

Zadanie polegające na identyfikacji tego, co reprezentuje dźwięk, nazywa się klasyfikacją dźwięku . Model klasyfikacji dźwięku jest szkolony w zakresie rozpoznawania różnych zdarzeń audio. Można na przykład wytrenować model w zakresie rozpoznawania zdarzeń reprezentujących trzy różne zdarzenia: klaskanie, pstrykanie palcami i pisanie na klawiaturze. TensorFlow Lite zapewnia zoptymalizowane, wstępnie wyszkolone modele, które można wdrożyć w aplikacjach mobilnych. Dowiedz się więcej o klasyfikacji dźwięku za pomocą TensorFlow tutaj .
Poniższa ilustracja przedstawia dane wyjściowe modelu klasyfikacji audio w systemie Android.
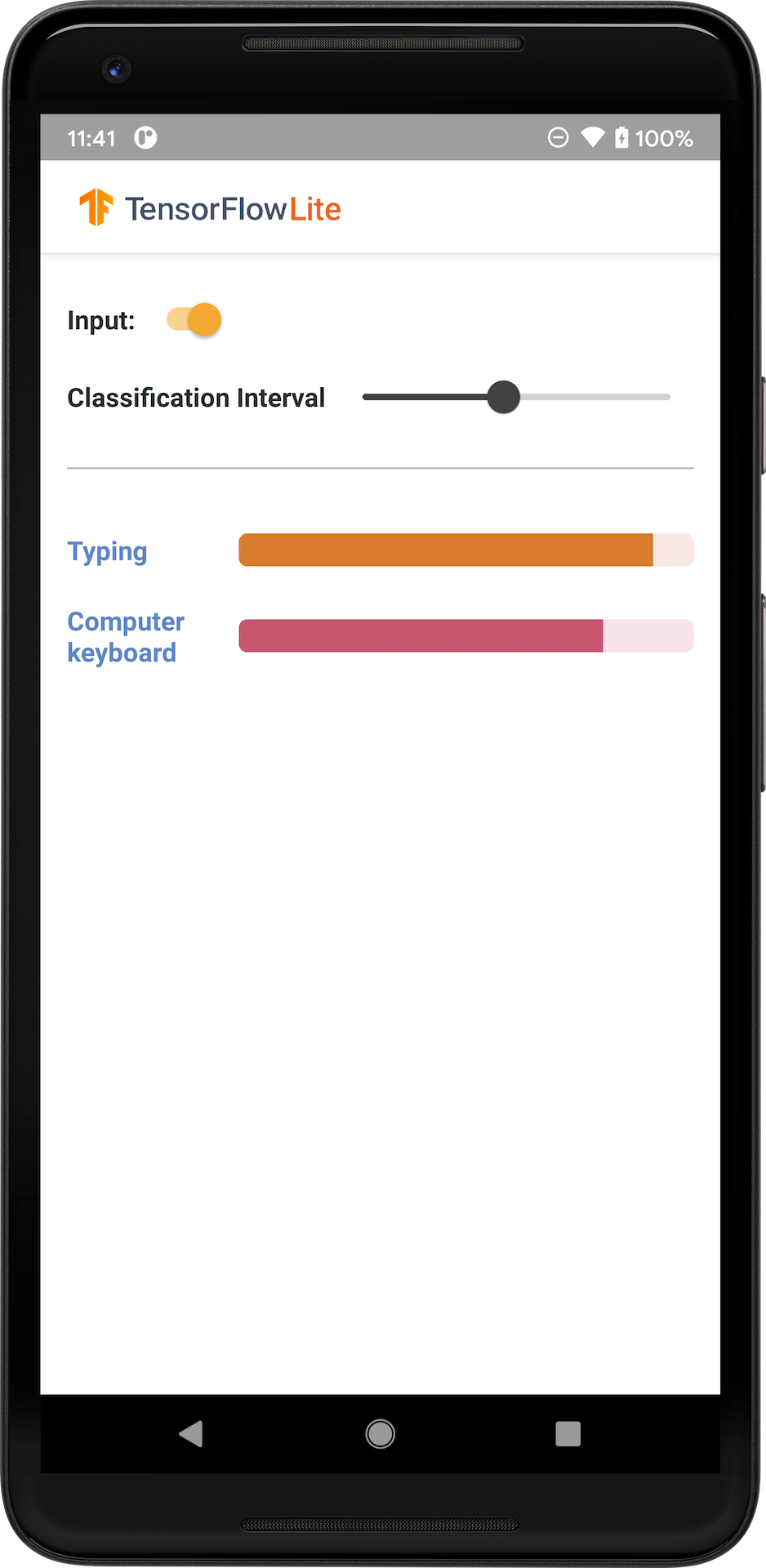
Zaczynaj
Jeśli dopiero zaczynasz korzystać z TensorFlow Lite i pracujesz z systemem Android, zalecamy zapoznanie się z poniższymi przykładowymi aplikacjami, które mogą pomóc Ci rozpocząć.
Możesz wykorzystać gotowy interfejs API z biblioteki zadań TensorFlow Lite, aby zintegrować modele klasyfikacji audio w zaledwie kilku wierszach kodu. Możesz także zbudować własny, niestandardowy potok wnioskowania, korzystając z biblioteki pomocniczej TensorFlow Lite .
Poniższy przykład Androida demonstruje implementację przy użyciu biblioteki zadań TFLite
Jeśli korzystasz z platformy innej niż Android/iOS lub znasz już interfejsy API TensorFlow Lite , pobierz model startowy i pliki pomocnicze (jeśli dotyczy).
Pobierz model startowy z TensorFlow Hub
Opis modelu
YAMNet to klasyfikator zdarzeń audio, który przyjmuje kształt fali audio jako dane wejściowe i dokonuje niezależnych przewidywań dla każdego z 521 zdarzeń audio z ontologii AudioSet . Model wykorzystuje architekturę MobileNet v1 i został przeszkolony przy użyciu korpusu AudioSet. Model ten został pierwotnie wydany w TensorFlow Model Garden, gdzie znajduje się kod źródłowy modelu, oryginalny punkt kontrolny modelu i bardziej szczegółowa dokumentacja.
Jak to działa
Istnieją dwie wersje modelu YAMNet przekonwertowanego do TFLite:
YAMNet To oryginalny model klasyfikacji dźwięku z dynamicznym rozmiarem sygnału wejściowego, odpowiedni do zastosowań w zakresie transferu uczenia się, wdrażania w Internecie i na urządzeniach mobilnych. Ma również bardziej złożone dane wyjściowe.
YAMNet/klasyfikacja to skwantowana wersja z prostszą ramką wejściową o stałej długości (15600 próbek) i zwracającą pojedynczy wektor wyników dla 521 klas zdarzeń audio.
Wejścia
Model akceptuje tablicę 1-D float32 Tensor lub NumPy o długości 15600 zawierającą przebieg o długości 0,975 sekundy reprezentowany jako próbki mono 16 kHz w zakresie [-1.0, +1.0] .
Wyjścia
Model zwraca dwuwymiarowy tensor float32 o kształcie (1, 521) zawierający przewidywane wyniki dla każdej z 521 klas w ontologii AudioSet obsługiwanych przez YAMNet. Indeks kolumny (0-520) tensora partytur jest odwzorowywany na odpowiednią nazwę klasy AudioSet przy użyciu mapy klas YAMNet, która jest dostępna jako powiązany plik yamnet_label_list.txt spakowany do pliku modelu. Poniżej znajdziesz informacje dotyczące użycia.
Odpowiednie zastosowania
Można użyć YAMNet
- jako samodzielny klasyfikator zdarzeń audio, który zapewnia rozsądną bazę dla szerokiej gamy zdarzeń audio.
- jako ekstraktor cech wysokiego poziomu: dane wyjściowe YAMNet dotyczące osadzania 1024-D można wykorzystać jako funkcje wejściowe innego modelu, które można następnie wytrenować na niewielkiej ilości danych dla określonego zadania. Umożliwia to szybkie tworzenie wyspecjalizowanych klasyfikatorów audio bez konieczności stosowania dużej ilości oznakowanych danych i bez konieczności kompleksowego uczenia dużego modelu.
- jako ciepły start: parametry modelu YAMNet można wykorzystać do zainicjowania części większego modelu, co umożliwia szybsze dostrajanie i eksplorację modelu.
Ograniczenia
- Wyniki klasyfikatora YAMNet nie zostały skalibrowane pomiędzy klasami, więc nie można bezpośrednio traktować wyników jako prawdopodobieństw. Dla każdego zadania najprawdopodobniej będziesz musiał przeprowadzić kalibrację przy użyciu danych specyficznych dla zadania, co pozwoli ci przypisać odpowiednie progi punktacji i skalowanie dla poszczególnych zajęć.
- YAMNet został przeszkolony na milionach filmów YouTube i chociaż są one bardzo zróżnicowane, nadal może występować rozbieżność w domenie pomiędzy przeciętnym filmem w YouTube a wejściami audio oczekiwanymi dla danego zadania. Powinieneś spodziewać się pewnych dostrojeń i kalibracji, aby YAMNet był użyteczny w każdym budowanym systemie.
Personalizacja modelu
Dostarczone wstępnie wyszkolone modele są przeszkolone do wykrywania 521 różnych klas audio. Pełną listę klas znajdziesz w pliku etykiet w repozytorium modelu .
Możesz użyć techniki zwanej uczeniem transferowym, aby ponownie wytrenować model w celu rozpoznawania klas, które nie znajdują się w oryginalnym zestawie. Można na przykład ponownie wytrenować model w celu wykrywania wielu śpiewów ptaków. Aby to zrobić, będziesz potrzebować zestawu nagrań audio szkoleniowych dla każdej nowej wytwórni, którą chcesz szkolić. Zalecanym sposobem jest użycie biblioteki TensorFlow Lite Model Maker , która upraszcza proces uczenia modelu TensorFlow Lite przy użyciu niestandardowego zestawu danych, w kilku linijkach kodu. Wykorzystuje uczenie transferowe, aby zmniejszyć ilość wymaganych danych i czasu szkoleniowego. Możesz także uczyć się na podstawie uczenia transferowego w zakresie rozpoznawania dźwięku jako przykładu uczenia się transferowego.
Dalsza lektura i zasoby
Aby dowiedzieć się więcej o pojęciach związanych z klasyfikacją audio, skorzystaj z następujących zasobów: