้อง yamnet_label_list.txt ที่อัดแน่นอยู่ในไฟล์โมเดล ดูด้านล่างสำหรับการใช้งาน
การใช้งานที่เหมาะสม
สามารถใช้ YAMNet ได้
- เป็นตัวแยกประเภทเหตุการณ์เสียงแบบสแตนด์อโลนที่ให้พื้นฐานที่เหมาะสมสำหรับเหตุการณ์เสียงที่หลากหลาย
- ในฐานะตัวแยกคุณสมบัติระดับสูง: เอาต์พุตที่ฝัง 1024-D ของ YAMNet สามารถใช้เป็นคุณสมบัติอินพุตของรุ่นอื่น ซึ่งสามารถฝึกกับข้อมูลจำนวนเล็กน้อยสำหรับงานเฉพาะได้ ช่วยให้สามารถสร้างตัวแยกประเภทเสียงแบบพิเศษได้อย่างรวดเร็วโดยไม่ต้องใช้ข้อมูลที่มีป้ายกำกับจำนวนมาก และไม่ต้องฝึกโมเดลขนาดใหญ่ตั้งแต่ต้นทางถึงปลายทาง
- การเริ่มต้นอย่างอบอุ่น: พารามิเตอร์โมเดล YAMNet สามารถใช้เพื่อเริ่มต้นส่วนหนึ่งของโมเดลที่ใหญ่กว่า ซึ่งช่วยให้ปรับแต่งและสำรวจโมเดลได้รวดเร็วยิ่งขึ้น
ข้อจำกัด
- เอาต์พุตตัวแยกประเภทของ YAMNet ยังไม่ได้รับการปรับเทียบระหว่างคลาสต่างๆ ดังนั้นคุณจึงไม่สามารถถือว่าเอาต์พุตเป็นความน่าจะเป็นได้โดยตรง สำหรับงานใดๆ ก็ตาม คุณจะต้องดำเนินการสอบเทียบด้วยข้อมูลเฉพาะงาน ซึ่งช่วยให้คุณสามารถกำหนดเกณฑ์คะแนนและการปรับขนาดต่อชั้นเรียนได้อย่างเหมาะสม
- YAMNet ได้รับการฝึกอบรมเกี่ยวกับวิดีโอ YouTube หลายล้านรายการ และถึงแม้ว่าวิดีโอเหล่านี้จะมีความหลากหลายมาก แต่ก็ยังอาจมีโดเมนที่ไม่ตรงกันระหว่างวิดีโอ YouTube โดยเฉลี่ยกับอินพุตเสียงที่คาดหวังสำหรับงานใดก็ตาม คุณควรคาดหวังที่จะทำการปรับแต่งและสอบเทียบอย่างละเอียดเพื่อให้ YAMNet สามารถใช้งานได้ในทุกระบบที่คุณสร้าง
การปรับแต่งโมเดล
โมเดลที่ได้รับการฝึกล่วงหน้าจะได้รับการฝึกให้ตรวจจับคลาสเสียงที่แตกต่างกัน 521 คลาส สำหรับรายการคลาสทั้งหมด โปรดดูไฟล์ป้ายกำกับใน ที่เก็บโมเดล
คุณสามารถใช้เทคนิคที่เรียกว่าการเรียนรู้แบบถ่ายโอนเพื่อฝึกโมเดลใหม่เพื่อจดจำคลาสที่ไม่ได้อยู่ในชุดดั้งเดิม ตัวอย่างเช่น คุณสามารถฝึกโมเดลใหม่เพื่อตรวจจับเสียงนกร้องหลายตัว ในการดำเนินการนี้ คุณจะต้องมีชุดไฟล์เสียงการฝึกอบรมสำหรับค่ายเพลงใหม่แต่ละค่ายที่คุณต้องการฝึก วิธีที่แนะนำคือการใช้ไลบรารี TensorFlow Lite Model Maker ซึ่งช่วยให้กระบวนการฝึกโมเดล TensorFlow Lite ง่ายขึ้นโดยใช้ชุดข้อมูลที่กำหนดเองในโค้ดไม่กี่บรรทัด ใช้การเรียนรู้แบบถ่ายโอนเพื่อลดปริมาณข้อมูลและเวลาการฝึกอบรมที่จำเป็น คุณยังสามารถเรียนรู้จาก Transfer Learning สำหรับการจดจำเสียง เป็นตัวอย่างหนึ่งของ Transfer Learning
อ่านเพิ่มเติมและแหล่งข้อมูล
ใช้แหล่งข้อมูลต่อไปนี้เพื่อเรียนรู้เพิ่มเติมเกี่ยวกับแนวคิดที่เกี่ยวข้องกับการจัดประเภทเสียง: