
Chơi trò chơi cờ bàn với một đặc vụ, được huấn luyện bằng phương pháp học tăng cường và được triển khai với TensorFlow Lite.
Bắt đầu
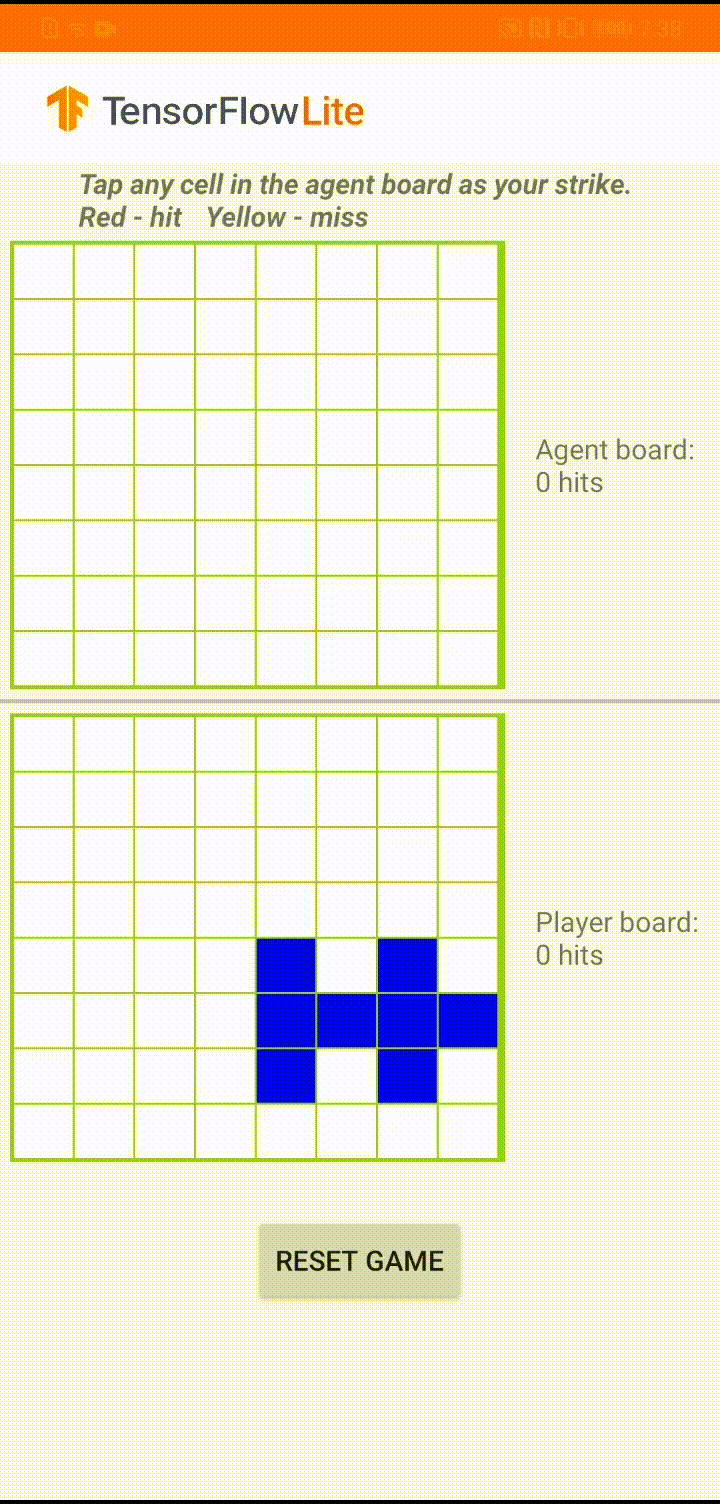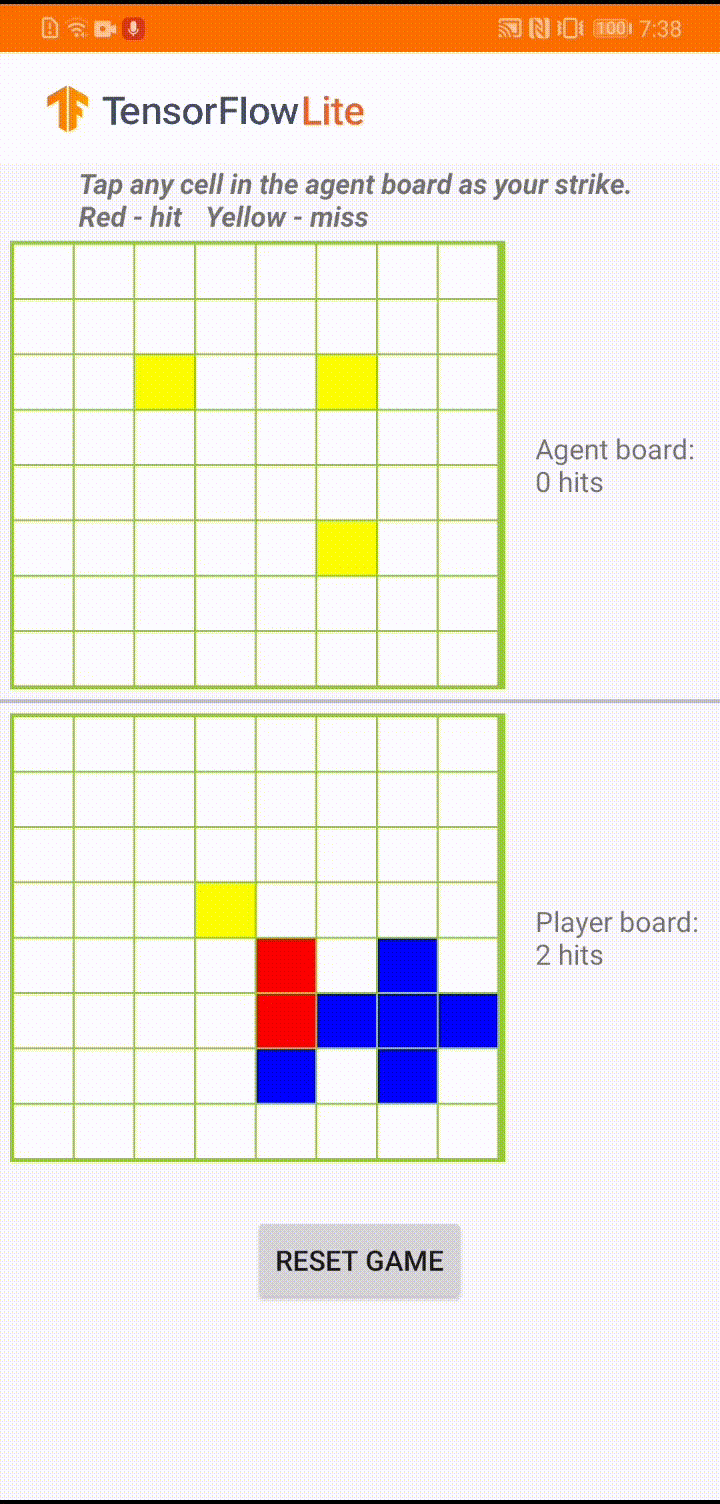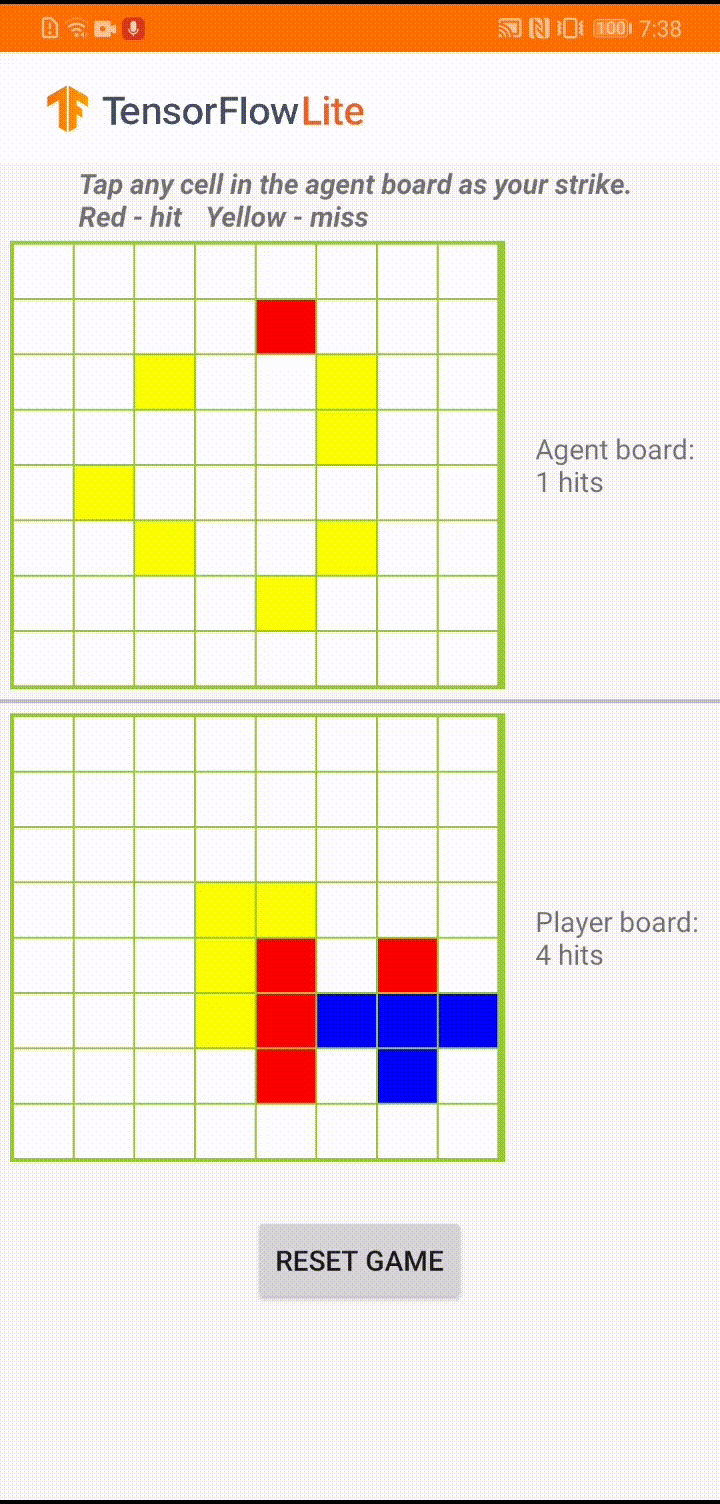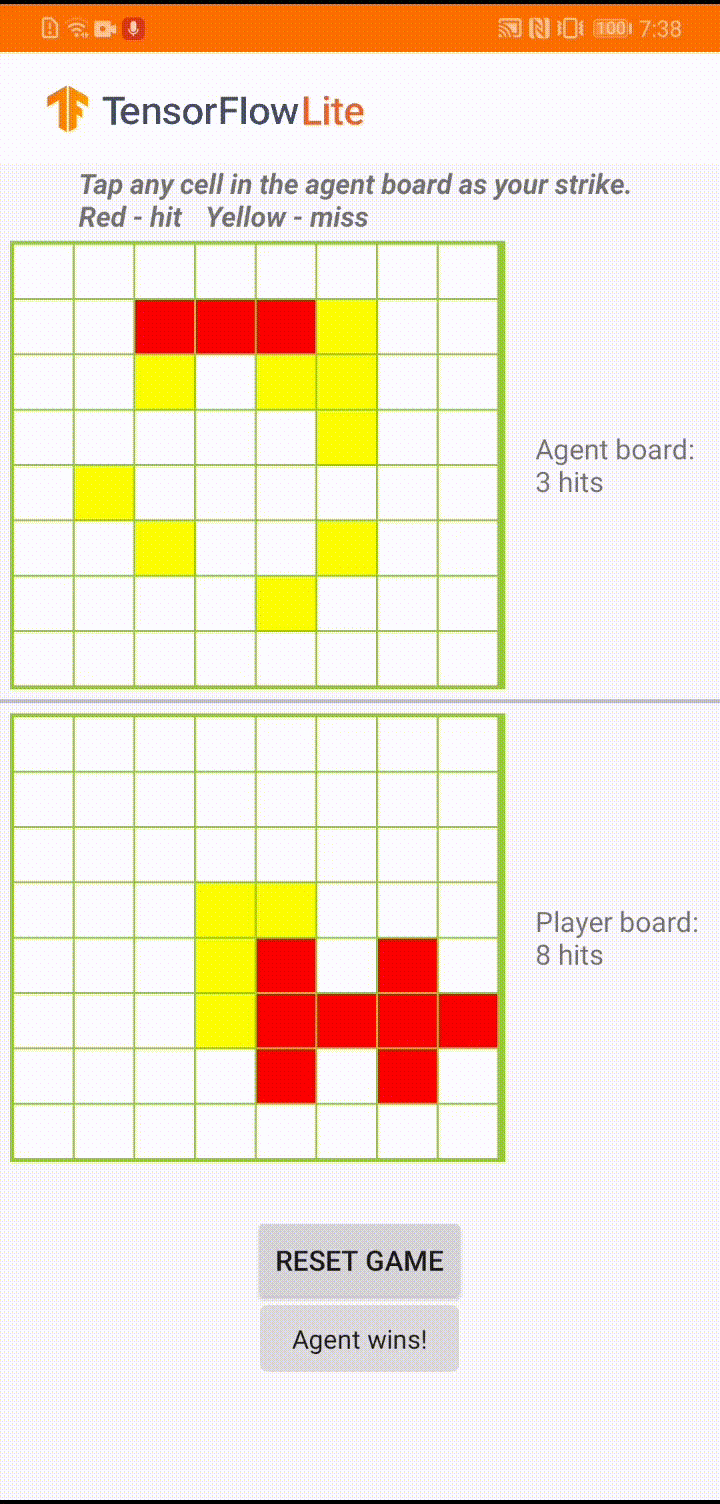
Nếu bạn chưa quen với TensorFlow Lite và đang làm việc với Android, chúng tôi khuyên bạn nên khám phá ứng dụng ví dụ sau để có thể giúp bạn bắt đầu.
Nếu bạn đang sử dụng nền tảng không phải Android hoặc đã quen với API TensorFlow Lite , bạn có thể tải xuống mô hình đã đào tạo của chúng tôi.
Làm thế nào nó hoạt động
Mô hình này được xây dựng để một đại lý trò chơi chơi một trò chơi board nhỏ có tên là 'Plane Strike'. Để được giới thiệu nhanh về trò chơi này và các quy tắc của nó, vui lòng tham khảo README này.
Bên dưới giao diện người dùng của ứng dụng, chúng tôi đã xây dựng một tác nhân chống lại người chơi là con người. Tác nhân là một MLP 3 lớp lấy trạng thái bảng làm đầu vào và đưa ra điểm dự đoán cho mỗi ô trong số 64 ô bảng có thể có. Mô hình được đào tạo bằng cách sử dụng gradient chính sách (REINFORCE) và bạn có thể tìm thấy mã đào tạo tại đây . Sau khi đào tạo tác nhân, chúng tôi chuyển đổi mô hình thành TFLite và triển khai nó trong ứng dụng Android.
Trong quá trình chơi trò chơi thực tế trong ứng dụng Android, khi đến lượt tác nhân hành động, tác nhân sẽ xem trạng thái bàn cờ của người chơi (bảng ở dưới cùng), trong đó chứa thông tin về các lần đánh thành công và không thành công trước đó (trượt và đánh trượt) và sử dụng mô hình đã được huấn luyện để dự đoán nơi sẽ tấn công tiếp theo, để nó có thể kết thúc trò chơi trước khi người chơi thực hiện.
Điểm chuẩn hiệu suất
Số điểm chuẩn hiệu suất được tạo bằng công cụ được mô tả ở đây .
| Tên mẫu | Kích thước mô hình | Thiết bị | CPU |
|---|---|---|---|
| Độ dốc chính sách | 84 Kb | Pixel 3 (Android 10) | 0,01 mili giây* |
| Pixel 4 (Android 10) | 0,01 mili giây* |
* 1 chủ đề được sử dụng.
Đầu vào
Mô hình này chấp nhận Tensor float32 3-D của (1, 8, 8) làm trạng thái bảng.
đầu ra
Mô hình trả về một Tensor 2-D có hình dạng float32 (1,64) làm điểm dự đoán cho mỗi vị trí trong số 64 vị trí tấn công có thể xảy ra.
Đào tạo mô hình của riêng bạn
Bạn có thể huấn luyện mô hình của riêng mình cho bảng lớn hơn/nhỏ hơn bằng cách thay đổi tham số BOARD_SIZE trong mã huấn luyện .