

Phân loại video là nhiệm vụ học máy nhằm xác định nội dung video thể hiện. Mô hình phân loại video được huấn luyện trên tập dữ liệu video chứa một tập hợp các lớp duy nhất, chẳng hạn như các hành động hoặc chuyển động khác nhau. Mô hình nhận các khung hình video làm đầu vào và xuất ra xác suất của mỗi lớp được thể hiện trong video.
Các mô hình phân loại video và phân loại hình ảnh đều sử dụng hình ảnh làm đầu vào để dự đoán xác suất của những hình ảnh đó thuộc các lớp được xác định trước. Tuy nhiên, mô hình phân loại video cũng xử lý các mối quan hệ không gian-thời gian giữa các khung liền kề để nhận ra các hành động trong video.
Ví dụ: mô hình nhận dạng hành động video có thể được đào tạo để xác định các hành động của con người như chạy, vỗ tay và vẫy tay. Hình ảnh sau đây hiển thị đầu ra của mô hình phân loại video trên Android.
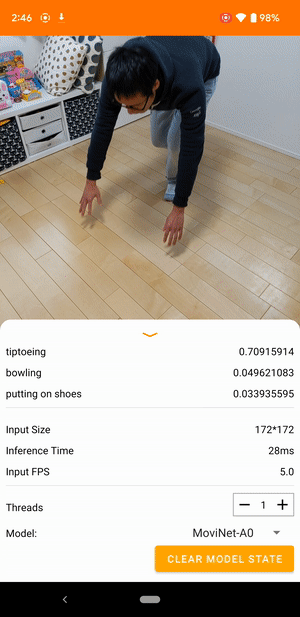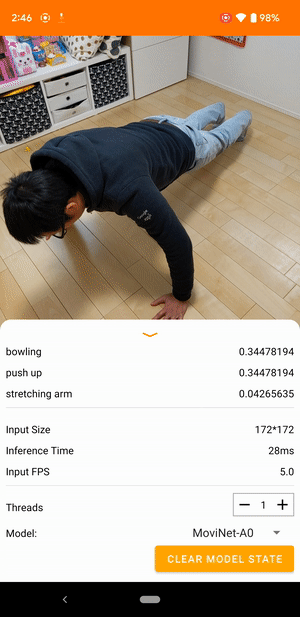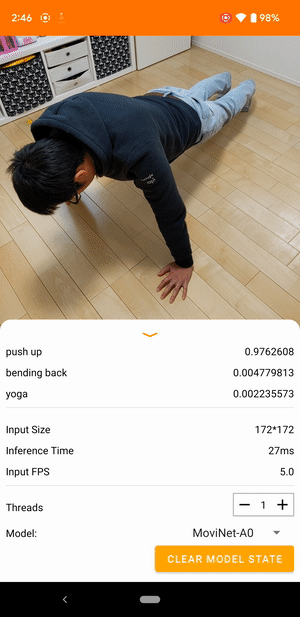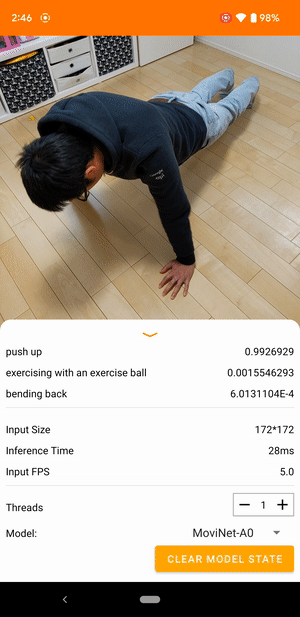
Bắt đầu
Nếu bạn đang sử dụng nền tảng không phải Android hoặc Raspberry Pi hoặc nếu bạn đã quen với API TensorFlow Lite , hãy tải xuống mô hình phân loại video ban đầu và các tệp hỗ trợ. Bạn cũng có thể xây dựng quy trình suy luận tùy chỉnh của riêng mình bằng Thư viện hỗ trợ TensorFlow Lite .
Tải xuống mô hình khởi đầu có siêu dữ liệu
Nếu bạn chưa quen với TensorFlow Lite và đang làm việc với Android hoặc Raspberry Pi, hãy khám phá các ứng dụng ví dụ sau để giúp bạn bắt đầu.
Android
Ứng dụng Android sử dụng camera sau của thiết bị để phân loại video liên tục. Suy luận được thực hiện bằng API Java TensorFlow Lite . Ứng dụng demo phân loại các khung và hiển thị các phân loại được dự đoán trong thời gian thực.
Raspberry Pi
Ví dụ Raspberry Pi sử dụng TensorFlow Lite với Python để thực hiện phân loại video liên tục. Kết nối Raspberry Pi với máy ảnh, như Pi Camera, để thực hiện phân loại video theo thời gian thực. Để xem kết quả từ camera, hãy kết nối màn hình với Raspberry Pi và sử dụng SSH để truy cập Pi shell (để tránh kết nối bàn phím với Pi).
Trước khi bắt đầu, hãy thiết lập Raspberry Pi của bạn với Raspberry Pi OS (tốt nhất là nên cập nhật lên Buster).
Mô tả về mô hình
Mạng video di động ( MoViNets ) là nhóm mô hình phân loại video hiệu quả được tối ưu hóa cho thiết bị di động. MoViNets thể hiện tính chính xác và hiệu quả tiên tiến trên một số bộ dữ liệu nhận dạng hành động video quy mô lớn, khiến chúng rất phù hợp cho các tác vụ nhận dạng hành động video .
Có ba biến thể của mô hình MoviNet cho TensorFlow Lite: MoviNet-A0 , MoviNet-A1 và MoviNet-A2 . Các biến thể này được huấn luyện bằng bộ dữ liệu Kinetics-600 để nhận dạng 600 hành động khác nhau của con người. MoviNet-A0 là nhỏ nhất, nhanh nhất và kém chính xác nhất. MoviNet-A2 là lớn nhất, chậm nhất và chính xác nhất. MoviNet-A1 là sự kết hợp giữa A0 và A2.
Làm thế nào nó hoạt động
Trong quá trình đào tạo, mô hình phân loại video được cung cấp video và nhãn liên quan của chúng. Mỗi nhãn là tên của một khái niệm hoặc lớp riêng biệt mà mô hình sẽ học cách nhận biết. Để nhận dạng hành động video , video sẽ là hành động của con người và nhãn sẽ là hành động liên quan.
Mô hình phân loại video có thể học cách dự đoán xem video mới có thuộc bất kỳ lớp nào được cung cấp trong quá trình đào tạo hay không. Quá trình này được gọi là suy luận . Bạn cũng có thể sử dụng phương pháp học chuyển giao để xác định các lớp video mới bằng cách sử dụng mô hình có sẵn.
Mô hình này là mô hình phát trực tuyến nhận video liên tục và phản hồi theo thời gian thực. Khi mô hình nhận được luồng video, nó sẽ xác định xem có bất kỳ lớp nào từ tập dữ liệu huấn luyện có được thể hiện trong video hay không. Đối với mỗi khung hình, mô hình trả về các lớp này cùng với xác suất video đại diện cho lớp đó. Một ví dụ đầu ra tại một thời điểm nhất định có thể trông như sau:
| Hoạt động | Xác suất |
|---|---|
| nhảy múa theo hình vuông | 0,02 |
| kim chỉ | 0,08 |
| vặn vẹo ngón tay | 0,23 |
| Vẫy tay | 0,67 |
Mỗi hành động ở đầu ra tương ứng với một nhãn trong dữ liệu huấn luyện. Xác suất biểu thị khả năng hành động đó được hiển thị trong video.
Đầu vào mô hình
Mô hình này chấp nhận một luồng khung hình video RGB làm đầu vào. Kích thước của video đầu vào rất linh hoạt, nhưng lý tưởng nhất là nó phù hợp với độ phân giải và tốc độ khung hình đào tạo mô hình:
- MoviNet-A0 : 172 x 172 ở tốc độ 5 khung hình / giây
- MoviNet-A1 : 172 x 172 ở tốc độ 5 khung hình / giây
- MoviNet-A1 : 224 x 224 ở tốc độ 5 khung hình / giây
Video đầu vào phải có giá trị màu trong khoảng 0 và 1, tuân theo các quy ước đầu vào hình ảnh phổ biến.
Trong nội bộ, mô hình cũng phân tích bối cảnh của từng khung hình bằng cách sử dụng thông tin được thu thập trong các khung hình trước đó. Điều này được thực hiện bằng cách lấy các trạng thái bên trong từ đầu ra của mô hình và đưa nó trở lại mô hình cho các khung sắp tới.
Đầu ra mô hình
Mô hình trả về một loạt nhãn và điểm số tương ứng của chúng. Điểm số là các giá trị logit đại diện cho dự đoán cho mỗi lớp. Những điểm số này có thể được chuyển đổi thành xác suất bằng cách sử dụng hàm softmax ( tf.nn.softmax ).
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
Trong nội bộ, đầu ra của mô hình cũng bao gồm các trạng thái bên trong của mô hình và đưa nó trở lại mô hình cho các khung hình sắp tới.
Điểm chuẩn hiệu suất
Số điểm chuẩn hiệu suất được tạo bằng công cụ đo điểm chuẩn . MoviNets chỉ hỗ trợ CPU.
Hiệu suất của mô hình được đo bằng lượng thời gian cần thiết để mô hình chạy suy luận trên một phần cứng nhất định. Thời gian thấp hơn ngụ ý một mô hình nhanh hơn. Độ chính xác được đo bằng tần suất mô hình phân loại chính xác một lớp trong video.
| Tên mẫu | Kích cỡ | Sự chính xác * | Thiết bị | CPU ** |
|---|---|---|---|---|
| MoviNet-A0 (Số nguyên được lượng tử hóa) | 3,1 MB | 65% | Pixel 4 | 5 mili giây |
| Pixel 3 | 11 mili giây | |||
| MoviNet-A1 (Số nguyên được lượng tử hóa) | 4,5 MB | 70% | Pixel 4 | 8 mili giây |
| Pixel 3 | 19 mili giây | |||
| MoviNet-A2 (Số nguyên được lượng tử hóa) | 5,1 MB | 72% | Pixel 4 | 15 mili giây |
| Pixel 3 | 36 mili giây |
* Độ chính xác cao nhất được đo trên bộ dữ liệu Kinetics-600 .
** Độ trễ được đo khi chạy trên CPU 1 luồng.
Tùy chỉnh mô hình
Các mô hình được đào tạo trước được đào tạo để nhận dạng 600 hành động của con người từ bộ dữ liệu Kinetics-600 . Bạn cũng có thể sử dụng phương pháp học chuyển giao để đào tạo lại mô hình nhằm nhận ra các hành động không có trong tập hợp ban đầu của con người. Để làm điều này, bạn cần một bộ video đào tạo cho từng hành động mới mà bạn muốn đưa vào mô hình.
Để biết thêm về cách tinh chỉnh mô hình trên dữ liệu tùy chỉnh, hãy xem kho MoViNets và hướng dẫn MoViNets .
Đọc thêm và tài nguyên
Sử dụng các tài nguyên sau để tìm hiểu thêm về các khái niệm được thảo luận trên trang này: