
Takviyeli öğrenme kullanılarak eğitilen ve TensorFlow Lite ile konuşlandırılan bir temsilciye karşı masa oyunu oynayın.
Başlamak
TensorFlow Lite'ta yeniyseniz ve Android ile çalışıyorsanız, başlamanıza yardımcı olabilecek aşağıdaki örnek uygulamayı incelemenizi öneririz.
Android dışında bir platform kullanıyorsanız veya TensorFlow Lite API'lerine zaten aşina iseniz eğitimli modelimizi indirebilirsiniz.
Nasıl çalışır
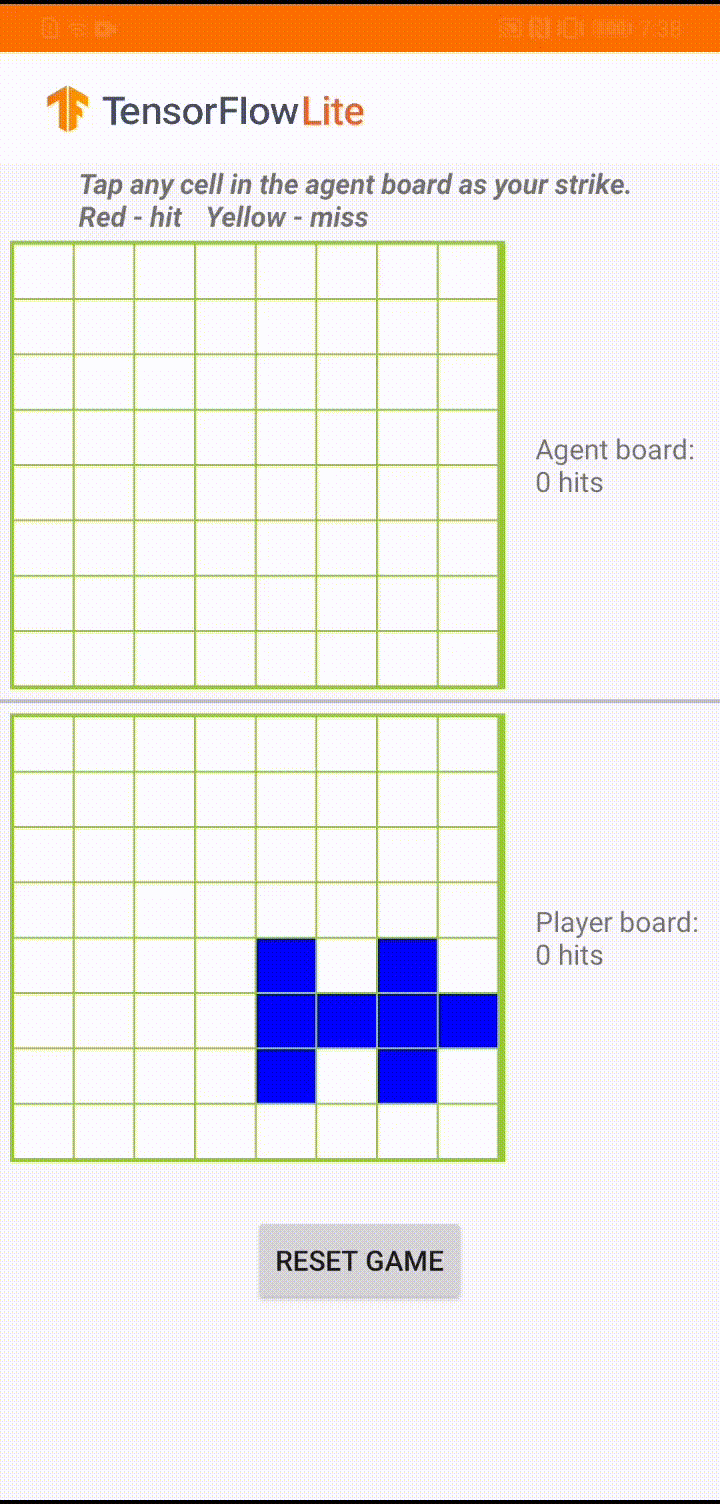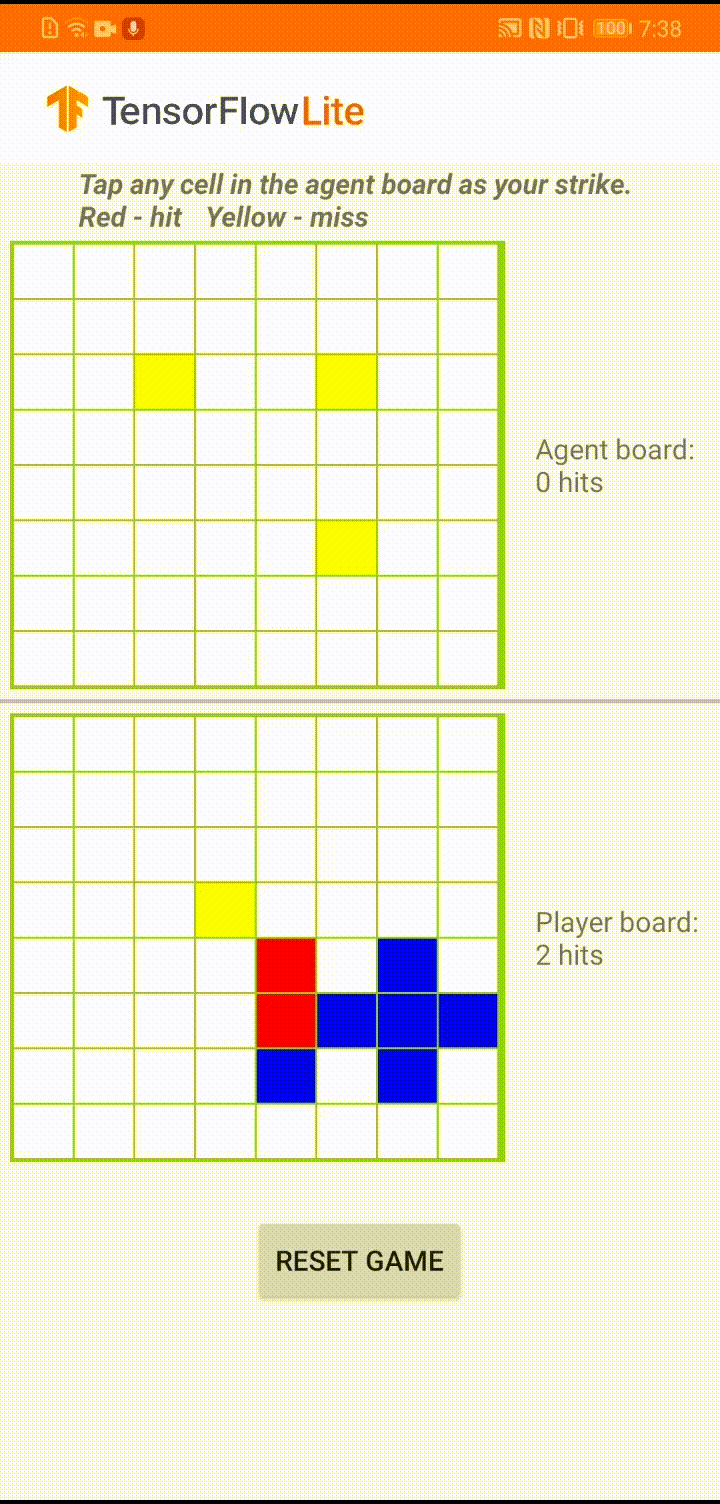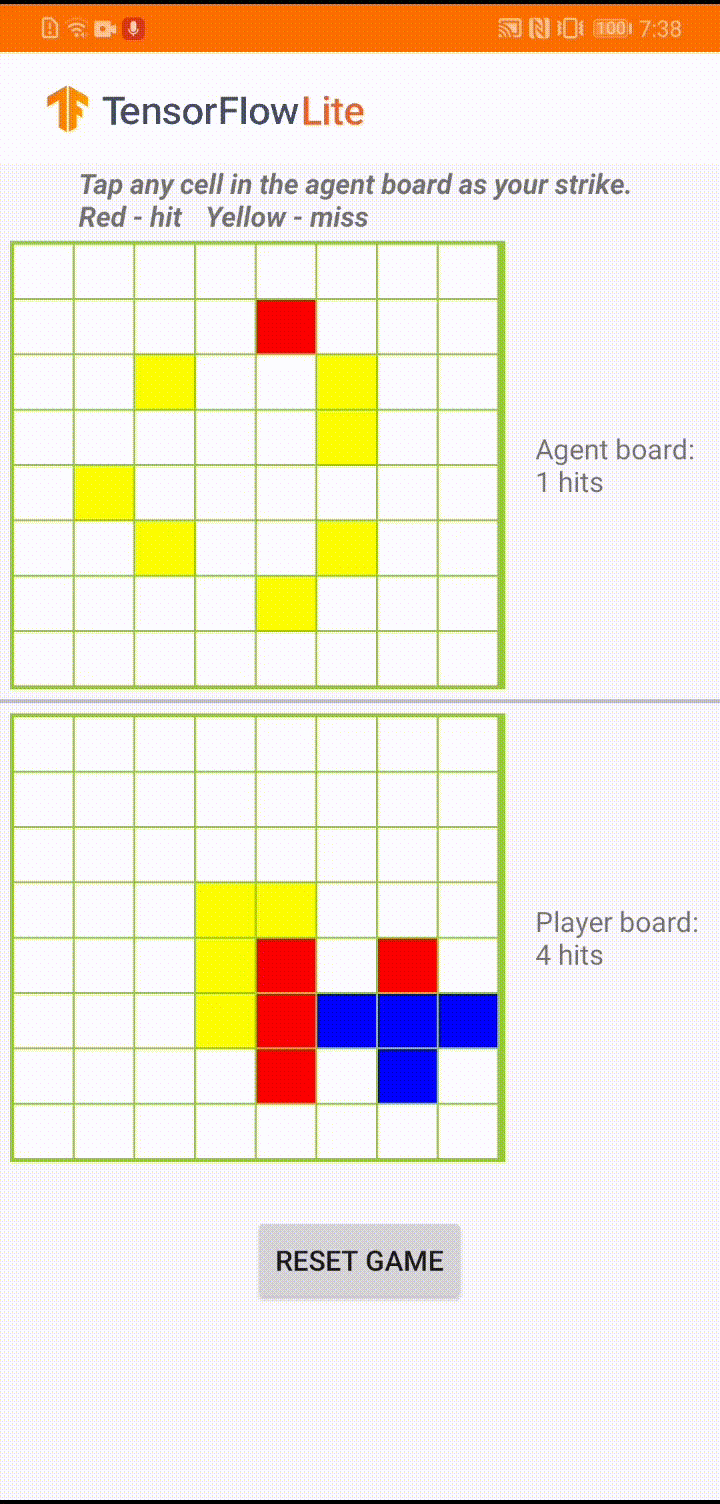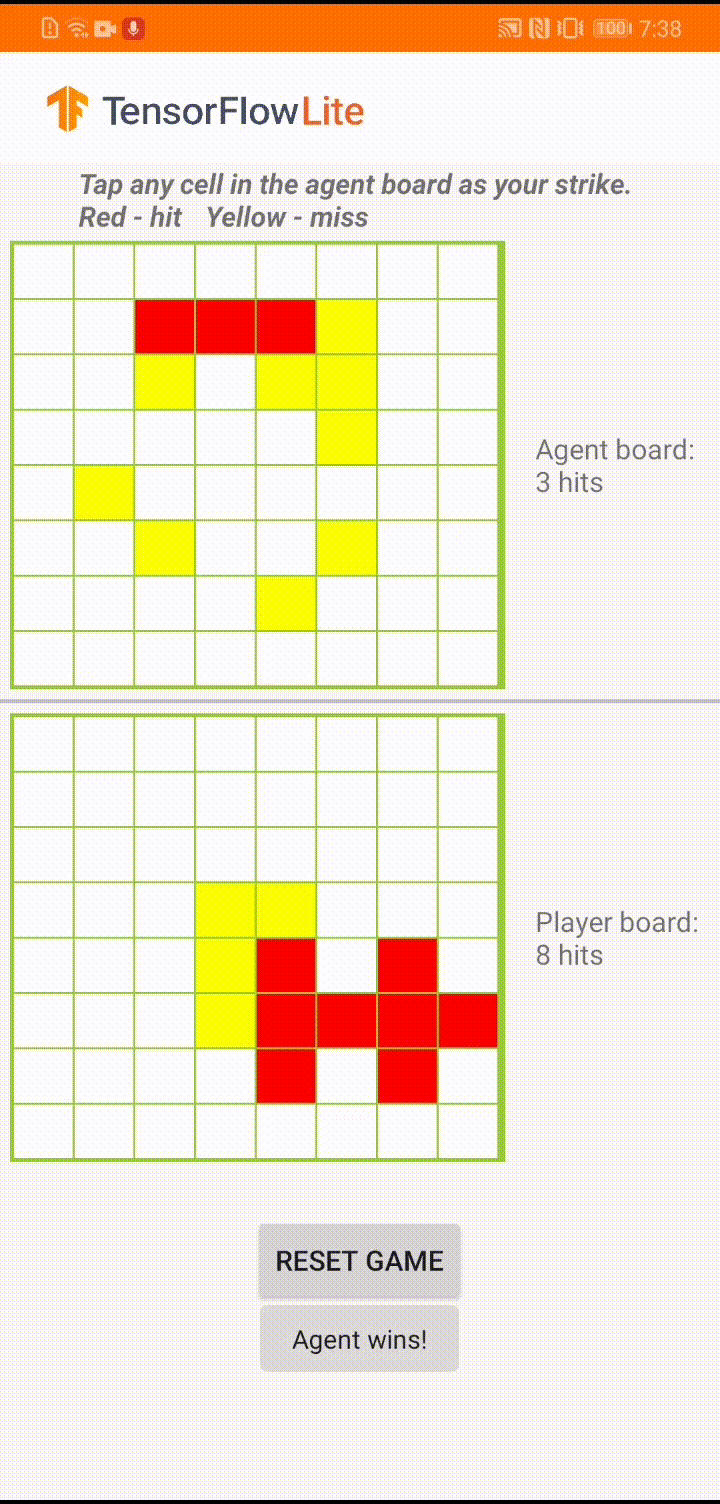
Model, bir oyun temsilcisinin 'Plane Strike' adlı küçük bir masa oyununu oynaması için tasarlandı. Bu oyuna ve kurallarına hızlı bir giriş için lütfen bu README dosyasına bakın.
Uygulamanın kullanıcı arayüzünün altında, insan oyuncuya karşı oynayan bir ajan oluşturduk. Aracı, tahta durumunu girdi olarak alan ve 64 olası tahta hücresinin her biri için tahmin edilen puanı çıkaran 3 katmanlı bir MLP'dir. Model, politika gradyanı (REINFORCE) kullanılarak eğitilir ve eğitim kodunu burada bulabilirsiniz. Aracıyı eğittikten sonra modeli TFLite'a dönüştürüp Android uygulamasına dağıtıyoruz.
Android uygulamasında gerçek oyun sırasında, harekete geçme sırası temsilciye geldiğinde, temsilci, önceki başarılı ve başarısız vuruşlar (isabetler ve ıskalamalar) hakkında bilgi içeren insan oyuncunun tahta durumuna (alttaki tahta) bakar. ve bir sonraki vuruşun nereye yapılacağını tahmin etmek için eğitilmiş modeli kullanır, böylece oyunu insan oyuncudan önce bitirebilir.
Performans kıyaslamaları
Performans kıyaslama numaraları burada açıklanan araçla oluşturulur.
| Model adı | Modeli boyutu | Cihaz | İşlemci |
|---|---|---|---|
| Politika Gradyanı | 84 Kb | Piksel 3 (Android 10) | 0,01 ms* |
| Piksel 4 (Android 10) | 0,01 ms* |
* 1 konu kullanıldı.
Girişler
Model, kart durumu olarak (1, 8, 8)'in 3 boyutlu float32 Tensörünü kabul eder.
çıktılar
Model, 64 olası vuruş pozisyonunun her biri için tahmin edilen puanlar olarak 2 boyutlu float32 şekil Tensörünü (1,64) döndürür.
Kendi modelinizi eğitin
Eğitim kodundaki BOARD_SIZE parametresini değiştirerek kendi modelinizi daha büyük/daha küçük bir tahta için eğitebilirsiniz.