
|
|
|
Introduction
Large language models (LLMs) are a class of machine learning models that are trained to generate text based on large datasets. They can be used for natural language processing (NLP) tasks, including text generation, question answering, and machine translation. They are based on Transformer architecture and are trained on massive amounts of text data, often involving billions of words. Even LLMs of a smaller scale, such as GPT-2, can perform impressively. Converting TensorFlow models to a lighter, faster, and low-power model allows for us to run generative AI models on-device, with benefits of better user security because data will never leave your device.
This runbook shows you how to build an Android app with TensorFlow Lite to run a Keras LLM and provides suggestions for model optimization using quantizing techniques, which otherwise would require a much larger amount of memory and greater computational power to run.
We have open sourced our Android app framework that any compatible TFLite LLMs can plug into. Here are two demos:
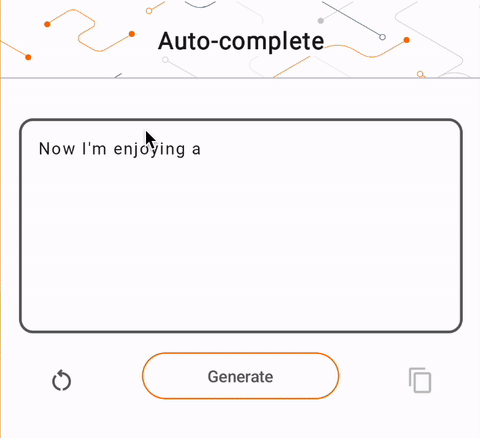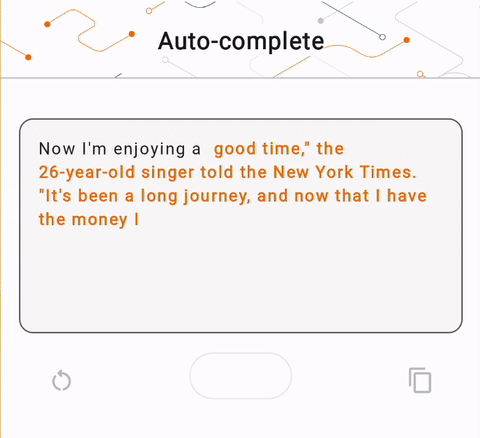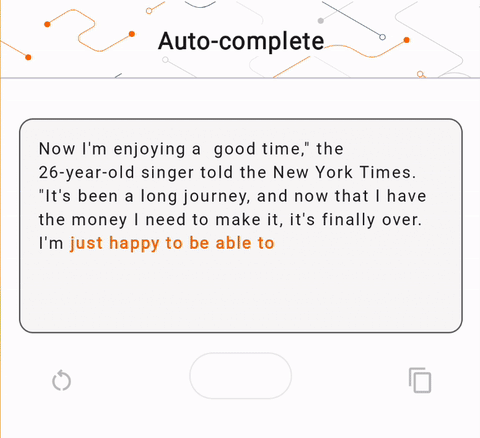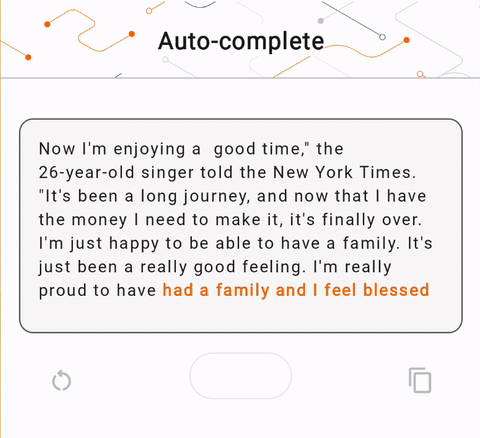
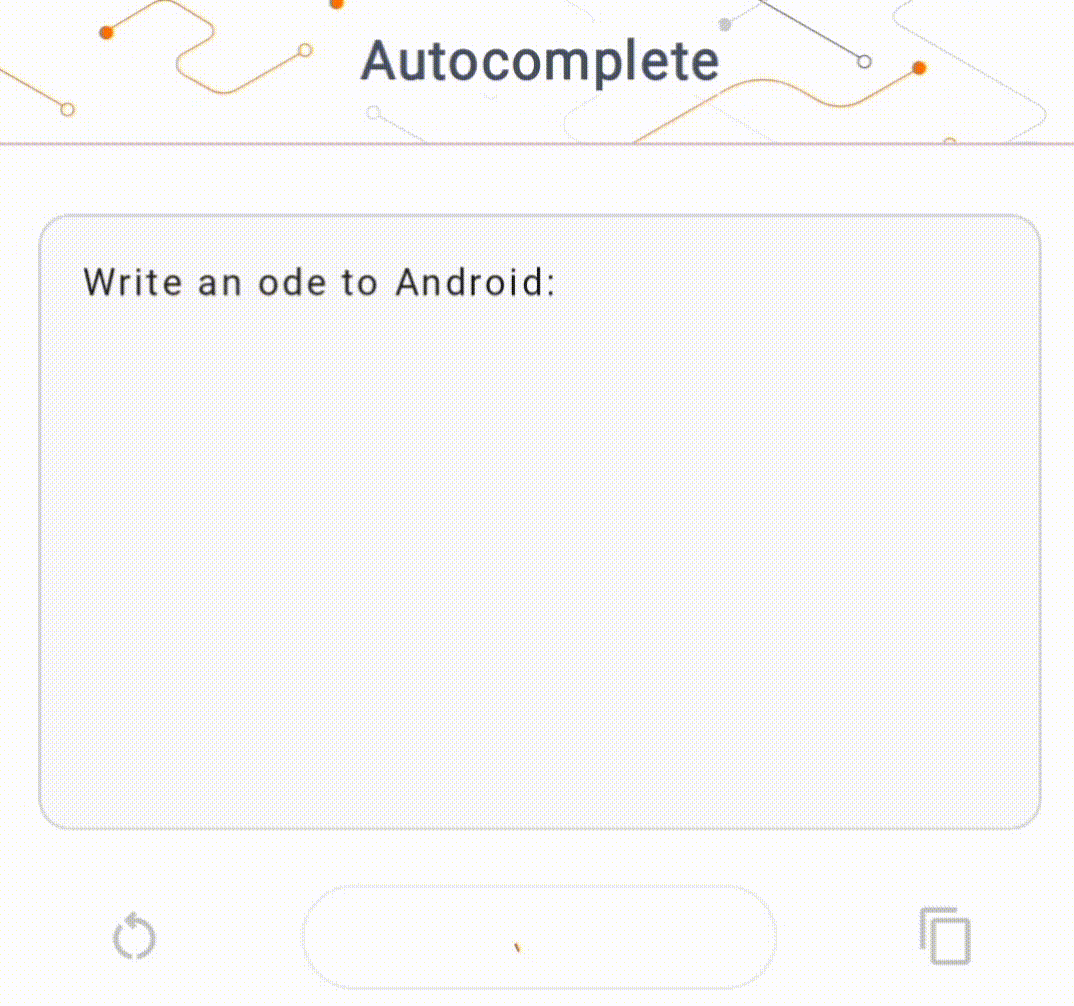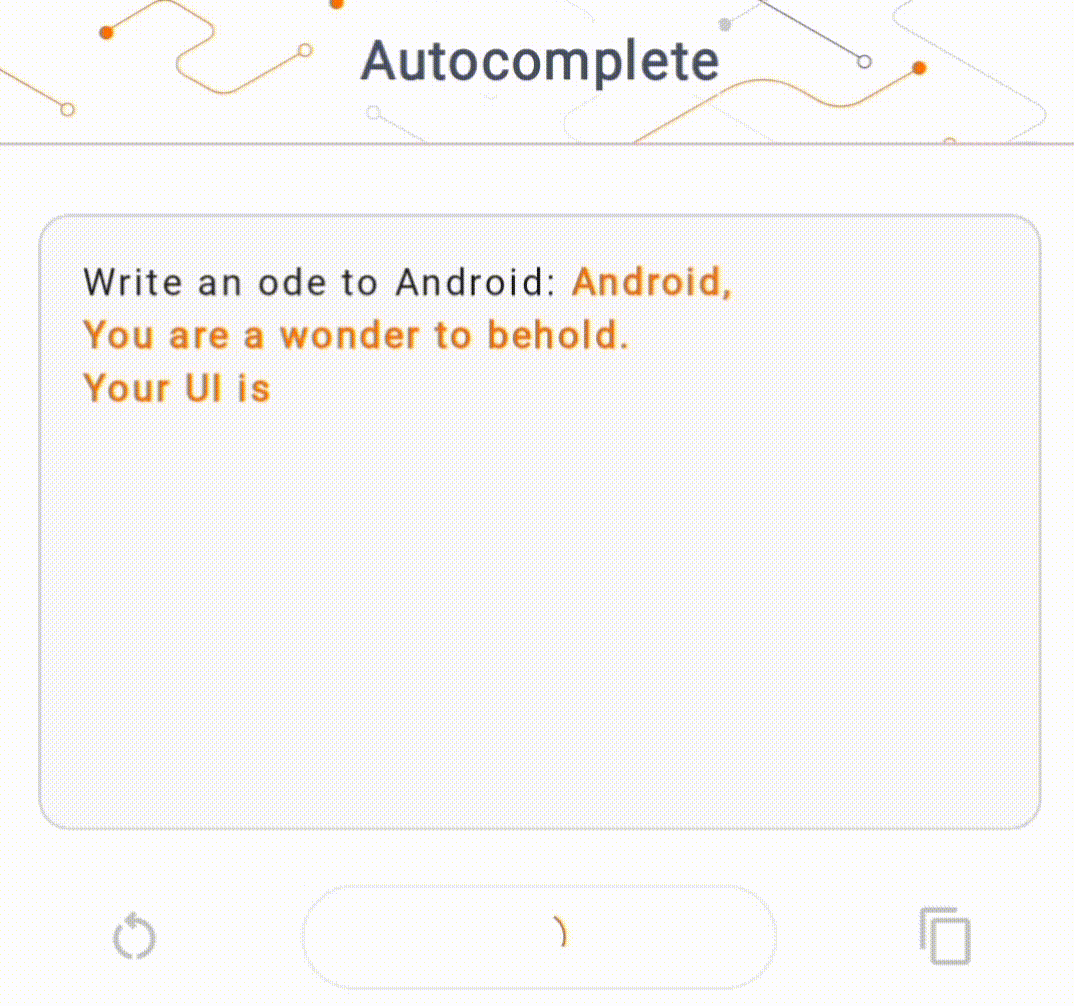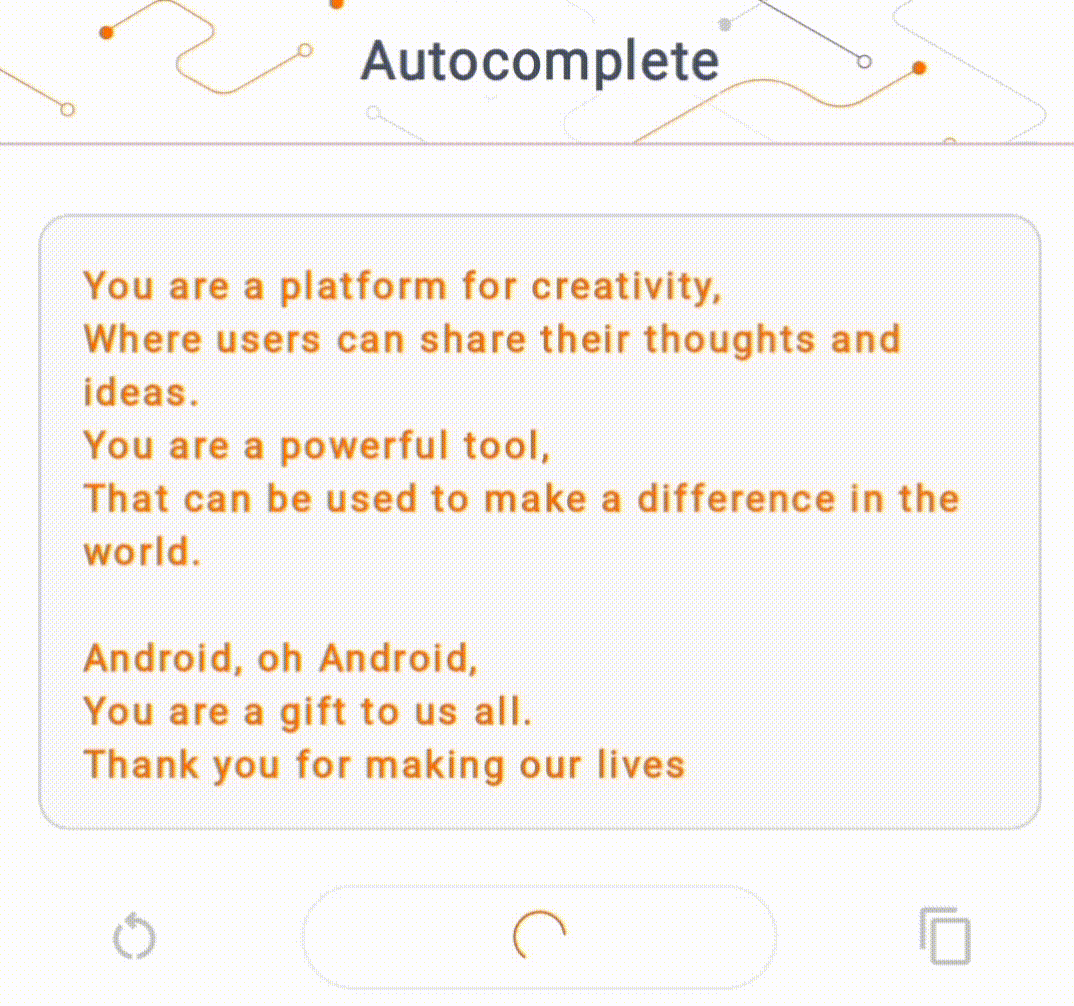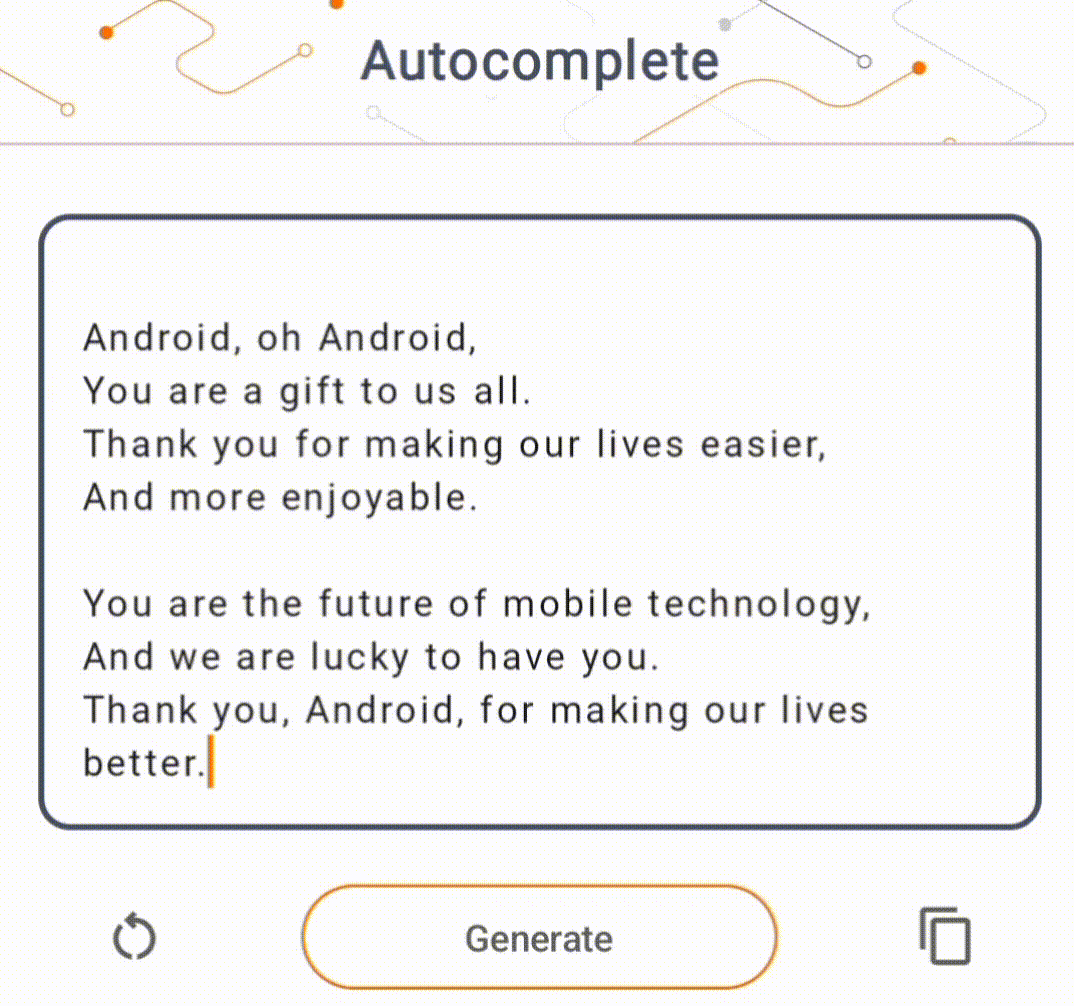
- In Figure 1, we used a Keras GPT-2 model to perform text completion tasks on device.
- In Figure 2, we converted a version of instruction-tuned PaLM model (1.5 billion parameters) to TFLite and executed through TFLite runtime.
Guides
Model authoring
For this demonstration, we will use KerasNLP to get the GPT-2 model. KerasNLP is a library that contains state-of-the-art pretrained models for natural language processing tasks, and can support users through their entire development cycle. You can see the list of models available in the KerasNLP repository. The workflows are built from modular components that have state-of-the-art preset weights and architectures when used out-of-the-box and are easily customizable when more control is needed. Creating the GPT-2 model can be done with the following steps:
gpt2_tokenizer = keras_nlp.models.GPT2Tokenizer.from_preset("gpt2_base_en")
gpt2_preprocessor = keras_nlp.models.GPT2CausalLMPreprocessor.from_preset(
"gpt2_base_en",
sequence_length=256,
add_end_token=True,
)
gpt2_lm =
keras_nlp.models.GPT2CausalLM.from_preset(
"gpt2_base_en",
preprocessor=gpt2_preprocessor
)
One commonality among these three lines of code is the from_preset() method,
which will instantiate the part of Keras API from a preset architecture and/or
weights, therefore loading the pre-trained model. From this code snippet, you’ll
also notice three modular components:
Tokenizer: converts a raw string input into integer token IDs suitable for a Keras Embedding layer. GPT-2 uses the byte-pair encoding (BPE) tokenizer specifically.
Preprocessor: layer for tokenizing and packing inputs to be fed into a Keras model. Here, the preprocessor will pad the tensor of token IDs to a specified length (256) after tokenization.
Backbone: Keras model that follows the SoTA transformer backbone architecture and has the preset weights.
Additionally, you can check out the full GPT-2 model implementation on GitHub.
Model conversion
TensorFlow Lite is a mobile library for deploying methods on mobile, microcontrollers, and other edge devices. The first step is to convert a Keras model to a more compact TensorFlow Lite format using the TensorFlow Lite converter, and then use the TensorFlow Lite interpreter, which is highly optimized for mobile devices, to run the converted model.
 Start with the
Start with the generate() function from GPT2CausalLM that performs the
conversion. Wrap the generate() function to create a concrete TensorFlow
function:
@tf.function
def generate(prompt, max_length):
"""
Args:
prompt: input prompt to the LLM in string format
max_length: the max length of the generated tokens
"""
return gpt2_lm.generate(prompt, max_length)
concrete_func = generate.get_concrete_function(tf.TensorSpec([], tf.string), 100)
Note that you can also use from_keras_model() from
TFLiteConverter
in order to perform the conversion.
Now define a helper function that will run inference with an input and a TFLite
model. TensorFlow text ops are not built-in ops in the TFLite runtime, so you
will need to add these custom ops in order for the interpreter to make inference
on this model. This helper function accepts an input and a function that
performs the conversion, namely the generator() function defined above.
def run_inference(input, generate_tflite):
interp = interpreter.InterpreterWithCustomOps(
model_content=generate_tflite,
custom_op_registerers=
tf_text.tflite_registrar.SELECT_TFTEXT_OPS
)
interp.get_signature_list()
generator = interp.get_signature_runner('serving_default')
output = generator(prompt=np.array([input]))
You can convert the model now:
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
generate_tflite = converter.convert()
run_inference("I'm enjoying a", generate_tflite)
Quantization
TensorFlow Lite has implemented an optimization technique called quantization which can reduce model size and accelerate inference. Through the quantization process, 32-bit floats are mapped to smaller 8-bit integers, therefore reducing the model size by a factor of 4 for more efficient execution on modern hardwares. There are several ways to do quantization in TensorFlow. You can visit the TFLite Model optimization and TensorFlow Model Optimization Toolkit pages for more information. The types of quantizations are explained briefly below.
Here, you will use the
post-training dynamic range quantization
on the GPT-2 model by setting the converter optimization flag to
tf.lite.Optimize.DEFAULT, and the rest of the conversion process is the same
as detailed before. We tested that with this quantization technique the latency
is around 6.7 seconds on Pixel 7 with max output length set to 100.
gpt2_lm.jit_compile = False
converter = tf.lite.TFLiteConverter.from_concrete_functions(
[concrete_func],
gpt2_lm)
converter.target_spec.supported_ops = [
tf.lite.OpsSet.TFLITE_BUILTINS, # enable TFLite ops
tf.lite.OpsSet.SELECT_TF_OPS, # enable TF ops
]
converter.allow_custom_ops = True
converter.optimizations = [tf.lite.Optimize.DEFAULT]
converter.target_spec.experimental_select_user_tf_ops = [
"UnsortedSegmentJoin",
"UpperBound"
]
converter._experimental_guarantee_all_funcs_one_use = True
quant_generate_tflite = converter.convert()
run_inference("I'm enjoying a", quant_generate_tflite)
Dynamic Range
Dynamic range quantization is the recommended starting point for optimizing on-device models. It can achieve about a 4x reduction in the model size, and is a recommended starting point as it provides reduced memory usage and faster computation without you having to provide a representative dataset for calibration. This type of quantization statically quantizes only the weights from floating point to 8-bit integer at conversion time.
FP16
Floating point models can also be optimized by quantizing the weights to float16 type. The advantages of float16 quantization are reducing the model size by up to half (as all weights become half their size), causing minimal loss in accuracy, and supporting GPU delegates that can operate directly on float16 data (which results in faster computation than on float32 data). A model converted to float16 weights can still run on the CPU without additional modifications. The float16 weights are upsampled to float32 before the first inference, which permits a reduction in model size in exchange for a minimal impact to latency and accuracy.
Full Integer Quantization
Full integer quantization both converts the 32 bit floating point numbers, including weights and activations, to the nearest 8 bit integers. This type of quantization results in a smaller model with increased inference speed, which is incredibly valuable when using microcontrollers. This mode is recommended when activations are sensitive to the quantization.
Android App integration
You can follow this Android example to integrate your TFLite model into an Android App.
Prerequisites
If you have not already, install Android Studio, following the instructions on the website.
- Android Studio 2022.2.1 or above.
- An Android device or Android emulator with more than 4G memory
Building and Running with Android Studio
- Open Android Studio, and from the Welcome screen, select Open an existing Android Studio project.
- From the Open File or Project window that appears, navigate to and select
the
lite/examples/generative_ai/androiddirectory from wherever you cloned the TensorFlow Lite sample GitHub repo. - You may also need to install various platforms and tools according to error messages.
- Rename the converted .tflite model to
autocomplete.tfliteand copy it intoapp/src/main/assets/folder. - Select menu Build -> Make Project to build the app. (Ctrl+F9, depending on your version).
- Click menu Run -> Run 'app'. (Shift+F10, depending on your version)
Alternatively, you can also use the gradle wrapper to build it in the command line. Please refer to the Gradle documentation for more information.
(Optional) Building the .aar file
By default the app automatically downloads the needed .aar files. But if you
want to build your own, switch to app/libs/build_aar/ folder run
./build_aar.sh. This script will pull in the necessary ops from TensorFlow
Text and build the aar for Select TF operators.
After compilation, a new file tftext_tflite_flex.aar is generated. Replace the
.aar file in app/libs/ folder and re-build the app.
Note that you still need to include the standard tensorflow-lite aar in your
gradle file.
Context window size
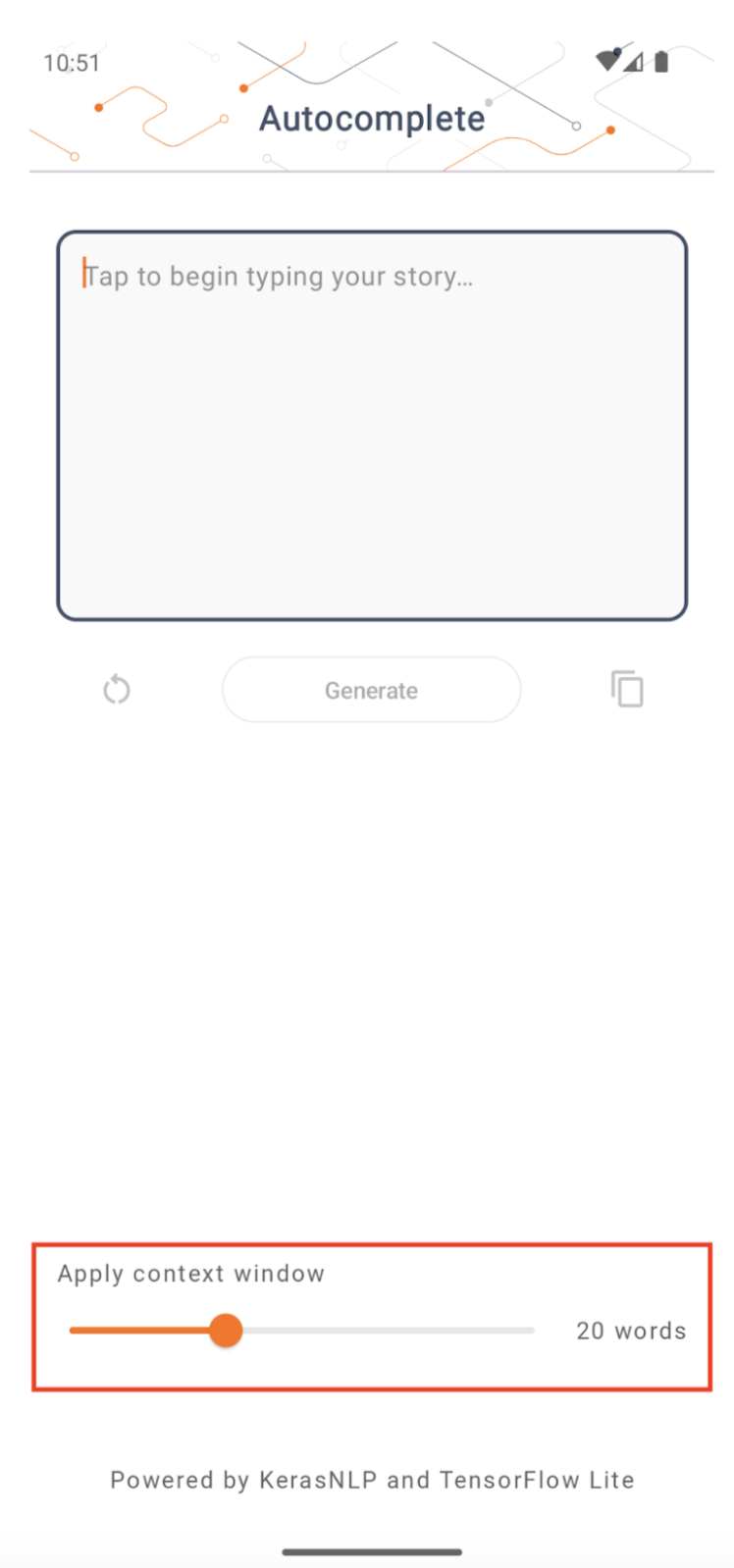
The app has a changeable parameter ‘context window size’, which is needed because LLMs today generally have a fixed context size which limits how many words/tokens can be fed into the model as ‘prompt’ (note that ‘word’ is not necessarily equivalent to ‘token’ in this case, due to different tokenization methods). This number is important because:
- Setting it too small, the model will not have enough context to generate meaningful output
- Setting it too big, the model will not have enough room to work with (since the output sequence is inclusive of the prompt)
You can experiment with it, but setting it to ~50% of output sequence length is a good start.
Safety and Responsible AI
As noted in the original OpenAI GPT-2 announcement, there are notable caveats and limitations with the GPT-2 model. In fact, LLMs today generally have some well-known challenges such as hallucinations, fairness, and bias; this is because these models are trained on real-world data, which make them reflect real world issues.
This codelab is created only to demonstrate how to create an app powered by LLMs with TensorFlow tooling. The model produced in this codelab is for educational purposes only and not intended for production usage.
LLM production usage requires thoughtful selection of training datasets and comprehensive safety mitigations. One such functionality offered in this Android app is the profanity filter, which rejects bad user inputs or model outputs. If any inappropriate language is detected, the app will in return reject that action. To learn more about Responsible AI in the context of LLMs, make sure to watch the Safe and Responsible Development with Generative Language Models technical session at Google I/O 2023 and check out the Responsible AI Toolkit.