

वीडियो वर्गीकरण एक मशीन लर्निंग कार्य है जो यह पहचानता है कि वीडियो क्या दर्शाता है। एक वीडियो वर्गीकरण मॉडल को एक वीडियो डेटासेट पर प्रशिक्षित किया जाता है जिसमें अद्वितीय वर्गों का एक सेट होता है, जैसे कि विभिन्न क्रियाएं या गतिविधियां। मॉडल इनपुट के रूप में वीडियो फ़्रेम प्राप्त करता है और वीडियो में प्रत्येक वर्ग के प्रतिनिधित्व की संभावना को आउटपुट करता है।
वीडियो वर्गीकरण और छवि वर्गीकरण मॉडल दोनों पूर्वनिर्धारित वर्गों से संबंधित उन छवियों की संभावनाओं की भविष्यवाणी करने के लिए इनपुट के रूप में छवियों का उपयोग करते हैं। हालाँकि, एक वीडियो वर्गीकरण मॉडल वीडियो में क्रियाओं को पहचानने के लिए आसन्न फ़्रेमों के बीच स्थानिक-लौकिक संबंधों को भी संसाधित करता है।
उदाहरण के लिए, एक वीडियो एक्शन रिकग्निशन मॉडल को दौड़ने, ताली बजाने और हाथ हिलाने जैसी मानवीय गतिविधियों की पहचान करने के लिए प्रशिक्षित किया जा सकता है। निम्न छवि एंड्रॉइड पर वीडियो वर्गीकरण मॉडल का आउटपुट दिखाती है।
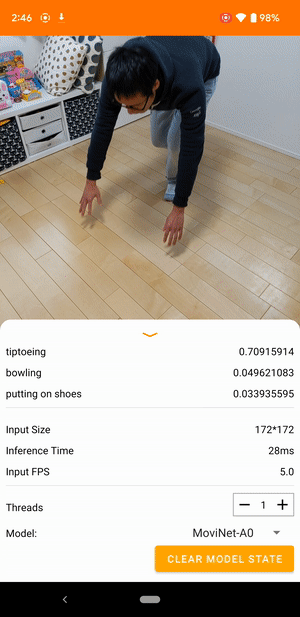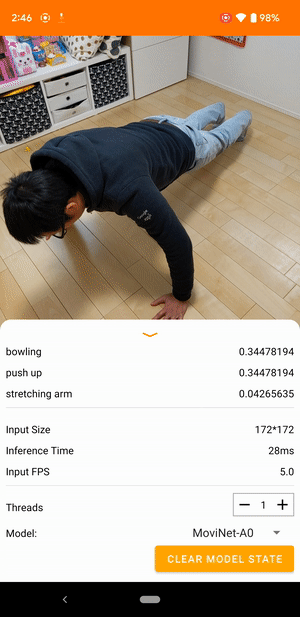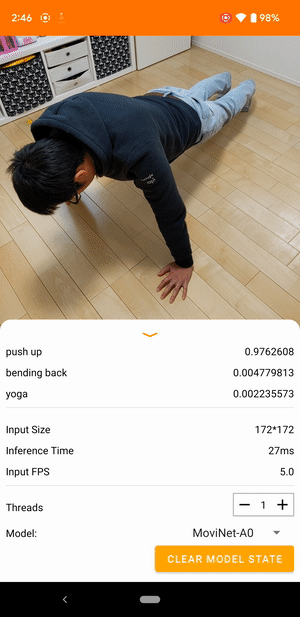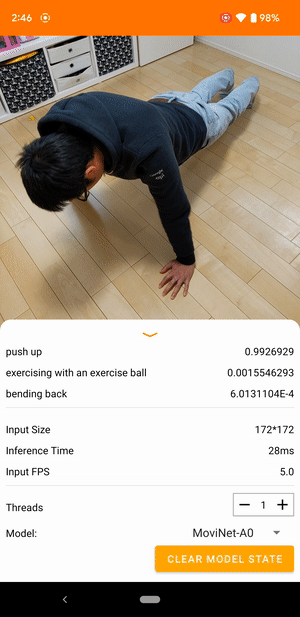
शुरू हो जाओ
यदि आप Android या Raspberry Pi के अलावा किसी अन्य प्लेटफ़ॉर्म का उपयोग कर रहे हैं, या यदि आप पहले से ही TensorFlow Lite API से परिचित हैं, तो स्टार्टर वीडियो वर्गीकरण मॉडल और सहायक फ़ाइलें डाउनलोड करें। आप TensorFlow Lite सपोर्ट लाइब्रेरी का उपयोग करके अपनी स्वयं की कस्टम अनुमान पाइपलाइन भी बना सकते हैं।
मेटाडेटा के साथ स्टार्टर मॉडल डाउनलोड करें
यदि आप TensorFlow Lite में नए हैं और Android या Raspberry Pi के साथ काम कर रहे हैं, तो आरंभ करने में आपकी सहायता के लिए निम्नलिखित उदाहरण एप्लिकेशन देखें।
एंड्रॉयड
एंड्रॉइड एप्लिकेशन निरंतर वीडियो वर्गीकरण के लिए डिवाइस के बैक कैमरे का उपयोग करता है। अनुमान TensorFlow Lite Java API का उपयोग करके किया जाता है। डेमो ऐप फ़्रेम को वर्गीकृत करता है और वास्तविक समय में अनुमानित वर्गीकरण प्रदर्शित करता है।
रास्पबेरी पाई
रास्पबेरी पाई उदाहरण निरंतर वीडियो वर्गीकरण करने के लिए पायथन के साथ टेन्सरफ्लो लाइट का उपयोग करता है। वास्तविक समय में वीडियो वर्गीकरण करने के लिए रास्पबेरी पाई को पाई कैमरा जैसे कैमरे से कनेक्ट करें। कैमरे से परिणाम देखने के लिए, मॉनिटर को रास्पबेरी पाई से कनेक्ट करें और पाई शेल तक पहुंचने के लिए एसएसएच का उपयोग करें (कीबोर्ड को पाई से कनेक्ट करने से बचने के लिए)।
शुरू करने से पहले, अपने रास्पबेरी पाई को रास्पबेरी पाई ओएस (अधिमानतः बस्टर में अपडेट) के साथ सेट करें ।
मॉडल वर्णन
मोबाइल वीडियो नेटवर्क ( MoViNets ) मोबाइल उपकरणों के लिए अनुकूलित कुशल वीडियो वर्गीकरण मॉडल का एक परिवार है। MoViNets कई बड़े पैमाने पर वीडियो एक्शन रिकग्निशन डेटासेट पर अत्याधुनिक सटीकता और दक्षता प्रदर्शित करता है, जो उन्हें वीडियो एक्शन रिकग्निशन कार्यों के लिए उपयुक्त बनाता है।
TensorFlow Lite के लिए MoviNet मॉडल के तीन प्रकार हैं: MoviNet-A0 , MoviNet-A1 , और MoviNet-A2 । इन वेरिएंट्स को 600 विभिन्न मानवीय क्रियाओं को पहचानने के लिए काइनेटिक्स-600 डेटासेट के साथ प्रशिक्षित किया गया था। MoviNet-A0 सबसे छोटा, तेज़ और सबसे कम सटीक है। MoviNet-A2 सबसे बड़ा, धीमा और सबसे सटीक है। MoviNet-A1, A0 और A2 के बीच एक समझौता है।
यह काम किस प्रकार करता है
प्रशिक्षण के दौरान, एक वीडियो वर्गीकरण मॉडल में वीडियो और उनसे संबंधित लेबल प्रदान किए जाते हैं। प्रत्येक लेबल एक विशिष्ट अवधारणा या वर्ग का नाम है, जिसे मॉडल पहचानना सीखेगा। वीडियो कार्रवाई पहचान के लिए, वीडियो मानवीय गतिविधियों के होंगे और लेबल संबंधित कार्रवाई के होंगे।
वीडियो वर्गीकरण मॉडल यह अनुमान लगाना सीख सकता है कि नए वीडियो प्रशिक्षण के दौरान प्रदान की गई किसी भी कक्षा से संबंधित हैं या नहीं। इस प्रक्रिया को अनुमान कहा जाता है. आप पहले से मौजूद मॉडल का उपयोग करके वीडियो की नई कक्षाओं की पहचान करने के लिए ट्रांसफर लर्निंग का भी उपयोग कर सकते हैं।
मॉडल एक स्ट्रीमिंग मॉडल है जो निरंतर वीडियो प्राप्त करता है और वास्तविक समय में प्रतिक्रिया देता है। जैसे ही मॉडल एक वीडियो स्ट्रीम प्राप्त करता है, यह पहचानता है कि प्रशिक्षण डेटासेट में से कोई भी वर्ग वीडियो में दर्शाया गया है या नहीं। प्रत्येक फ्रेम के लिए, मॉडल इन कक्षाओं को इस संभावना के साथ लौटाता है कि वीडियो कक्षा का प्रतिनिधित्व करता है। किसी निश्चित समय पर एक उदाहरण आउटपुट इस प्रकार दिख सकता है:
| कार्रवाई | संभावना |
|---|---|
| चौकोर नृत्य | 0.02 |
| धागे में पिरोने वाली सुई | 0.08 |
| उँगलियाँ घुमाना | 0.23 |
| हाथ हिलाना | 0.67 |
आउटपुट में प्रत्येक क्रिया प्रशिक्षण डेटा में एक लेबल से मेल खाती है। संभाव्यता इस संभावना को दर्शाती है कि कार्रवाई वीडियो में प्रदर्शित की जा रही है।
मॉडल इनपुट
मॉडल इनपुट के रूप में RGB वीडियो फ़्रेम की एक स्ट्रीम स्वीकार करता है। इनपुट वीडियो का आकार लचीला है, लेकिन आदर्श रूप से यह मॉडल प्रशिक्षण रिज़ॉल्यूशन और फ़्रेम-दर से मेल खाता है:
- MoviNet-A0 : 172 x 172 5 एफपीएस पर
- मूवीनेट-ए1 : 172 x 172 5 एफपीएस पर
- मूवीनेट-ए1 : 224 x 224 5 एफपीएस पर
सामान्य छवि इनपुट परंपराओं का पालन करते हुए, इनपुट वीडियो में रंग मान 0 और 1 की सीमा के भीतर होने की उम्मीद है।
आंतरिक रूप से, मॉडल पिछले फ़्रेमों में एकत्रित जानकारी का उपयोग करके प्रत्येक फ़्रेम के संदर्भ का विश्लेषण भी करता है। यह मॉडल आउटपुट से आंतरिक स्थिति लेकर और इसे आगामी फ़्रेमों के लिए मॉडल में वापस फीड करके पूरा किया जाता है।
मॉडल आउटपुट
मॉडल लेबल और उनके संबंधित स्कोर की एक श्रृंखला लौटाता है। स्कोर लॉगिट मान हैं जो प्रत्येक वर्ग के लिए भविष्यवाणी का प्रतिनिधित्व करते हैं। इन अंकों को सॉफ्टमैक्स फ़ंक्शन ( tf.nn.softmax ) का उपयोग करके संभावनाओं में परिवर्तित किया जा सकता है।
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
आंतरिक रूप से, मॉडल आउटपुट में मॉडल से आंतरिक स्थिति भी शामिल होती है और इसे आगामी फ़्रेमों के लिए मॉडल में वापस फीड किया जाता है।
प्रदर्शन मानदंड
प्रदर्शन बेंचमार्क नंबर बेंचमार्किंग टूल से उत्पन्न होते हैं। MoviNets केवल CPU को सपोर्ट करता है।
मॉडल के प्रदर्शन को हार्डवेयर के किसी दिए गए टुकड़े पर अनुमान चलाने में लगने वाले समय से मापा जाता है। कम समय का तात्पर्य तेज़ मॉडल से है। सटीकता इस बात से मापी जाती है कि मॉडल कितनी बार किसी वीडियो में किसी वर्ग को सही ढंग से वर्गीकृत करता है।
| मॉडल नाम | आकार | शुद्धता * | उपकरण | CPU ** |
|---|---|---|---|---|
| MoviNet-A0 (पूर्णांक परिमाणित) | 3.1 एमबी | 65% | पिक्सेल 4 | 5 एमएस |
| पिक्सेल 3 | 11 एमएस | |||
| MoviNet-A1 (पूर्णांक परिमाणित) | 4.5 एमबी | 70% | पिक्सेल 4 | 8 एमएस |
| पिक्सेल 3 | 19 एमएस | |||
| MoviNet-A2 (पूर्णांक परिमाणित) | 5.1 एमबी | 72% | पिक्सेल 4 | 15 एमएस |
| पिक्सेल 3 | 36 एमएस |
* टॉप-1 सटीकता काइनेटिक्स-600 डेटासेट पर मापी गई।
** 1-थ्रेड के साथ सीपीयू पर चलने पर विलंबता मापी गई।
मॉडल अनुकूलन
पूर्व-प्रशिक्षित मॉडलों को काइनेटिक्स-600 डेटासेट से 600 मानवीय क्रियाओं को पहचानने के लिए प्रशिक्षित किया जाता है। आप किसी मॉडल को उन मानवीय कार्यों को पहचानने के लिए फिर से प्रशिक्षित करने के लिए ट्रांसफर लर्निंग का भी उपयोग कर सकते हैं जो मूल सेट में नहीं हैं। ऐसा करने के लिए, आपको प्रत्येक नए कार्य के लिए प्रशिक्षण वीडियो के एक सेट की आवश्यकता होगी जिसे आप मॉडल में शामिल करना चाहते हैं।
कस्टम डेटा पर फाइन-ट्यूनिंग मॉडल के बारे में अधिक जानकारी के लिए MoViNets रेपो और MoViNets ट्यूटोरियल देखें।
आगे पढ़ना और संसाधन
इस पृष्ठ पर चर्चा की गई अवधारणाओं के बारे में अधिक जानने के लिए निम्नलिखित संसाधनों का उपयोग करें: