
| | |  GitHub에서 소스 보기 GitHub에서 소스 보기 |
개인화된 추천은 미디어 콘텐츠 검색, 쇼핑 제품 제안 및 다음 앱 추천과 같은 모바일 기기의 다양한 사용 사례에 널리 사용됩니다. 사용자 개인 정보를 보호하면서 애플리케이션에 개인화된 추천을 제공하는 데 관심이 있다면 다음 예제와 도구 키트를 살펴보세요.
참고: 모델을 사용자 지정하려면 TensorFlow Lite Model Maker를 사용해 보세요.
시작하기
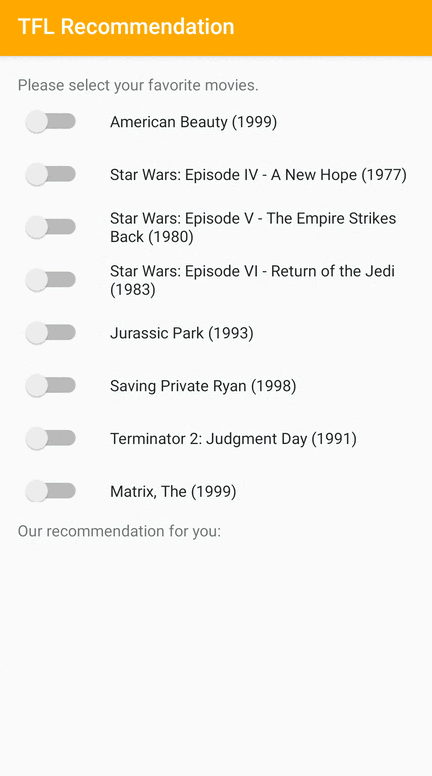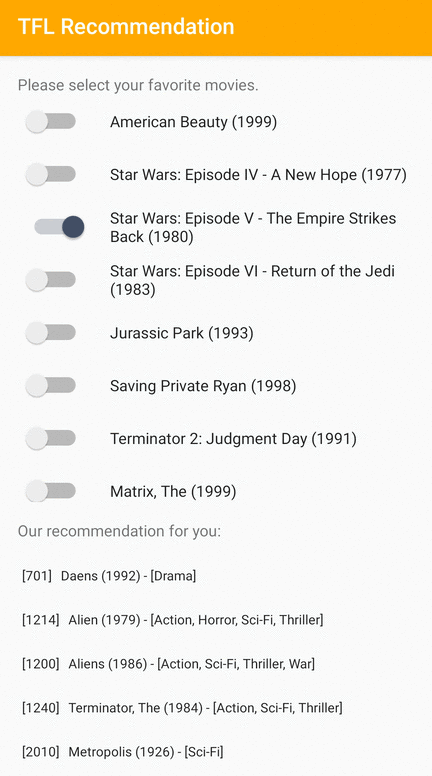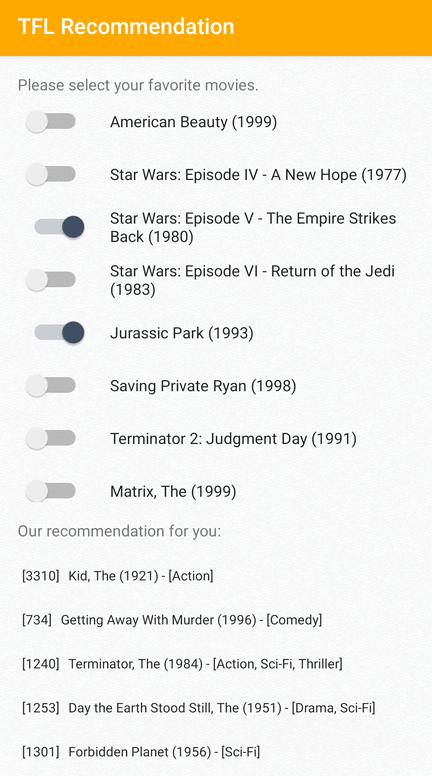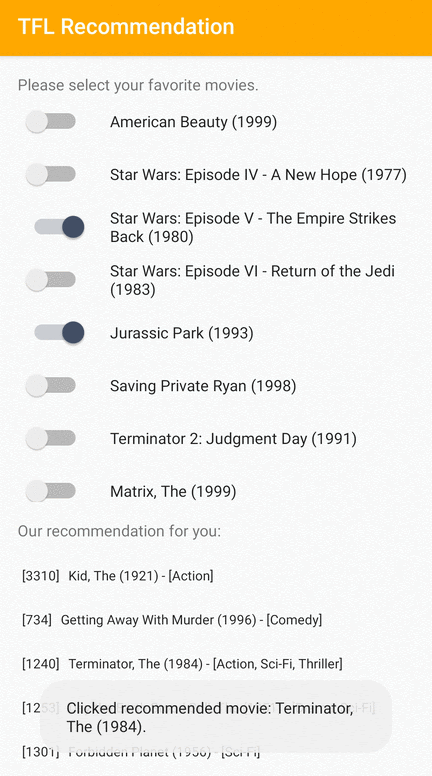
Android 사용자에게 관련 항목을 추천하는 방법을 보여주는 TensorFlow Lite 샘플 애플리케이션을 제공합니다.
Android 이외의 플랫폼을 사용 중이거나 TensorFlow Lite API에 이미 익숙한 경우, 스타터 추천 모델을 다운로드할 수 있습니다.
구성 가능한 방식으로 자신의 모델을 훈련하도록 Github에서 훈련 스크립트도 제공합니다.
모델 아키텍처 이해하기
컨텍스트 인코더를 사용하여 순차 사용자 기록을 인코딩하고 레이블 인코더를 사용하여 예측된 추천 후보를 인코딩하는 이중 인코더 모델 아키텍처를 이용합니다. 컨텍스트와 레이블 인코딩 간의 유사성은 예측된 후보가 사용자의 요구를 충족할 가능성을 나타내는 데 사용됩니다.
이 코드 베이스에는 다음의 세 가지 순차적 사용자 기록 인코딩 기술이 제공됩니다.
- BOW(bag-of-words encoder): 컨텍스트 순서를 고려하지 않고 사용자 활동의 임베딩을 평균화합니다.
- CNN(컨볼루셔널 신경망 인코더): 여러 레이어의 컨볼루셔널 신경망을 적용하여 컨텍스트 인코딩을 생성합니다.
- RNN(순환 신경망): 순환 신경망을 적용하여 컨텍스트 시퀀스를 인코딩합니다.
각 사용자 활동을 모델링하기 위해 활동 항목의 ID(ID 기반) 또는 항목의 여러 특성(특성 기반) 또는 둘의 조합을 사용할 수 있습니다. 특성 기반 모델은 사용자의 동작을 집합적으로 인코딩하기 위해 여러 특성을 활용합니다. 이 코드 베이스를 사용하여 구성 가능한 방식으로 ID 기반 또는 특성 기반 모델을 만들 수 있습니다.
훈련 후, TensorFlow Lite 모델을 내보내 추천 후보 중에서 top-K 예측을 직접 제공할 수 있습니다.
고유한 훈련 데이터 사용하기
훈련된 모델 외에도 고유한 데이터로 모델을 훈련할 수 있는 오픈 소스 GitHub 도구 키트가 제공됩니다. 이 튜토리얼의 설명에 따라 도구 키트를 사용하고 자신의 모바일 애플리케이션에서 훈련된 모델을 배포하는 방법을 배울 수 있습니다.
이 튜토리얼에 따라 여기서 사용된 것과 같은 기술을 적용하여 고유한 데이터세트로 추천 모델을 훈련해 보세요.
예시
예를 들어 ID 기반 및 특성 기반 접근 방식을 모두 사용하여 추천 모델을 훈련했습니다. ID 기반 모델은 영화 ID만 입력으로 사용하고 특성 기반 모델은 영화 ID와 영화 장르 ID를 모두 입력으로 사용합니다. 다음 입력 및 출력 예를 확인해 보세요.
입력
컨텍스트 영화 ID:
- 라이온 킹(ID: 362)
- 토이 스토리(ID: 1)
- (기타 등등)
컨텍스트 영화 장르 ID:
- 애니메이션(ID: 15)
- 어린이(ID: 9)
- 뮤지컬(ID: 13)
- 애니메이션(ID: 15)
- 어린이(ID: 9)
- 코미디(ID: 2)
- (기타 등등)
출력:
- 추천 영화 ID:
- 토이 스토리 2(ID: 3114)
- (기타 등등)
참고: 사전 훈련된 모델은 연구 목적으로 MovieLens 데이터세트를 기반으로 구축되었습니다.
성능 벤치마크
성능 벤치 마크 수치는 여기에 설명된 도구를 사용하여 생성됩니다.
| 모델명 | 모델 크기 | 기기 | CPU |
|---|---|---|---|
| 추천(영화 ID를 입력으로) | 0.52Mb | Pixel 3 | 0.09ms* |
| Pixel 4 | 0.05ms * | ||
| 추천(영화 ID 및 영화 장르를 입력으로) | 1.3Mb | Pixel 3 | 0.13ms* |
| Pixel 4 | 0.06ms* |
- 4개의 스레드가 사용되었습니다.
고유한 훈련 데이터 사용하기
훈련된 모델 외에도 고유한 데이터로 모델을 훈련할 수 있는 오픈 소스 GitHub 도구 키트가 제공됩니다. 이 튜토리얼의 설명에 따라 도구 키트를 사용하고 자신의 모바일 애플리케이션에서 훈련된 모델을 배포하는 방법을 배울 수 있습니다.
이 튜토리얼에 따라 여기서 사용된 것과 같은 기술을 적용하여 고유한 데이터세트로 추천 모델을 훈련해 보세요.
고유 데이터를 사용한 모델 사용자 정의 팁
이 데모 애플리케이션에 통합된 미리 훈련된 모델은 MovieLens 데이터세트로 훈련했으며 어휘 크기, 내장 차원 및 입력 컨텍스트 길이와 같은 사용자 고유의 데이터를 기반으로 모델 구성을 수정해야 할 수 있습니다. 다음은 몇 가지 팁입니다.
입력 컨텍스트 길이: 최상의 입력 컨텍스트 길이는 데이터세트에 따라 다릅니다. 레이블 이벤트가 장기 관심사 및 단기 컨텍스트와 얼마나 관련성이 있는지에 따라 입력 컨텍스트 길이를 선택하는 것이 좋습니다.
인코더 유형 선택: 입력 컨텍스트 길이에 따라 인코더 유형을 선택하는 것이 좋습니다. Bag-of-words 인코더는 짧은 입력 컨텍스트 길이(예: <10)에 효과적이며 CNN 및 RNN 인코더는 긴 입력 컨텍스트 길이에서 더 많은 요약 기능을 제공합니다.
항목 또는 사용자 활동을 나타내기 위해 기본 요소를 사용하면 모델 성능을 개선하고 새로운 항목을 더 잘 수용할 수 있으며 임베딩 공간을 축소할 수 있으므로 메모리 소비가 줄어들고 기기에 더 친숙해질 수 있습니다.