

طبقهبندی ویدیو ، وظیفه یادگیری ماشینی برای شناسایی چیزی است که یک ویدیو نشان میدهد. یک مدل طبقهبندی ویدیویی بر روی یک مجموعه داده ویدیویی آموزش داده میشود که شامل مجموعهای از کلاسهای منحصربهفرد، مانند اقدامات یا حرکات مختلف است. مدل فریم های ویدئویی را به عنوان ورودی دریافت می کند و احتمال نمایش هر کلاس در ویدئو را خروجی می دهد.
مدلهای طبقهبندی ویدئو و طبقهبندی تصویر هر دو از تصاویر به عنوان ورودی برای پیشبینی احتمالات آن تصاویر متعلق به کلاسهای از پیش تعریفشده استفاده میکنند. با این حال، یک مدل طبقهبندی ویدیویی روابط مکانی-زمانی بین فریمهای مجاور را برای تشخیص اقدامات در یک ویدیو پردازش میکند.
به عنوان مثال، یک مدل تشخیص کنش ویدیویی را می توان برای شناسایی اعمال انسان مانند دویدن، کف زدن و تکان دادن آموزش داد. تصویر زیر خروجی یک مدل طبقه بندی ویدیویی در اندروید را نشان می دهد.
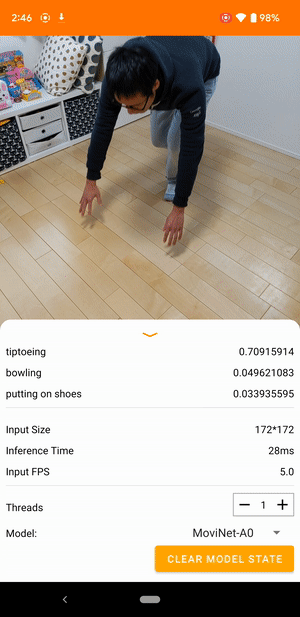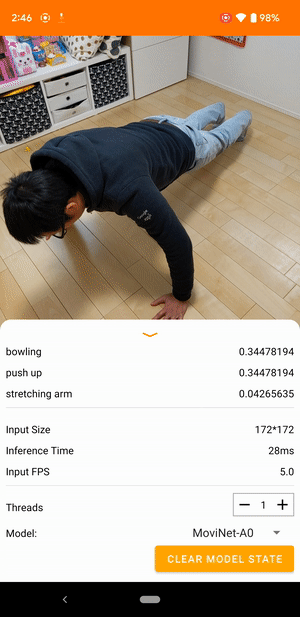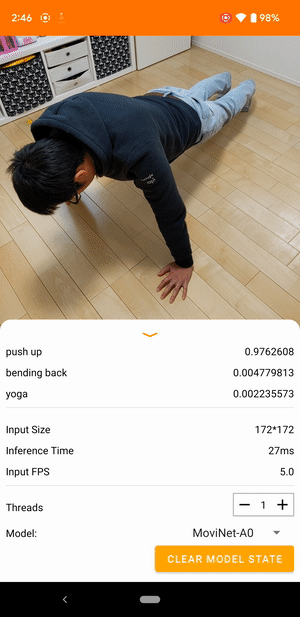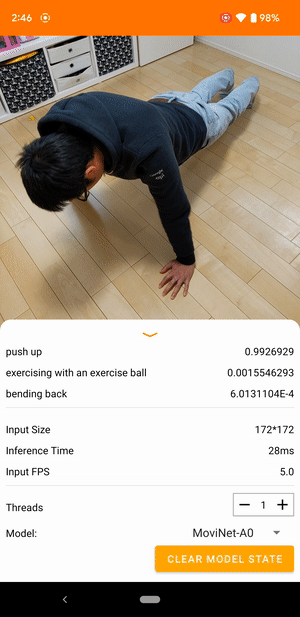
شروع کنید
اگر از پلتفرمی غیر از Android یا Raspberry Pi استفاده میکنید، یا اگر قبلاً با APIهای TensorFlow Lite آشنا هستید، مدل طبقهبندی ویدیوی شروع و فایلهای پشتیبانی را دانلود کنید. شما همچنین می توانید خط لوله استنتاج سفارشی خود را با استفاده از کتابخانه پشتیبانی TensorFlow Lite بسازید.
اگر با TensorFlow Lite تازه کار هستید و با Android یا Raspberry Pi کار می کنید، نمونه برنامه های زیر را بررسی کنید تا به شما در شروع کار کمک کند.
اندروید
برنامه اندروید از دوربین پشتی دستگاه برای طبقه بندی پیوسته ویدیو استفاده می کند. استنتاج با استفاده از TensorFlow Lite Java API انجام می شود. برنامه آزمایشی فریم ها را طبقه بندی می کند و طبقه بندی های پیش بینی شده را در زمان واقعی نمایش می دهد.
رزبری پای
مثال Raspberry Pi از TensorFlow Lite با پایتون برای انجام طبقهبندی ویدیویی پیوسته استفاده میکند. Raspberry Pi را به دوربینی مانند Pi Camera وصل کنید تا طبقهبندی ویدیوی بلادرنگ را انجام دهید. برای مشاهده نتایج از دوربین، یک مانیتور را به Raspberry Pi متصل کنید و از SSH برای دسترسی به پوسته Pi (برای جلوگیری از اتصال صفحه کلید به Pi) استفاده کنید.
قبل از شروع، Raspberry Pi خود را با سیستم عامل Raspberry Pi (ترجیحاً بهروزرسانی شده به Buster) تنظیم کنید .
توضیحات مدل
شبکههای ویدیویی موبایل ( MoViNets ) خانوادهای از مدلهای طبقهبندی ویدیویی کارآمد هستند که برای دستگاههای تلفن همراه بهینه شدهاند. MoViNets دقت و کارایی پیشرفتهای را در چندین مجموعه دادههای تشخیص اقدام ویدیویی در مقیاس بزرگ نشان میدهد، و آنها را برای کارهای تشخیص اقدام ویدیویی مناسب میسازد.
سه نوع از مدل MoviNet برای TensorFlow Lite وجود دارد: MoviNet-A0 ، MoviNet-A1 و MoviNet-A2 . این انواع با مجموعه داده Kinetics-600 برای تشخیص 600 عمل مختلف انسانی آموزش داده شدند. MoviNet-A0 کوچکترین، سریعترین و کم دقتترین است. MoviNet-A2 بزرگترین، کندترین و دقیق ترین است. MoviNet-A1 یک سازش بین A0 و A2 است.
چگونه کار می کند
در طول آموزش، یک مدل طبقه بندی ویدیویی ویدیوها و برچسب های مرتبط با آنها ارائه می شود. هر برچسب نام یک مفهوم یا کلاس متمایز است که مدل یاد می گیرد آن را تشخیص دهد. برای تشخیص کنش ویدیویی ، ویدیوها مربوط به اعمال انسانی و برچسبها کنش مرتبط خواهند بود.
مدل طبقهبندی ویدیویی میتواند پیشبینی کند که آیا ویدیوهای جدید متعلق به هر یک از کلاسهای ارائه شده در طول آموزش هستند یا خیر. این فرآیند استنتاج نامیده می شود. همچنین میتوانید از آموزش انتقال برای شناسایی کلاسهای جدید ویدیوها با استفاده از یک مدل از قبل موجود استفاده کنید.
این مدل یک مدل استریم است که ویدیوی پیوسته را دریافت می کند و در زمان واقعی پاسخ می دهد. همانطور که مدل یک جریان ویدیویی دریافت می کند، مشخص می کند که آیا هر یک از کلاس های مجموعه داده آموزشی در ویدیو نمایش داده شده است یا خیر. برای هر فریم، مدل این کلاسها را همراه با احتمال اینکه ویدیو نشاندهنده کلاس باشد، برمیگرداند. یک نمونه خروجی در یک زمان معین ممکن است به صورت زیر باشد:
| عمل | احتمال |
|---|---|
| رقص مربع | 0.02 |
| سوزن نخ | 0.08 |
| چرخاندن انگشتان | 0.23 |
| دست تکان دادن | 0.67 |
هر عمل در خروجی مربوط به یک برچسب در داده های آموزشی است. احتمال نشان دهنده احتمال این است که عمل در ویدیو نمایش داده شود.
ورودی های مدل
این مدل جریانی از فریم های ویدئویی RGB را به عنوان ورودی می پذیرد. اندازه ویدیوی ورودی انعطافپذیر است، اما در حالت ایدهآل با وضوح آموزش مدل و نرخ فریم مطابقت دارد:
- MoviNet-A0 : 172×172 با سرعت 5 فریم در ثانیه
- MoviNet-A1 : 172 x 172 با سرعت 5 فریم در ثانیه
- MoviNet-A1 : 224 x 224 با سرعت 5 فریم در ثانیه
انتظار میرود که ویدیوهای ورودی دارای مقادیر رنگی در محدوده 0 و 1 باشند، مطابق با قراردادهای رایج ورودی تصویر .
در داخل، مدل همچنین زمینه هر فریم را با استفاده از اطلاعات جمع آوری شده در فریم های قبلی تجزیه و تحلیل می کند. این کار با گرفتن حالت های داخلی از خروجی مدل و برگرداندن آن به مدل برای فریم های آینده انجام می شود.
خروجی های مدل
مدل مجموعه ای از برچسب ها و امتیازات مربوط به آنها را برمی گرداند. امتیازها مقادیر لاجیت هستند که پیش بینی هر کلاس را نشان می دهند. این امتیازات را می توان با استفاده از تابع softmax ( tf.nn.softmax ) به احتمالات تبدیل کرد.
exp_logits = np.exp(np.squeeze(logits, axis=0))
probabilities = exp_logits / np.sum(exp_logits)
در داخل، خروجی مدل شامل حالات داخلی مدل نیز میشود و آن را برای فریمهای آینده به مدل برمیگرداند.
معیارهای عملکرد
اعداد معیار عملکرد با ابزار محک تولید می شوند. MoviNets فقط از CPU پشتیبانی می کند.
عملکرد مدل با مدت زمانی که طول می کشد تا یک مدل استنتاج را روی یک قطعه سخت افزاری مشخص انجام دهد اندازه گیری می شود. زمان کمتر به معنای مدل سریعتر است. دقت با تعداد دفعاتی که مدل به درستی یک کلاس را در یک ویدیو طبقه بندی می کند اندازه گیری می شود.
| نام مدل | اندازه | دقت * | دستگاه | سی پی یو ** |
|---|---|---|---|---|
| MoviNet-A0 (عدد صحیح کوانتیزه شده) | 3.1 مگابایت | 65% | پیکسل 4 | 5 میلی ثانیه |
| پیکسل 3 | 11 میلی ثانیه | |||
| MoviNet-A1 (عدد صحیح کوانتیزه شده) | 4.5 مگابایت | 70% | پیکسل 4 | 8 میلی ثانیه |
| پیکسل 3 | 19 میلی ثانیه | |||
| MoviNet-A2 (عدد صحیح کوانتیزه شده) | 5.1 مگابایت | 72% | پیکسل 4 | 15 میلی ثانیه |
| پیکسل 3 | 36 میلیثانیه |
* دقت Top-1 بر روی مجموعه داده Kinetics-600 اندازه گیری شده است.
** تأخیر هنگام اجرا بر روی CPU با 1 رشته اندازه گیری می شود.
سفارشی سازی مدل
مدل های از پیش آموزش دیده برای تشخیص 600 عمل انسانی از مجموعه داده Kinetics-600 آموزش دیده اند. همچنین میتوانید از یادگیری انتقالی برای آموزش مجدد مدلی برای تشخیص اقدامات انسانی که در مجموعه اصلی نیستند استفاده کنید. برای انجام این کار، به مجموعه ای از فیلم های آموزشی برای هر یک از اقدامات جدیدی که می خواهید در مدل بگنجانید، نیاز دارید.
برای اطلاعات بیشتر در مورد مدلهای تنظیم دقیق دادههای سفارشی، به Repo MoViNets و آموزش MoViNets مراجعه کنید.
مطالعه بیشتر و منابع
برای کسب اطلاعات بیشتر در مورد مفاهیم مورد بحث در این صفحه از منابع زیر استفاده کنید: