
| | |  Afficher la source sur GitHub Afficher la source sur GitHub |
Les recommandations personnalisées sont largement utilisées pour divers cas d'utilisation sur les appareils mobiles, tels que la récupération de contenu multimédia, la suggestion de produits d'achat et la recommandation de la prochaine application. Si vous souhaitez fournir des recommandations personnalisées dans votre application tout en respectant la confidentialité des utilisateurs, nous vous recommandons d'explorer l'exemple et la boîte à outils suivants.
Commencer
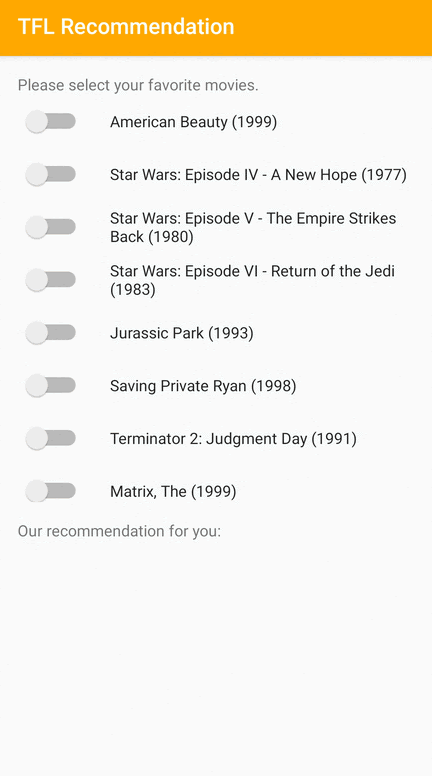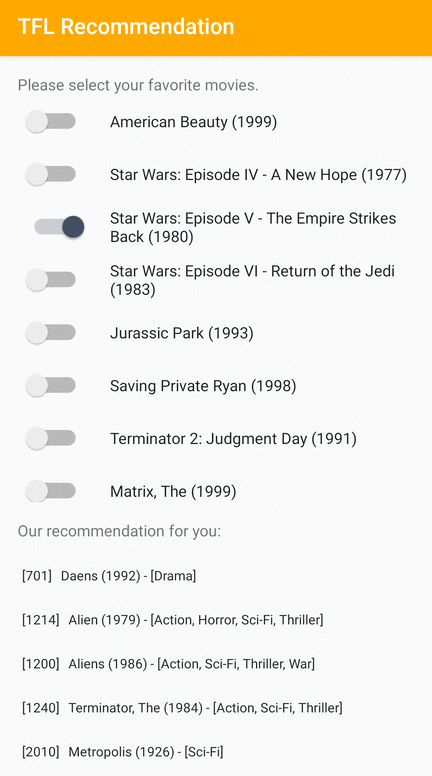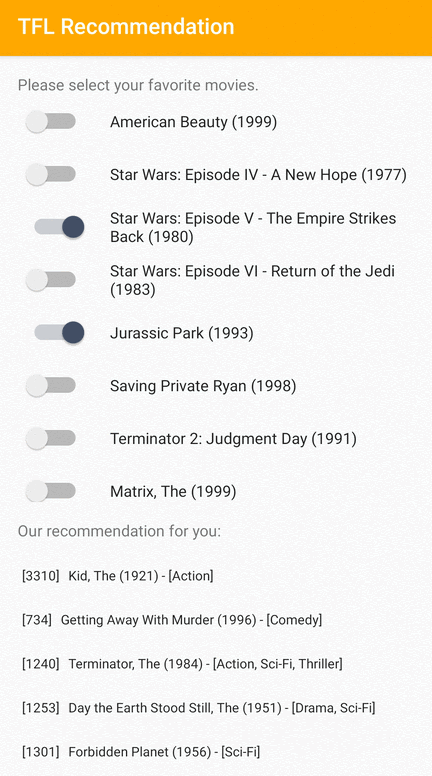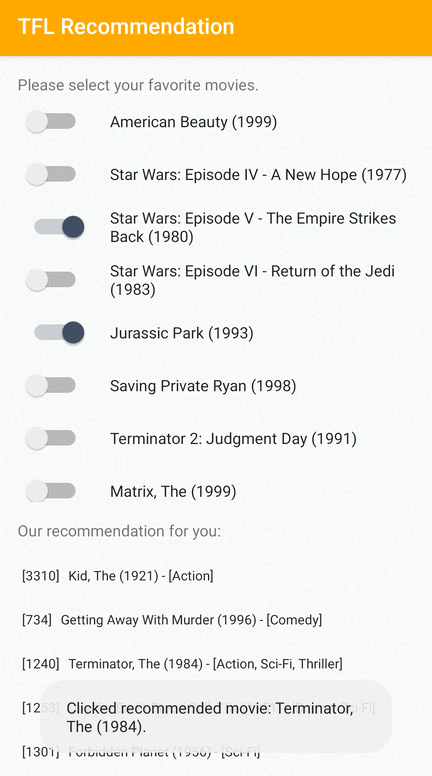
Nous fournissons un exemple d'application TensorFlow Lite qui montre comment recommander des éléments pertinents aux utilisateurs sur Android.
Si vous utilisez une plate-forme autre qu'Android ou si vous connaissez déjà les API TensorFlow Lite, vous pouvez télécharger notre modèle de recommandation de démarrage.
Télécharger le modèle de démarrage
Nous fournissons également un script de formation dans Github pour former votre propre modèle de manière configurable.
Comprendre l'architecture du modèle
Nous exploitons une architecture de modèle à double encodeur, avec un encodeur de contexte pour encoder l'historique séquentiel des utilisateurs et un encodeur d'étiquette pour encoder le candidat à la recommandation prédit. La similarité entre les codages de contexte et d'étiquette est utilisée pour représenter la probabilité que le candidat prédit réponde aux besoins de l'utilisateur.
Trois techniques différentes de codage séquentiel de l'historique des utilisateurs sont fournies avec cette base de code :
- Encodeur de sac de mots (BOW) : moyenne des intégrations des activités des utilisateurs sans tenir compte de l'ordre du contexte.
- Encodeur de réseau neuronal convolutif (CNN) : application de plusieurs couches de réseaux neuronaux convolutifs pour générer un codage de contexte.
- Encodeur de réseau neuronal récurrent (RNN) : application d'un réseau neuronal récurrent pour coder la séquence de contexte.
Pour modéliser chaque activité utilisateur, nous pourrions utiliser l'ID de l'élément d'activité (basé sur l'ID), ou plusieurs fonctionnalités de l'élément (basées sur les fonctionnalités), ou une combinaison des deux. Le modèle basé sur les fonctionnalités utilise plusieurs fonctionnalités pour coder collectivement le comportement des utilisateurs. Avec cette base de code, vous pouvez créer des modèles basés sur des identifiants ou des fonctionnalités de manière configurable.
Après la formation, un modèle TensorFlow Lite sera exporté et pourra directement fournir des prédictions top-K parmi les candidats à la recommandation.
Utilisez vos données d'entraînement
En plus du modèle entraîné, nous fournissons une boîte à outils open source dans GitHub pour entraîner des modèles avec vos propres données. Vous pouvez suivre ce didacticiel pour apprendre à utiliser la boîte à outils et à déployer des modèles entraînés dans vos propres applications mobiles.
Veuillez suivre ce didacticiel pour appliquer la même technique que celle utilisée ici pour entraîner un modèle de recommandation à l'aide de vos propres ensembles de données.
Exemples
À titre d'exemple, nous avons formé des modèles de recommandation avec des approches basées sur l'ID et sur les fonctionnalités. Le modèle basé sur les ID prend uniquement les ID de film en entrée, et le modèle basé sur les fonctionnalités prend à la fois les ID de film et les ID de genre de film en entrées. Veuillez trouver les exemples d’entrées et de sorties suivants.
Contributions
ID de film contextuel :
- Le Roi Lion (ID: 362)
- Histoire de jouets (ID : 1)
- (et plus)
Identifiants contextuels des genres de films :
- Animation (ID : 15)
- Enfants (ID: 9)
- Comédie musicale (ID : 13)
- Animation (ID : 15)
- Enfants (ID: 9)
- Comédie (ID: 2)
- (et plus)
Les sorties:
- ID de films recommandés :
- Histoire de jouets 2 (ID : 3114)
- (et plus)
Repères de performances
Les numéros de référence de performance sont générés avec l'outil décrit ici .
| Nom du modèle | Taille du modèle | Appareil | CPU |
|---|---|---|---|
| recommandation (ID du film en entrée) | 0,52 Mo | Pixel 3 | 0,09 ms* |
| Pixel4 | 0,05 ms* | ||
| recommandation (ID du film et genre du film comme entrées) | 1,3 Mo | Pixel 3 | 0,13 ms* |
| Pixel4 | 0,06 ms* |
* 4 fils utilisés.
Utilisez vos données d'entraînement
En plus du modèle entraîné, nous fournissons une boîte à outils open source dans GitHub pour entraîner des modèles avec vos propres données. Vous pouvez suivre ce didacticiel pour apprendre à utiliser la boîte à outils et à déployer des modèles entraînés dans vos propres applications mobiles.
Veuillez suivre ce didacticiel pour appliquer la même technique que celle utilisée ici pour entraîner un modèle de recommandation à l'aide de vos propres ensembles de données.
Conseils pour personnaliser le modèle avec vos données
Le modèle pré-entraîné intégré dans cette application de démonstration est formé avec l'ensemble de données MovieLens . Vous souhaiterez peut-être modifier la configuration du modèle en fonction de vos propres données, telles que la taille du vocabulaire, l'intégration des dimensions et la longueur du contexte d'entrée. Voici quelques conseils :
Longueur du contexte d'entrée : la meilleure longueur du contexte d'entrée varie selon les ensembles de données. Nous suggérons de sélectionner la longueur du contexte d'entrée en fonction de la corrélation entre les événements d'étiquette et les intérêts à long terme par rapport au contexte à court terme.
Sélection du type d'encodeur : nous vous suggérons de sélectionner le type d'encodeur en fonction de la longueur du contexte d'entrée. L'encodeur de sac de mots fonctionne bien pour les contextes d'entrée courts (par exemple <10), les encodeurs CNN et RNN apportent plus de capacité de résumé pour les contextes d'entrée longs.
L'utilisation de fonctionnalités sous-jacentes pour représenter des éléments ou des activités utilisateur pourrait améliorer les performances du modèle, mieux accueillir de nouveaux éléments, éventuellement réduire les espaces d'intégration, réduisant ainsi la consommation de mémoire et plus conviviale sur l'appareil.