
Zagraj w grę planszową przeciwko agentowi, który jest szkolony przy użyciu uczenia się przez wzmacnianie i wdrażany za pomocą TensorFlow Lite.
Zaczynaj
Jeśli dopiero zaczynasz korzystać z TensorFlow Lite i pracujesz z systemem Android, zalecamy zapoznanie się z poniższą przykładową aplikacją, która może pomóc Ci rozpocząć.
Jeśli korzystasz z platformy innej niż Android lub znasz już API TensorFlow Lite , możesz pobrać nasz przeszkolony model.
Jak to działa
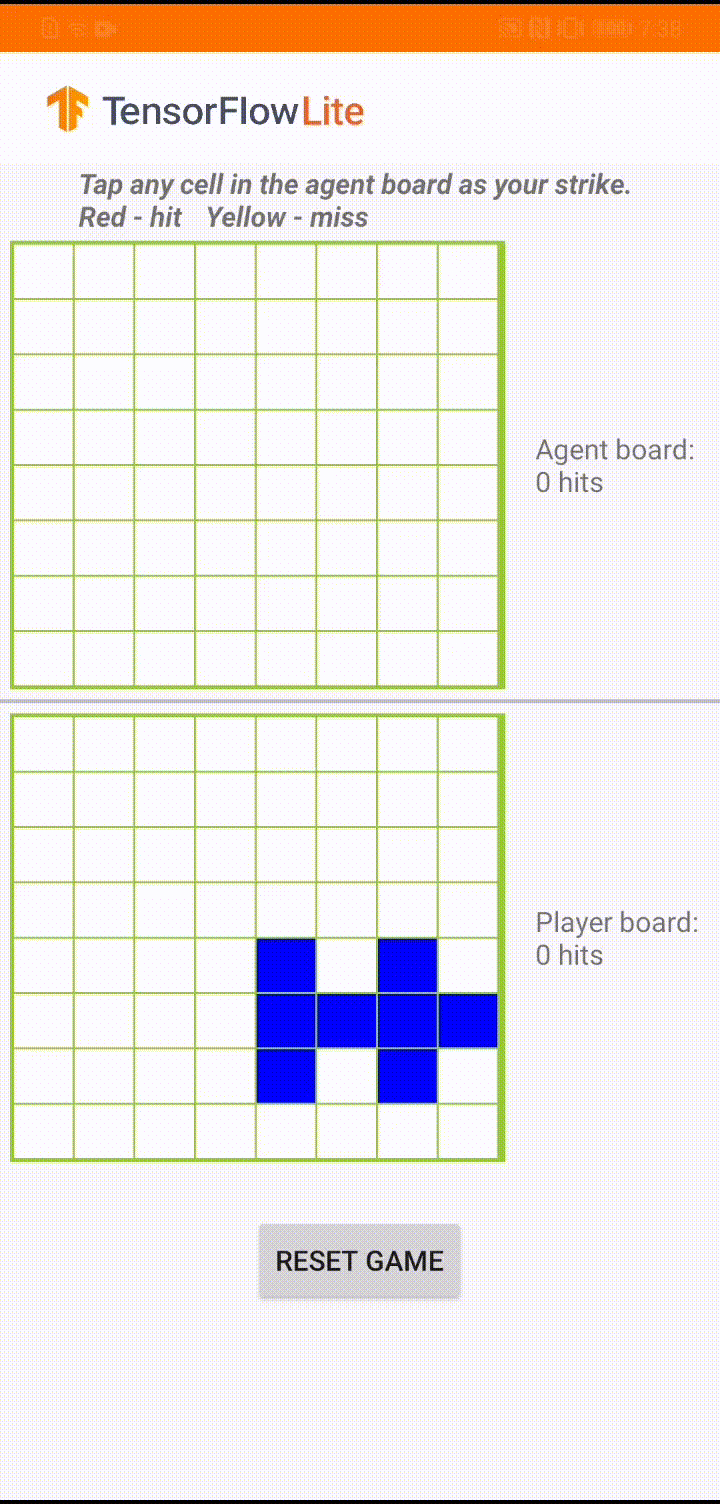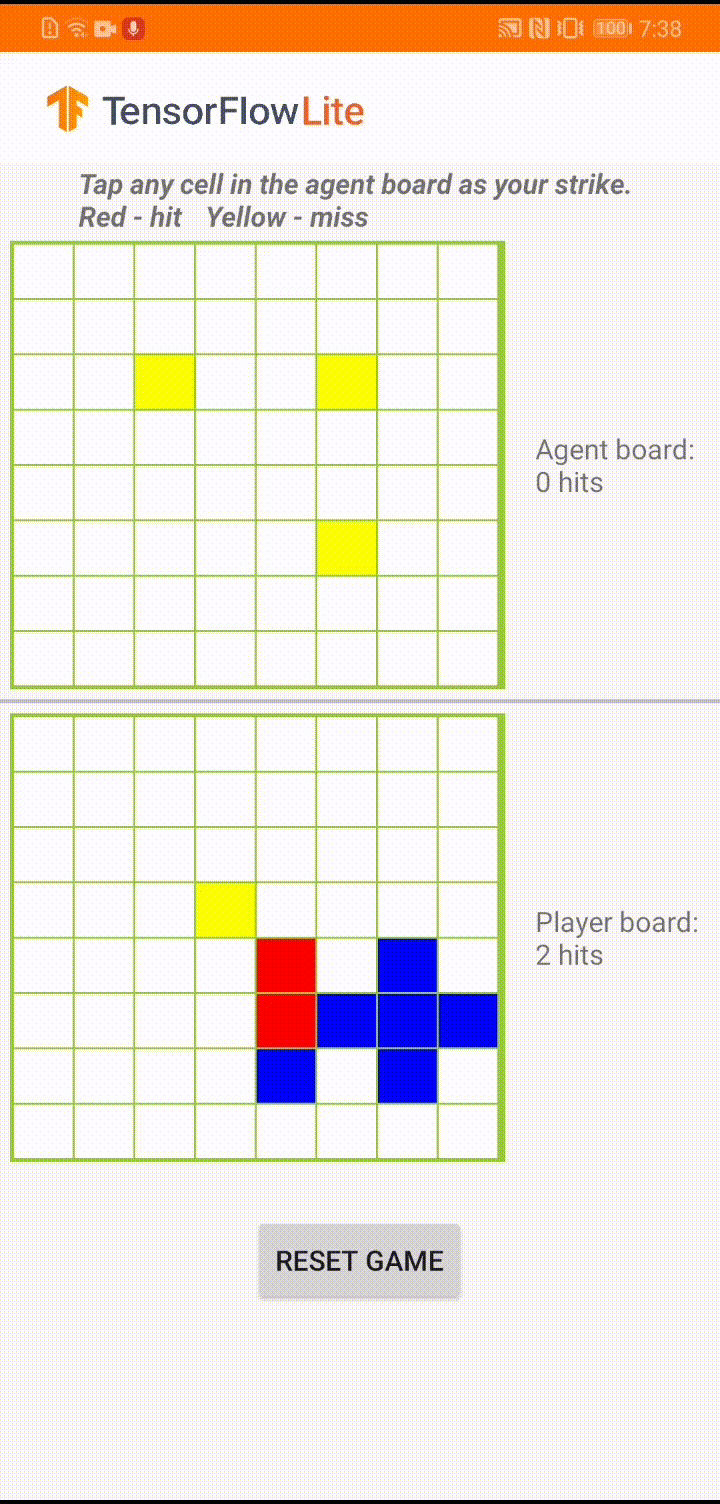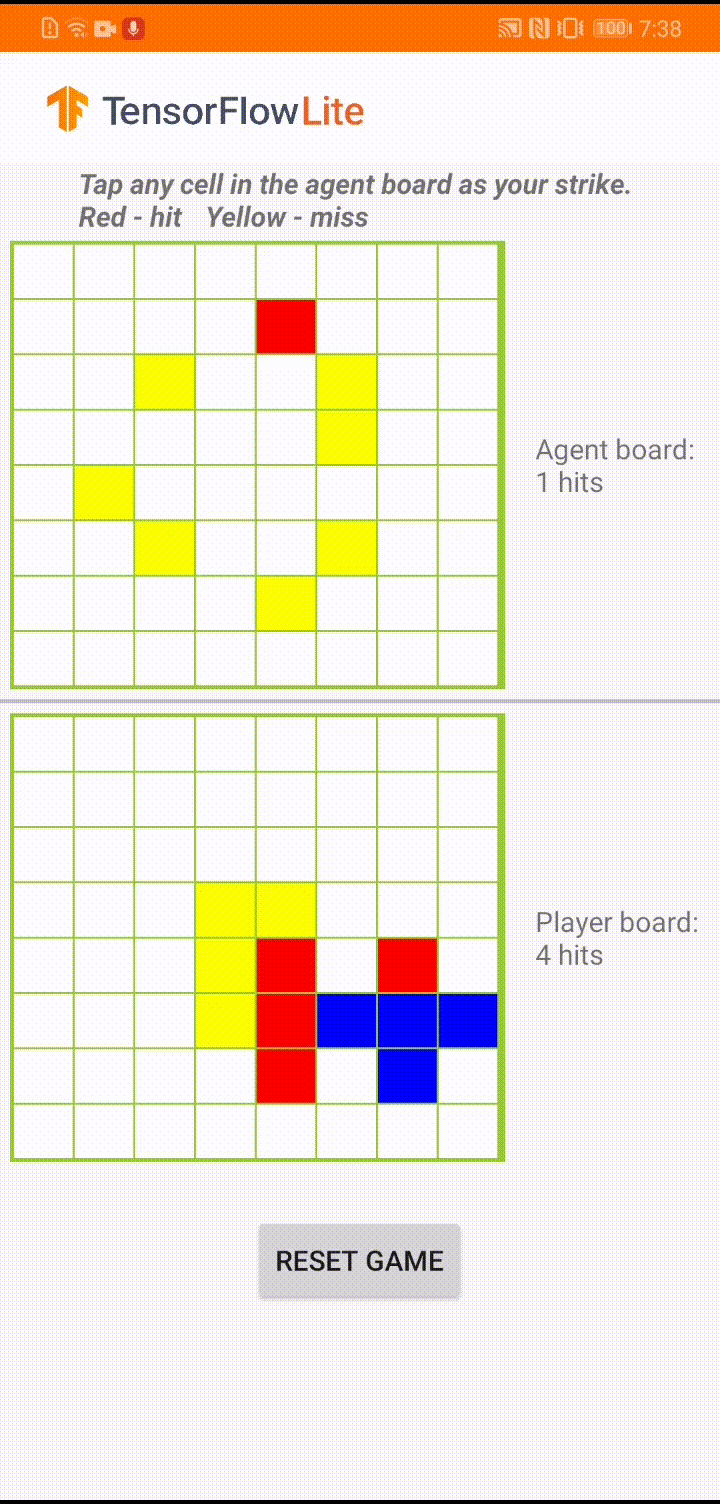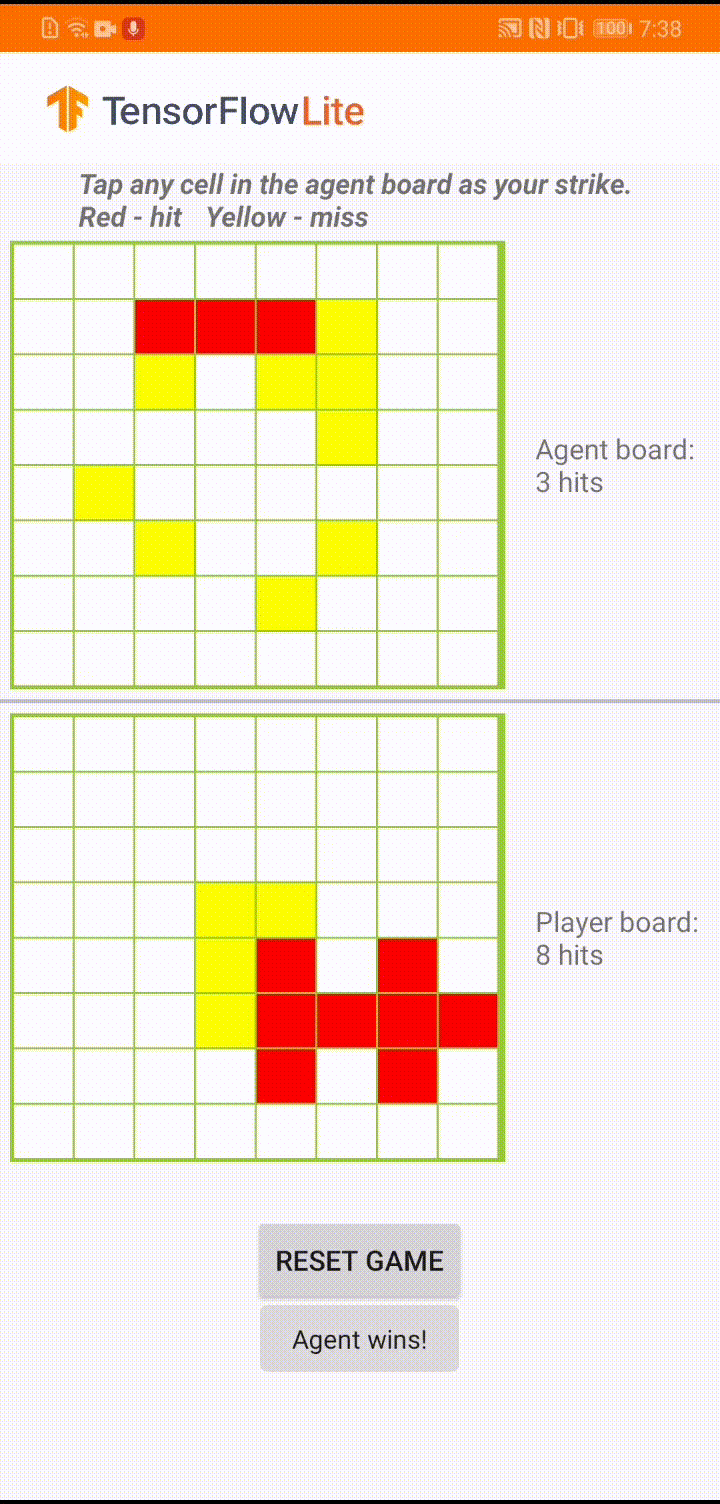
Model jest przeznaczony dla agenta gier do grania w małą grę planszową o nazwie „Plane Strike”. Aby szybko zapoznać się z tą grą i jej zasadami, zapoznaj się z tym plikiem README .
Pod interfejsem aplikacji zbudowaliśmy agenta, który gra przeciwko ludzkiemu graczowi. Agent to 3-warstwowy system MLP, który przyjmuje stan płytki jako dane wejściowe i wyprowadza przewidywany wynik dla każdej z 64 możliwych komórek płytki. Model jest szkolony przy użyciu gradientu polityki (REINFORCE), a kod szkoleniowy znajdziesz tutaj . Po przeszkoleniu agenta konwertujemy model do TFLite i wdrażamy go w aplikacji na Androida.
Podczas samej gry w aplikacji na Androida, gdy nadchodzi kolej agenta na podjęcie działań, agent sprawdza stan planszy gracza (tablica na dole), który zawiera informacje o poprzednich udanych i nieudanych uderzeniach (trafienia i chybienia). i wykorzystuje wyszkolony model do przewidywania, gdzie uderzyć dalej, aby mógł zakończyć grę, zanim zrobi to gracz-człowiek.
Benchmarki wydajności
Wartości porównawcze wydajności są generowane za pomocą narzędzia opisanego tutaj .
| Nazwa modelu | Rozmiar modelu | Urządzenie | procesor |
|---|---|---|---|
| Gradient polityki | 84 KB | Piksel 3 (Android 10) | 0,01 ms* |
| Piksel 4 (Android 10) | 0,01 ms* |
* 1 użyte wątki.
Wejścia
Model przyjmuje trójwymiarowy tensor float32 o wartości (1, 8, 8) jako stan płytki.
Wyjścia
Model zwraca dwuwymiarowy tensor kształtu float32 (1,64) jako przewidywane wyniki dla każdej z 64 możliwych pozycji uderzenia.
Trenuj własnego modela
Możesz wytrenować swój własny model dla większej/mniejszej płytki, zmieniając parametr BOARD_SIZE w kodzie szkoleniowym .