

একটি অডিও কি প্রতিনিধিত্ব করে তা সনাক্ত করার কাজটিকে অডিও শ্রেণীবিভাগ বলা হয়। একটি অডিও শ্রেণীবিভাগ মডেল বিভিন্ন অডিও ঘটনা চিনতে প্রশিক্ষণ দেওয়া হয়. উদাহরণস্বরূপ, আপনি একটি মডেলকে তিনটি ভিন্ন ইভেন্টের প্রতিনিধিত্বকারী ইভেন্টগুলিকে চিনতে প্রশিক্ষণ দিতে পারেন: হাততালি দেওয়া, আঙুল তোলা এবং টাইপ করা। TensorFlow Lite অপ্টিমাইজ করা প্রাক-প্রশিক্ষিত মডেলগুলি প্রদান করে যা আপনি আপনার মোবাইল অ্যাপ্লিকেশনগুলিতে স্থাপন করতে পারেন। এখানে TensorFlow ব্যবহার করে অডিও শ্রেণীবিভাগ সম্পর্কে আরও জানুন।
নিম্নলিখিত চিত্রটি অ্যান্ড্রয়েডে অডিও শ্রেণিবিন্যাস মডেলের আউটপুট দেখায়।
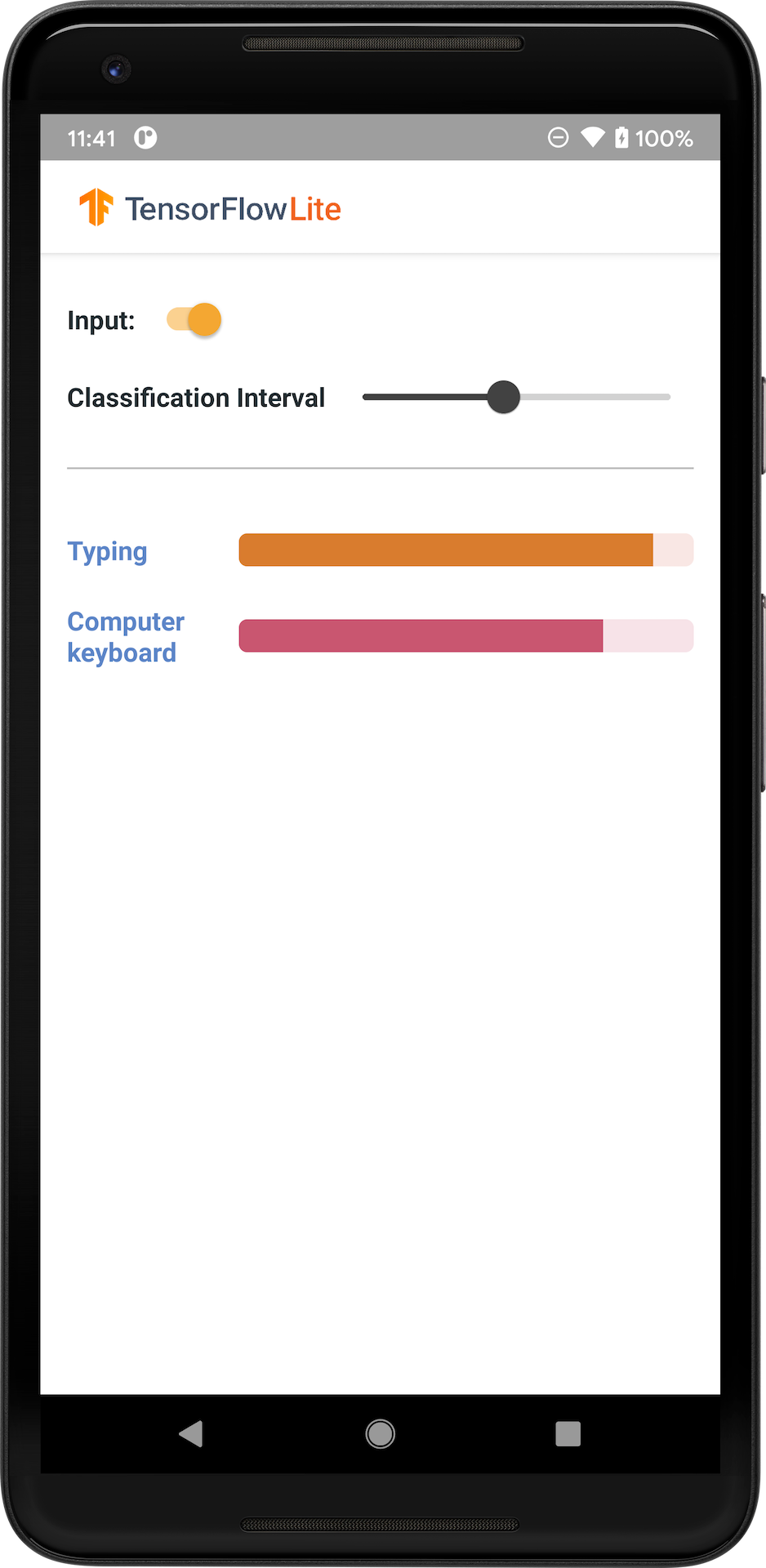
এবার শুরু করা যাক
আপনি যদি TensorFlow Lite-এ নতুন হয়ে থাকেন এবং Android এর সাথে কাজ করেন, তাহলে আমরা আপনাকে শুরু করতে সাহায্য করতে পারে এমন নিম্নলিখিত উদাহরণের অ্যাপ্লিকেশনগুলি অন্বেষণ করার পরামর্শ দিই৷
আপনি কোডের কয়েকটি লাইনে অডিও শ্রেণীবিভাগ মডেলগুলিকে একীভূত করতে টেনসরফ্লো লাইট টাস্ক লাইব্রেরি থেকে আউট-অফ-বক্স API ব্যবহার করতে পারেন। এছাড়াও আপনি টেনসরফ্লো লাইট সাপোর্ট লাইব্রেরি ব্যবহার করে আপনার নিজস্ব কাস্টম ইনফারেন্স পাইপলাইন তৈরি করতে পারেন।
নীচের Android উদাহরণটি TFLite টাস্ক লাইব্রেরি ব্যবহার করে বাস্তবায়ন প্রদর্শন করে
আপনি যদি Android/iOS ছাড়া অন্য কোনো প্ল্যাটফর্ম ব্যবহার করেন, অথবা আপনি যদি ইতিমধ্যেই TensorFlow Lite API- এর সাথে পরিচিত হন, তাহলে স্টার্টার মডেল এবং সমর্থনকারী ফাইলগুলি ডাউনলোড করুন (যদি প্রযোজ্য হয়)।
টেনসরফ্লো হাব থেকে স্টার্টার মডেল ডাউনলোড করুন
মডেলের বিবরণ
YAMNet হল একটি অডিও ইভেন্ট ক্লাসিফায়ার যা অডিও ওয়েভফর্মকে ইনপুট হিসেবে নেয় এবং অডিওসেট অন্টোলজি থেকে 521টি অডিও ইভেন্টের প্রতিটির জন্য স্বাধীন ভবিষ্যদ্বাণী করে। মডেলটি MobileNet v1 আর্কিটেকচার ব্যবহার করে এবং অডিওসেট কর্পাস ব্যবহার করে প্রশিক্ষিত হয়েছিল। এই মডেলটি মূলত টেনসরফ্লো মডেল গার্ডেনে প্রকাশিত হয়েছিল, যেখানে মডেল সোর্স কোড, আসল মডেল চেকপয়েন্ট এবং আরও বিস্তারিত ডকুমেন্টেশন রয়েছে।
কিভাবে এটা কাজ করে
TFLite এ রূপান্তরিত YAMNet মডেলের দুটি সংস্করণ রয়েছে:
YAMNet হল আসল অডিও ক্লাসিফিকেশন মডেল, গতিশীল ইনপুট সাইজ সহ, ট্রান্সফার লার্নিং, ওয়েব এবং মোবাইল ডিপ্লয়মেন্টের জন্য উপযুক্ত। এটি একটি আরো জটিল আউটপুট আছে.
YAMNet/শ্রেণীবিভাগ হল একটি পরিমাপকৃত সংস্করণ যার একটি সহজ স্থির দৈর্ঘ্যের ফ্রেম ইনপুট (15600 নমুনা) এবং 521টি অডিও ইভেন্ট ক্লাসের জন্য একটি একক ভেক্টর স্কোর প্রদান করে।
ইনপুট
মডেলটি 15600 দৈর্ঘ্যের একটি 1-D float32 টেনসর বা NumPy অ্যারে গ্রহণ করে যাতে একটি 0.975 সেকেন্ডের তরঙ্গরূপ রয়েছে যা [-1.0, +1.0] পরিসরে মনো 16 kHz নমুনা হিসাবে উপস্থাপিত হয়।
আউটপুট
মডেলটি YAMNet দ্বারা সমর্থিত অডিওসেট অন্টোলজির 521টি ক্লাসের প্রতিটির জন্য ভবিষ্যদ্বাণীকৃত স্কোর সমন্বিত একটি 2-ডি float32 টেনসর (1, 521) প্রদান করে। স্কোর টেনসরের কলাম সূচক (0-520) YAMNet ক্লাস ম্যাপ ব্যবহার করে সংশ্লিষ্ট অডিওসেট শ্রেণীর নামের সাথে ম্যাপ করা হয়েছে, যা মডেল ফাইলে প্যাক করা একটি সংশ্লিষ্ট ফাইল yamnet_label_list.txt হিসাবে উপলব্ধ। ব্যবহারের জন্য নীচে দেখুন.
উপযুক্ত ব্যবহার
YAMNet ব্যবহার করা যেতে পারে
- একটি স্বতন্ত্র অডিও ইভেন্ট ক্লাসিফায়ার হিসাবে যা বিভিন্ন ধরণের অডিও ইভেন্ট জুড়ে একটি যুক্তিসঙ্গত বেসলাইন প্রদান করে।
- একটি উচ্চ-স্তরের বৈশিষ্ট্য এক্সট্র্যাক্টর হিসাবে: YAMNet-এর 1024-D এম্বেডিং আউটপুট অন্য মডেলের ইনপুট বৈশিষ্ট্য হিসাবে ব্যবহার করা যেতে পারে যা তারপর একটি নির্দিষ্ট কাজের জন্য অল্প পরিমাণ ডেটার উপর প্রশিক্ষিত হতে পারে। এটি প্রচুর লেবেলযুক্ত ডেটার প্রয়োজন ছাড়াই এবং একটি বড় মডেলের এন্ড-টু-এন্ড প্রশিক্ষণ ছাড়াই দ্রুত বিশেষায়িত অডিও ক্লাসিফায়ার তৈরি করতে দেয়।
- একটি উষ্ণ শুরু হিসাবে: YAMNet মডেল প্যারামিটারগুলি একটি বড় মডেলের অংশ শুরু করতে ব্যবহার করা যেতে পারে যা দ্রুত ফাইন-টিউনিং এবং মডেল অন্বেষণের অনুমতি দেয়।
সীমাবদ্ধতা
- YAMNet এর ক্লাসিফায়ার আউটপুটগুলি ক্লাস জুড়ে ক্যালিব্রেট করা হয়নি, তাই আপনি সরাসরি আউটপুটগুলিকে সম্ভাব্যতা হিসাবে বিবেচনা করতে পারবেন না। যে কোনও কাজের জন্য, আপনাকে সম্ভবত টাস্ক-নির্দিষ্ট ডেটা সহ একটি ক্রমাঙ্কন করতে হবে যা আপনাকে সঠিক প্রতি-শ্রেণির স্কোর থ্রেশহোল্ড এবং স্কেলিং নির্ধারণ করতে দেয়।
- YAMNet লক্ষ লক্ষ ইউটিউব ভিডিওতে প্রশিক্ষিত হয়েছে এবং যদিও এগুলি খুব বৈচিত্র্যময়, তবুও কোনও নির্দিষ্ট কাজের জন্য প্রত্যাশিত YouTube ভিডিও এবং অডিও ইনপুটগুলির মধ্যে একটি ডোমেনের অমিল থাকতে পারে৷ আপনার তৈরি করা যেকোনো সিস্টেমে YAMNet ব্যবহারযোগ্য করার জন্য আপনার কিছু পরিমাণ ফাইন-টিউনিং এবং ক্রমাঙ্কন করার আশা করা উচিত।
মডেল কাস্টমাইজেশন
প্রদত্ত প্রাক-প্রশিক্ষিত মডেলগুলি 521টি বিভিন্ন অডিও ক্লাস সনাক্ত করতে প্রশিক্ষিত। ক্লাসের সম্পূর্ণ তালিকার জন্য, মডেল সংগ্রহস্থলে লেবেল ফাইলটি দেখুন।
আপনি মূল সেটে না থাকা ক্লাসগুলি সনাক্ত করার জন্য একটি মডেলকে পুনরায় প্রশিক্ষণ দেওয়ার জন্য ট্রান্সফার লার্নিং নামে পরিচিত একটি কৌশল ব্যবহার করতে পারেন। উদাহরণস্বরূপ, আপনি একাধিক পাখির গান সনাক্ত করতে মডেলটিকে পুনরায় প্রশিক্ষণ দিতে পারেন। এটি করার জন্য, আপনি প্রশিক্ষণ দিতে চান এমন প্রতিটি নতুন লেবেলের জন্য আপনার প্রশিক্ষণ অডিওগুলির একটি সেট প্রয়োজন। প্রস্তাবিত উপায় হল TensorFlow Lite Model Maker লাইব্রেরি ব্যবহার করা যা কোডের কয়েকটি লাইনে কাস্টম ডেটাসেট ব্যবহার করে একটি TensorFlow Lite মডেল প্রশিক্ষণের প্রক্রিয়াকে সহজ করে। এটি প্রয়োজনীয় প্রশিক্ষণের ডেটা এবং সময় কমাতে ট্রান্সফার লার্নিং ব্যবহার করে। আপনি স্থানান্তর শেখার উদাহরণ হিসাবে অডিও স্বীকৃতির জন্য ট্রান্সফার লার্নিং থেকেও শিখতে পারেন।
আরও পড়া এবং সম্পদ
অডিও শ্রেণীবিভাগ সম্পর্কিত ধারণা সম্পর্কে আরও জানতে নিম্নলিখিত সংস্থানগুলি ব্যবহার করুন: